
从运算速度来看,MAC(乘法/累加)时间已经从20世 纪80年代初的400ns(如TMS32010)降低到10ns以下 DSP芯片内部关键的乘法器部件从1980年的占模片区 (die area)的4o%左右下降到5%以下,先进的DSP芯片 的片内已含有多个乘法器部件和算术逻辑单元,片内 RAM的数量也增加了一个数量级以上。 *1980年采用4μm NMOS.工艺,而现在则普遍采用亚微 米(Micron)CMOS工艺
从运算速度来看,MAC(乘法/累加)时间已经从20世 纪80年代初的400ns(如TMS32010)降低到10ns以下 DSP芯片内部关键的乘法器部件从1980年的占模片区 (die area)的40%左右下降到5%以下,先进的DSP芯片 的片内已含有多个乘法器部件和算术逻辑单元,片内 RAM的数量也增加了一个数量级以上。 1980年采用4μm NMOS工艺,而现在则普遍采用亚微 米(Micron)CMOS工艺

每隔10年DSP芯片的发展 年份 1982 1992(97) 2002 口 工艺线宽(um) 3 0.8(0.35) 0.18 ▣ MAC*(MIPS) 5 40(100) 2G 时钟(MH) 20 80(200) 500 ▣ RAM (Words) 144 1K 16K ▣ ROM (Words) 1.5K 4K 64K 价格(美元) 150 15 1.5 ▣ 功耗(mv/MIPS)250 12.5 0.1 晶体管数 50K 500 5M 硅片尺寸 3英寸 6英寸(8英寸)12英寸* 做一次乘法和累加计算的时间
每隔10年DSP芯片的发展 年份 1982 1992(97) 2002 工艺线宽(um) 3 0.8(0.35) 0.18 MAC*(MIPS) 5 40(100) 2G 时钟(MH) 20 80(200) 500 RAM(Words) 144 1K 16K ROM(Words) 1.5K 4K 64K 价格(美元) 150 15 1.5 功耗(mv/MIPS)250 12.5 0.1 晶体管数 50K 500 5M 硅片尺寸 3英寸 6英寸(8英寸) 12英寸* 做一次乘法和累加计算的时间

二、DSP的特点 *)采用哈佛(Harvard)总线结构。 与哈佛结构相关,DSP芯片广泛 采用流水线操作以减少指令执行 时间
1)采用哈佛(Harvard)总线结构。 与哈佛结构相关,DSP芯片广泛 采用流水线操作以减少指令执行 时间 二、DSP的特点
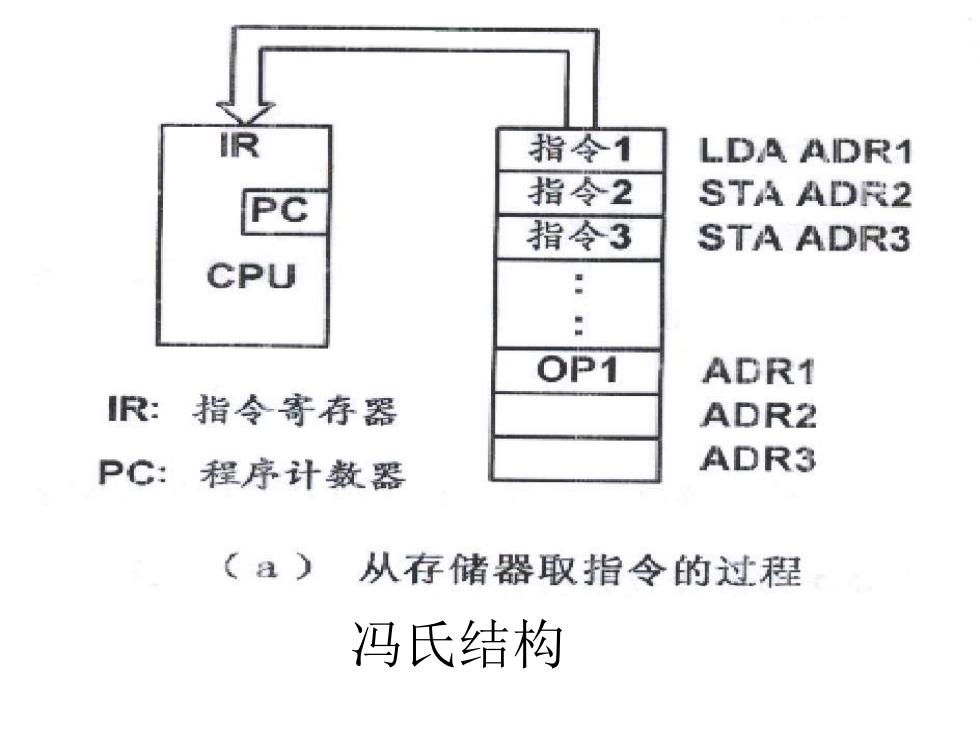
IR 指令1 LDA ADR1 PC 指令2 STA ADR2 指令3 STA ADR3 CPU OP1 ADR1 IR:指令寄存器 ADR2 PC: 程序计数器 ADR3 (a) 从存储器取指令的过程 冯氏结构
冯氏结构
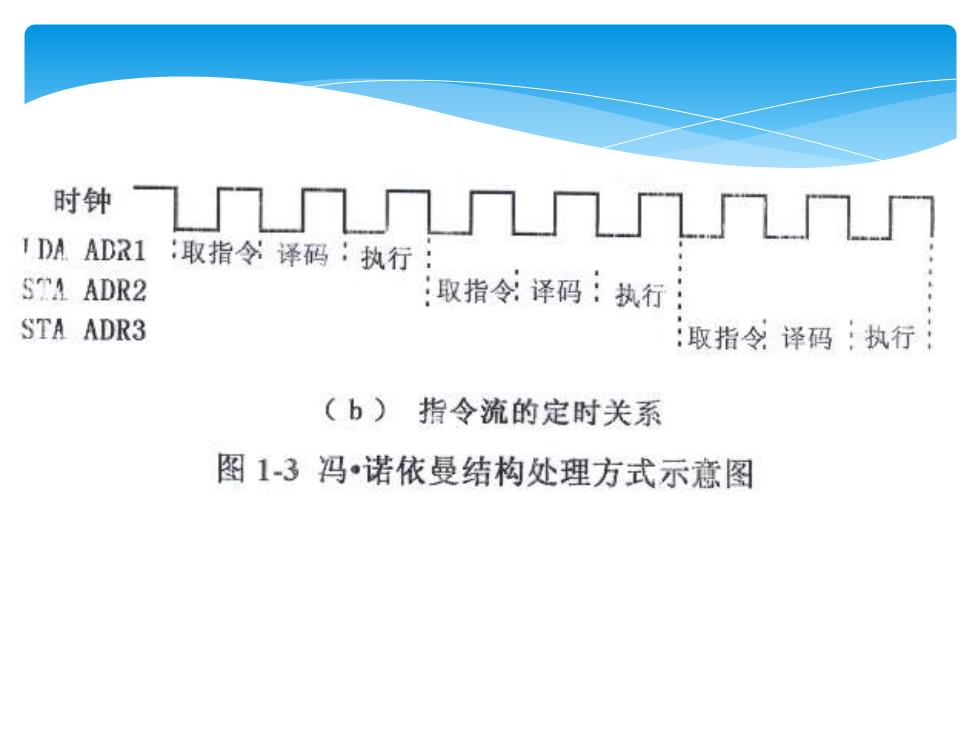
时钟 ΠΠΠL1 I DA.ADR1 :取指令译码:执行 STA ADR2 :取指令:译码:执行 STA ADR3 :取指令译码执行 (b)指令流的定时关系 图13冯诺依曼结构处理方式示意图