
第三章宽金信息的态博弄 §1完养信息的动态博弈 级2经莫助意博来罐型 §3沈全非克薄情亮时爽博来(网阶辰) S4助窥停来分析的同画和扩展时轮 本节讨论完美信息下的动态博弃 §1完第信电的动态博弈 £1完美信意的功宽博弈 药销曲是的行动适环,每个参与人须题用飞 美中军事博弃一 指盖 §1完第信息的动态博弈 §1完美信息的动态博弈 博弈树(gmee -有限次博弃的扩展式表述 铁融轿程致食镜出不用装转格特次布 批 ▣大 :上风有一格楼 树: 不
1 § 1 完美信息的动态博弈 § 2 经典动态博弈模型 § 3完全非完美信息动态博弈(两阶段) § 4 动态博弈分析的问题和扩展讨论 第三章 完全信息动态博弈 动态博弈(Dynamic Games)或序贯行动博弈 Sequential-Move Games 本节讨论完美信息下的动态博弈 参与人的行动有先后顺序 后行动者能够观察到先行动者都干 了什么——完美信息 § 1 完美信息的动态博弈 例:欺负他人可以获得快乐,你会欺负他人吗? 欺负他人会担心他人的报复。——先行动者在选择行动时要考虑自己的选择对后行动 者的影响。 无论何时完成了行动选择,参与人都需要料想他们 当前的行动会如何影响未来的行动,包括对手的行 动和自己的行动。 于是,参与人是在计算未来结果的基础上决定他们 当前的行动选择。 为了做出最优的行动选择,每个参与人须运用怎 样的互动思维? § 1 完美信息的动态博弈 § 1 完美信息的动态博弈 解放初,美国总是寻找机会来侵犯我国。对此,毛主席提出了 “人不犯我、我不犯人,人若犯我、我必犯人”的战略方针。 行动空间:美国“犯我”或“不犯我”,中国“犯人”或“不犯人” 行动顺序:美国先行动,我国依美国的行动而后动 支付: 若美国“犯我”,中国“犯人”,则支付向量为(-2,-2); 若美国“犯我”,中国“不犯人”,则支付向量为(2,-4); 若美国“不犯我”,中国“犯人”,则支付向量为(3,-5); 若美国“不犯我”,中国“犯人”,则支付向量为(1,1)。 完全信息:对对手的 支付情况完全清楚 美中军事博弈 介绍一种展示和分析动态博弈的技术——博弈树,被称为博弈的扩展式表述,可以将 有关博弈的组成的基本要素:参与人、行动、支付表述出来。类似于决策树的概念 (这类树形图表达的是单个决策者在一个中性环境中连续不断的决策点或决策结)— —博弈树正是博弈中所有参与人决策树的合并,给出参与人所有可能行动,给出博弈 所有可能的结果。 § 1 完美信息的动态博弈 博弈树 (game tree)——有限次博弈的扩展式表述 犯人 犯人 不犯人 不犯人 犯我 不犯我 美国 我国 我国 (1,1) (3,-5) (2,-4) (-2,-2) 决策结:行 动时点 枝:任意决策结出 发能够选择的行动 终点结:对应一 个博弈结果,支 付向量 初始结 路径:由不同枝形成的链构造出不同路径,每条路径都通过有限次行动将你带到 博弈的某个终点。 例:两房地产商A、B进行房地产开发。市场需求大、小的概率各占50%。投入: 1亿。 当市场上有两栋楼出售时 需求大时,每栋售价1.4亿, 需求小时,售价7千万; 如果市场上只有一栋楼 需求大时,可卖1.8亿 需求小时,可卖1.1亿 引入一个“自然”的外部参与人,随机性 事件被假定为一个称为自然的参与人来控制 博弈的随机性特征在 博弈树中如何表述? § 1 完美信息的动态博弈
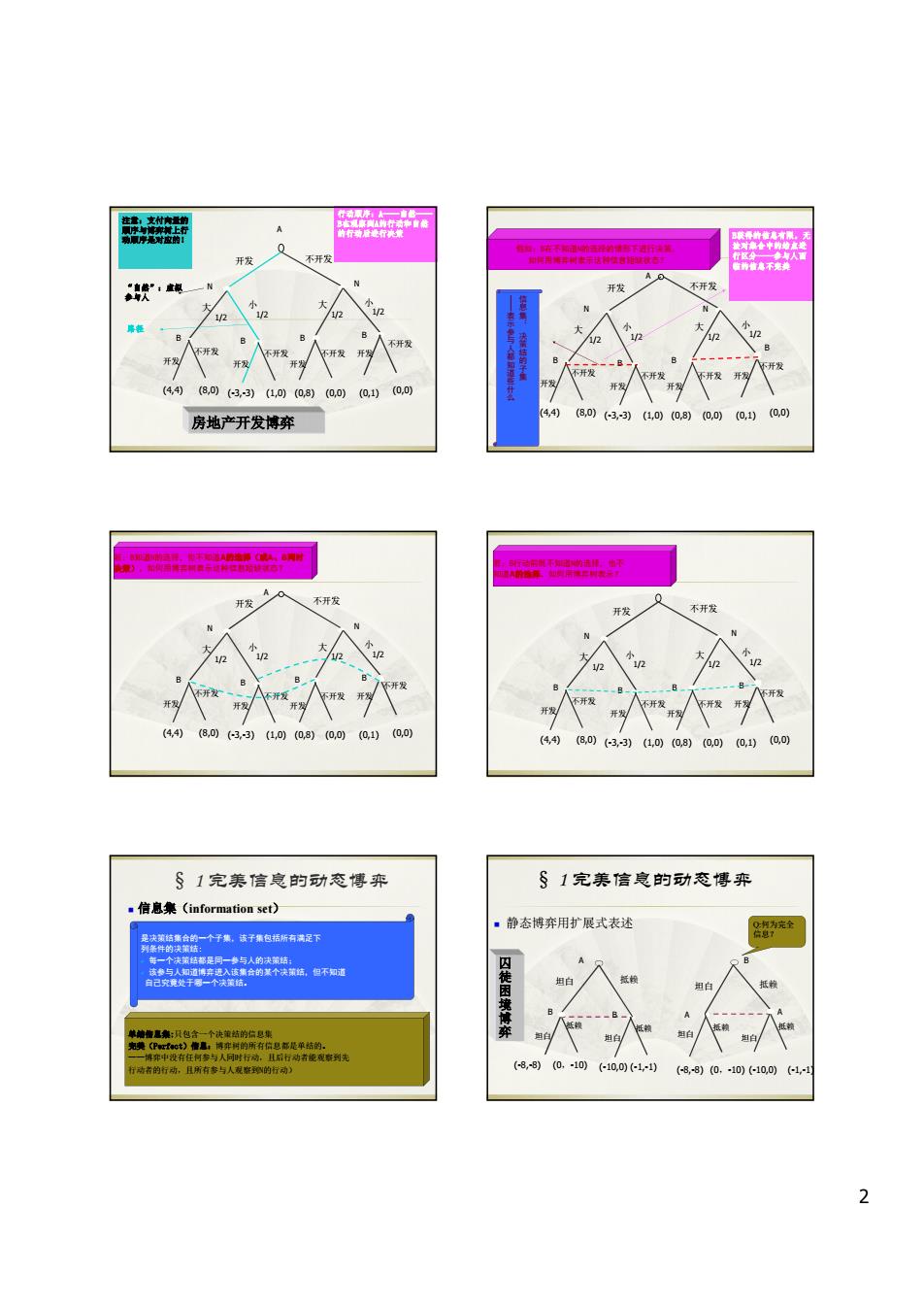
器 开发 房地产开发博弃 (0)(-3.-3)(1.0)(0)((0.)(00) 不开发 开发 4 可3,-31,008)0,0)0,1)(a0 §1完美信息的动态博弈 §1完第信息的动态博弈 信息集(information s较t) 。静态博弈用扩展式表述 2
2 A 开发 不开发 N N 大 小 1/2 1/2 大 小 1/2 1/2 B B B B 开发 不开发 开发 不开发 开发 不开发 开发 不开发 (4,4) (8,0) (-3,-3) (1,0) (0,8) (0,0) (0,1) (0,0) 注意:支付向量的 顺序与博弈树上行 动顺序是对应的! “自然”:虚拟 参与人 行动顺序:A——自然—— B在观察到A的行动和自然 的行动后进行决策 路径 房地产开发博弈 A 开发 不开发 N N 大 小 1/2 1/2 大 小 1/2 1/2 B B B B 开发 不开发 开发 不开发 开发 不开发 开发 不开发 (4,4) (8,0) (-3,-3) (1,0) (0,8) (0,0) (0,1) (0,0) B获得的信息有限,无 法对集合中的结点进 行区分——参与人面 临的信息不完美 假如:B在不知道N的选择的情形下进行决策, 如何用博弈树表示这种信息短缺状态? 信 息 集 : 决 策 结 的 子 集 —— 表 示 参 与 人 都 知 道 些 什 么 A 开发 不开发 N N 大 小 1/2 1/2 大 小 1/2 1/2 B B B B 开发 不开发 开发 不开发 开发 不开发 开发 不开发 (4,4) (8,0) (-3,-3) (1,0) (0,8) (0,0) (0,1) (0,0) 若:B知道N的选择,但不知道A的选择(或A、B同时 决策),如何用博弈树表示这种信息短缺状态? A 开发 不开发 N N 大 小 1/2 1/2 大 小 1/2 1/2 B B B B 开发 不开发 开发 不开发 开发 不开发 开发 不开发 (4,4) (8,0) (-3,-3) (1,0) (0,8) (0,0) (0,1) (0,0) 若:B行动前既不知道N的选择,也不 知道A的选择,如何用博弈树表示? 信息集(information set) 是决策结集合的一个子集,该子集包括所有满足下 列条件的决策结: 每一个决策结都是同一参与人的决策结; 该参与人知道博弈进入该集合的某个决策结,但不知道 自己究竟处于哪一个决策结。 单结信息集:只包含一个决策结的信息集 完美(Perfect)信息:博弈树的所有信息都是单结的。 ——博弈中没有任何参与人同时行动,且后行动者能观察到先 行动者的行动,且所有参与人观察到N的行动) § 1 完美信息的动态博弈 静态博弈用扩展式表述 B A A 坦白 抵赖 坦白 抵赖 坦白 抵赖 (-8,-8) (0,-10) (-10,0) (-1,-1) A 坦白 抵赖 B B 坦白 抵赖 坦白 抵赖 (-8,-8) (0,-10) (-10,0) (-1,-1) Q:何为完全 信息? 囚 徒 困 境 博 弈 § 1 完美信息的动态博弈

§1完美信电的动态博弈 动态博弈中的策略 开黎研发 人在结上 中军填 开发 入不开发 我开发是卡 下开发 费经段 不家 中 蜀不梨 S1完美信定的功意博弈 S1完美信息的动意博弈 广展式与策略式的对比 a—n. 制耳劉耳耳默认默认,割耳默认,默认! 18. S1完第信息的动态博弈 §1完第信息的动态博弈 。NE不逼制耳献认) 如果孩子足够理性,会相父亲马7 生 行
3 但是,参与人可以制定一个行动计划,将每个决策结上 的选择都事先规定好,即使这个决策点实际上不会出 现。——策略 动态博弈中的策略 博弈树中参与人在结点上所选择的单个行动—— 一步/招 (move) 策略: 人不犯我、我不犯人; 人若犯我、我必犯人 美国 中国 不犯人 (-2,-2) (2,-4) (3,-5) (0,0) 中国 美中军事博弈 § 1 完美信息的动态博弈 开发策略:不论A开发不开发, 我开发——{开发,开发} 追随策略:A开发我开发,A不 开发我不开发——{开发,不 开发} ; 对抗策略:A开发我不开发,A 不开发我开发——{不开发, 开发} ; 不开发策略:不论A开发不开发 我不开发)——{不开发,不 开发}; 策略空间为:{开发,开发}、 {开发,不开发} 、{不开发, 开发} (不开发,不开发}。 A 开发 不开发 B B 开发 不开发 开发 (-3,-3) (1,0) (0,1) (0,0) 不开发 x x’ A的策略空间为:(开发,不开发); B有2个可选择的行动,但策略空间中的可选策略有? 静态博弈中 策略=行动 扩展式与策略式的对比 {割耳,割耳} {割耳,默认} {默认,割耳} {默认,默认} 画 -3,-3 -3,-3 1,0 1,0 不画 -4,-3 0,0 -4,-3 0,0 割耳 画 不画 割耳 默认 默认 小孩 父亲 父亲 (0,0) (-4,-3) (1,-2) (-3,-3) 小 孩 父亲 威胁博弈 § 1 完美信息的动态博弈 {割耳,割耳} {割耳,默认} {默认,割耳} {默认,默认} 画 -3,-3 -3,-3 1,-2 1,-2 不画 -4,-3 0,0 -4,-3 0,0 割耳 画 不画 割耳 默认 默认 小孩 父亲 父亲 (0,0) (-4,-3) (1,-2) (-3,-3) 三个NE: (不画,{割耳,默认}) (画,{默认,割耳}) (画,{默认,默认}) § 1 完美信息的动态博弈 § 1 完美信息的动态博弈 NE(不画,{割耳,默认}): 父亲威胁孩子,如果画,那么就割掉耳朵。孩子相信了威 胁,则最好选择不画;如果孩子选择不画,则父亲选择 {割耳,默认}是最优的。 如果孩子足够理性,会相信父亲威胁吗? 一旦孩子选择了“画”,父亲无疑选择默认,即策略中事 先“规定”的“你画我就割你的耳朵”这一行动届时不会 发生。——父亲的威胁是不可置信的(not credible) 。 (不画,{割耳,默认}), (画,{默认,割耳})不会是该博弈合理的均衡。 这些包含了不可置信的策略所构成的NE是不能作为模型预测结果的,必须去除。 动态博弈中,各博弈方的策略是他们自己预先设定 的,在各个博弈阶段,针对各种情况的相应行为选 择的计划。这些策略实际上并没有强制力,而且实 施起来有一个过程,因此,只要符合博弈方自己的 利益,他们完全可以在博弈过程中改变计划。我们 称这种问题为动态博弈中的“相机选择”(Contingent Play)问题。 问题:纳什均衡在动态博弈中失效,关键是动态博弈 中各博弈方策略选择行为上的“可信性”问题。 § 1 完美信息的动态博弈

§1完第信息的动态博弃 §1完第信息的动态博弈 不 S1完美信息的动态博恋 §1完第信息的动态博弈 不包含不可置信的行功的策略 齐方的为也就客易确了。 S1完美信息的动态博弈 S1完养信息的动态博弈 海盗分赃 海盗分赃 的网:拾白已9 5是(90.10.1)
4 定义:如果一个完美信息的动态博弈中,各博 弈方的策略构成的一个策略组合满足,在整个 动态博弈及它的所有子博弈中都构成纳什均衡, 那么这个策略组合称为该动态博弈的一个“子 博弈精炼纳什均衡”。 子博弈精炼纳什均衡能够排除均衡策略中不可信的威胁和 承诺,因此是真正稳定的。 子博弈精炼纳什均衡必须对博弈方在所有选择节点处的选 择做出规定,包括最终不在均衡路径上的节点。 逆推归纳法是求完美信息动态博弈子博弈精炼纳什均衡的 基本方法。 § 1 完美信息的动态博弈 定义:由一个动态博弈第一阶段以外的某阶段开始的 后续博弈阶段构成的,有初始信息集和进行博弈所需 要的全部信息,能够自成一个博弈的原博弈的一部分, 称为原动态博弈的一个“子博弈”。 乙 甲 不借 借 分 不分 (1,0) (0,4) (2,2) 乙 (-1,0) 注: (1)从一个单点决 策节开始,之后的所 有枝节包含其中 (2)子博弈不能分 割信息集 § 1 完美信息的动态博弈 NE:(不画,{割,默认})(不是子博 弈I的均衡) NE:(画, {默认,割} )(不是子博 弈II的均衡) NE:(画, {默认,默认} ) 不包含不可置信的行动的策略——子博弈精炼纳什均衡(能够 排除保证实际发生的动态行为与事前规定的策略是一致的,因 此是真正稳定的)。 子博弈Ⅱ (-3,-3) (1,-2) 子博弈Ⅰ 小孩 父 亲 默认 (-4,-3) (0,0) 威胁博弈 § 1 完美信息的动态博弈 定义:从动态博弈的最后一个阶段博弈方的行 为开始分析,逐步倒推回前一个阶段相应博弈 方的行为选择,一直到第一个阶段的分析方法, 称为“逆推归纳法”。 逻辑基础:动态博弈中先行动的理性的博弈方, 在前面阶段选择行为时必然会先考虑后行为博 弈方在后面阶段中将会怎样选择行为,只有在 博弈的最后一个阶段选择的,不再有后续阶段 牵制的博弈方,才能直接作出明确选择。而当 后面阶段博弈方的选择确定以后,前一阶段博 弈方的行为也就容易确定了。 § 1 完美信息的动态博弈 § 1 完美信息的动态博弈 5个海盗抢到了100颗宝石,每一颗都有一样的大小和一 样贵重的价值,经过商议,他们决定将宝石这样分配: a 抽签决定自己的号码1,2,3,4,5。 b 首先,由1号提出分配方案,然后5人进行表决, 如果同意这种方案的人达到半数,就按照1号的提案进行 分配,否则,他将被扔入大海喂鲨鱼,然后由接下来的 人继续重复提议。 假设每个海盗都是绝顶聪明,也不互相合作,而且每个 都追求最大限度得到金币宝石 1号海盗如何提议? 海盗分赃 § 1 完美信息的动态博弈 5号海盗:分给自己100枚宝石 4号海盗:分给自己100枚宝石并赞成自己;5号海盗被 分得0枚,反对无用 3号海盗:分给5号海盗1枚并得到5号的同意;分给自己 99枚,自己同意;分给4号海盗0枚,4号反对也无用 2号海盗:分给4号1枚得到4号的同意;分给自己99枚, 自己也同意;3、5号反对无用。 1号海盗:分给3、5号海盗各1枚,获得3、5号的同意; 分给自己98枚,自己同意;分给2、4号海盗0枚,他们 会反对但不起作用。 均衡结果是(98,0,1,0,1) 海盗分赃

§2经典勋疮博弈棉型 一、Stackelberg真头竞争模型 一、所克零格型 岩新去智的产全业为质者。 -(ata)F-2a- 二、时价还价得弃 正向销速求都smN结是,第一身段全之的间题为 =agmx,(,94a)=6g:-g42-9i 。带新.包就是反酒直为 一、Stackelberga有头竞争模型 一,Stacke1berg真头竞争模型 9g-5g)-6-g)—中e湖版 ,比较stackeberg候型和ouno模型结果: mx4(4,9%)=6g-94- 御照数” 代入反 二、讨价还价模型 二、讨价还价模型 纳法 线出一个制比到,对甲由的比可以体受可动 85
5 §2 经典动态博弈模型 一、斯塔克博格模型 二、讨价还价博弈 企业1为领头企业,首先选择自己的产量;企业2为跟随者, 根据企业1的产量选择自己的产量 Q q1 q2 , P P(Q) 8 Q 2 c1 c2 1 1 1 1 1 1 2 2 1 u qP(Q)cq q[8(q q )] q 2 6q1q1q2 q1 2 2 2 2 2 1 2 2 2 u q P(Q)c q q [8(q q )] q 2 6q2 q1q2 q2 逆向归纳法求解SPNE结果。第二阶段企业2的问题为 2 * 2 2 2 1 2 2 1 2 2 arg max ( , ) 6 q q u q q q q q q 一阶条件,也就是反应函数为 一、Stackelberg寡头竞争模型 * 2 2 1 1 1 ( ) (6 ) 2 q s q q 与cournot模型中企业2的反应 函数相同 企业1会预测到企业2的反应,因此第一阶段的问题为 1 * 2 max ( , ) 6 1 1 2 1 1 2 1 q u q q q q q q 代入企业2的反应函数得 q1 *=3 则 q2 *=1.5 产量 支付 厂商1 3单位 4.5 厂商2 1.5单位 2.25 古诺博弈均衡: 厂商1 2单位 4 厂商2 2单位 4 一、Stackelberg寡头竞争模型 比较stackelberg模型和counot模型结果: stackelberg均衡 counot均衡 为什么? 企业1存在先动优势(first-mover advantage) 产量 支付 产量 支付 厂商1 3单位 4.5 2 4 厂商2 1.5单位 2.25 2 4 与cournot模型相比,企业2拥有信息优势反而对自己不利 一、Stackelberg寡头竞争模型 二、讨价还价模型 讨价还价:两人就如何分享1万元现金进行谈判,并定下 如下规则: 先由甲提出一个分割比例,对甲提出的比例乙可以接受也可以 拒绝; 如果乙拒绝甲的方案,则他自己应提出另一个方案,让甲选择 接受与否; …… 只要任何一方接受对方的方案,博弈就结束,而如果方案被拒 绝,则被拒绝方案与以后的讨价还价不再有关系。 每一次,一方提出一个方案,与另一方选择是否接受为一个回 合,讨价还价每多进行一个回合,由于谈判费用和利息损失等, 双方的利益都要打一个折扣(其值在0—1之间,我们称为消耗 系数。 二、讨价还价模型 利用逆推归纳法分析: 第三回合,甲出S,双方的利益分别为 2 S和 2 (10000- S)(由于乙必须接受,故S通常为10000) 第二回合,乙的选择。乙知道一旦博弈进行到第三回 合,甲的策略及双方的得益。如果乙已经拒绝第一回 合甲的方案,此时他该怎样出价才能使自己的利益最 大化? 原则:任何一博弈方只要利益不少于下一回合自己出价时的 利益,就愿意接受对方的出价 故乙在第二回合能让甲接受的,也是可能使自己得最大利益 的S2,应满足使甲的二、三回合得益相同,此时,乙的得益 为(10000-S)