实验二一元回归模型 【实验目的】 通过本实验,熟练掌握简单(一元)线性回归模型的文档建立和数据录入,熟悉viw 对象操作和函数应用,熟悉viWs进行回归分析的操作步骤,熟练掌握一元线性回归模型 的建模、检验和预测等方法。学会用Eviews软件的回归分析功能分析和解决实际问题。 【实验内容】 一、建立我国城镇居民平均消费支出模型(2-2-1.f1) 二、建立我国财政收入模型(2-2-2.w1) 【实验步骤】 一、建立我国城镇居民平均消费支出模型(2-2-1.F1) 问题概述:研究全国31个省市2002年城市居民家庭平均每人消费支出(Y)与收入(X) 的数量关系(单位:亿元)。 1.建立工作文件和序列。选择Eviews主菜单File/New/Workfile,进而在文件创建对 话框中做如图2-2-1的设置,确定后再选择0 bject//New object建立两个序列(图2-2-2) Vorkfile Create ■☒ Workfile structure type Data range Unstructured /Undated Observations:31 (optiona wf:2-21 Page: 图2-2-1创建工作文件 白EVievs G回☒ File Edit View Froe Quick Options Yindow Help generate Series. Manage Links A Formulae. Eetch from DB. 图2-2-2建立序列
10 实验二 一元回归模型 【实验目的】 通过本实验,熟练掌握简单(一元)线性回归模型的文档建立和数据录入,熟悉 Eviews 对象操作和函数应用,熟悉 Eviews 进行回归分析的操作步骤,熟练掌握一元线性回归模型 的建模、检验和预测等方法。学会用 Eviews 软件的回归分析功能分析和解决实际问题。 【实验内容】 一、建立我国城镇居民平均消费支出模型(2-2-1.wf1) 二、建立我国财政收入模型(2-2-2.wf1) 【实验步骤】 一、建立我国城镇居民平均消费支出模型(2-2-1.WF1) 问题概述:研究全国 31 个省市 2002 年城市居民家庭平均每人消费支出(Y)与收入(X) 的数量关系(单位:亿元)。 1. 建立工作文件和序列。选择 Eviews 主菜单 File/New/Workfile,进而在文件创建对 话框中做如图 2-2-1 的设置,确定后再选择 Object/New object 建立两个序列(图 2-2-2)。 图 2-2-1 创建工作文件 图 2-2-2 建立序列
2.通过序列视图(viw)考察数据的特征:趋势图、散点图、描述统计量和相关系数。 通过序列窗口中的VieW功能键下Graphy/Line,Graph/Scatter,Descriptive statistics, correlations菜单来完成:操作方式如图2-2-3所示, rkf Group:GROUP01 Workfile:2-2-1:Untitle viewlProc]object Print Name Freeze DefaultSort Transp 卫ated Data Table 56 Graph. 68 Descriptive Stats ovr1ncAys1s -ay Tabulation. ests of Equality 16 Principal Components. Cress Correlation (2). 图2-2-3群窗口中的View功能键的下拉菜单 3.线性回归模型的估计(命令方式和菜单方式) (1)命令方式:L5yCX,如图2-2-4所示 EViews 回☒ 图2-2-4命令方式估计模型 (2)菜单方式 ①点击Quick\Estimate Equation,如图2-2-5所示。 EVievs te Series. Show Enpty Group (Edit Series) Series statistics Group Statistics stinate卫qustior Estinate yAR. 图2-2-5建立方程对象估计模型
11 2.通过序列视图(view)考察数据的特征:趋势图、散点图、描述统计量和相关系数。 通过序列窗口中的 View 功能键下 Graph/Line,Graph/Scatter,Descriptive statistics, correlations 菜单来完成;操作方式如图 2-2-3 所示。 图 2-2-3 群窗口中的 View 功能键的下拉菜单 3.线性回归模型的估计(命令方式和菜单方式) (1)命令方式:LS Y C X,如图 2-2-4 所示。 图 2-2-4 命令方式估计模型 (2)菜单方式 ①点击 Quick\Estimate Equation,如图 2-2-5 所示。 图 2-2-5 建立方程对象估计模型

②在弹出的方程设定框内输入模型:YCX或Y=C(1)+C(2)机,可参考图1-1-9。 确定后可得到模型参数估计的结果,如图2-2-6所示。 4.方程对象窗口及功能 图2-2-6表明,F统计量为421.90,方程具有显著性:而截距项的显著性检验不能通过 (件随概率0.334>0.05),从经济意义上考虑自发性消费是应该有的一部分,可以保留战距 项:X系数的显著不为零,说明城市人均可支配收入对消费支出有显著影响:可决系数为 0.9357也表明模型总体拟合较好。 在方程(Equation)窗口中(图2-2-6),VieW(视图)、Estimate(估计、Forecast (预测)、Stats(统计量)和Resids(残差)是常用的按钮,点击相应按钮可以执行相应 的功能。 ▣Equation:EQ01 Vorkfi1e:2-2-1:mtit.□▣☒ Miew Proc]Object Print Name Freeze Estimate Forecast Stats Resids Denendentvarnable:X Date:07/31/09 Time:17:04 5n2me603gegrvatons.31 Variable Coemicient Std.Error +Statistic Prob. 28898628 83889 R-squared 0.935685 5982.476 squared 003159 Sum squared resid 4950317 15.0404 F-3iatod 21902 1481439 Prob(F-statistic) 0.000000 图2-2-6模型估计结果 5.残差项正态分布检验 回归的残差项服从正态分布是建立模型的基本要求,在工作文件目录中双击r©sid序 列,在打开的窗口中点击View/Descriptive Statistics/Histogram and Stats,.如图2-2-7 所示,可以得到柱状分布图、Jarque-Bera统计量和它的伴随概率等统计量,如图2-2-8所 示。图中Jarque-Bera统计量的伴随概率(Probability)大于0.05,则认为残差服从正态 分布。也可从偏度(Skewness)和峰度(Kurtosis)考察残差序列分布的特点,由偏度值 0.7439可知,其概率分布为左偏(值为0是为对称分布):由峰度值3.8902可知,其比标
12 ②在弹出的方程设定框内输入模型:Y C X 或 Y=C(1)+C(2)*X,可参考图 1-1-9。 确定后可得到模型参数估计的结果,如图 2-2-6 所示。 4.方程对象窗口及功能 图 2-2-6 表明,F 统计量为 421.90,方程具有显著性;而截距项的显著性检验不能通过 (伴随概率 0.334>0.05),从经济意义上考虑自发性消费是应该有的一部分,可以保留截距 项;X 系数的显著不为零,说明城市人均可支配收入对消费支出有显著影响;可决系数为 0.9357 也表明模型总体拟合较好。 在方程(Equation)窗口中(图 2-2-6),View(视图)、Estimate(估计)、Forecast (预测)、Stats(统计量)和 Resids(残差)是常用的按钮,点击相应按钮可以执行相应 的功能。 图 2-2-6 模型估计结果 5.残差项正态分布检验 回归的残差项服从正态分布是建立模型的基本要求。在工作文件目录中双击 resid 序 列,在打开的窗口中点击 View/Descriptive Statistics/Histogram and Stats,如图 2-2-7 所示,可以得到柱状分布图、Jarque-Bera 统计量和它的伴随概率等统计量,如图 2-2-8 所 示。图中 Jarque-Bera 统计量的伴随概率(Probability)大于 0.05,则认为残差服从正态 分布。 也可从偏度(Skewness)和峰度(Kurtosis)考察残差序列分布的特点,由偏度值 0.7439 可知,其概率分布为左偏(值为 0 是为对称分布);由峰度值 3.8902 可知,其比标
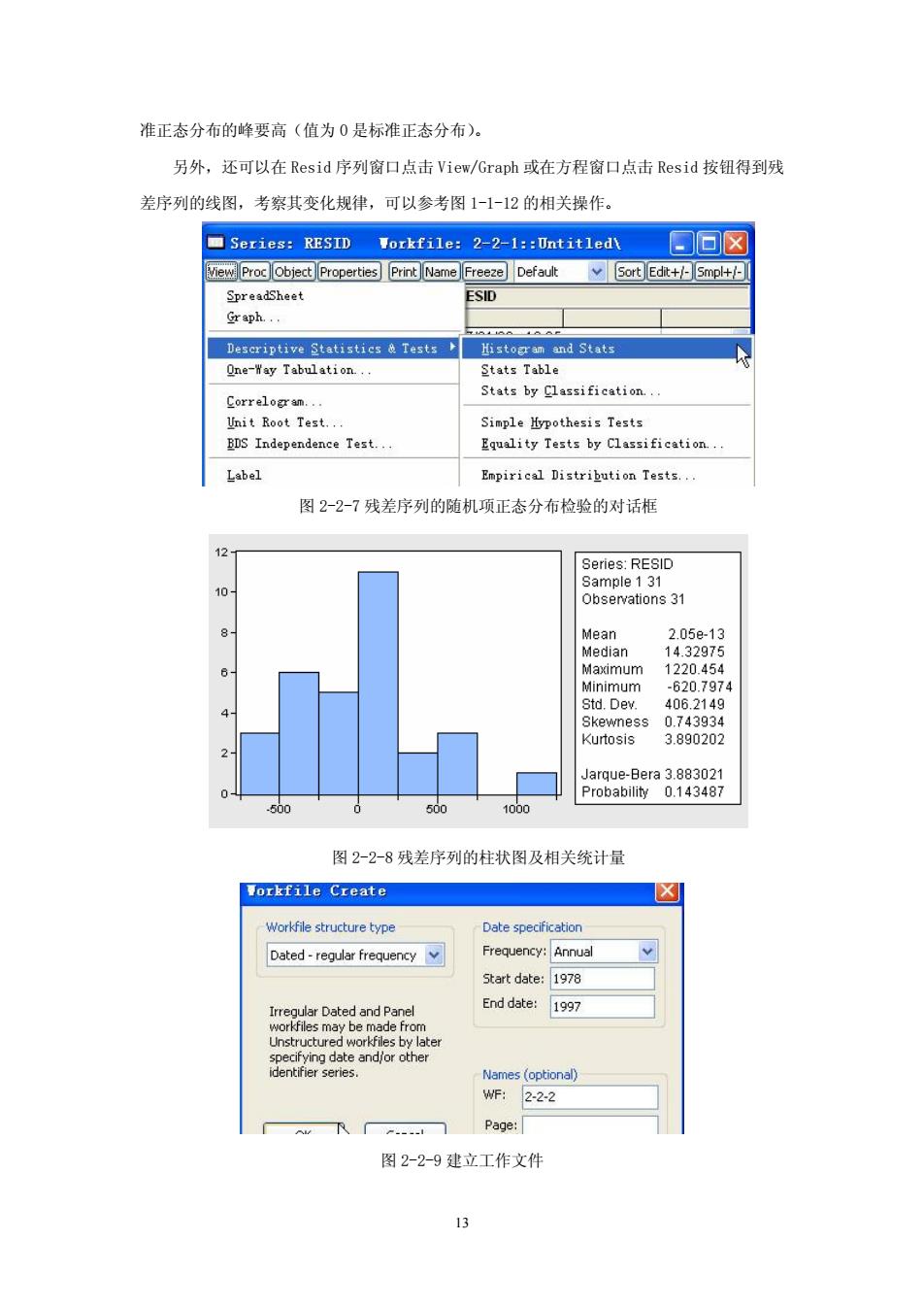
准正态分布的峰要高(值为0是标准正态分布)。 另外,还可以在Resid序列窗口点击View/Graph或在方程窗口点击Resid按纽得到残 差序列的线图,考察其变化规律,可以参考图1一1-12的相关操作。 ▣Series:RESID Workfi1e:2-2-1:atit1ed回☒ View Proc object (Properties Print Name Freeze Edt+/-Smpl+/- ESID Descriptive Statistics Tests Hstoran and Stats One-Yay Tabulation +。tT1。 Stats by Classification. Correlogran. Unit Root Test. Sinple Hypothesis Tests BDS Independence Text. Equality Tests by Classification Label Empirical Distribution Tests. 图2-2-7残差序列的随机项正态分布检验的对话框 Observations 31 Mean kewne5s0.74393 Kurtosis 3.89020 500 1000 图2-2-8残差序列的柱状图及相关统计量 Vorkfile create ☒ Date Dated-regular frequency Frequency:Annual Start date:1978 teoarDa edandpanel End date:1997 Page: 图2-2-9建立工作文件
13 准正态分布的峰要高(值为 0 是标准正态分布)。 另外,还可以在 Resid 序列窗口点击 View/Graph 或在方程窗口点击 Resid 按钮得到残 差序列的线图,考察其变化规律,可以参考图 1-1-12 的相关操作。 图 2-2-7 残差序列的随机项正态分布检验的对话框 图 2-2-8 残差序列的柱状图及相关统计量 图 2-2-9 建立工作文件
二、建立我国财政收入模型(2-2-2.wf1) 问题概述:研究中国1978~1997年的财政收入(Y)和国内生产总值(X)的数量关系。 (单位:亿元) 1.建立工作文件 在命令窗口键入CREATE,弹出创建文件对话框,做如图2-2-9的设置。 2.输入数据 在命令窗口链入:DATA Y X,即可打开群窗口,输入相关数据,如图2-2-10所示。 图EVievs Eile Edit gbject View Proc Quick Options Window Help data xy ■crop:NTITLED Workfile:UNTITLED:Intitled\间区 iew Print Name Freeze DefaultScrt Transpose Edit+-Smpl+ 图2-2-10命令方式建立群 3.图形分析 (1)在命令窗口健入PL0TYX,得到趋势图,也可参考图2-1-17的相关操作。 (2)在命令窗口键入SCAT X Y,得到两个序列的相关图,如图2-2-11。 9.000 8.000 7.000 6.000 400 30 2.000 20.000 0.006000 图2-2-11财政收入()与国内生产总值()的相关图 4.估计线性回归模型 (1)命令方式LS Y C X,与图2-2-4操作相同 (2)菜单方式
14 二、建立我国财政收入模型(2-2-2.wf1) 问题概述:研究中国 1978~1997 年的财政收入(Y)和国内生产总值(X)的数量关系。 (单位:亿元) 1.建立工作文件 在命令窗口键入 CREATE,弹出创建文件对话框,做如图 2-2-9 的设置。 2.输入数据 在命令窗口键入:DATA Y X,即可打开群窗口,输入相关数据,如图 2-2-10 所示。 图 2-2-10 命令方式建立群 3.图形分析 (1)在命令窗口键入 PLOT Y X,得到趋势图,也可参考图 2-1-17 的相关操作。 (2)在命令窗口键入 SCAT X Y,得到两个序列的相关图,如图 2-2-11。 图 2-2-11 财政收入(Y)与国内生产总值(X)的相关图 4.估计线性回归模型 (1)命令方式 LS Y C X,与图 2-2-4 操作相同。 (2)菜单方式