
y[k]=x[π(k)小,keT 交织器通常采用下列方式来表示: 00 为简单起见,我们有时也用置换向量π=(π(O),π(,.,π(N-)来表示。 Let u=(u)be an information bit sequence of length N,where 4:∈0,1,1≤k≤N,它一方面直接进入第一个分量编码器RSC1进行卷积编码,另一方 面经过交织后变为长度相同但比特位置重新排列的序列。Lti=(a,立,iv)be the permuted sequence by the interleaver corresponding to the original information sequence u=(4,4,x),according to the mappingi立=4k,l≤k≤N.交织后的序列i进入第 二个分量编码器RSC2进行编码,这样我们就得到了两个不同的校验序列cP和2P。假 定图4.5中两个分量编码器的码率均是l/2,Since both encoders are systematic and operate on the same set of input bits,it is only necessary to transmit the input bits once,and the overall code has rate R=13.The overall codeword consists of the systematic bit sequencee -u and two parity bit sequences c'and c;that is,the codeword is given by c=(c).wherec=(N.is the output code block at time 为了提高turbo码的码率,除可以选用高码率(e.g,rate-2/3)的分量码外,还可以采 用删余(puncturing)技术从这两个校验序列中周期性地删除一些校验位,然后再与信 息序列(systematic sequence)c=u复用在一起送给数据调制器。例如,在图4.5中, In order to increase the rate of the turbo code to R=1/2,the two parity sequences can be punctured according to the following puncturing pattern(别余矩阵): where the 0's in the mth row of P indicates that the corresponding bit of the mth parity sequence will not be transmitted.即上述P矩阵表示别去来自RSCl的校验序列c'P的偶数 位置比特与来自RSC2的校验序列c2P的奇数位置比特。这样,采用别余技术后,turbo 编码器在k时刻的输出为c,=(G,c),其中c由和c”交替组成: 4-6
4-6 yk x k k ( ) , 交织器通常采用下列方式来表示: 1 2 (1) (2) ( ) N N 为简单起见,我们有时也用置换向量π (0), (1), , ( 1) N 来表示。 Let 1 2 , ,., N u uu u be an information bit sequence of length N, where {0,1},1 k u kN . 它一方面直接进入第一个分量编码器 RSC1 进行卷积编码,另一方 面经过交织后变为长度相同但比特位置重新排列的序列。Let u uu u 1 2 , ,., N be the permuted sequence by the interleaver corresponding to the original information sequence 1 2 , ,., N u uu u , according to the mapping ( ) ,1 k k u u kN . 交织后的序列u 进入第 二个分量编码器 RSC2 进行编码,这样我们就得到了两个不同的校验序列 1 2 p p c c 和 。假 定图 4.5 中两个分量编码器的码率均是 1/2, Since both encoders are systematic and operate on the same set of input bits, it is only necessary to transmit the input bits once, and the overall code has rate Rc = 1/3. The overall codeword consists of the systematic bit sequence c s = u and two parity bit sequences 1 2 p p c c and ; that is, the codeword is given by 1 2 , ,., N c cc c , where 1 2 , , ,1 sp p k kk k c cc c k N , is the output code block at time k. 为了提高 turbo 码的码率,除可以选用高码率(e.g., rate-2/3)的分量码外,还可以采 用删余(puncturing)技术从这两个校验序列中周期性地删除一些校验位,然后再与信 息序列(systematic sequence) s c u 复用在一起送给数据调制器。例如,在图 4.5 中, In order to increase the rate of the turbo code to Rc = 1/2, the two parity sequences can be punctured according to the following puncturing pattern(删余矩阵): 1 0 0 1 P where the 0’s in the mth row of P indicates that the corresponding bit of the mth parity sequence will not be transmitted. 即上述 P 矩阵表示删去来自 RSC1 的校验序列 1p c 的偶数 位置比特与来自 RSC2 的校验序列 2 p c 的奇数位置比特。这样,采用删余技术后,turbo 编码器在 k 时刻的输出为 (, ) s p k kk c c c ,其中 pp p 1 2 kk k cc c 由 和 交替组成:

-使a ifk is odd number Recursive Systematic Encoder 从图4.5可以看出,在tubo编码方案中两个分量码采用并行级联方式,并且编码 器结构为递归形式而不是传统的非递归编码器。一个递归编码器具有下面两个特点: >An RSC encoder has an infinite impulse response. An arbitrary input will cause a"good"(high weight)output with high probability. 从差错控制编码理论可知,非系统卷积码(NSC)的BER性能在高信噪比时比约 束长度相同的非递归系统码要好,而在低信噪比时情况却正好相反。递归系统卷积 (RSC)码综合了NSC码和系统码的特性,虽然它与NSC码具有相同的tr©is结构和 自由距离,但是在高码率(R≥2/3)的情况下,对任何信噪比,它的性能均比等效的 NSC码要好。因此,在turbo码中采用RSC码作为分量码。一个生成多项式为(37,21) (八进制表示)的16状态RSC编码器结构如图4.6所示,其生成矩阵表示为 1+D' G(D)=1 +D+D+D'+Di] c 图4.6G=(37,21)的RSC编码器 Pseudo-Random Interleaver 交织器虽然仅仅是在RSC2编码之前将信息序列中的N个比特的位置进行随机置 换,但它却起着关键的作用,很大程度地影响着turbo码的性能。 Shannon showed that large block-length random codes achieve channel capacity. However,its high decoding complexity prohibits its applications in practice.因此,多少年 来随机编码理论一直是作为分析与证明编码定理的主要方法,而如何在构造码上发挥作 4.7
4-7 1 2 , if is even number , if is odd number p p k k p k c k c c k 。 Recursive Systematic Encoder 从图 4.5 可以看出,在 turbo 编码方案中两个分量码采用并行级联方式,并且编码 器结构为递归形式而不是传统的非递归编码器。一个递归编码器具有下面两个特点: An RSC encoder has an infinite impulse response. An arbitrary input will cause a “good” (high weight) output with high probability. 从差错控制编码理论可知,非系统卷积码(NSC)的 BER 性能在高信噪比时比约 束长度相同的非递归系统码要好,而在低信噪比时情况却正好相反。递归系统卷积 (RSC)码综合了 NSC 码和系统码的特性,虽然它与 NSC 码具有相同的 trellis 结构和 自由距离,但是在高码率( Rc 2 3/ )的情况下,对任何信噪比,它的性能均比等效的 NSC 码要好。因此,在 turbo 码中采用 RSC 码作为分量码。一个生成多项式为(37,21) (八进制表示)的 16 状态 RSC 编码器结构如图 4.6 所示,其生成矩阵表示为 4 234 1 ( ) 1, 1 D G D DD D D 。 图 4.6 G = (37,21)的 RSC 编码器 Pseudo-Random Interleaver 交织器虽然仅仅是在 RSC2 编码之前将信息序列中的 N 个比特的位置进行随机置 换,但它却起着关键的作用,很大程度地影响着 turbo 码的性能。 Shannon showed that large block-length random codes achieve channel capacity. However,its high decoding complexity prohibits its applications in practice. 因此,多少年 来随机编码理论一直是作为分析与证明编码定理的主要方法,而如何在构造码上发挥作 k u s k c p k c

用却并未引起人们的足够重视。It has been recognized that codes with structure don't perform as well as random codes.The turbo coding method provides an effective solution to this problem: Make the code appear random.while maintaining enough structure to permit decoding. In turbo codes,this is achieved by the use of random interleaver.Interleaving has a role in shaping the weight distribution of the code,leading to that Turbo codes possess randomlike properties. 另一方面,通过随机交织,使得编码序列在长为2N或3N(不使用刑余)比特的范 围内具有记忆性,从而由简单的短码得到了长码。当交织器充分大时,tubo码就具有 近似于随机长码的特性。 ■一个例子 下面通过一个简单例子来具体说明Turbo码编码器的工作过程。 考虑图4.7(a)所示的Turbof码编码器,其中两个分量编码器均是4状态,码率为1/2 的(7,5),RSC编码器,其生成矩阵为 1+D2 G(D)=1.1+D+D 分量编码器的trellis图如图4.7(b)所示。 令u表示turbo编码器的输入信息比特序列,i表示交织器的输出序列。假定采用一个size 为7的伪随机交织器 π7=(4.1,6,3,5.7,2), 则有元=4,2=4等等 如果输入序列u=(101100),则c'=(1011001),图4.7(b)中上面的RSC编码器的状态 转移为: 0112001→310310→300110201 对应的输出校验序列cP=(1100100)。 经过交织后的序列i=(1101010),从而下面的RSC编码器的输出校验序列 c2p=(1000000). 所以,未经删余的码率为1/3的turbo码编码器输出码字为
4-8 用却并未引起人们的足够重视。It has been recognized that codes with structure don’t perform as well as random codes. The turbo coding method provides an effective solution to this problem: Make the code appear random, while maintaining enough structure to permit decoding. In turbo codes, this is achieved by the use of random interleaver. Interleaving has a role in shaping the weight distribution of the code, leading to that Turbo codes possess random-like properties. 另一方面,通过随机交织,使得编码序列在长为 2N 或 3N(不使用删余)比特的范 围内具有记忆性,从而由简单的短码得到了长码。当交织器充分大时,turbo 码就具有 近似于随机长码的特性。 一个例子 下面通过一个简单例子来具体说明Turbo码编码器的工作过程。 考虑图4.7(a)所示的Turbo码编码器,其中两个分量编码器均是4状态,码率为1/2 的 8 (7,5) RSC编码器,其生成矩阵为 2 2 1 ( ) 1, 1 D G D D D 分量编码器的trellis图如图4.7(b)所示。 令u表示turbo编码器的输入信息比特序列, u 表示交织器的输出序列。假定采用一个size 为7的伪随机交织器 7 = (4, 1, 6, 3, 5, 7, 2), 则有 1 42 1 u uu u , 等等。 如果输入序列u (1011001),则 (1011001) s c ,图4.7(b)中上面的RSC编码器的状态 转移为: 1/11 0/ 01 1/10 1/10 0/ 01 0/00 1/10 02 3331 21 对应的输出校验序列 1 (1100100) p c 。 经过交织后的序列 u (1101010) ,从而下面的 RSC 编码器的输出校验序列 2 (1000000) p c 。 所以,未经删余的码率为1/3的turbo码编码器输出码字为
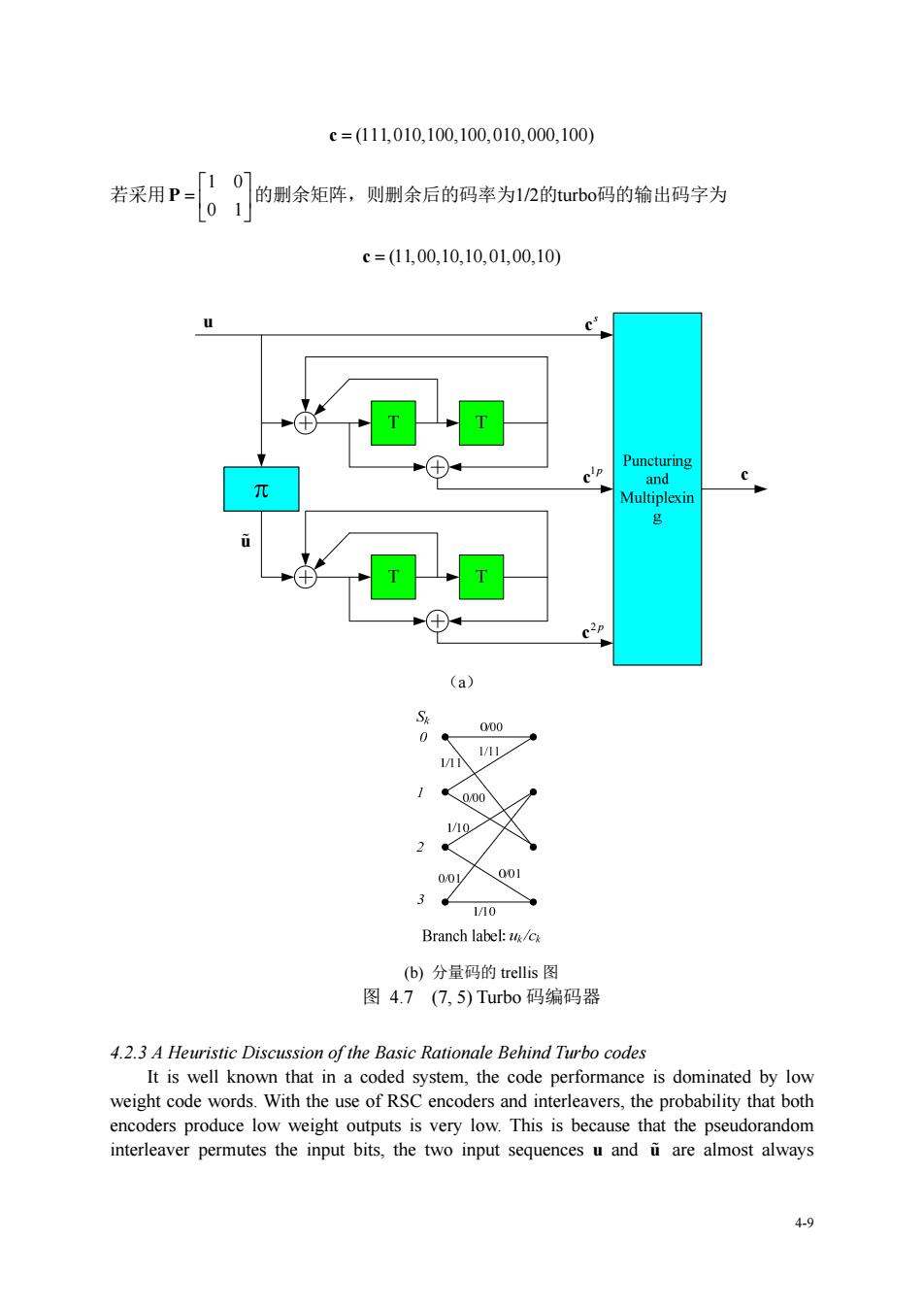
c=111,010,100,100,010,000,100) 若采用P=10 的删余矩阵,则刷余后的码率为1/2的ubo码的输出码字为 01 c=(11,00,10,10,01,00,10) c +⊕ 十 001 Branch label:/c (b)分量码的trellis图 图4.7(7,5)Turbo码编码器 4.2.3 A Heuristic Discussion of the Basic Rationale Behind Turbo codes It is well known that in a coded system,the code performance is dominated by low weight code words.With the use of RSC encoders and interleavers,the probability that both encoders produce low weight outputs is very low.This is because that the pseudorandom interleaver permutes the input bits,the two input sequences u and i are almost always 4.9
4-9 c (111,010,100,100,010,000,100) 若采用 1 0 0 1 P 的删余矩阵,则删余后的码率为1/2的turbo码的输出码字为 c (11,00,10,10,01,00,10) u 1p c 2 p c s u c c (a) (b) 分量码的 trellis 图 图 4.7 (7, 5) Turbo 码编码器 4.2.3 A Heuristic Discussion of the Basic Rationale Behind Turbo codes It is well known that in a coded system, the code performance is dominated by low weight code words. With the use of RSC encoders and interleavers, the probability that both encoders produce low weight outputs is very low. This is because that the pseudorandom interleaver permutes the input bits, the two input sequences u and u are almost always

different,though of the same weight,and the two encoders will (with high probability) e parity seque es of differer weights This allel concatenation of RSC codes.Refer to Fig.4.8. T the parity ith thusfiv comintereanthrist ad (4.1)involves (approximately)independent and identically distributed random variables.The resulting code will have properties very close to those of random codes,and the latter are well-known"good"codes. Systematic par y) (identity) Y2 YN (b) Figure 4.8 a)In this multiple parallel concatenation of Circular RSC (CRSC)codes,the block containing k information bits is encoded N times.The probability that the sequence remains of the RTZ(retrn tozero)type after the N pseudorandom permutations is very low.The properties ofthis very close to those of random codes.b)The mumber of encodings can be limitedto o provided that permutation devised.This isa classical turbo code. As Dave Forney pointed out:Rather than attacking error exponents,they (turbo codes)attack multiplicities. Remark:Good long codes should have a distribution which mimics that of random coding rather than have a large minimum distance Since the constituent encoders are realized in recursive systematic form,a nonzero input bit is required to return the encoder to the all-zero state and thus all detours are associated with information sequences of weight 2 or greater,at least one for departure,and one for the oding perfo eanalysis show that the e error paths with the minimum id thir compound paths dominate the BERperom of turbo codes.Let min denote the lowest weight of the parity check sequence in error paths of 4-10
4-10 different, though of the same weight, and the two encoders will (with high probability) produce parity sequences of different weights. This can be generalized to multiple parallel concatenation of RSC codes. Refer to Fig. 4.8. Let w be the total parity weight obtained after concatenating. Then, w = theparity weights of M component codes (4.1) With the use of recursive component codes and random interleaving, the right hand side of (4.1) involves (approximately) independent and identically distributed random variables. The resulting code will have properties very close to those of random codes, and the latter are well-known “good” codes. Figure 4.8 a) In this multiple parallel concatenation of Circular RSC (CRSC) codes, the block containing k information bits is encoded N times. The probability that the sequence remains of the RTZ(return to zero) type after the N pseudorandom permutations is very low. The properties of this multiconcatenated code are very close to those of random codes. b) The number of encodings can be limited to two, provided that permutation Π2 is judiciously devised. This is a classical turbo code. As Dave Forney pointed out: Rather than attacking error exponents, they (turbo codes) attack multiplicities. Remark: Good long codes should have a distribution which mimics that of random coding rather than have a large minimum distance. Since the constituent encoders are realized in recursive systematic form, a nonzero input bit is required to return the encoder to the all-zero state and thus all detours are associated with information sequences of weight 2 or greater, at least one for departure, and one for the merger. The ML decoding performance analysis shows that the error paths with the minimum information weight wmin = 2 and their compound paths dominate the BER performance of turbo codes. Let zmin denote the lowest weight of the parity check sequence in error paths of