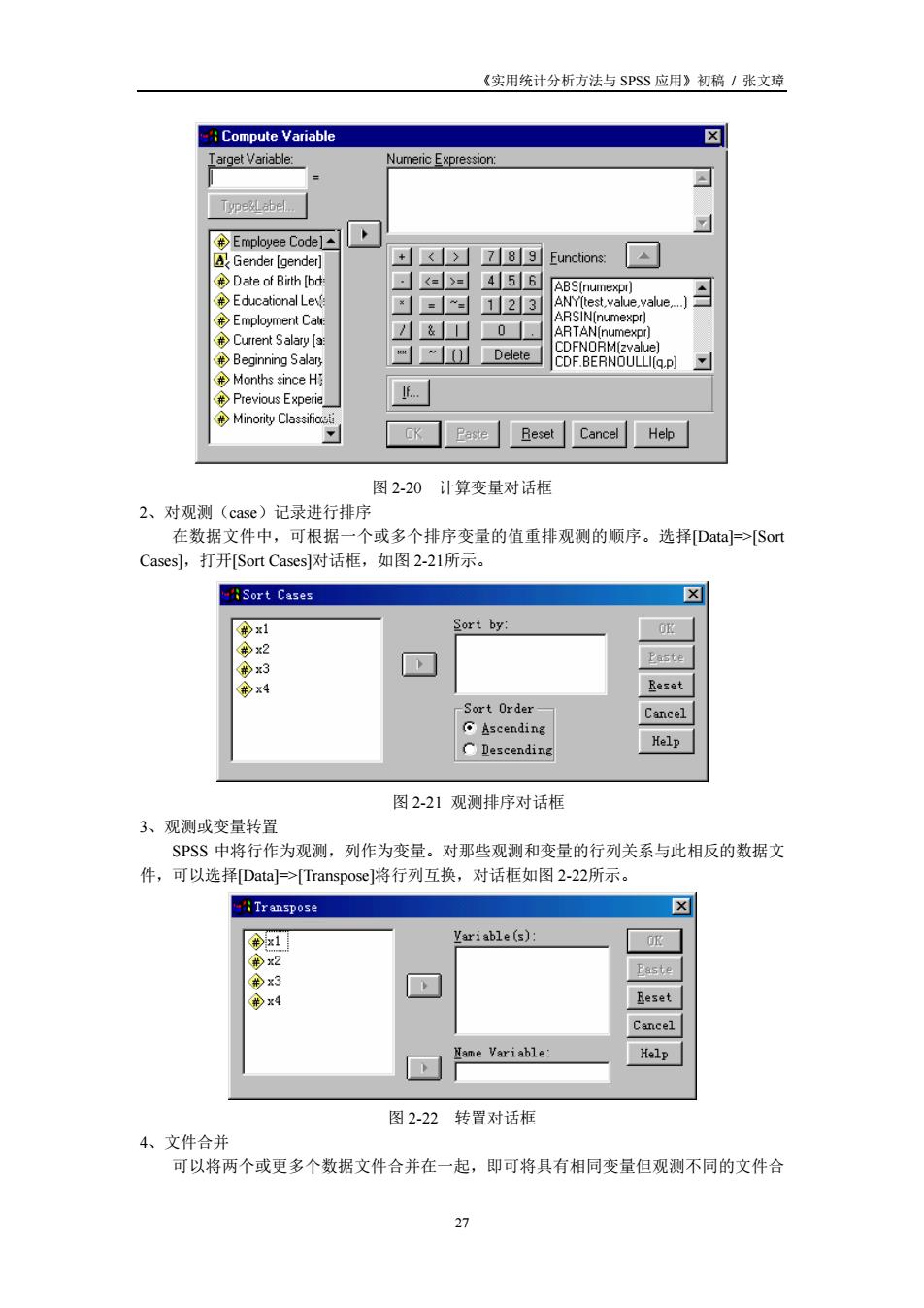
《实用统计分析方法与SPSS应用》初稿/张文球 Compute Variable X rget Variable: umeric Expression +>Z89 Eunctions:▲ Date of Bith [b .=>=456 ¥Educational L ==123 Months since H oK2ae「Reset Cancel Help 图2-20计算变量对话框 2、对观测(case)记录进行排序 在数据文件中,可根据一个或多个排序变量的值重排观测的顺序。选Daa]>So Cases],打开Sort Cases]对话框,如图2-21所示 Sort Case Sort by: Easte 3 x4 Sort Order Cancel 「He1p 图2-21观测排序对话框 3、观测或变量转置 SSS中将行作为观测,列作为变量。对那些观测和变量的行列关系与此相反的数据文 件,可以选择[Data->Transpose]将行列互换,对话框如图2-22所示。 Transpose ☒ ariable(s): Peste ame Variable Help 图2-22 转置对话框 4、文件合并 可以将两个或更多个数据文件合并在一起,即可将具有相同变量但观测不同的文件合
《实用统计分析方法与 SPSS 应用》初稿 / 张文璋 27 图 2-20 计算变量对话框 2、对观测(case)记录进行排序 在数据文件中,可根据一个或多个排序变量的值重排观测的顺序。选择[Data]=>[Sort Cases],打开[Sort Cases]对话框,如图 2-21所示。 图 2-21 观测排序对话框 3、观测或变量转置 SPSS 中将行作为观测,列作为变量。对那些观测和变量的行列关系与此相反的数据文 件,可以选择[Data]=>[Transpose]将行列互换,对话框如图 2-22所示。 图 2-22 转置对话框 4、文件合并 可以将两个或更多个数据文件合并在一起,即可将具有相同变量但观测不同的文件合
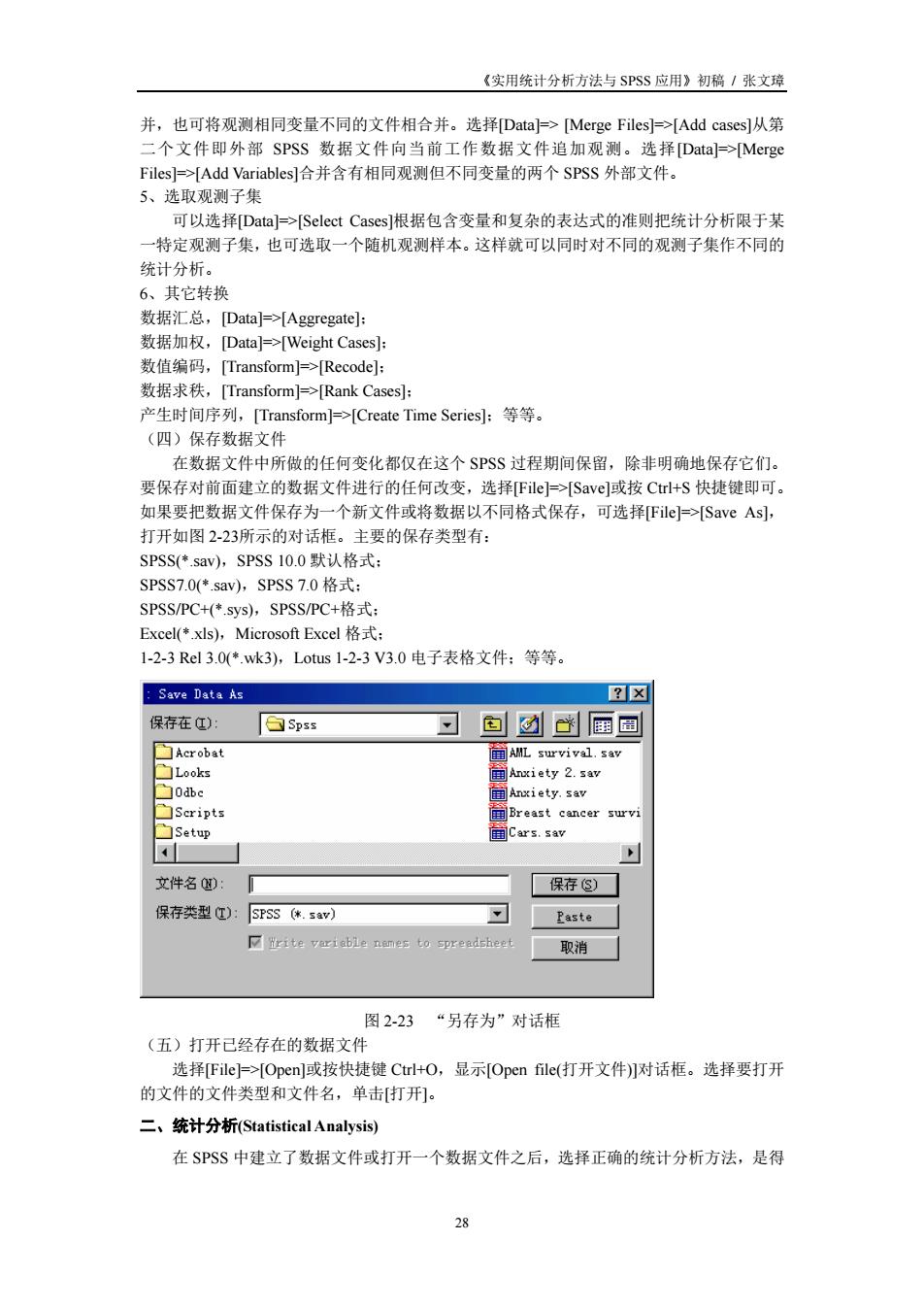
《实用统计分析方法与SPSS应用》初稿/张文琼 并,也可将观测相同变量不同的文件相合并。选择Data上>Merge Files]=>Add cases]从第 二个文件即外部SPSS数据文件向当前工作数据文件追加观测。选择Daa>Mcrg iables]合并含有相同观测但不同变量的两个SPSS外部文件 可以选Data]=>[Select Cases]根据包含变量和复杂的表达式的准则把统计分析限于某 一特定观测子集,也可选取一个随机观测样本。这样就可以同时对不同的观测子集作不同的 统计分析。 6、其它转换 数据汇总,[Data]>Aggregate:] 数据加权,[Data->Weight Cases:] 数值编码,[Transform]=>Recode]: 数据求秩,Transforml=→Rank Casesl 产生时间序列,[Transform]>[Create Time Series:等等。 (四) 存数据 在数据文件中所做的任何变化都仅在这个SPSS过程期间保留,除非明确地保存它们。 要保存对前面建立的数据文件进行的任何改变,选择File>[Save]或按Crl+S快捷键即可。 如果要把数据文件保存为一个新文件或将数据以不同格式保存,可选择File=>[Save As], 打开加图223所示的对话框。主要的保存类型有: SPSS*av),SPSS10.0默认格式: SPSS7.0(.sav,SPSs7.0格式: SPSS/PC+(*svs),SPSS/PC+格式 Excell◆xlsl.Microsoft exce格式 1-2-3Rl3.0(*wk3),Lotus1-2-3V3.0电子表格文件:等等。 Save Data As ?☒ 保存在): Spss 可动心国画 Acrobat iety 2. Seripts Breast cancer surv Cars.sav 文件名 保存③) 保存类型T):SF33.sa】 消 图2-23“另存为”对话框 (五)打开已经存在的数据文 选择File]>Open或按快捷键Crl+O,显示Open file(打开文件)切对话框。选择要打开 的文件的文件类型和文件名,单击打开 二、统计分析(Statistical Analysis) 在SPSS中建立了数据文件或打开一个数据文件之后,选择正确的统计分析方法,是得
《实用统计分析方法与 SPSS 应用》初稿 / 张文璋 28 并,也可将观测相同变量不同的文件相合并。选择[Data]=> [Merge Files]=>[Add cases]从第 二个文件即外部 SPSS 数据文件向当前工作数据文件追加观测。选择[Data]=>[Merge Files]=>[Add Variables]合并含有相同观测但不同变量的两个 SPSS 外部文件。 5、选取观测子集 可以选择[Data]=>[Select Cases]根据包含变量和复杂的表达式的准则把统计分析限于某 一特定观测子集,也可选取一个随机观测样本。这样就可以同时对不同的观测子集作不同的 统计分析。 6、其它转换 数据汇总,[Data]=>[Aggregate]; 数据加权,[Data]=>[Weight Cases]; 数值编码,[Transform]=>[Recode]; 数据求秩,[Transform]=>[Rank Cases]; 产生时间序列,[Transform]=>[Create Time Series];等等。 (四)保存数据文件 在数据文件中所做的任何变化都仅在这个 SPSS 过程期间保留,除非明确地保存它们。 要保存对前面建立的数据文件进行的任何改变,选择[File]=>[Save]或按 Ctrl+S 快捷键即可。 如果要把数据文件保存为一个新文件或将数据以不同格式保存,可选择[File]=>[Save As], 打开如图 2-23所示的对话框。主要的保存类型有: SPSS(*.sav),SPSS 10.0 默认格式; SPSS7.0(*.sav),SPSS 7.0 格式; SPSS/PC+(*.sys),SPSS/PC+格式; Excel(*.xls),Microsoft Excel 格式; 1-2-3 Rel 3.0(*.wk3),Lotus 1-2-3 V3.0 电子表格文件;等等。 图 2-23 “另存为”对话框 (五)打开已经存在的数据文件 选择[File]=>[Open]或按快捷键 Ctrl+O,显示[Open file(打开文件)]对话框。选择要打开 的文件的文件类型和文件名,单击[打开]。 二、统计分析(Statistical Analysis) 在 SPSS 中建立了数据文件或打开一个数据文件之后,选择正确的统计分析方法,是得
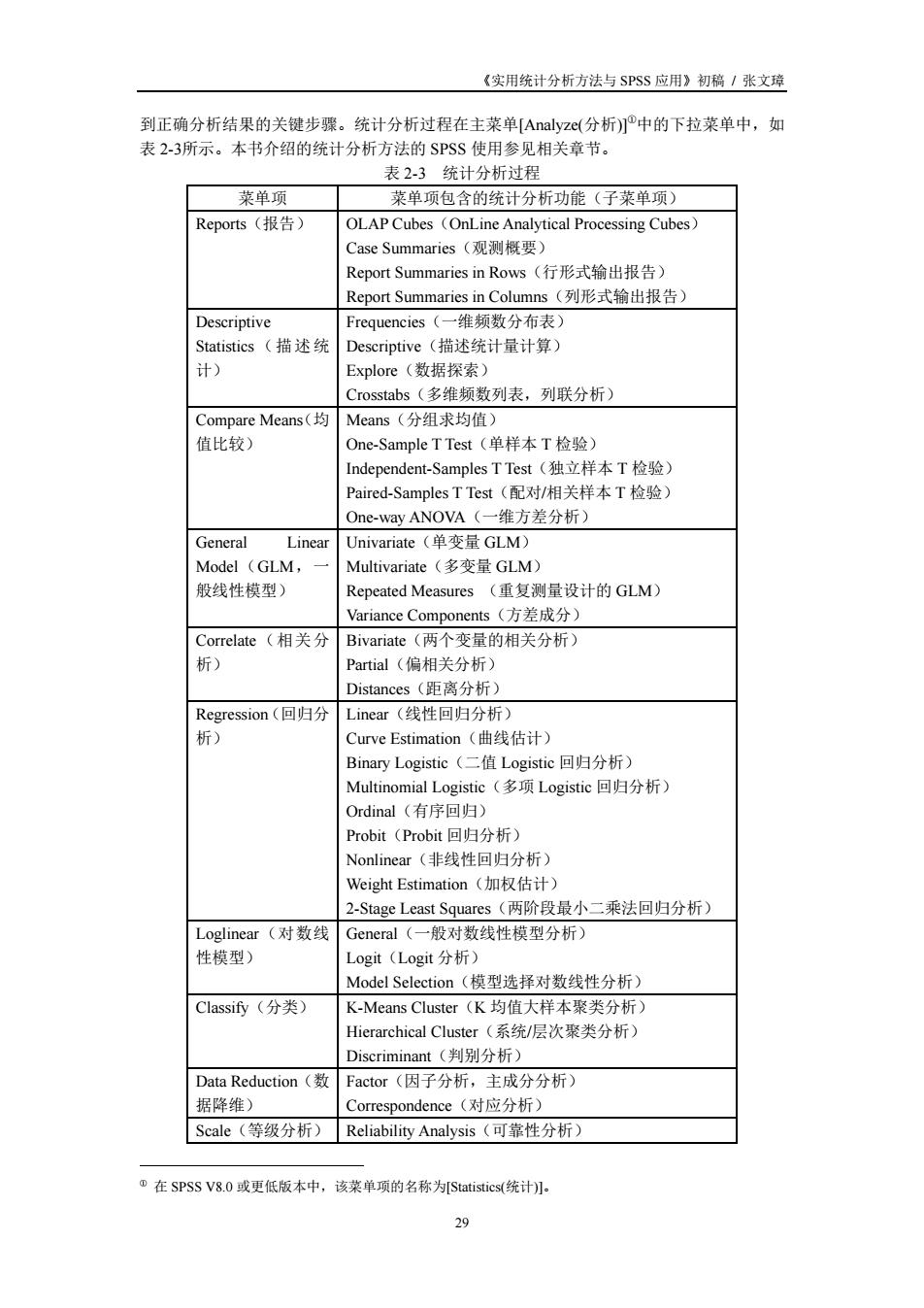
《实用统计分析方法与SPSS应用》初稿/张文球 到正确分析结果的关键步骤。统计分析过程在主菜单[Aazc(分析)心中的下拉莱单中,如 表2.3所示。本书介绍的统计分析方法的SPSS使用参见相关章节。 表2-3统计分析过程 莱单项 菜单项包含的统计分析功能(子莱单项) Reports(报告) OLAP Cubes (OnLine Analytical Processing Cubes) Case Summaries(观测摄要) Report Summaries in Rows(行形式输出报告) Report Summaries in Col mns(列形式输出报告) Descriptive 维频数分布表) Statistics(描述统Deseriptive(描述统计量计算) 计) Explore(数据探索) stabs(多维频数列表,列联分析) Compare Means(均 Means(分组求均值) 值比较) One-Sample T Test(单样本T检验) Independent-SamplesTTest(独立样本T检验) Paired.Samples T Test(配对/相关样本T检验) One-way ANOVA(一维方差分析) General Univariate(单变量GLM Model (GLM, Multivariate(多变量GLM) 般线性模型) Repeated Measures(重复测量设计的GLM) Variance Components(方若成分) Correlate(相关分 Bivariate (两个变量的相关分析) 析) Partial(偏相关分析 Distances(距离分析) Regression(同归分Linear(线性同归分析) Curve Estimation(曲线估计) ary Logistic (二值Logistic回归分析 Multinomial Logistic(多项Logistic回归分析) Ordinal(有序回归) Probit(Probit回归分析) Nonlinear(非线性同归分析 Neight Estimation(加权估计 2-Stage Least Squares(两阶段最小二乘法回归分析) Loglinear(对数线General(一般对数线性模型分析) 性模型) Logit(Logit分析) Model Selection(揽型洗对物线性分析 K-Means Cluster(K均值大样本聚类分析 Hierarchical Cluster(系统/层次聚类分析) Discriminant(判别分析) Data Reduction(数Factor(因子分析,主成分分析) 据降维) respondence(对应分析) Scale(等级分析)Reliability Analysis(可靠性分析) 在SPSS V8.0或更低版本中,该莱单项的名称为Statistics(统计。 39
《实用统计分析方法与 SPSS 应用》初稿 / 张文璋 29 到正确分析结果的关键步骤。统计分析过程在主菜单[Analyze(分析)]①中的下拉菜单中,如 表 2-3所示。本书介绍的统计分析方法的 SPSS 使用参见相关章节。 表 2-3 统计分析过程 菜单项 菜单项包含的统计分析功能(子菜单项) Reports(报告) OLAP Cubes(OnLine Analytical Processing Cubes) Case Summaries(观测概要) Report Summaries in Rows(行形式输出报告) Report Summaries in Columns(列形式输出报告) Descriptive Statistics(描述统 计) Frequencies(一维频数分布表) Descriptive(描述统计量计算) Explore(数据探索) Crosstabs(多维频数列表,列联分析) Compare Means(均 值比较) Means(分组求均值) One-Sample T Test(单样本 T 检验) Independent-Samples T Test(独立样本 T 检验) Paired-Samples T Test(配对/相关样本 T 检验) One-way ANOVA(一维方差分析) General Linear Model(GLM,一 般线性模型) Univariate(单变量 GLM) Multivariate(多变量 GLM) Repeated Measures (重复测量设计的 GLM) Variance Components(方差成分) Correlate(相关分 析) Bivariate(两个变量的相关分析) Partial(偏相关分析) Distances(距离分析) Regression(回归分 析) Linear(线性回归分析) Curve Estimation(曲线估计) Binary Logistic(二值 Logistic 回归分析) Multinomial Logistic(多项 Logistic 回归分析) Ordinal(有序回归) Probit(Probit 回归分析) Nonlinear(非线性回归分析) Weight Estimation(加权估计) 2-Stage Least Squares(两阶段最小二乘法回归分析) Loglinear(对数线 性模型) General(一般对数线性模型分析) Logit(Logit 分析) Model Selection(模型选择对数线性分析) Classify(分类) K-Means Cluster(K 均值大样本聚类分析) Hierarchical Cluster(系统/层次聚类分析) Discriminant(判别分析) Data Reduction(数 据降维) Factor(因子分析,主成分分析) Correspondence(对应分析) Scale(等级分析) Reliability Analysis(可靠性分析) ① 在 SPSS V8.0 或更低版本中,该菜单项的名称为[Statistics(统计)]
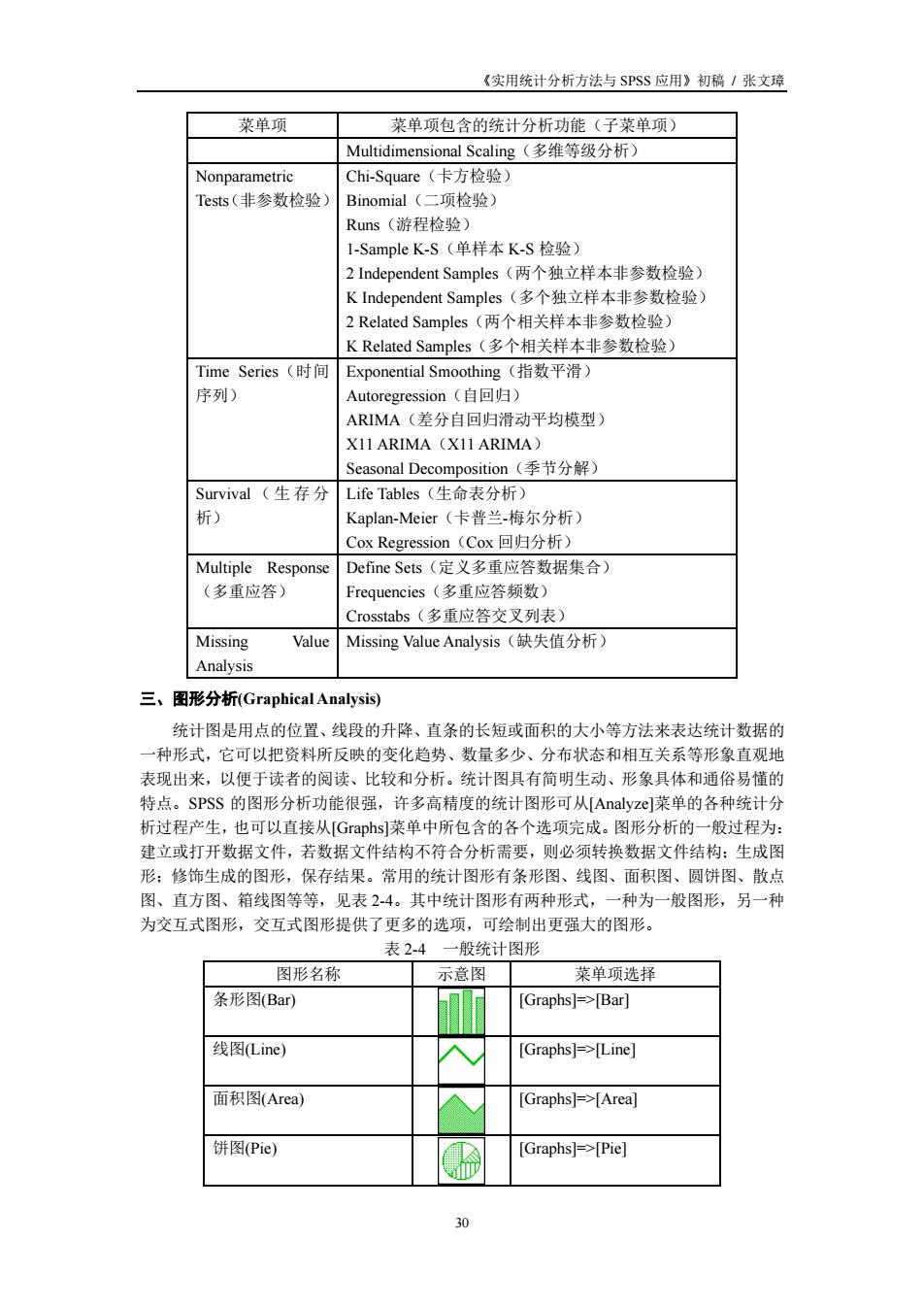
《实用统计分析方法与SPSS应用》初稿/张文璋 菜单项 菜单项包含的统计分析功能(子菜单项) Multidimensional Scaling(多维等级分析) Nonparametric Chi-Square(卡方检验) Tests(非参数检哈】 Binomial(一项检哈) Runs(游程检验) 1-SampleK-S(单样本K-S检验) 2 Independent Samples(两个独立样本非参数检验 K Independent Samples(多个独立样本非参数检验, 2 Related Samples(两个相关样本非参数检验) K Related Samples(多个相关样本非参数检验) Exponential Smoothing(指数平滑) ion(自回归) ARIMA(差分自回归滑动平均模型) X11ARIMA (XII ARIMA) Seasonal Decomposition(季节分解) Survival(生存分 Life Tables(生命表分析) 析) Kaplan-Meier(卡普兰-梅尔分析) Cox Regression(Cox回归分析) Multiple Response Define Sets(定义多重应答数据集合) (多重应答) requencies(多重应答频数) stabs(多重应答交叉列表】 Missing Value Missing Value Analysis(缺失值分析) Analysis 三、图形分析Graphical Analysis) 统计图是用点的位置、线段的升降、直条的长短或面积的大小等方法来表达统计数据的 一种形式,它可以把资料所反映的变化趋势、数量多少、分布状态和相互关系等形象直观地 表现出来,以便于读者的阅读、比较和分析。统计图具有简明生动、形象具体和通俗易懂的 结占。pS的图形分折功能很品,许多高持府的计图形可从Anav]菜单的冬种续计分 析过程产生,也可以直接从 raphs菜单中所包含的各 个选项完成。图形分析的 一般过程为 建立或打开数据文件,若数据文件结构不符合分析需要,则必须转换数据文件结构:生成图 形:修饰生成的图形,保存结果。常用的统计图形有条形图、线图、面积图、圆饼图、散点 图、直方图、箱线图等等,见表24。其中统计图形有两种形式,一种为一般图形,另一种 为交互式图形,交互式图形提供了更多的选项,可绘制出更强大的图形。 一般统计图形 图形名称 示意图 菜单项选择 条形图(Bar) [Graphs]=>Barl 线图Line) [Graphs]=>[Line] 面积图(Area) [Graphs]=>[Area] 饼图Pie) Graphs]->Pie间
《实用统计分析方法与 SPSS 应用》初稿 / 张文璋 30 菜单项 菜单项包含的统计分析功能(子菜单项) Multidimensional Scaling(多维等级分析) Nonparametric Tests(非参数检验) Chi-Square(卡方检验) Binomial(二项检验) Runs(游程检验) 1-Sample K-S(单样本 K-S 检验) 2 Independent Samples(两个独立样本非参数检验) K Independent Samples(多个独立样本非参数检验) 2 Related Samples(两个相关样本非参数检验) K Related Samples(多个相关样本非参数检验) Time Series(时间 序列) Exponential Smoothing(指数平滑) Autoregression(自回归) ARIMA(差分自回归滑动平均模型) X11 ARIMA(X11 ARIMA) Seasonal Decomposition(季节分解) Survival (生存分 析) Life Tables(生命表分析) Kaplan-Meier(卡普兰-梅尔分析) Cox Regression(Cox 回归分析) Multiple Response (多重应答) Define Sets(定义多重应答数据集合) Frequencies(多重应答频数) Crosstabs(多重应答交叉列表) Missing Value Analysis Missing Value Analysis(缺失值分析) 三、图形分析(Graphical Analysis) 统计图是用点的位置、线段的升降、直条的长短或面积的大小等方法来表达统计数据的 一种形式,它可以把资料所反映的变化趋势、数量多少、分布状态和相互关系等形象直观地 表现出来,以便于读者的阅读、比较和分析。统计图具有简明生动、形象具体和通俗易懂的 特点。SPSS 的图形分析功能很强,许多高精度的统计图形可从[Analyze]菜单的各种统计分 析过程产生,也可以直接从[Graphs]菜单中所包含的各个选项完成。图形分析的一般过程为: 建立或打开数据文件,若数据文件结构不符合分析需要,则必须转换数据文件结构;生成图 形;修饰生成的图形,保存结果。常用的统计图形有条形图、线图、面积图、圆饼图、散点 图、直方图、箱线图等等,见表 2-4。其中统计图形有两种形式,一种为一般图形,另一种 为交互式图形,交互式图形提供了更多的选项,可绘制出更强大的图形。 表 2-4 一般统计图形 图形名称 示意图 菜单项选择 条形图(Bar) [Graphs]=>[Bar] 线图(Line) [Graphs]=>[Line] 面积图(Area) [Graphs]=>[Area] 饼图(Pie) [Graphs]=>[Pie]
《实用统计分析方法与SPSS应用》初稿/张文璋 高低图High-Low) 面 [Graphs]=>[High-Low] 帕累托图(Pareto) Graphs=>Pareto 工序控制图(Control) [Graphs]=>[Controll 箱线图(Boxplot) 699 [Graphs]=>[Boxplot] 误差条图(Error Bar)) 面 [Graphs]=>[Error Bar] 散点图(Scatter) 8 [Graphs]>[Scatter] 直方图Histogram) h [Graphs]=>[Histogram] PP正态概率图 [Graphs]->[P-P] (Normal P-P) Q-Q正态概率图 [Graphs]=>[Q-Q] (Normal o.o) 时序图(Sequence) [Graphs]=[Sequence] 自相关图 [Graphs]=>[Time Series] (Autocorrelations) =>LAutocorrelationsl 石相关图 ss-Correlations) 表2-5 交互式统计图形 图形名称 菜单项选择 条形图(Bar) Graphs]>[Interactive][Bar 点图(DoU) [Graphs>[Interactive]=>[Dot] 线图Line) [Graphs]=>[Interactive]=>[Line] 带状图(Ribhon) [Graphs]=>[Interactive]=>[Ribbon] 点线图Drop-Line) Graphs=>Interactive=>Drop-Line 面积图(Area) [Graphs]=>[Interactive][Area] 饼图Pe [Graphsl=>[Interactivel=>Pie.] [Graphs]=>[Interactive]=>[Boxplot 误差条图Error Bar) [Graphs=>Interactive=Error Bar 直方图(Histogram) [Graphs]=>[Interactive]=[Histogram] [Graphs]=>[Interactive]=>[Scatterplot] 四、输出管理Output Management) 不管是统计分析还是图形分析,其结果都输出到新的窗口一一Viewer窗口或Dran Viewer窗D,SPsS认 出窗口为Viewer窗口 (如图2-24所示)。V ☐的左边是输 出大纲视图(如图2-25所示),可以单击统计过程名称左边的“+”和“”展开或收缩输出
《实用统计分析方法与 SPSS 应用》初稿 / 张文璋 31 高低图(High-Low) [Graphs]=>[High-Low] 帕累托图(Pareto) [Graphs]=>[Pareto] 工序控制图(Control) [Graphs]=>[Control] 箱线图(Boxplot) [Graphs]=>[Boxplot] 误差条图(Error Bar) [Graphs]=>[Error Bar] 散点图(Scatter) [Graphs]=>[Scatter] 直方图(Histogram) [Graphs]=>[Histogram] P-P 正态概率图 (Normal P-P) [Graphs]=>[P-P] Q-Q 正态概率图 (Normal Q-Q) [Graphs]=>[Q-Q] 时序图(Sequence) [Graphs]=>[Sequence] 自相关图 (Autocorrelations) [Graphs]=>[Time Series] =>[Autocorrelations] 互相关图 (Cross-Correlations) [Graphs]=>[Time Series] =>[Cross-Correlations] 表 2-5 交互式统计图形 图形名称 菜单项选择 条形图(Bar) [Graphs]=>[Interactive]=>[Bar] 点图(Dot) [Graphs]=>[Interactive]=>[Dot] 线图(Line) [Graphs]= >[Interactive]=>[Line] 带状图(Ribbon) [Graphs]= >[Interactive]=>[Ribbon] 点线图(Drop-Line) [Graphs]= >[Interactive]=>[Drop-Line] 面积图(Area) [Graphs]= >[Interactive]=>[Area] 饼图(Pie) [Graphs]= >[Interactive]=>[Pie.] 箱线图(Boxplot) [Graphs]= >[Interactive]=>[Boxplot] 误差条图(Error Bar) [Graphs]= >[Interactive]=>[Error Bar] 直方图(Histogram) [Graphs]= >[Interactive]=>[Histogram] 散点图(Scatterplot) [Graphs]= >[Interactive]=>[Scatterplot] 四、输出管理(Output Management) 不管是统计分析还是图形分析,其结果都输出到新的窗口——Viewer 窗口或 Draft Viewer 窗口,SPSS 默认输出窗口为 Viewer 窗口(如图 2-24所示)。Viewer 窗口的左边是输 出大纲视图(如图 2-25所示),可以单击统计过程名称左边的“+”和“-”展开或收缩输出