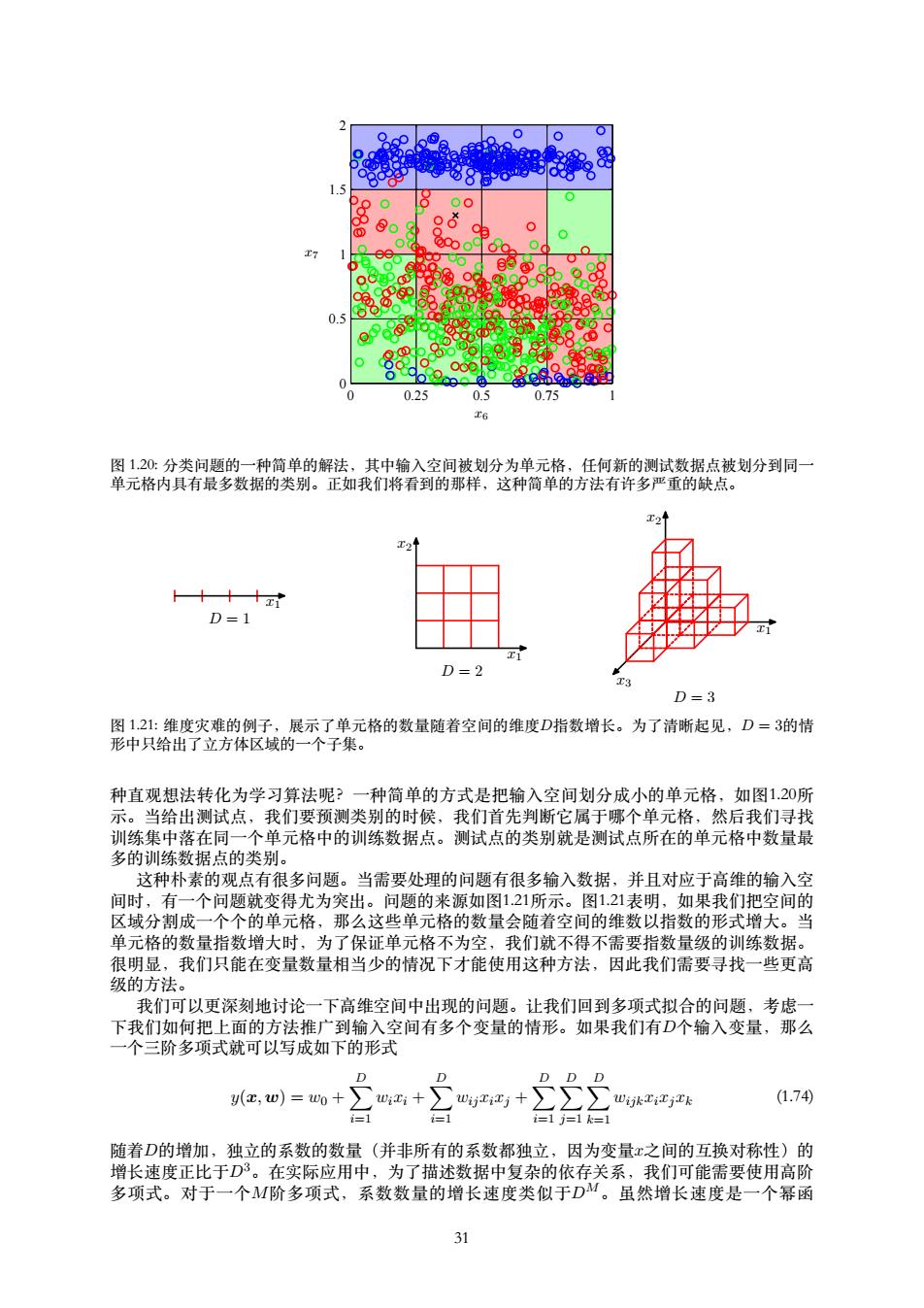
● 880 1.5 ● 0.5 ●G 0 ● 0 0.25 0.5 0.75 图120:分类问题的一种简单的解法,其中输入空间被划分为单元格,任何新的测试数据点被划分到同一 单元格内具有最多数据的类别。正如我们将看到的那样,这种简单的方法有许多严重的缺点。 T21 24 十+十xi D=1 2 D=2 D=3 图121:维度灾难的例子,展示了单元格的数量随着空间的维度D指数增长。为了清晰起见,D=3的情 形中只给出了立方体区域的一个子集。 种直观想法转化为学习算法呢?一种简单的方式是把输入空间划分成小的单元格,如图1.20所 示。当给出测试点,我们要预测类别的时候,我们首先判断它属于哪个单元格,然后我们寻找 训练集中落在同一个单元格中的训练数据点。测试点的类别就是测试点所在的单元格中数量最 多的训练数据点的类别。 这种朴素的观点有很多问题。当需要处理的问题有很多输入数据,并且对应于高维的输入空 间时,有一个问题就变得尤为突出。问题的来源如图1.21所示。图1.21表明,如果我们把空间的 区域分割成一个个的单元格,那么这些单元格的数量会随着空间的维数以指数的形式增大。当 单元格的数量指数增大时,为了保证单元格不为空,我们就不得不需要指数量级的训练数据。 很明显,我们只能在变量数量相当少的情况下才能使用这种方法,因此我们需要寻找一些更高 级的方法。 我们可以更深刻地讨论一下高维空间中出现的问题。让我们回到多项式拟合的问题,考虑一 下我们如何把上面的方法推广到输入空间有多个变量的情形。如果我们有D个输入变量,那么 一个三阶多项式就可以写成如下的形式 DDD y(,w)=w0+ +∑“r+∑∑∑ (1.74) i=1 -1 i=1j=1k=1 随着D的增加,独立的系数的数量(并非所有的系数都独立,因为变量x之间的互换对称性)的 增长速度正比于D3。在实际应用中,为了描述数据中复杂的依存关系,我们可能需要使用高阶 多项式。对于一个M阶多项式,系数数量的增长速度类似于D“。虽然增长速度是一个幂函 31
x6 x7 0 0.25 0.5 0.75 1 0 0.5 1 1.5 2 图 1.20: 分类问题的⼀种简单的解法,其中输⼊空间被划分为单元格,任何新的测试数据点被划分到同⼀ 单元格内具有最多数据的类别。正如我们将看到的那样,这种简单的⽅法有许多严重的缺点。 x1 D = 1 x1 x2 D = 2 x1 x2 x3 D = 3 图 1.21: 维度灾难的例⼦,展⽰了单元格的数量随着空间的维度D指数增长。为了清晰起见,D = 3的情 形中只给出了⽴⽅体区域的⼀个⼦集。 种直观想法转化为学习算法呢?⼀种简单的⽅式是把输⼊空间划分成⼩的单元格,如图1.20所 ⽰。当给出测试点,我们要预测类别的时候,我们⾸先判断它属于哪个单元格,然后我们寻找 训练集中落在同⼀个单元格中的训练数据点。测试点的类别就是测试点所在的单元格中数量最 多的训练数据点的类别。 这种朴素的观点有很多问题。当需要处理的问题有很多输⼊数据,并且对应于⾼维的输⼊空 间时,有⼀个问题就变得尤为突出。问题的来源如图1.21所⽰。图1.21表明,如果我们把空间的 区域分割成⼀个个的单元格,那么这些单元格的数量会随着空间的维数以指数的形式增⼤。当 单元格的数量指数增⼤时,为了保证单元格不为空,我们就不得不需要指数量级的训练数据。 很明显,我们只能在变量数量相当少的情况下才能使⽤这种⽅法,因此我们需要寻找⼀些更⾼ 级的⽅法。 我们可以更深刻地讨论⼀下⾼维空间中出现的问题。让我们回到多项式拟合的问题,考虑⼀ 下我们如何把上⾯的⽅法推⼴到输⼊空间有多个变量的情形。如果我们有D个输⼊变量,那么 ⼀个三阶多项式就可以写成如下的形式 y(x, w) = w0 + ∑ D i=1 wixi + ∑ D i=1 wijxixj + ∑ D i=1 ∑ D j=1 ∑ D k=1 wijkxixjxk (1.74) 随着D的增加,独⽴的系数的数量(并⾮所有的系数都独⽴,因为变量x之间的互换对称性)的 增长速度正⽐于D3。在实际应⽤中,为了描述数据中复杂的依存关系,我们可能需要使⽤⾼阶 多项式。对于⼀个M阶多项式,系数数量的增长速度类似于DM。虽然增长速度是⼀个幂函 31
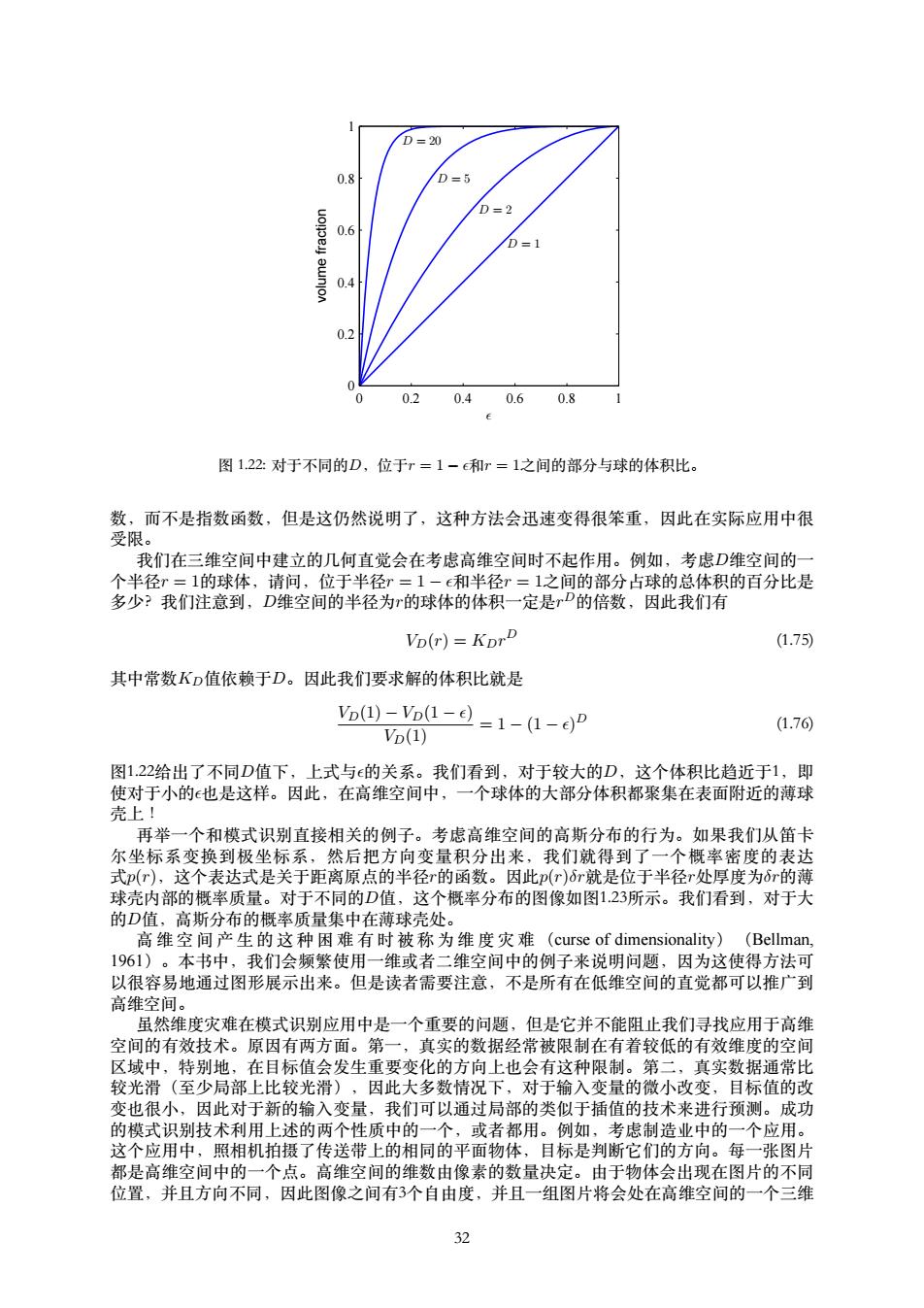
D=20 0.8 D=5 D=2 0.6 D=1 eunjoA 0.4 0.2 0 0 0.20.40.60.8 图1.22:对于不同的D,位于r=1-和r=1之间的部分与球的体积比。 数,而不是指数函数,但是这仍然说明了,这种方法会迅速变得很笨重,因此在实际应用中很 受限。 我们在三维空间中建立的几何直觉会在考虑高维空间时不起作用。例如,考虑D维空间的一 个半径r=1的球体,请问,位于半径r=1-和半径r=1之间的部分占球的总体积的百分比是 多少?我们注意到,D维空间的半径为的球体的体积一定是rD的倍数,因此我们有 VD(r)=KDrD (1.75) 其中常数KD值依赖于D。因此我们要求解的体积比就是 Vo)-Vo-Q=1-(1-)P (1.76) VD(1)】 图1.22给出了不同D值下,上式与的关系。我们看到,对于较大的D,这个体积比趋近于1,即 使对于小的也是这样。因此,在高维空间中,一个球体的大部分体积都聚集在表面附近的薄球 壳上! 再举一个和模式识别直接相关的例子。考虑高维空间的高斯分布的行为。如果我们从笛卡 尔坐标系变换到极坐标系,然后把方向变量积分出来,我们就得到了一个概率密度的表达 式p(r),这个表达式是关于距离原点的半径r的函数。因此p(r)6r就是位于半径r处厚度为6r的薄 球壳内部的概率质量。对于不同的D值,这个概率分布的图像如图123所示。我们看到,对于大 的D值,高斯分布的概率质量集中在薄球壳处。 高维空间产生的这种困难有时被称为维度灾难(curse of dimensionality)(Bellman, 1961)。本书中,我们会频繁使用一维或者二维空间中的例子来说明问题,因为这使得方法可 以很容易地通过图形展示出来。但是读者需要注意,不是所有在低维空间的直觉都可以推广到 高维空间。 虽然维度灾难在模式识别应用中是一个重要的问题,但是它并不能阻止我们寻找应用于高维 空间的有效技术。原因有两方面。第一,真实的数据经常被限制在有着较低的有效维度的空间 区域中,特别地,在目标值会发生重要变化的方向上也会有这种限制。第二,真实数据通常比 较光滑(至少局部上比较光滑),因此大多数情况下,对于输入变量的微小改变,目标值的改 变也很小,因此对于新的输入变量,我们可以通过局部的类似于插值的技术来进行预测。成功 的模式识别技术利用上述的两个性质中的一个,或者都用。例如,考虑制造业中的一个应用。 这个应用中,照相机拍摄了传送带上的相同的平面物体,目标是判断它们的方向。每一张图片 都是高维空间中的一个点。高维空间的维数由像素的数量决定。由于物体会出现在图片的不同 位置,并且方向不同,因此图像之间有3个自由度,并且一组图片将会处在高维空间的一个三维 32
² volume fraction D = 1 D = 2 D = 5 D = 20 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 图 1.22: 对于不同的D,位于r = 1 − ϵ和r = 1之间的部分与球的体积⽐。 数,⽽不是指数函数,但是这仍然说明了,这种⽅法会迅速变得很笨重,因此在实际应⽤中很 受限。 我们在三维空间中建⽴的⼏何直觉会在考虑⾼维空间时不起作⽤。例如,考虑D维空间的⼀ 个半径r = 1的球体,请问,位于半径r = 1 − ϵ和半径r = 1之间的部分占球的总体积的百分⽐是 多少?我们注意到,D维空间的半径为r的球体的体积⼀定是r D的倍数,因此我们有 VD(r) = KDr D (1.75) 其中常数KD值依赖于D。因此我们要求解的体积⽐就是 VD(1) − VD(1 − ϵ) VD(1) = 1 − (1 − ϵ) D (1.76) 图1.22给出了不同D值下,上式与ϵ的关系。我们看到,对于较⼤的D,这个体积⽐趋近于1,即 使对于⼩的ϵ也是这样。因此,在⾼维空间中,⼀个球体的⼤部分体积都聚集在表⾯附近的薄球 壳上! 再举⼀个和模式识别直接相关的例⼦。考虑⾼维空间的⾼斯分布的⾏为。如果我们从笛卡 尔坐标系变换到极坐标系,然后把⽅向变量积分出来,我们就得到了⼀个概率密度的表达 式p(r),这个表达式是关于距离原点的半径r的函数。因此p(r)δr就是位于半径r处厚度为δr的薄 球壳内部的概率质量。对于不同的D值,这个概率分布的图像如图1.23所⽰。我们看到,对于⼤ 的D值,⾼斯分布的概率质量集中在薄球壳处。 ⾼ 维 空 间 产 ⽣ 的 这 种 困 难 有 时 被 称 为 维 度 灾 难 (curse of dimensionality) (Bellman, 1961)。本书中,我们会频繁使⽤⼀维或者⼆维空间中的例⼦来说明问题,因为这使得⽅法可 以很容易地通过图形展⽰出来。但是读者需要注意,不是所有在低维空间的直觉都可以推⼴到 ⾼维空间。 虽然维度灾难在模式识别应⽤中是⼀个重要的问题,但是它并不能阻⽌我们寻找应⽤于⾼维 空间的有效技术。原因有两⽅⾯。第⼀,真实的数据经常被限制在有着较低的有效维度的空间 区域中,特别地,在⽬标值会发⽣重要变化的⽅向上也会有这种限制。第⼆,真实数据通常⽐ 较光滑(⾄少局部上⽐较光滑),因此⼤多数情况下,对于输⼊变量的微⼩改变,⽬标值的改 变也很⼩,因此对于新的输⼊变量,我们可以通过局部的类似于插值的技术来进⾏预测。成功 的模式识别技术利⽤上述的两个性质中的⼀个,或者都⽤。例如,考虑制造业中的⼀个应⽤。 这个应⽤中,照相机拍摄了传送带上的相同的平⾯物体,⽬标是判断它们的⽅向。每⼀张图⽚ 都是⾼维空间中的⼀个点。⾼维空间的维数由像素的数量决定。由于物体会出现在图⽚的不同 位置,并且⽅向不同,因此图像之间有3个⾃由度,并且⼀组图⽚将会处在⾼维空间的⼀个三维 32
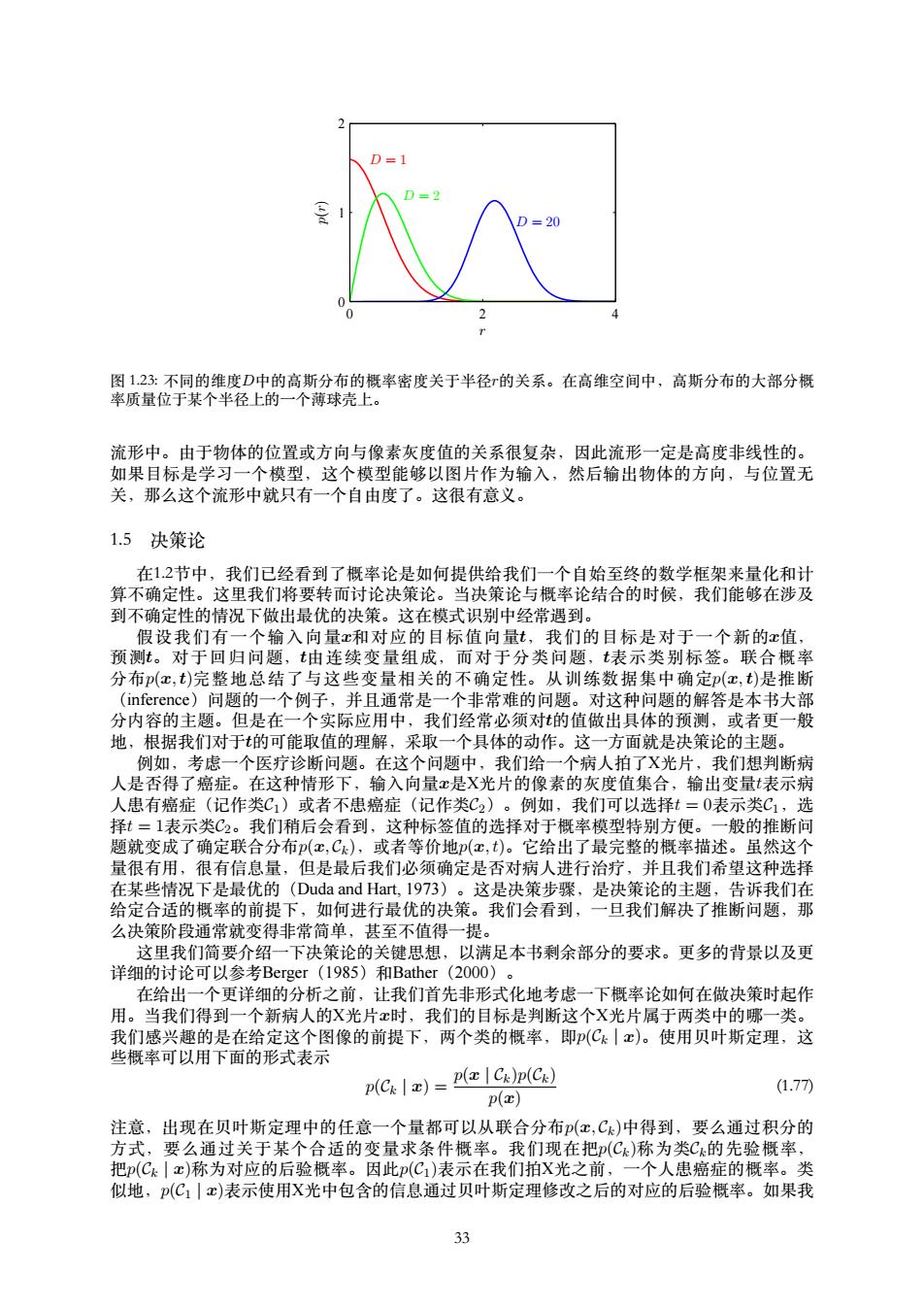
D=1 D=2 2 图123:不同的维度D中的高斯分布的概率密度关于半径r的关系。在高维空间中,高斯分布的大部分概 率质量位于某个半径上的一个薄球壳上。 流形中。由于物体的位置或方向与像素灰度值的关系很复杂,因此流形一定是高度非线性的。 如果目标是学习一个模型,这个模型能够以图片作为输入,然后输出物体的方向,与位置无 关,那么这个流形中就只有一个自由度了。这很有意义。 1.5决策论 在1.2节中,我们已经看到了概率论是如何提供给我们一个自始至终的数学框架来量化和计 算不确定性。这里我们将要转而讨论决策论。当决策论与概率论结合的时候,我们能够在涉及 到不确定性的情况下做出最优的决策。这在模式识别中经常遇到。 假设我们有一个输入向量x和对应的目标值向量t,我们的目标是对于一个新的x值, 预测t。对于回归问题,由连续变量组成,而对于分类问题,t表示类别标签。联合概率 分布(x,t)完整地总结了与这些变量相关的不确定性。从训练数据集中确定(x,t)是推断 (inference)问题的一个例子,并且通常是一个非常难的问题。对这种问题的解答是本书大部 分内容的主题。但是在一个实际应用中,我们经常必须对的值做出具体的预测,或者更一般 地,根据我们对于t的可能取值的理解,采取一个具体的动作。这一方面就是决策论的主题。 例如,考虑一个医疗诊断问题。在这个问题中,我们给一个病人拍了X光片,我们想判断病 人是否得了癌症。在这种情形下,输入向量x是X光片的像素的灰度值集合,输出变量表示病 人患有癌症(记作类C1)或者不患癌症(记作类C2)。例如,我们可以选择t=0表示类C,选 择t=1表示类C2。我们稍后会看到,这种标签值的选择对于概率模型特别方便。一般的推断问 题就变成了确定联合分布p(c,Ck),或者等价地(c,t)。它给出了最完整的概率描述。虽然这个 量很有用,很有信息量,但是最后我们必须确定是否对病人进行治疗,并且我们希望这种选择 在某些情况下是最优的(Duda and Hart,I973)。这是决策步骤,是决策论的主题,告诉我们在 给定合适的概率的前提下,如何进行最优的决策。我们会看到,一旦我们解决了推断问题,那 么决策阶段通常就变得非常简单,甚至不值得一提。 这里我们简要介绍一下决策论的关键思想,以满足本书剩余部分的要求。更多的背景以及更 详细的讨论可以参考Berger(1985)和Bather(2000)。 在给出一个更详细的分析之前,让我们首先非形式化地考虑一下概率论如何在做决策时起作 用。当我们得到一个新病人的X光片x时,我们的目标是判断这个X光片属于两类中的哪一类。 我们感兴趣的是在给定这个图像的前提下,两个类的概率,即(Ck|x)。使用贝叶斯定理,这 些概率可以用下面的形式表示 p(Ck)=p(C)p(Ck) (1.77) p(x) 注意,出现在贝叶斯定理中的任意一个量都可以从联合分布(c,Ck)中得到,要么通过积分的 方式,要么通过关于某个合适的变量求条件概率。我们现在把(Ck)称为类Ck的先验概率, 把(C|x)称为对应的后验概率。因此p(C)表示在我们拍X光之前,一个人患癌症的概率。类 似地,(C1|x)表示使用X光中包含的信息通过贝叶斯定理修改之后的对应的后验概率。如果我 33
D = 1 D = 2 D = 20 r p(r) 0 2 4 0 1 2 图 1.23: 不同的维度D中的⾼斯分布的概率密度关于半径r的关系。在⾼维空间中,⾼斯分布的⼤部分概 率质量位于某个半径上的⼀个薄球壳上。 流形中。由于物体的位置或⽅向与像素灰度值的关系很复杂,因此流形⼀定是⾼度⾮线性的。 如果⽬标是学习⼀个模型,这个模型能够以图⽚作为输⼊,然后输出物体的⽅向,与位置⽆ 关,那么这个流形中就只有⼀个⾃由度了。这很有意义。 1.5 决策论 在1.2节中,我们已经看到了概率论是如何提供给我们⼀个⾃始⾄终的数学框架来量化和计 算不确定性。这⾥我们将要转⽽讨论决策论。当决策论与概率论结合的时候,我们能够在涉及 到不确定性的情况下做出最优的决策。这在模式识别中经常遇到。 假设我们有⼀个输⼊向量x和对应的⽬标值向量t,我们的⽬标是对于⼀个新的x值, 预测t。对于回归问题,t由连续变量组成,⽽对于分类问题,t表⽰类别标签。联合概率 分布p(x, t)完整地总结了与这些变量相关的不确定性。从训练数据集中确定p(x, t)是推断 (inference)问题的⼀个例⼦,并且通常是⼀个⾮常难的问题。对这种问题的解答是本书⼤部 分内容的主题。但是在⼀个实际应⽤中,我们经常必须对t的值做出具体的预测,或者更⼀般 地,根据我们对于t的可能取值的理解,采取⼀个具体的动作。这⼀⽅⾯就是决策论的主题。 例如,考虑⼀个医疗诊断问题。在这个问题中,我们给⼀个病⼈拍了X光⽚,我们想判断病 ⼈是否得了癌症。在这种情形下,输⼊向量x是X光⽚的像素的灰度值集合,输出变量t表⽰病 ⼈患有癌症(记作类C1)或者不患癌症(记作类C2)。例如,我们可以选择t = 0表⽰类C1,选 择t = 1表⽰类C2。我们稍后会看到,这种标签值的选择对于概率模型特别⽅便。⼀般的推断问 题就变成了确定联合分布p(x, Ck),或者等价地p(x, t)。它给出了最完整的概率描述。虽然这个 量很有⽤,很有信息量,但是最后我们必须确定是否对病⼈进⾏治疗,并且我们希望这种选择 在某些情况下是最优的(Duda and Hart, 1973)。这是决策步骤,是决策论的主题,告诉我们在 给定合适的概率的前提下,如何进⾏最优的决策。我们会看到,⼀旦我们解决了推断问题,那 么决策阶段通常就变得⾮常简单,甚⾄不值得⼀提。 这⾥我们简要介绍⼀下决策论的关键思想,以满⾜本书剩余部分的要求。更多的背景以及更 详细的讨论可以参考Berger(1985)和Bather(2000)。 在给出⼀个更详细的分析之前,让我们⾸先⾮形式化地考虑⼀下概率论如何在做决策时起作 ⽤。当我们得到⼀个新病⼈的X光⽚x时,我们的⽬标是判断这个X光⽚属于两类中的哪⼀类。 我们感兴趣的是在给定这个图像的前提下,两个类的概率,即p(Ck | x)。使⽤贝叶斯定理,这 些概率可以⽤下⾯的形式表⽰ p(Ck | x) = p(x | Ck)p(Ck) p(x) (1.77) 注意,出现在贝叶斯定理中的任意⼀个量都可以从联合分布p(x, Ck)中得到,要么通过积分的 ⽅式,要么通过关于某个合适的变量求条件概率。我们现在把p(Ck)称为类Ck的先验概率, 把p(Ck | x)称为对应的后验概率。因此p(C1)表⽰在我们拍X光之前,⼀个⼈患癌症的概率。类 似地,p(C1 | x)表⽰使⽤X光中包含的信息通过贝叶斯定理修改之后的对应的后验概率。如果我 33

To p(x,C1) p(z,C2) Ri R2 图124:两个类别的联合概率分布p(红,C)与x的关系,以及决策边界x=金。x≥的值被分类为C2,因此 属于决策区域R2,而x<的值被分类为C1,属于区域R1。错误出现在蓝色、绿色和红色区域,从而对 于x<金,错误的来源是将属于类别C2的点错分到类别C1(表示为红色区域与绿色区域的总和),相反对 于x≥的点,错误的来源是将属于类别C的点错分到类别C2(表示为蓝色区域)。当我们改变决策区域 的位置时,绿色区域和蓝色区域的总面积是一个常数,而红色区域的面积发生改变。的最优选择 是(x,C1)的曲线与(x,C2)的曲线相交,对应于充=xo,因为此时红色区域消失。这等价于最小化错误分 类率的决策规则,这个规则将x分配到具有最大的后验概率p(Ck|x)的区域中。 们的目标是最小化把x分到错误类别中的可能性,那么根据直觉,我们要选择有最大后验概率的 类别。我们现在要证明,这种直觉是正确的,并且我们还会讨论进行决策的更加通用的标准。 1.5.1最小化错误分类率 假定我们的目标很简单,即尽可能少地作出错误分类。我们需要一个规则来把每个x的值分 到一个合适的类别。这种规则将会把输入空间切分成不同的区域Rk,这种区域被称为决策区域 (decision region)。每个类别都有一个决策区域,区域Rk中的所有点都被分到Ck类。决策区域 间的边界被叫做决策边界(decision boundary)或者决策面(decision surface)。注意,每一个 决策区域未必是连续的,可以由若干个分离的区域组成。在后续的章节中,我们会给出决策边 界和决策区域的例子。为了找到最优的决策规则,首先考虑两类的情形,就像癌症问题的例子 中那样。如果我们把属于C1类的输入向量分到了C2类(或者相反),那么我们就犯了一个错 误。这种事情发生的概率为 p(mistake)=p(x∈R1,C2)+p(x∈R2,C1) (1.78) p(x,C2)dx+ p(x,C1)dx 我们可以随意选择把点c分到两类中的某一类的决策规则。很明显,为了最小化p(mistake), 我们对于x的分类结果应该让公式(178)的被积函数尽量小。因此,如果对于给定 的c值,如果p(c,C)>p(c,C2),那么我们就把x分到类别C中。根据概率的乘积规则,我们 有(c,Ck)=p(Ck|c)P(c)。由于因子p(c)对于两项都相同,因此我们可以这样表述:如果我们 把每个x分配到后验概率(Ck|x)最大的类别中,那么我们分类错误的概率就会最小。对于一元 输入变量x的二分类问题,结果如图1.24所示。 对于更一般的K类的情形,最大化正确率会稍微简单一些,即最大化下式 K p(correct))=∑p(x∈Rk,Ck)=】 p(x,Ck)dx (1.79) k=1 k=1 R 当区域Rk的选择使得每个x都被分到使(c,Ck)最大的类别中时,上式取得最大值。再一次使用 乘积规则p(x,C)=p(Ck|x)p(x),并且注意到因子p(x)对于所有项都相同,我们可以看到每 个x都应该被分到有着最大后验概率(C|x)的类别中。 34
R1 R2 x0 xb p(x, C1) p(x, C2) x 图 1.24: 两个类别的联合概率分布p(x, Ck)与x的关系,以及决策边界x = xb。x ≥ xb的值被分类为C2,因此 属于决策区域R2,⽽x < xb的值被分类为C1,属于区域R1。错误出现在蓝⾊、绿⾊和红⾊区域,从⽽对 于x < xb,错误的来源是将属于类别C2的点错分到类别C1(表⽰为红⾊区域与绿⾊区域的总和),相反对 于x ≥ xb的点,错误的来源是将属于类别C1的点错分到类别C2(表⽰为蓝⾊区域)。当我们改变决策区域 的位置xb时,绿⾊区域和蓝⾊区域的总⾯积是⼀个常数,⽽红⾊区域的⾯积发⽣改变。xb的最优选择 是p(x, C1)的曲线与p(x, C2)的曲线相交,对应于xb = x0,因为此时红⾊区域消失。这等价于最⼩化错误分 类率的决策规则,这个规则将x分配到具有最⼤的后验概率p(Ck | x)的区域中。 们的⽬标是最⼩化把x分到错误类别中的可能性,那么根据直觉,我们要选择有最⼤后验概率的 类别。我们现在要证明,这种直觉是正确的,并且我们还会讨论进⾏决策的更加通⽤的标准。 1.5.1 最⼩化错误分类率 假定我们的⽬标很简单,即尽可能少地作出错误分类。我们需要⼀个规则来把每个x的值分 到⼀个合适的类别。这种规则将会把输⼊空间切分成不同的区域Rk,这种区域被称为决策区域 (decision region)。每个类别都有⼀个决策区域,区域Rk中的所有点都被分到Ck类。决策区域 间的边界被叫做决策边界(decision boundary)或者决策⾯(decision surface)。注意,每⼀个 决策区域未必是连续的,可以由若⼲个分离的区域组成。在后续的章节中,我们会给出决策边 界和决策区域的例⼦。为了找到最优的决策规则,⾸先考虑两类的情形,就像癌症问题的例⼦ 中那样。如果我们把属于C1类的输⼊向量分到了C2类(或者相反),那么我们就犯了⼀个错 误。这种事情发⽣的概率为 p(mistake) = p(x ∈ R1, C2) + p(x ∈ R2, C1) = ∫ R1 p(x, C2) dx + ∫ R2 p(x, C1) dx (1.78) 我们可以随意选择把点x分到两类中的某⼀类的决策规则。很明显,为了最⼩化p(mistake), 我 们 对 于x的 分 类 结 果 应 该 让 公 式 (1.78) 的 被 积 函 数 尽 量 ⼩。 因 此, 如 果 对 于 给 定 的x值,如果p(x, C1) > p(x, C2),那么我们就把x分到类别C1中。根据概率的乘积规则,我们 有p(x, Ck) = p(Ck | x)p(x)。由于因⼦p(x)对于两项都相同,因此我们可以这样表述:如果我们 把每个x分配到后验概率p(Ck | x)最⼤的类别中,那么我们分类错误的概率就会最⼩。对于⼀元 输⼊变量x的⼆分类问题,结果如图1.24所⽰。 对于更⼀般的K类的情形,最⼤化正确率会稍微简单⼀些,即最⼤化下式 p(correct) = ∑ K k=1 p(x ∈ Rk, Ck) = ∑ K k=1 ∫ Rk p(x, Ck) dx (1.79) 当区域Rk的选择使得每个x都被分到使p(x, Ck)最⼤的类别中时,上式取得最⼤值。再⼀次使⽤ 乘积规则p(x, Ck) = p(Ck | x)p(x),并且注意到因⼦p(x)对于所有项都相同,我们可以看到每 个x都应该被分到有着最⼤后验概率p(Ck | x)的类别中。 34

癌症 正常 癌症 0 1000 正常 0 图125:癌症诊断问题的损失矩阵的例子,矩阵的元素为Lk。行对应于真实的类别,而列对应于我们的 决策准则做出的分类。 1.5.2最小化期望损失 对于许多应用,我们的目标要比单纯地最小化错误分类的数量更加复杂。让我们再次考虑医 疗诊断的问题。我们注意到,如果已给没有患癌症的病人被错误地诊断为患病,结果可能给病 人带来一些压力,并且病人可能需要进一步确诊。相反,如果患癌症的病人被诊断为健康,结 果可能会因为缺少治疗而使病人过早死亡。因此这两种错误的结果是相当不同的。很明显,对 于第二种错误,我们最好少犯,甚至由于少犯第二种错误会导致第一种错误增加也没关系。 我们可以通过损失函数(loss function)来形式化地描述这个问题。损失函数也被称为代价 函数(cost function),是对于所有可能的决策或者动作可能产生的损失的一种整体的度量。我 们的目标是最小化整体的损失。注意,有些学者不考虑损失函数,而是考虑效用函数(ulty function),并且要最大化这个函数。如果我们让效用函数等于损失函数的相反数的话,那么这 些概念是等价的,因此整本书中我们都将使用损失函数这个概念。假设对于新的x的值,真实 的类别为Ck,我们把x分类为C,(其中可能与k相等,也可能不相等)。这样做的结果是,我们 会造成某种程度的损失,记作Lkj,它可以看成损失矩阵(loss matriⅸ)的第k,j个元素。例如, 在癌症的例子中,我们可能有图125所示的损失矩阵。这个特别的损失矩阵表明,如果我们做出 了正确的决策,那么不会造成损失。如果健康人被诊断为患有癌症,那么损失为1。但是如果一 个患有癌症的病人被诊断为健康,那么损失为1000。 最优解是使损失函数最小的解。但是,损失函数依赖于真实的类别,这是未知的。对于一个 给定的输入向量x,我们对于真实类别的不确定性通过联合概率分布(x,Ck)表示。因此,我们 转而去最小化平均损失。平均损失根据这个联合概率分布计算,定义为 四=∑∑ Lkip(,Ck)dx (1.80) 每一个x可以被独立地分到决策区域R中。我们的目标是选择区域R,来最小化期望损失 (1.80)。这表明,对于每个x,我们要最小化∑kLkP(c,Ck)。和之前一样,我们可以使用乘 积规则p(c,Ck)=p(Ck|x)P(c)来消除共同因子p(x)。因此,最小化期望损失的决策规则是对于 每个新的x,把它分到能使下式取得最小值的第类: ∑Lkjp(C:Ix) (1.81) 一旦我们知道了类的后验概率(Ck|x)之后,这件事就很容易做了。 1.5.3拒绝选项 我们已经看到,在发生分类错误的输入空间中,后验概率(Ck|c)通常远小于1,或者等价 地,不同类别的联合分布(x,Ck)有着可比的值。这些区域中,类别的归属相对不确定。在某些 应用中,对于这种困难的情况,避免做出决策是更合适的选择。这样会使得模型的分类错 误率降低。这被称为拒绝选项(reject option)。例如,在我们假想的医疗例子中,一种合适 的做法是,使用自动化的系统来对那些几乎没有疑问的X光片进行分类,然后把不容易分类 的X光片留给人类的专家。我们可以用这种方式来达到这个目的:引入一个阈值,拒绝后验概 率p(Ck|c)的最大值小于等于0的那些输入x。图1.26说明了一元输入变量x的二分类问题的情 35
正常 癌症 癌症 正常 ( ) 0 1000 1 0 图 1.25: 癌症诊断问题的损失矩阵的例⼦,矩阵的元素为Lkj。⾏对应于真实的类别,⽽列对应于我们的 决策准则做出的分类。 1.5.2 最⼩化期望损失 对于许多应⽤,我们的⽬标要⽐单纯地最⼩化错误分类的数量更加复杂。让我们再次考虑医 疗诊断的问题。我们注意到,如果已给没有患癌症的病⼈被错误地诊断为患病,结果可能给病 ⼈带来⼀些压⼒,并且病⼈可能需要进⼀步确诊。相反,如果患癌症的病⼈被诊断为健康,结 果可能会因为缺少治疗⽽使病⼈过早死亡。因此这两种错误的结果是相当不同的。很明显,对 于第⼆种错误,我们最好少犯,甚⾄由于少犯第⼆种错误会导致第⼀种错误增加也没关系。 我们可以通过损失函数(loss function)来形式化地描述这个问题。损失函数也被称为代价 函数(cost function),是对于所有可能的决策或者动作可能产⽣的损失的⼀种整体的度量。我 们的⽬标是最⼩化整体的损失。注意,有些学者不考虑损失函数,⽽是考虑效⽤函数(utility function),并且要最⼤化这个函数。如果我们让效⽤函数等于损失函数的相反数的话,那么这 些概念是等价的,因此整本书中我们都将使⽤损失函数这个概念。假设对于新的x的值,真实 的类别为Ck,我们把x分类为Cj(其中j可能与k相等,也可能不相等)。这样做的结果是,我们 会造成某种程度的损失,记作Lkj,它可以看成损失矩阵(loss matrix)的第k, j个元素。例如, 在癌症的例⼦中,我们可能有图1.25所⽰的损失矩阵。这个特别的损失矩阵表明,如果我们做出 了正确的决策,那么不会造成损失。如果健康⼈被诊断为患有癌症,那么损失为1。但是如果⼀ 个患有癌症的病⼈被诊断为健康,那么损失为1000。 最优解是使损失函数最⼩的解。但是,损失函数依赖于真实的类别,这是未知的。对于⼀个 给定的输⼊向量x,我们对于真实类别的不确定性通过联合概率分布p(x, Ck)表⽰。因此,我们 转⽽去最⼩化平均损失。平均损失根据这个联合概率分布计算,定义为 E[L] = ∑ k ∑ j ∫ Rj Lkjp(x, Ck) dx (1.80) 每⼀个x可以被独⽴地分到决策区域Rj中。我们的⽬标是选择区域Rj,来最⼩化期望损失 (1.80)。这表明,对于每个x,我们要最⼩化∑ k Lkjp(x, Ck)。和之前⼀样,我们可以使⽤乘 积规则p(x, Ck) = p(Ck | x)p(x)来消除共同因⼦p(x)。因此,最⼩化期望损失的决策规则是对于 每个新的x,把它分到能使下式取得最⼩值的第j类: ∑ k Lkjp(Ck | x) (1.81) ⼀旦我们知道了类的后验概率p(Ck | x)之后,这件事就很容易做了。 1.5.3 拒绝选项 我们已经看到,在发⽣分类错误的输⼊空间中,后验概率p(Ck | x)通常远⼩于1,或者等价 地,不同类别的联合分布p(x, Ck)有着可⽐的值。这些区域中,类别的归属相对不确定。在某些 应⽤中,对于这种困难的情况,避免做出决策是更合适的选择。这样会使得模型的分类错 误率降低。这被称为拒绝选项(reject option)。例如,在我们假想的医疗例⼦中,⼀种合适 的做法是,使⽤⾃动化的系统来对那些⼏乎没有疑问的X光⽚进⾏分类,然后把不容易分类 的X光⽚留给⼈类的专家。我们可以⽤这种⽅式来达到这个⽬的:引⼊⼀个阈值θ,拒绝后验概 率p(Ck | x)的最⼤值⼩于等于θ的那些输⼊x。图1.26说明了⼀元输⼊变量x的⼆分类问题的情 35