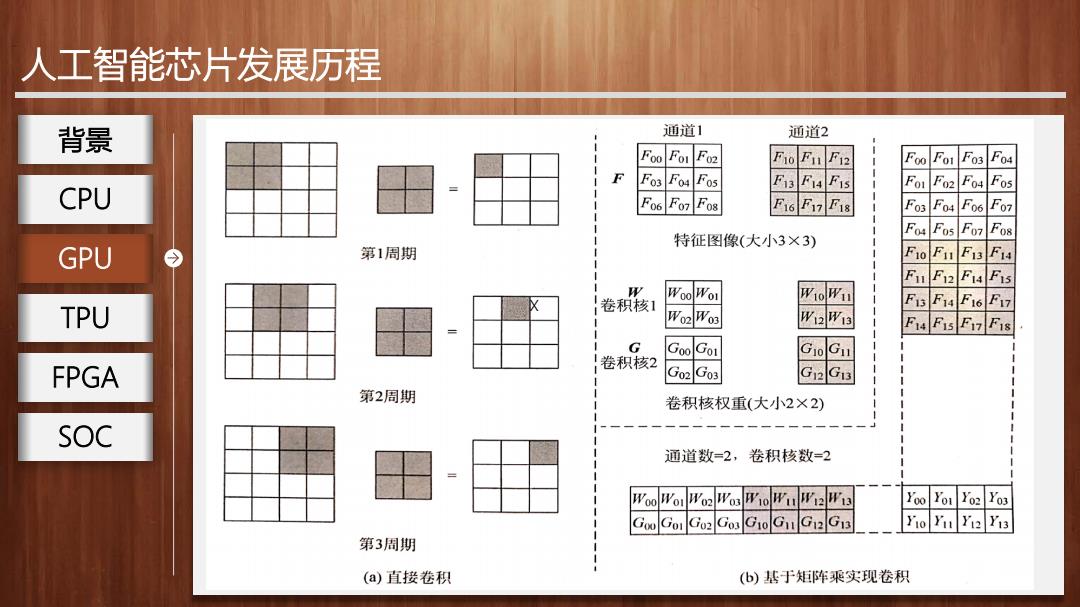
人工智能芯片发展历程 背景 通道1 通道2 Foo Fo1 F02 FoFn F12 Foo Fo1 F03 Fo4 F Fos Fo Fos F3 F4 FIS Fo1 F02 F04 Fos CPU Fo6 F07 F0s E16E7E18 F03 F04 Fo6 F07 F04 Fos F07 F08 特征图像(大小3×3) GPU 第1周期 F10FI F13 F14 Fu F12 F14 Fis WooWoi WioWu 卷积核1 F13 F14 F16F17 TPU Wo2Wo3 W2W13 F14 FIs F17 FIs G GooGo1 卷积核2 FPGA Go2Go3 G12G13 第2周期 卷积核权重(大小2×2) SOC 通道数=2,卷积核数=2 WooWor Wo2WosW10WuW12W13 Yoo Yor Yo2 Yo3 GooGoI Go2Gos G1oGu G12G1 Yio Yu Yi2 Yi3 第3周期 (a)直接卷积 (b)基于矩阵乘实现卷积
人工智能芯片发展历程 x GPU 背景 CPU TPU FPGA SOC

人工智能芯片发展历程 背景 GPU单指令多线程处理: CPU 。可以观察到,对于展开后的矩阵相乘, 左矩阵的每个行向量与右矩阵 GPU 的每一列向量的操作相同(乘和累加),但是作用于不同的数据上。 TPU GPU采用单指令多线程进行处理,每个线程同步的在不同的数据上执 FPGA 行相同的指令流,可以并行化计算。 SOC ●针对上述例子,GPU可以同时使用8个线程进行并行计算。每个线程可 在每个周期内并行执行一次乘加计算,多个线程独立并行执行。多线 程执行流程如下图所示,理想情况下8个周期即可输出所有点
人工智能芯片发展历程 GPU单指令多线程处理: 可以观察到,对于展开后的矩阵相乘,左矩阵的每个行向量与右矩阵 的每一列向量的操作相同(乘和累加),但是作用于不同的数据上。 GPU采用单指令多线程进行处理,每个线程同步的在不同的数据上执 行相同的指令流,可以并行化计算。 针对上述例子,GPU可以同时使用8个线程进行并行计算。每个线程可 在每个周期内并行执行一次乘加计算,多个线程独立并行执行。多线 程执行流程如下图所示,理想情况下8个周期即可输出所有点。 GPU 背景 CPU TPU FPGA SOC
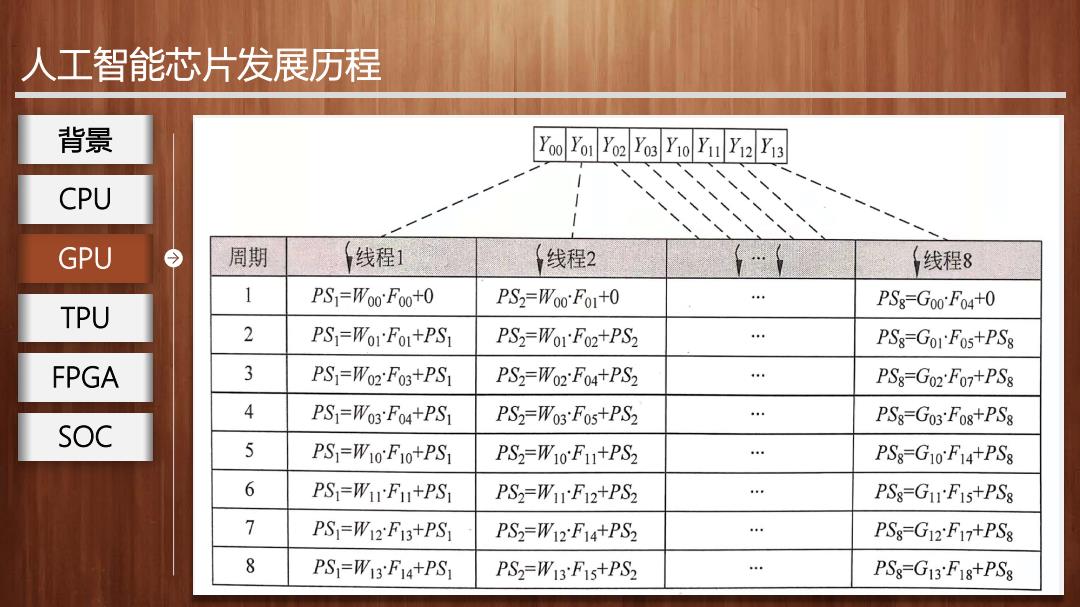
人工智能芯片发展历程 背景 Yoo Yo1 Yo2Yos Y1o Y11Y12Y13 CPU GPU 周期 线程1 线程2 线程8 1 PS]=Woo:F0o+0 PS2=Woo:Fo+0 PS8=Goo:F04+0 TPU 2 PS=WoIFol+PS1 PS2=WOrF02+PS2 PS8-GO1F0s+PS8 FPGA 3 PS]=W02F03+PS1 PS2=W02F04+PS2 4 PS8-G02 F07+PS8 4 PS]=W03:F04+PS1 PS2=W03Fos+PS2 PS8-G03Fo8+PS8 SOC 5 PS]=W10F10+PS1 PS2=W10F+PS2 PS8-G10:F14+PS8 6 PS=WIF+PS1 PS2=W1F12+PS2 PSS=G11F1s+PS8 7 PS=W12F13+PS P.S2=W12F14+PS2 PSs-G12F17+PS8 8 PS=W13F14+PS1 PS2=W13F1s+PS2 … PS8-G13:F18+PS8
人工智能芯片发展历程 x GPU 背景 CPU TPU FPGA SOC
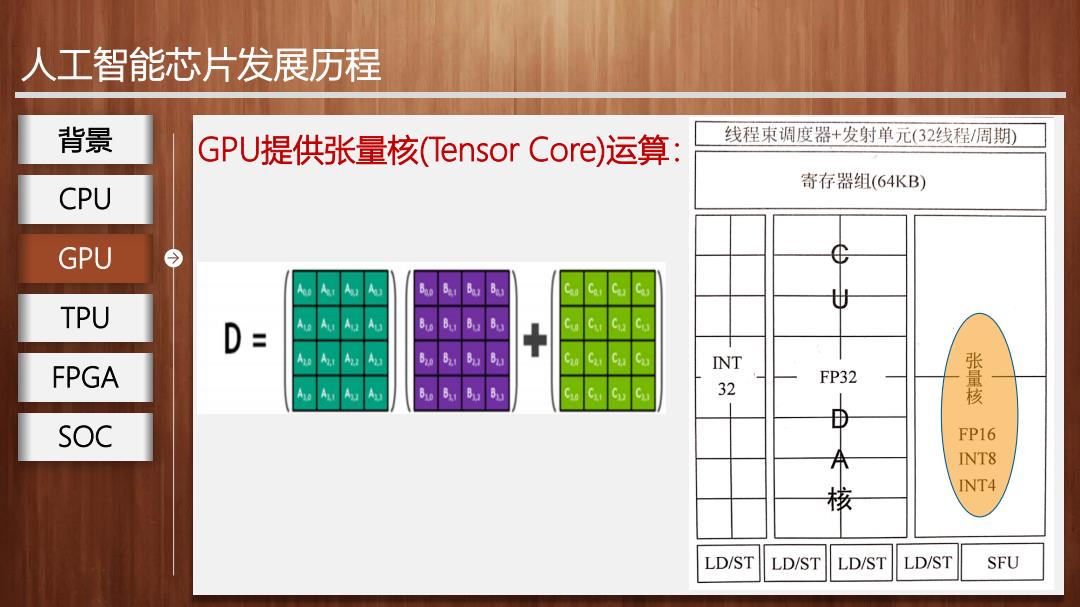
人工智能芯片发展历程 背景 GPU提供张量核(Tensor Core)运算: 线程束调度器+发射单元(32线程/周期) 寄存器组(64KB) CPU GPU TPU INT FPGA FP32 32 张量核 SOC FP16 INT8 核 INT4 LD/ST LD/ST LD/ST LD/ST SFU
人工智能芯片发展历程 x GPU提供张量核(Tensor Core)运算: GPU 背景 CPU TPU FPGA SOC

人工智能芯片发展历程 背景 GPU、CPU设计比对 CPU GPU主要面对类型高度统一、相互无依赖的大规模数据和不需打断 GPU 的纯净计算环境。 TPU ·拥有若干由数以干计的更小的核心(专为同时处理多重任务而设计) FPGA 组成的大规模并行计算架构。 ·基于大吞吐量设计。 SOC ·擅长计算密集和易于并行的程序
人工智能芯片发展历程 GPU、CPU设计比对 GPU主要面对类型高度统一、相互无依赖的大规模数据和不需打断 的纯净计算环境。 拥有若干由数以千计的更小的核心(专为同时处理多重任务而设计) 组成的大规模并行计算架构。 基于大吞吐量设计。 擅长计算密集和易于并行的程序。 GPU 背景 CPU TPU FPGA SOC