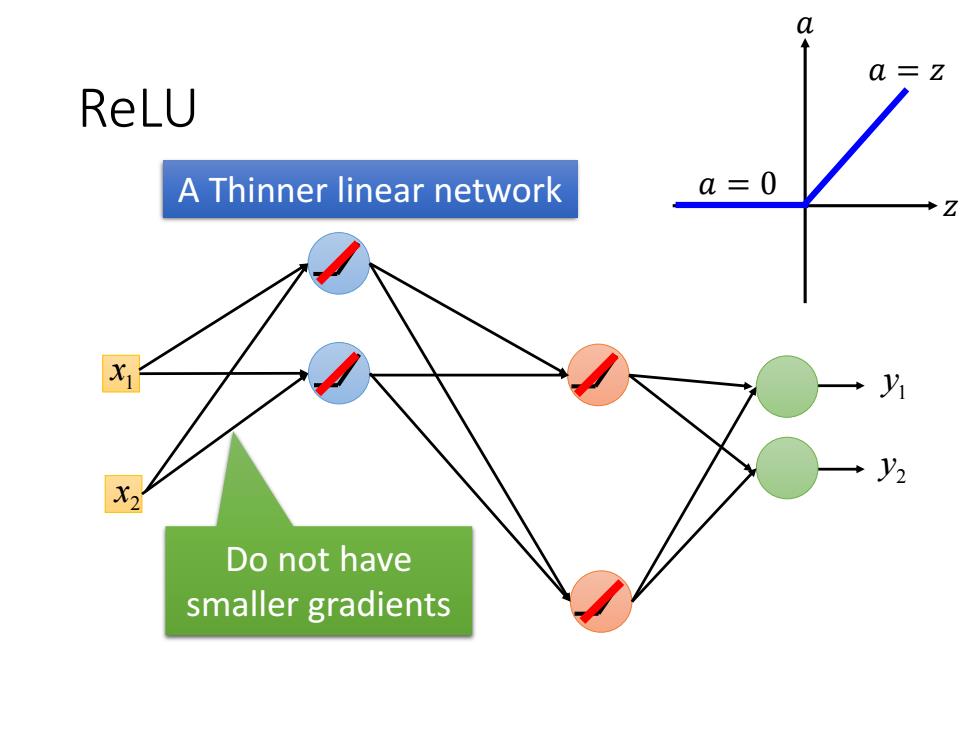
ReLU A Thinner linear network a=0 Do not have smaller gradients
ReLU 1 x 2 x 1 y 2 y A Thinner linear network Do not have smaller gradients 𝑧 𝑎 𝑎 = 𝑧 𝑎 = 0
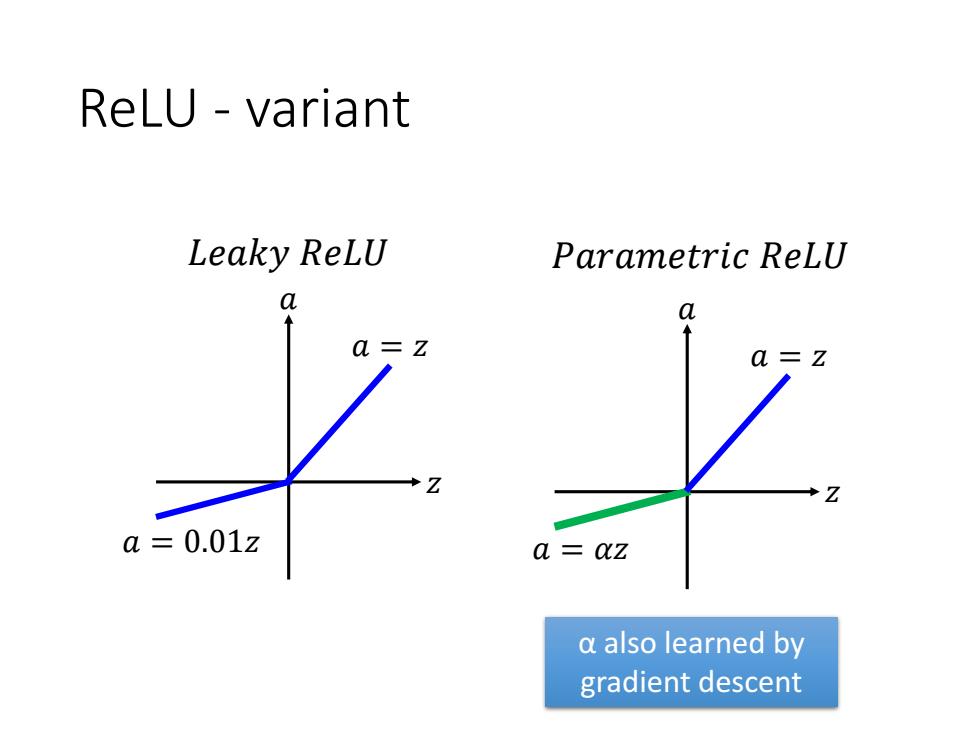
ReLU-variant Leaky ReLU Parametric ReLU 0 a a=0.01z a az a also learned by gradient descent
ReLU - variant 𝑧 𝑎 𝑎 = 𝑧 𝑎 = 0.01𝑧 𝐿𝑒𝑎𝑘𝑦 𝑅𝑒𝐿𝑈 𝑧 𝑎 𝑎 = 𝑧 𝑎 = 𝛼𝑧 𝑃𝑎𝑟𝑎𝑚𝑒𝑡𝑟𝑖𝑐 𝑅𝑒𝐿𝑈 α also learned by gradient descent
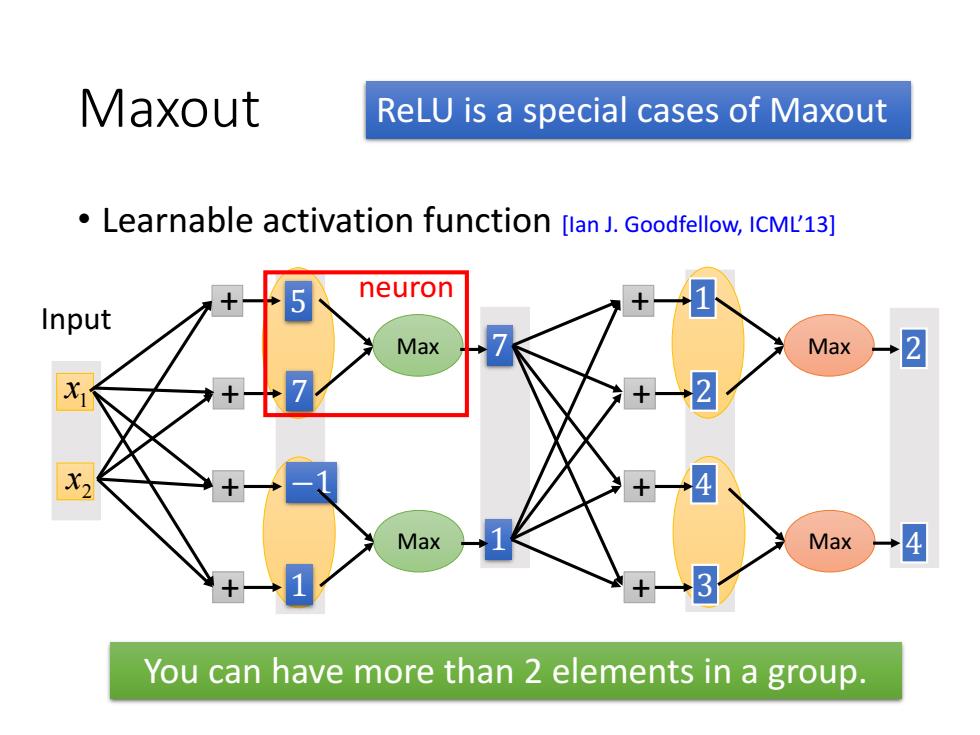
Maxout ReLU is a special cases of Maxout Learnable activation function [lan J.Goodfellow,ICML'13] 5 neuron Input Max Max 2 +-2 +一4 Max Max 4 +3 You can have more than 2 elements in a group
Maxout • Learnable activation function [Ian J. Goodfellow, ICML’13] Max 1 x 2 x Input Max + 5 + 7 + −1 + 1 7 1 Max Max + 1 + 2 + 4 + 3 2 4 ReLU is a special cases of Maxout You can have more than 2 elements in a group. neuron
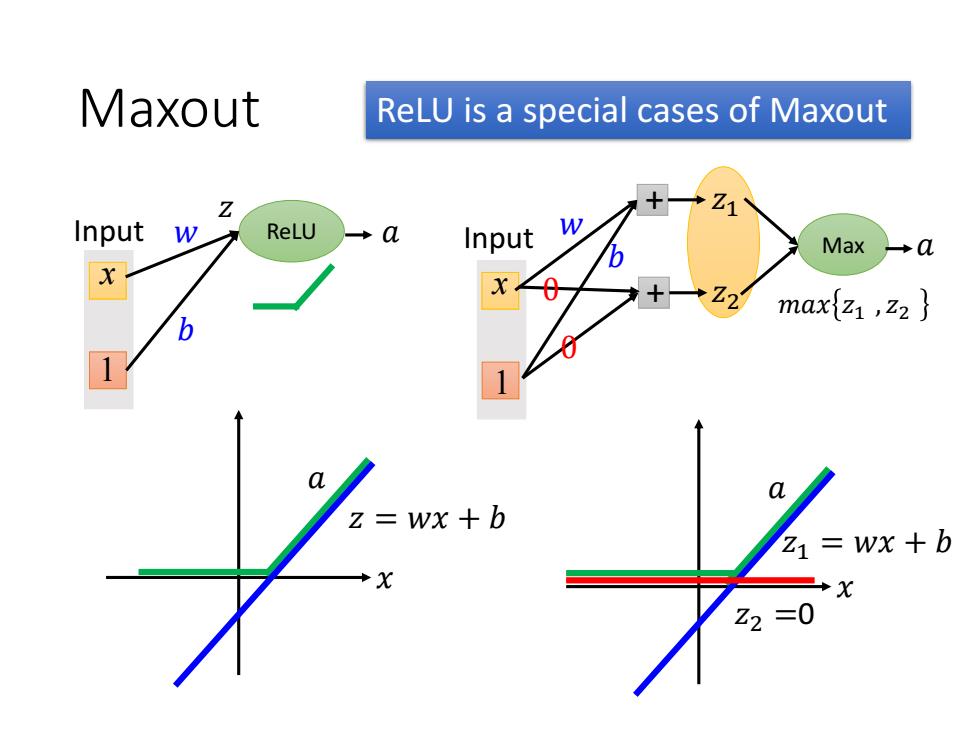
Maxout ReLU is a special cases of Maxout Z +Z1 Input w ReLU a Input w Max →a *Z21 maxz ,z2 区wx+0 Z1=Wx +b Z2=0
Maxout Max x1 Input + 𝑧1 + 𝑧2 𝑎 𝑚𝑎𝑥 𝑧1 , 𝑧2 𝑤 𝑏 0 0 𝑥 𝑧 = 𝑤𝑥 + 𝑏 𝑎 x1 Input ReLU 𝑧 𝑤 𝑏 𝑎 𝑥 𝑧1 = 𝑤𝑥 + 𝑏 𝑎 𝑧2 =0 ReLU is a special cases of Maxout
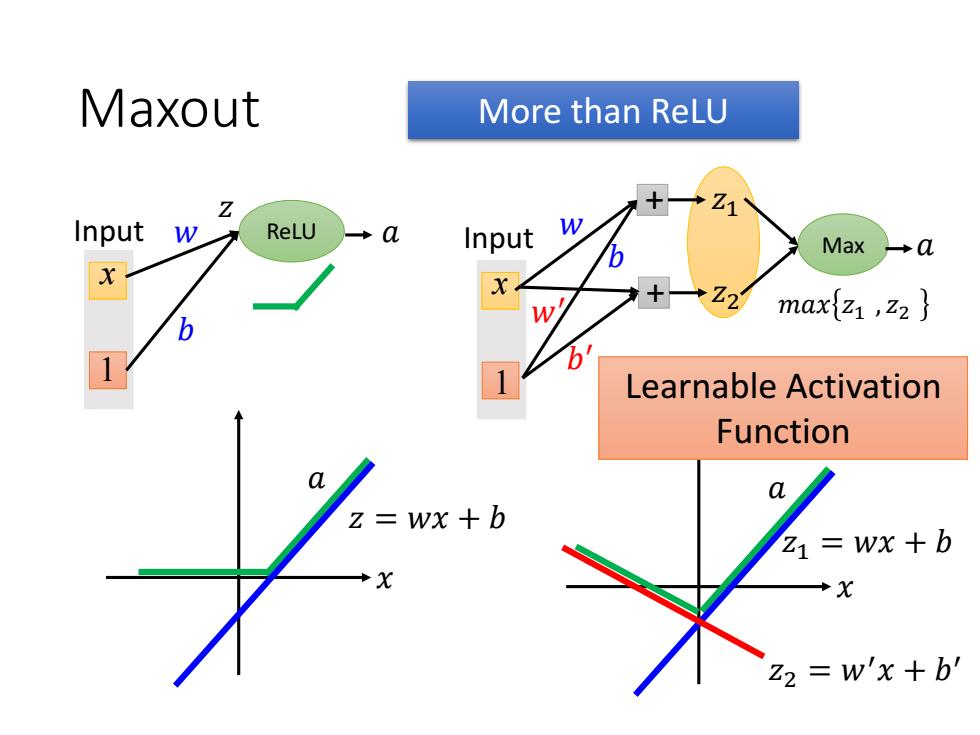
Maxout More than ReLU Z Input W ReLU a Input W Max →a 12 maxtz ,z2 Learnable Activation Function a z=wx+b Z1=Wx +b X Z2 =w'x +b
Maxout Max x1 Input + 𝑧1 + 𝑧2 𝑎 𝑚𝑎𝑥 𝑧1 , 𝑧2 𝑤 𝑏 𝑤′ 𝑏 ′ 𝑥 𝑧 = 𝑤𝑥 + 𝑏 𝑎 x1 Input ReLU 𝑧 𝑤 𝑏 𝑎 𝑥 𝑧1 = 𝑤𝑥 + 𝑏 𝑎 𝑧2 = 𝑤′𝑥 + 𝑏 ′ Learnable Activation Function More than ReLU