
各式各樣的Attention Hung-yi Lee李宏毅
各式各樣的 Attention Hung-yi Lee 李宏毅

Prerequisite https://youtu.be/hYdO9CscNes https://youtu.be/gmsMY5kc-zw 【機器學習2021】自注意力 【機器學習2021】自注意力 機制(Self-attention)(上) 機制(Self-attention)(下)
Prerequisite https://youtu.be/hYdO9CscNes https://youtu.be/gmsMY5kc-zw 【機器學習2021】自注意力 機制 (Self-attention) (上) 【機器學習2021】自注意力 機制 (Self-attention) (下)
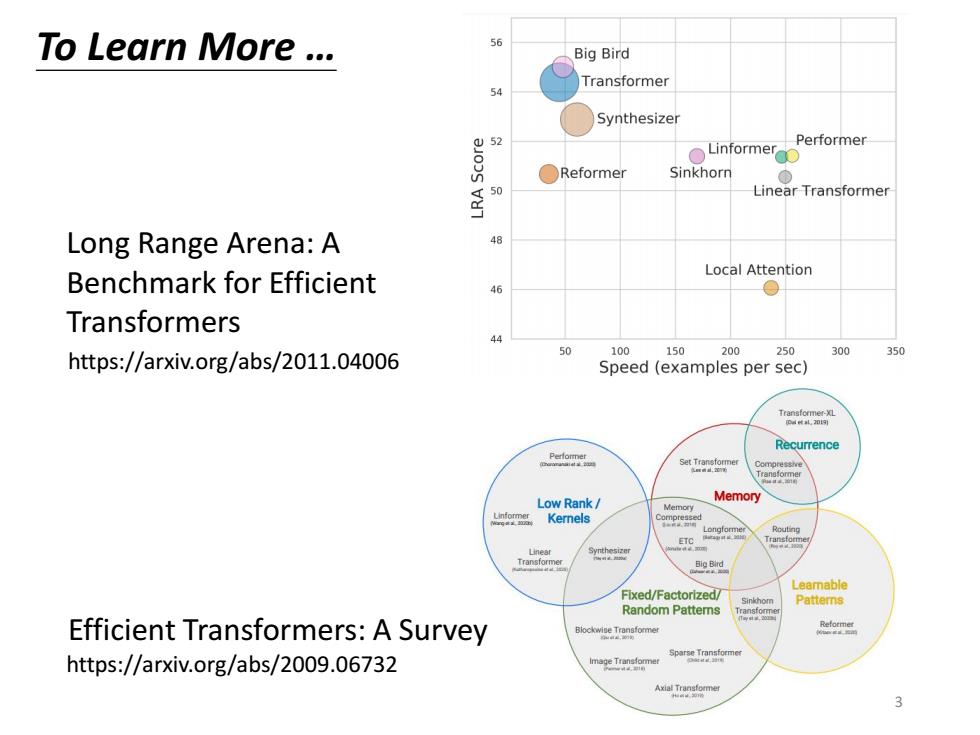
To Learn More.… Big Bird Transformer Synthesizer Performer ○Linformer ●Reformer Sinkhorn 0 Linear Transformer Long Range Arena:A Benchmark for Efficient Local Attention ● Transformers https://arxiv.org/abs/2011.04006 100 150 200 250 300 350 Speed (examples per sec) Recurrence Pefome sarTeiore Low Rank/ Memory Kernels ETC Transformer Synthe Big Bird Leamable Fixed/Factorlzed/ Patterns Random Patterns Efficient Transformers:A Survey eoe https://arxiv.org/abs/2009.06732 Axia
To Learn More … https://arxiv.org/abs/2009.06732 Efficient Transformers: A Survey Long Range Arena: A Benchmark for Efficient Transformers https://arxiv.org/abs/2011.04006 3
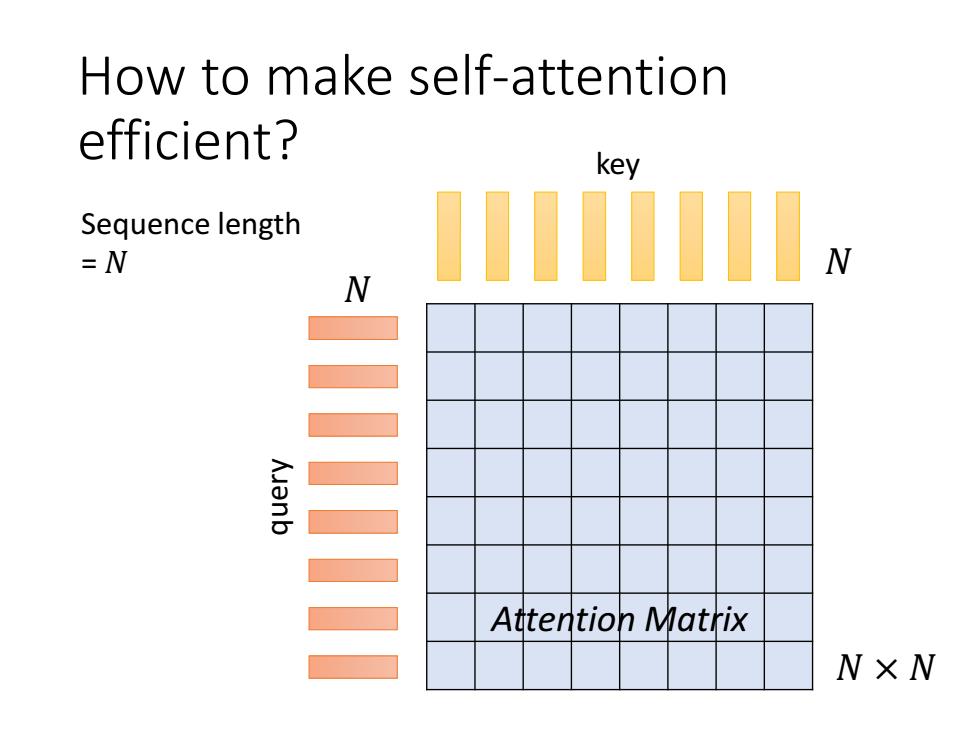
How to make self-attention efficient? key Sequence length =N anb 三三 Attention Matrix N×W
How to make self-attention efficient? Attention Matrix key query 𝑁 𝑁 𝑁 × 𝑁 Sequence length = 𝑁
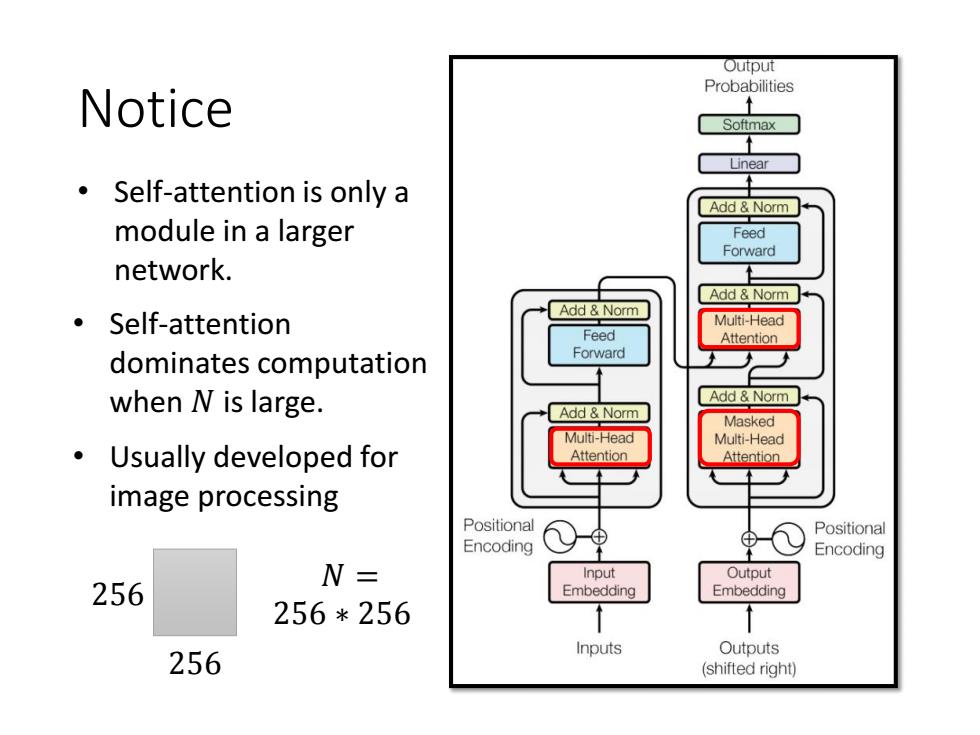
Output Probabilities Notice Softmax Self-attention is only a Add Norm module in a larger Feed Forward network. Add Norm Add Norm ·Self-attention Multi-Head Feed Attention dominates computation Forward when N is large. Add Norm Add Norm Masked Multi-Head Multi-Head Usually developed for Attention Attention image processing Positional Positional Encoding Encoding N= Input Output 256 Embedding Embedding 256*256 Inputs Outputs 256 (shifted right)
Notice • Self-attention is only a module in a larger network. • Self-attention dominates computation when 𝑁 is large. • Usually developed for image processing 𝑁 = 256 ∗ 256 256 256