
Error surface is rugged .. Tips for training:Adaptive Learning Rate
Error surface is rugged … Tips for training: Adaptive Learning Rate 1
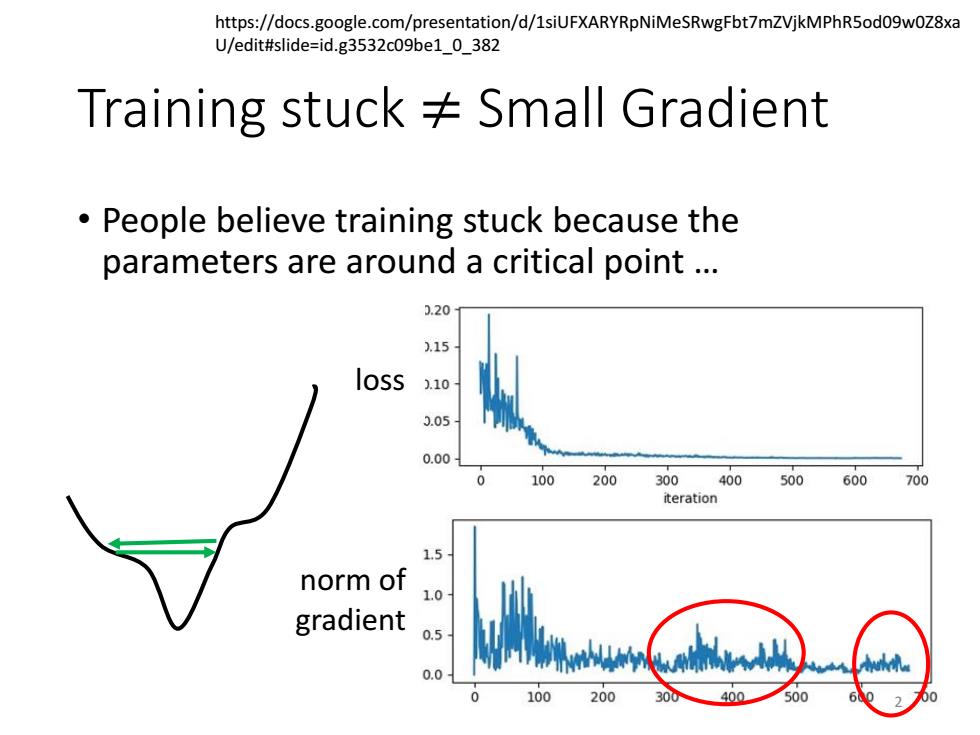
https://docs.google.com/presentation/d/1siUFXARYRpNiMeSRwgFbt7mZVjkMPhR5od09w0Z8xa U/edit#slide=id.g3532c09be1_0_382 Training stuck Small Gradient People believe training stuck because the parameters are around a critical point .. 0.20 .15 loss 1.10 3.05 0.00 100 200 300400500600 700 iteration 1.5 norm of 1.0 gradient 0.5 0.0 100 200 30 400 500
Training stuck ≠ Small Gradient • People believe training stuck because the parameters are around a critical point … loss norm of gradient https://docs.google.com/presentation/d/1siUFXARYRpNiMeSRwgFbt7mZVjkMPhR5od09w0Z8xa U/edit#slide=id.g3532c09be1_0_382 2

Wait a minute... 0.10 0.08 0.06 造o04 0.02 0.00 ·86。 0.0 0.1 0.2 0.3 0.4 0.5 minimum ratio
Wait a minute … 3
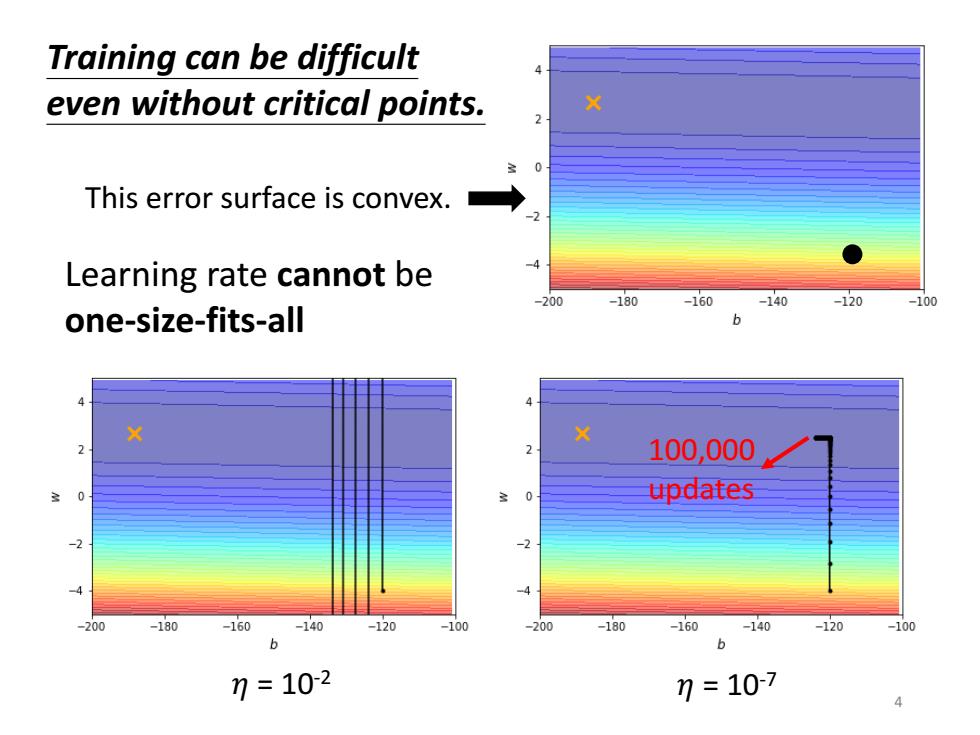
Training can be difficult even without critical points. This error surface is convex. Learning rate cannot be -200 -180 -160 -140 -120 -100 one-size-fits-all 6 X 100,000 0 updates 200 -180 -160 -140 -120 -100 -200 -180 -160 -140 -120 -100 b b 7=102 7=107 4
100,000 updates 𝜂 = 10-2 Learning rate cannot be one-size-fits-all Training can be difficult even without critical points. 𝜂 = 10-7 4 This error surface is convex
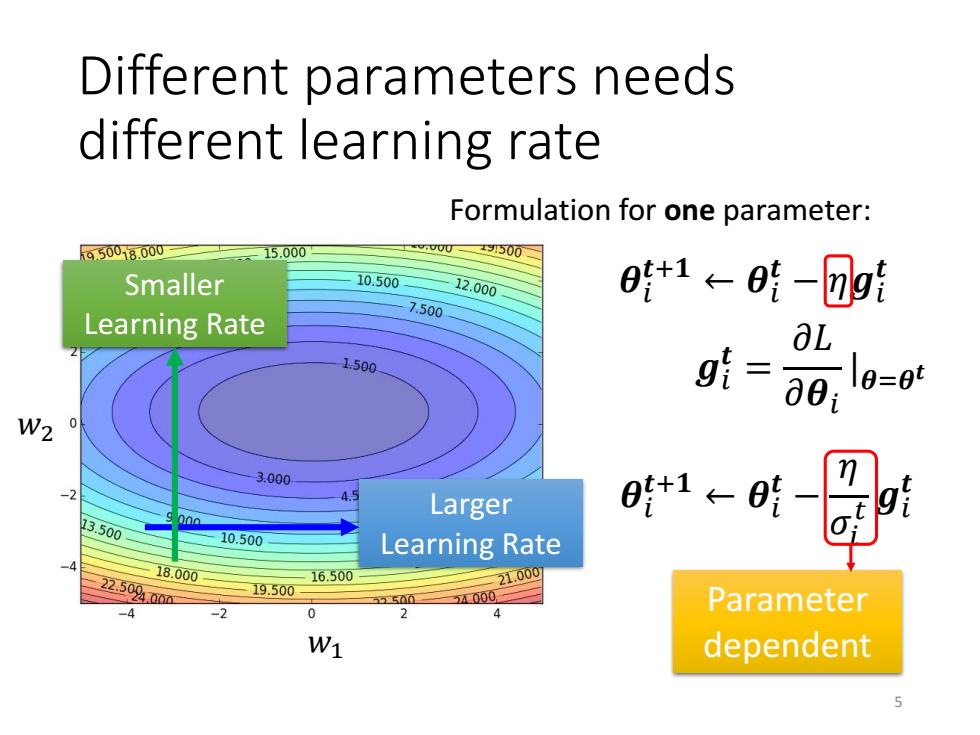
Different parameters needs different learning rate Formulation for one parameter: 650018.000 15.000 x3500 Smaller 10.500 12.000 0+1←01-⑦g1 7.500 Learning Rate aL 1500 g1=∂01 0=09 W2 0 3.000 Larger 时t1←时 13.500 00a 10.500 Learning Rate 18.000 22.50400m 16.500 19.500 21.000 5000 Parameter dependent
Different parameters needs different learning rate 𝑤1 𝑤2 Larger Learning Rate Smaller Learning Rate 𝜽𝑖 𝒕+𝟏 ← 𝜽𝑖 𝒕 − 𝜂𝒈𝑖 𝒕 𝜽𝑖 𝒕+𝟏 ← 𝜽𝑖 𝒕 − 𝜂 𝜎𝑖 𝑡 𝒈𝑖 𝒕 Parameter dependent 𝒈𝑖 𝒕 = 𝜕𝐿 𝜕𝜽𝑖 |𝜽=𝜽 𝒕 Formulation for one parameter: 5