ya n=Ta.x 注意力机制 Sino+smnB 2an erf x e' =mcA
注意力机制

动机 ·每个生成的tokeni可能与不同的源token:相关 bonjour 、le monde <eos> hidden state 中中中 hello world <bos>bonjour monde D2L.ai
动机 • 每个生成的token可能与不同的源token相关
注意力层 ·注意力层明确选择相关信息 它的存储器(memory) Memory 由“键值对”组成 键和查询越相似,则输 Values Output 出的值越相近 Attention Keys Query D2L.ai
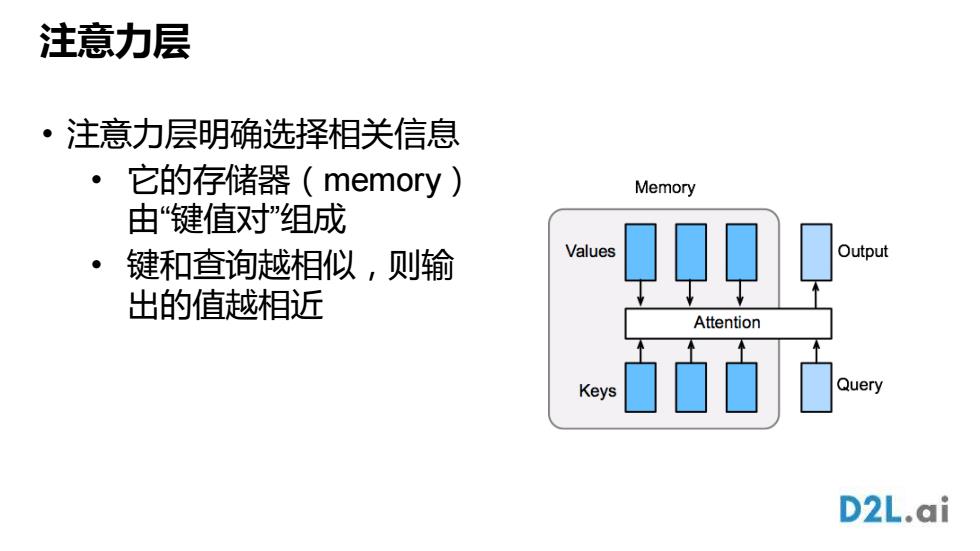
注意力层 • 注意力层明确选择相关信息 • 它的存储器(memory) 由“键值对”组成 • 键和查询越相似,则输 出的值越相近

注意力层 假设“一条询问”为q∈Rag,存储器为(k1,V1),…,(kVn); 。 k;eRak,V:∈Ra, ·计算n分数a1,,an;ai=(q,ki) 改变a可以 ·使用softmax获得注意力 获得不同 b1,…,bn=softmax(a1,…,an) 的注意力 ·输出是值的加权和 层 m 0=∑b1 i=1 D2L.ai
注意力层 • 假设“一条询问”为 𝐪 ∈ ℝ 𝑑𝑞 ,存储器为 (𝐤1, 𝐯1), … , (𝐤𝑛, 𝐯𝑛) ; 𝐤𝑖∈ ℝ 𝑑𝑘 ,𝐯𝑖 ∈ ℝ 𝑑𝑣 • 计算 n 分数 𝑎1, …, 𝑎𝑛;𝑎𝑖 = 𝛼(𝐪, 𝐤𝑖) • 使用 softmax 获得注意力 𝑏1, … , 𝑏𝑛 = softmax(𝑎1, … , 𝑎𝑛) • 输出是值的加权和 𝐨 = ∑ 𝑖=1 𝑛 𝑏𝑖𝐯𝑖 改变α可以 获得不同 的注意力 层

点乘注意力 ·假设询问的长度与值相同q,k;∈Rd a(q,k)=(q,k)/Vd ·向量化版本 ·m个询问Q∈Rmxd和n个键K∈Rnxd a(Q,K)QKT/Vd D2L.ai
点乘注意力 • 假设询问的长度与值相同 𝐪, 𝐤𝑖 ∈ ℝ 𝑑 𝛼(𝐪, 𝐤) = ⟨𝐪, 𝐤⟩/ 𝑑 • 向量化版本 • m 个询问 𝐐 ∈ ℝ 𝑚×𝑑 和 n 个键 𝐊 ∈ ℝ 𝑛×𝑑 𝛼(𝐐,𝐊) = 𝐐𝐊 𝑇 / 𝑑