
Research context General attention versus self-attention .y12 yo y:y2 attention Self-attention ko k:k2 90919z 国产之小丝 2024/5/13 6
Research context 2024/5/13 6 General attention versus self-attention x0 x1 x2 y0 y1 y2 attention y0 y1 y2 k0 k1 k2 v0 v1 v2 q0 q1 q2 Self-attention
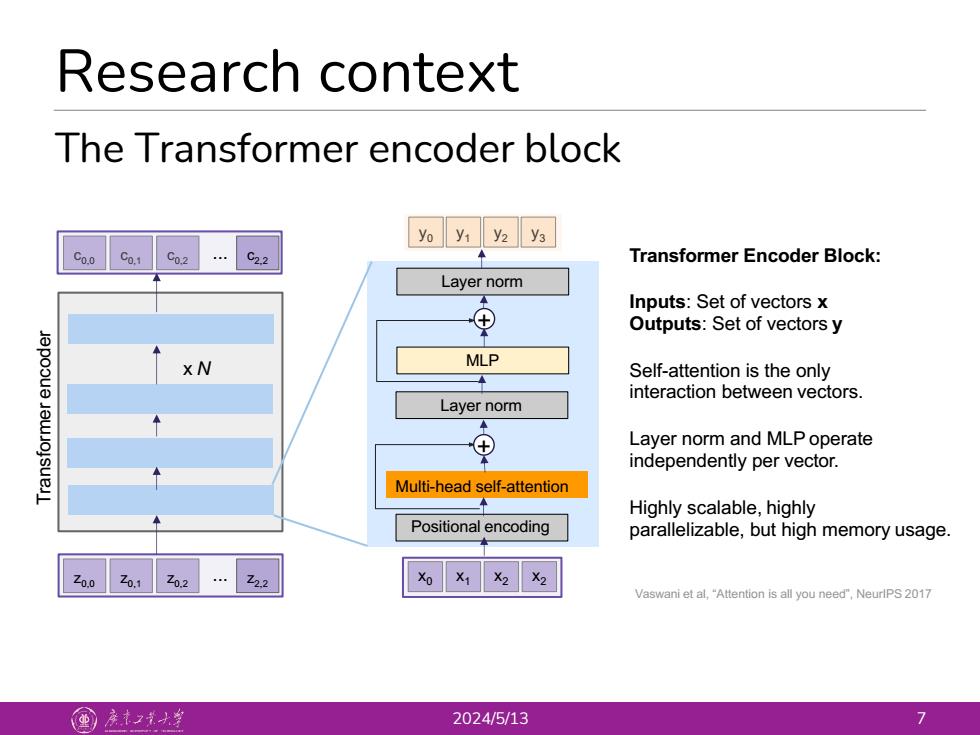
Research context The Transformer encoder block yo y1 y2 y3 C0.0 Co.1 C02…C2.2 Transformer Encoder Block: Layer norm Inputs:Set of vectors x ⊕ Outputs:Set of vectors y X N MLP Self-attention is the only 一 interaction between vectors. Layer norm ⊕ Layer norm and MLP operate independently per vector. Multi-head self-attention 二 Highly scalable,highly Positional encoding parallelizable,but high memory usage. Zo.o Z02…2.2 Vaswani et al,"Attention is all you need",NeurlPS 2017 国产大 2024/5/13 7
Research context 2024/5/13 7 The Transformer encoder block Multi-head self-attention Layer norm Layer norm MLP y0 y1 y2 y3 c0,2 c0,1 c0,0 c2,2 ... Transformer encoder Positional encoding parallelizable, but high memory usage. z ... 0,0 z0,1 z0,2 z2,2 x0 x1 x2 x2 Vaswani et al, “Attention is all you need”, NeurIPS 2017 x N Transformer Encoder Block: Inputs: Set of vectors x Outputs: Set of vectors y Self-attention is the only interaction between vectors. Layer norm and MLP operate independently per vector. Highly scalable, highly + +
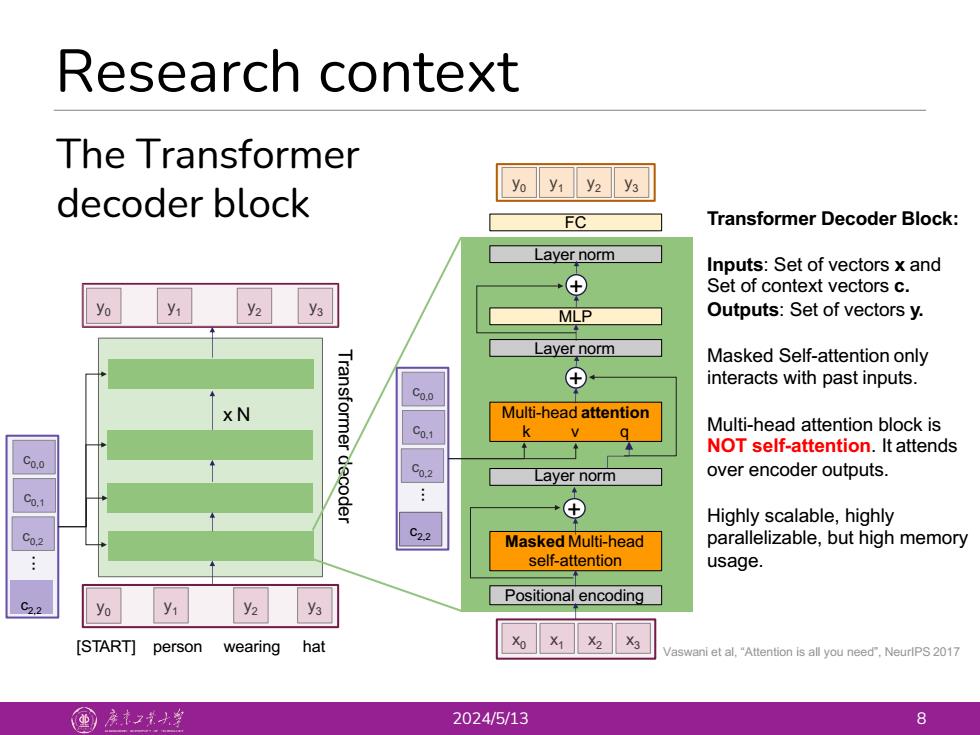
Research context The Transformer yoy1 y2 y3 decoder block FC Transformer Decoder Block: Layer norm Inputs:Set of vectors x and ⊕ Set of context vectors c. y1 y2 y3 MLP Outputs:Set of vectors y. Layer norm Masked Self-attention only Transformer ⊕ interacts with past inputs. Co.o Multi-head attention Co-1 q Multi-head attention block is NOT self-attention.It attends Co.o decoder 02 Layer norm over encoder outputs. Co.1 +⊕ Highly scalable,highly Co.2 C2.2 Masked Multi-head parallelizable,but high memory self-attention usage. Positional encoding C2.2 yo y y2 y3 [START]person wearing hat X1X2 X3 Vaswani et al,"Attention is all you need",NeurlPS 2017 重)亲大 2024/5/13 8
Research context 2024/5/13 8 The Transformer decoder block Transformer Decoder Block: Inputs: Set of vectors x and Set of context vectors c. Outputs: Set of vectors y. Masked Self-attention only interacts with past inputs. Multi-head attention block is NOT self-attention. It attends over encoder outputs. Highly scalable, highly parallelizable, but high memory usage. c0,2 c0,1 c0,0 c2,2... Transformer decoder x N y0 [START] y1 y2 person wearing hat y3 y0 y1 y2 y3 Vaswani et al, “Attention is all you need”, NeurIPS 2017 Positional encoding x0 x1 x2 x3 Masked Multi-head self-attention Layer norm Layer norm MLP y0 y1 y2 y3 c0,2 c0,1 c0,0 c2,2... FC Multi-head attention k v q + + Layer norm +
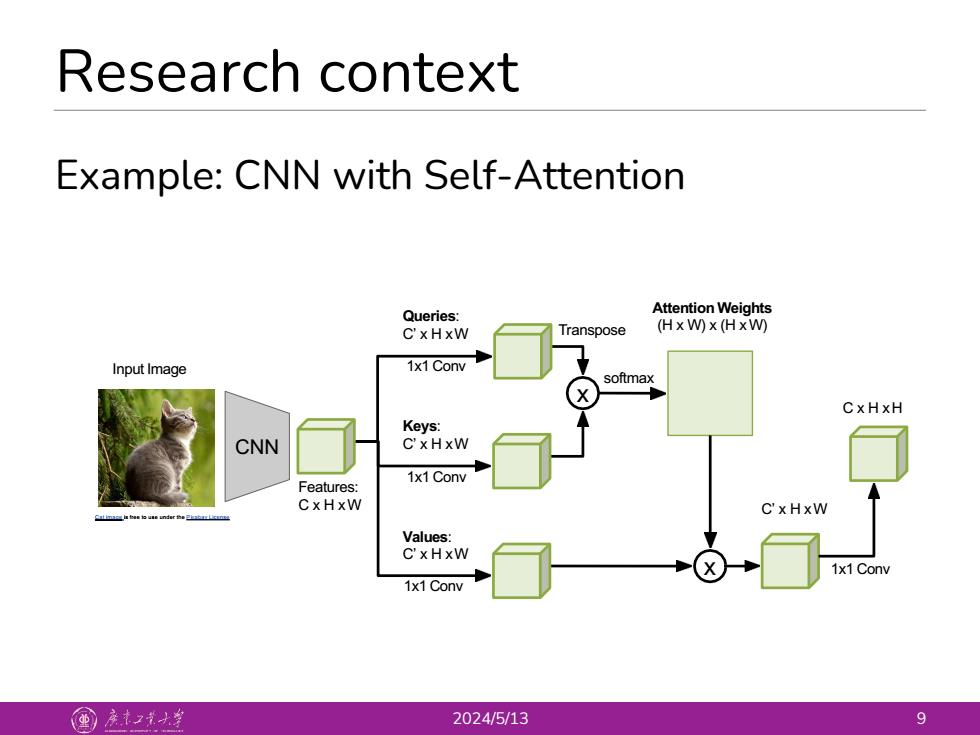
Research context Example:CNN with Self-Attention Queries: Attention Weights C'xHxW Transpose (HxW)x (HxW) Input Image 1x1 Conv softmax CxHxH Keys: CNN C'xHxW 1x1 Conv Features: CxHxW C'xHxW Values: C'xHxW 1x1 Conv 1x1 Conv 国产之大当 2024/5/13 9
Research context 2024/5/13 9 Example: CNN with Self-Attention Cat image is free to use under the Pixabay License Input Image CNN Features: C x H xW Queries: C’ x H xW Keys: C’ x H xW Values: C’ x H xW 1x1 Conv 1x1 Conv 1x1 Conv x Transpose softmax Attention Weights (H x W) x (H xW) x C’ x H xW 1x1 Conv C x H xH
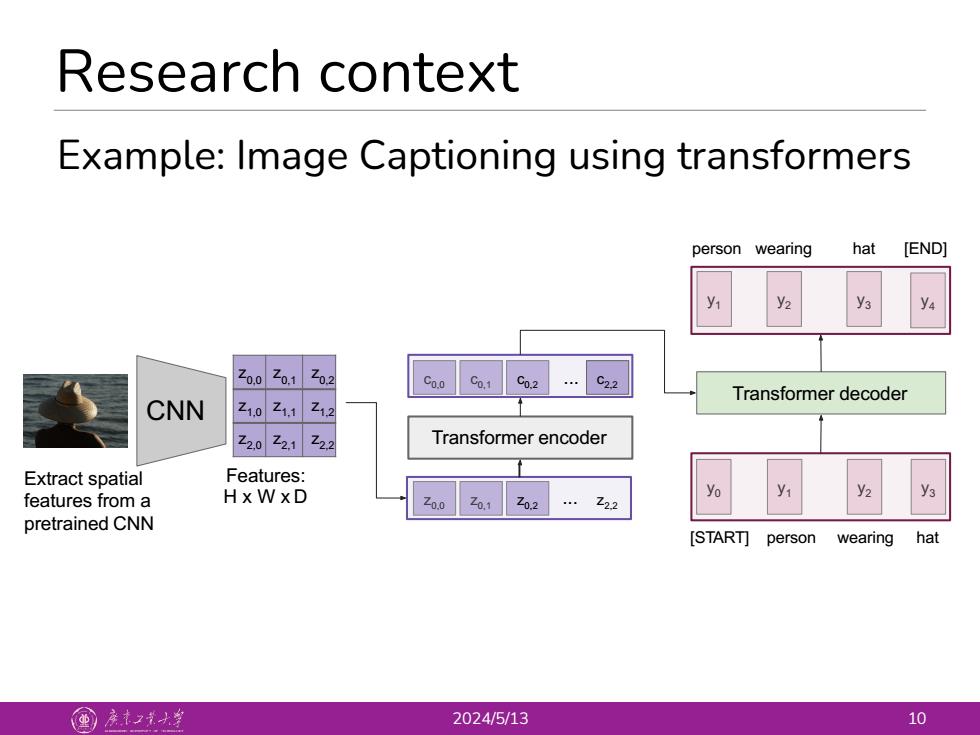
Research context Example:Image Captioning using transformers person wearing hat [END] y1 乙00Z01乙02 Co.0 Co.1 C0.2 C2.2 Z1,0 11Z1.2 Transformer decoder CNN 202122 Transformer encoder Extract spatial Features: features from a HxWXD .222 yo y2 y3 pretrained CNN [START]person wearing hat 国产之小生 2024/5/13 10
Research context 2024/5/13 10 Example: Image Captioning using transformers Extract spatial features from a pretrained CNN CNN Features: H x W x D z0,0 z0,1 z0,2 z1,0 z1,1 z1,2 z2,0 z2,1 z2,2 z0,0 z0,1 z0,2 z2,2 ... Transformer encoder c0,1 c0,0 c0,2 c2,2 ... y0 [START] person wearing hat y1 y2 y1 y3 y2 y4 y3 person wearing hat [END] Transformer decoder