
6.11无监督学习 聚类算法 K近邻 主成分分析
6.11 无监督学习 聚类算法 K近邻 主成分分析

引言 口无监督算法处理的是那些没有标记的数据: ·缺乏足够的先验知识,因此难以人工标注类别: ·进行人工类别标注的成本太高。 口希望计算机能代我们(部分)完成这些工作,或至少提供一些帮助。 常见的应用背景包括: ·从庞大的样本集合中选出一些具有代表性的加以标注用于分类器的训练: ·先将所有样本自动分为不同的类别,再由人类对这些类别进行标注; ·在无类别信息情况下,寻找好的特征。 口常用算法 ·主成分分析方法PCA等,等距映射方法、局部线性嵌入方法、拉普拉斯 特征映射方法、黑塞局部线性嵌入方法和局部切空间排列方法等
引言 无监督算法处理的是那些没有标记的数据: • 缺乏足够的先验知识,因此难以人工标注类别; • 进行人工类别标注的成本太高。 希望计算机能代我们(部分)完成这些工作,或至少提供一些帮助。 常见的应用背景包括: • 从庞大的样本集合中选出一些具有代表性的加以标注用于分类器的训练; • 先将所有样本自动分为不同的类别,再由人类对这些类别进行标注; • 在无类别信息情况下,寻找好的特征。 常用算法 • 主成分分析方法PCA等,等距映射方法、局部线性嵌入方法、拉普拉斯 特征映射方法、黑塞局部线性嵌入方法和局部切空间排列方法等
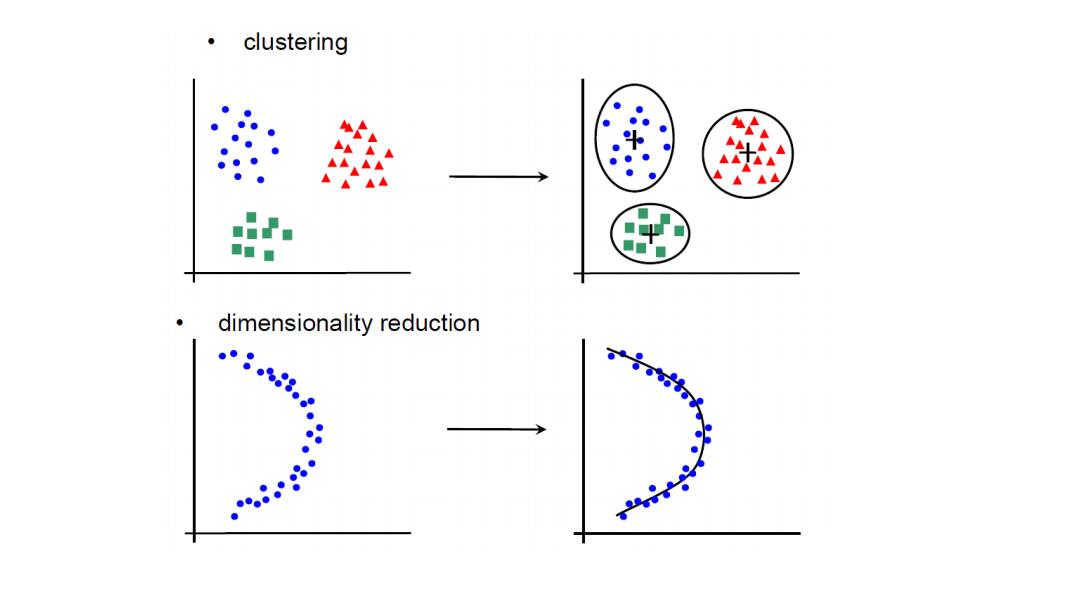
clustering ■■■ dimensionality reduction ● ●● ● ●● ● ●●●●
6.11.1聚类算法(Clustering) ·聚类算法是一种在数据集中找到相似数据子集(即clusters)的方法: ·它把数据样本按照彼此的相似或靠近程度分组,近的分为一组,远的分 成另外的组 ·属于无监督学习,因为哪些数据应该分成一组并没有所谓正确的答案 ·由于历史原因,聚类算法通常被等价成无监督学习 市场分割 社交关系分组
6.11.1 聚类算法(Clustering) • 聚类算法是一种在数据集中找到相似数据子集(即clusters)的方法: • 它把数据样本按照彼此的相似或靠近程度分组,近的分为一组,远的分 成另外的组 • 属于无监督学习,因为哪些数据应该分成一组并没有所谓正确的答案 • 由于历史原因,聚类算法通常被等价成无监督学习

聚类算法的分类 ·划分方法 ·划分聚类算法通过优化误差函数把数据集分割为K个部分,它需要K作为 输人参数。 ·典型的分割聚类算法有K-means算法,K-medoids.算法、CLARANS算法。 ·层次方法 ·层次聚类由不同层次的分割聚类组成,层次之间的分割具有嵌套的关系。 ·不需要输入参数,这是它优于分割聚类算法的一个明显的优点,其缺点 是终止条件必须具体指定。 ·典型的分层聚类算法有BIRCH算法、DBSCAN算法和CURE算法等。 ·基于密度的聚类方法 ·基于网格的聚类方法 ·具有模型的聚类方法
聚类算法的分类 • 划分方法 • 划分聚类算法通过优化误差函数把数据集分割为K个部分,它需要K作为 输人参数。 • 典型的分割聚类算法有K-means算法, K-medoids算法、CLARANS算法。 • 层次方法 • 层次聚类由不同层次的分割聚类组成,层次之间的分割具有嵌套的关系。 • 不需要输入参数,这是它优于分割聚类 算法的一个明显的优点,其缺点 是终止条件必须具体指定。 • 典型的分层聚类算法有BIRCH算法、DBSCAN算法和CURE算法等。 • 基于密度的聚类方法 • 基于网格的聚类方法 • 具有模型的聚类方法 • …