
Unsupervised Learning: Deep Auto-encoder
Unsupervised Learning: Deep Auto-encoder

Unsupervised Learning "We expect unsupervised learning to become far more important in the longer term.Human and animal learning is largely unsupervised:we discover the structure of the world by observing it,not by being told the name of every object." LeCun,Bengio,Hinton,Nature 2015 As I've said in previous statements:most of human and animal learning is unsupervised learning.If intelligence was a cake, unsupervised learning would be the cake,supervised learning would be the icing on the cake,and reinforcement learning would be the cherry on the cake.We know how to make the icing and the cherry,but we don't know how to make the cake. Yann LeCun,March 14,2016(Facebook)
Unsupervised Learning “We expect unsupervised learning to become far more important in the longer term. Human and animal learning is largely unsupervised: we discover the structure of the world by observing it, not by being told the name of every object.” – LeCun, Bengio, Hinton, Nature 2015 As I've said in previous statements: most of human and animal learning is unsupervised learning. If intelligence was a cake, unsupervised learning would be the cake, supervised learning would be the icing on the cake, and reinforcement learning would be the cherry on the cake. We know how to make the icing and the cherry, but we don't know how to make the cake. - Yann LeCun, March 14, 2016 (Facebook)
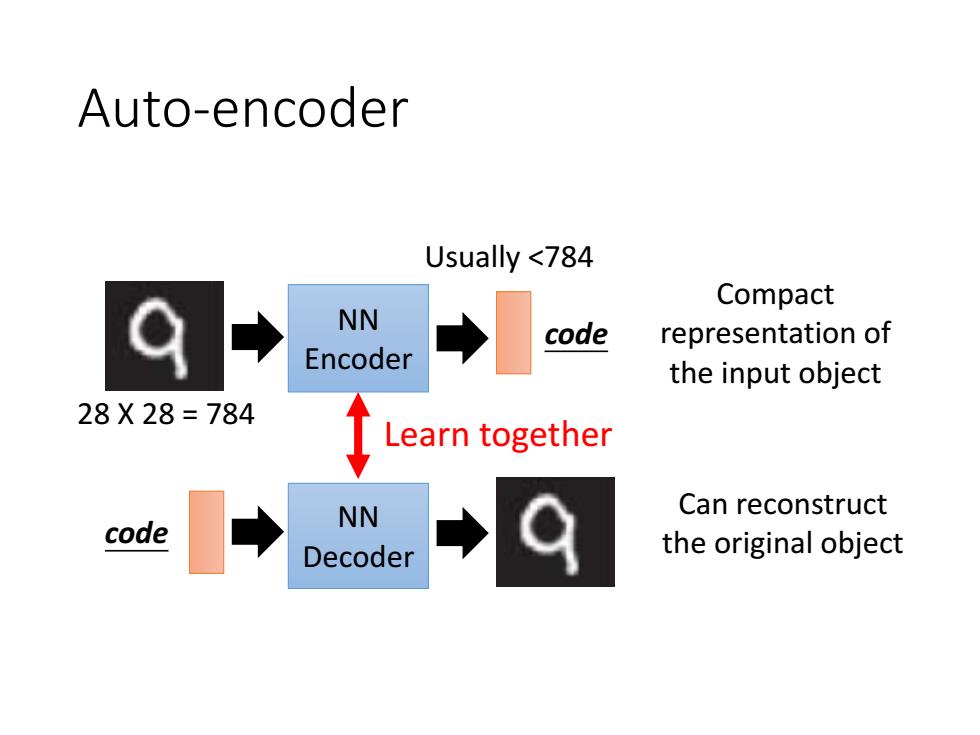
Auto-encoder Usually <784 Compact NN code representation of Encoder the input object 28X28=784 Learn together Can reconstruct code NN Decoder the original object
Auto-encoder NN Encoder NN Decoder code Compact representation of the input object code Can reconstruct the original object Learn together 28 X 28 = 784 Usually <784
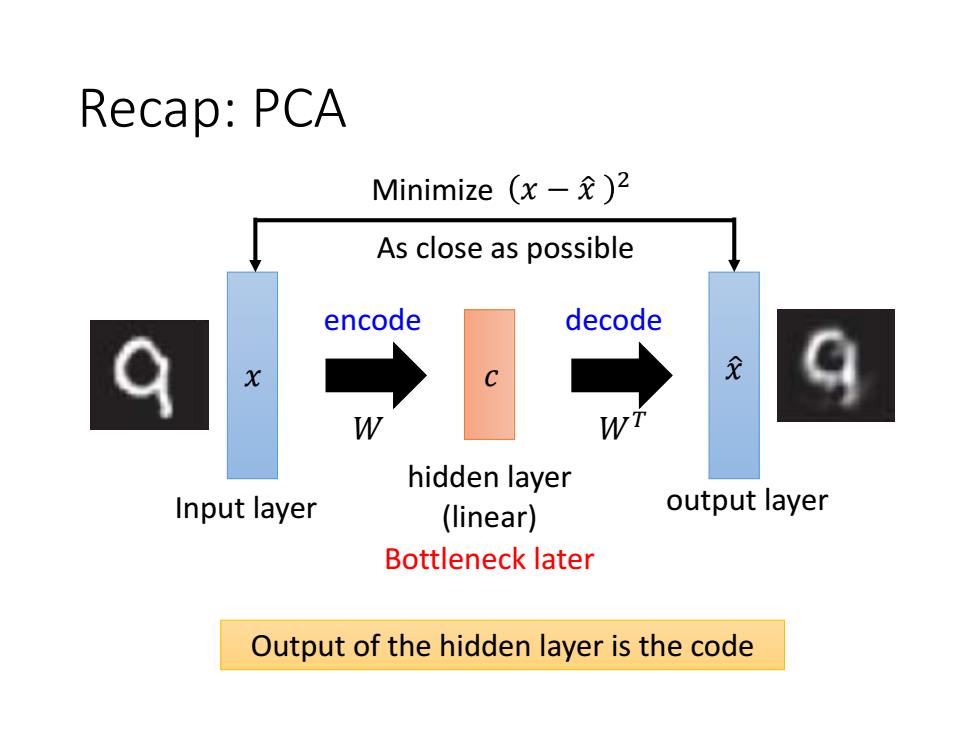
Recap:PCA Minimize(x-龙)2 As close as possible encode decode W hidden layer Input layer (linear) output layer Bottleneck later Output of the hidden layer is the code
Recap: PCA 𝑥 Input layer 𝑊 𝑥 ො 𝑊𝑇 output layer hidden layer (linear) 𝑐 As close as possible Minimize 𝑥 − 𝑥 ො 2 Bottleneck later Output of the hidden layer is the code encode decode

Deep Auto-encoder Symmetric is not necessary. Of course,the auto-encoder can be deep As close as possible W2 Initialize by RBM Code layer-by-layer Reference:Hinton,Geoffrey E.,and Ruslan R.Salakhutdinov."Reducing the dimensionality of data with neural networks."Science 313.5786(2006):504-507
Initialize by RBM layer-by-layer Reference: Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." Science 313.5786 (2006): 504-507 • Of course, the auto-encoder can be deep Deep Auto-encoder Input Layer Layer Layer bottle Output Layer Layer Layer Layer Layer … … Code As close as possible 𝑥 𝑥 ො 𝑊1 𝑊1 𝑇 𝑊2 𝑊2 𝑇 Symmetric is not necessary