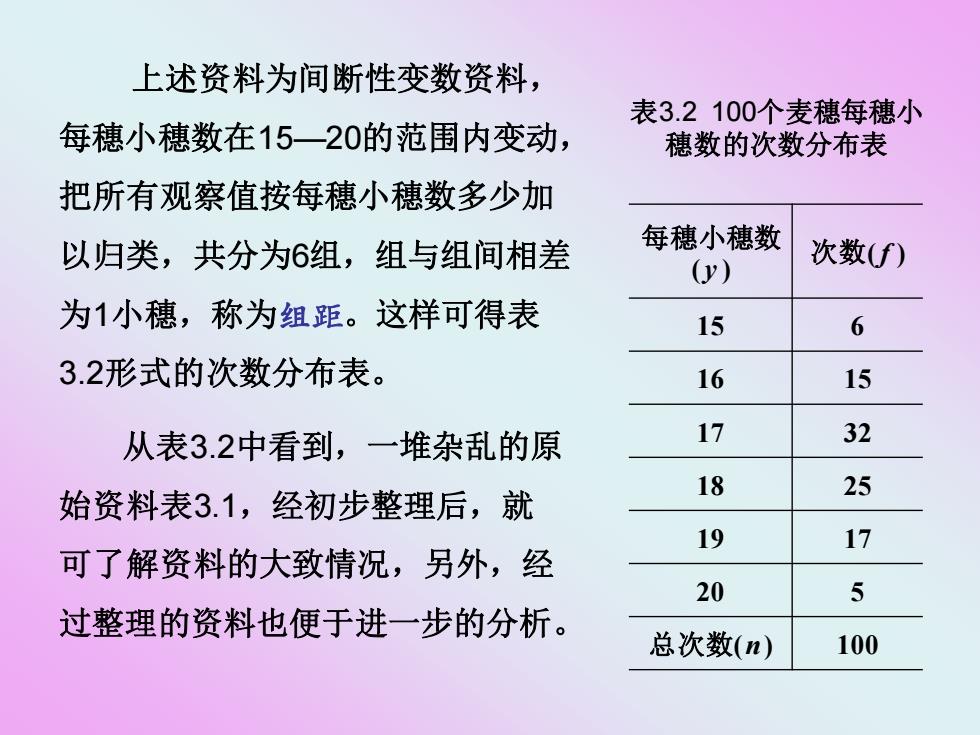
上述资料为间断性变数资料, 表3.2100个麦穗每穗小 每穗小穗数在15一20的范围内变动, 穗数的次数分布表 把所有观察值按每穗小穗数多少加 以归类,共分为6组,组与组间相差 每穗小穗数 次数(f) (y) 为1小穗,称为组距。这样可得表 15 6 3.2形式的次数分布表。 16 15 从表3.2中看到,一堆杂乱的原 17 32 18 25 始资料表3.1,经初步整理后,就 19 17 可了解资料的大致情况,另外,经 20 5 过整理的资料也便于进一步的分析。 总次数(n) 100
每穗小穗数 ( y ) 次数( f ) 15 6 16 15 17 32 18 25 19 17 20 5 总次数(n) 100 表3.2 100个麦穗每穗小 穗数的次数分布表 从表3.2中看到,一堆杂乱的原 始资料表3.1,经初步整理后,就 可了解资料的大致情况,另外,经 过整理的资料也便于进一步的分析。 上述资料为间断性变数资料, 每穗小穗数在15—20的范围内变动, 把所有观察值按每穗小穗数多少加 以归类,共分为6组,组与组间相差 为1小穗,称为组距。这样可得表 3.2形式的次数分布表
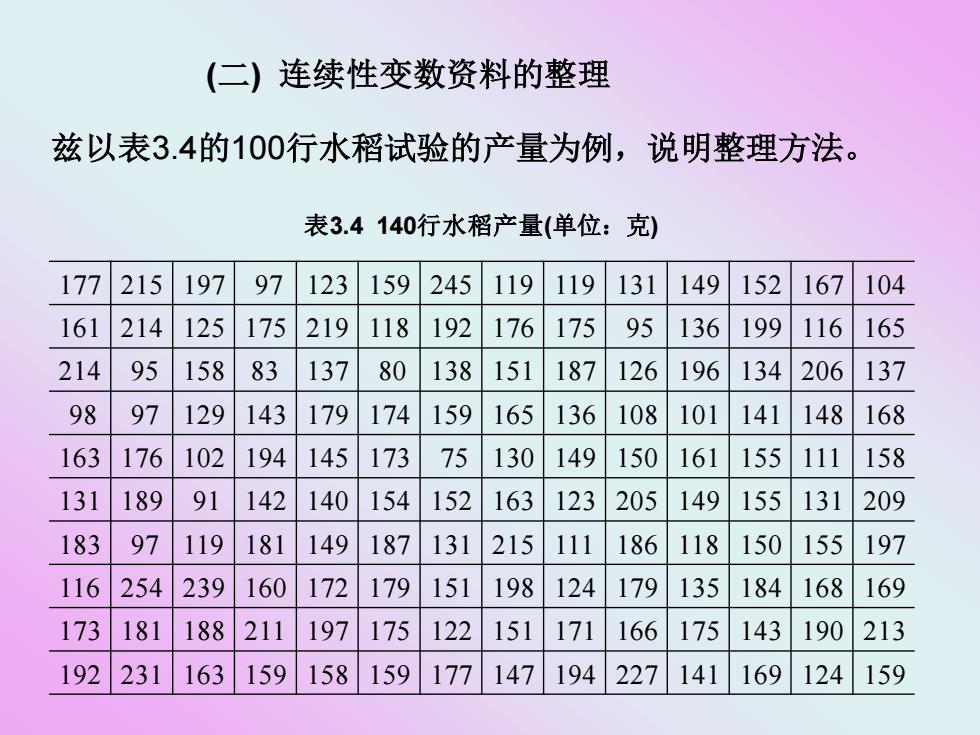
(二) 连续性变数资料的整理 兹以表3.4的100行水稻试验的产量为例,说明整理方法。 表3.4140行水稻产量(单位:克) 177215 197 97 123 159 245 119 119 131 149 152 167 104 161 214 125 175 219 118 192 176 175 95 136 199 116 165 214 95 158 83 137 80 138 151 187 126 196 134 206 137 98 97 129 143 179 174 159 165 136 108 101 141 148 168 163 176 102 194 145 173 75 130 149 150 161 155 111 158 131 189 91 142 140 154 152 163 123 205 149 155 131 209 183 97 119 181 149 187 131 215 111 186 118 150 155 197 116 254 239 160 172 179 151 198 124 179 135 184 168 169 173 181 188 211 197 175 122 151 171 166 175 143 190 213 192 231 163 159 158 159 177 147 194 227 141 169 124 159
(二) 连续性变数资料的整理 兹以表3.4的100行水稻试验的产量为例,说明整理方法。 177 215 197 97 123 159 245 119 119 131 149 152 167 104 161 214 125 175 219 118 192 176 175 95 136 199 116 165 214 95 158 83 137 80 138 151 187 126 196 134 206 137 98 97 129 143 179 174 159 165 136 108 101 141 148 168 163 176 102 194 145 173 75 130 149 150 161 155 111 158 131 189 91 142 140 154 152 163 123 205 149 155 131 209 183 97 119 181 149 187 131 215 111 186 118 150 155 197 116 254 239 160 172 179 151 198 124 179 135 184 168 169 173 181 188 211 197 175 122 151 171 166 175 143 190 213 192 231 163 159 158 159 177 147 194 227 141 169 124 159 表3.4 140行水稻产量(单位:克)

具体步骤: 1.数据排序(so)首先对数据按从小到大排列(升序) 或从大到小排列(降序)。 2.求极差(range))所有数据中的最大观察值和最小 观察值的差数,称为极差,亦即整个样本的变异幅度。 从表3.4中查到最大观察值为254g,最小观察值为75g, 极差为254一75=179g
具体步骤: 1. 数据排序(sort) 首先对数据按从小到大排列(升序) 或从大到小排列(降序)。 2. 求极差(range) 所有数据中的最大观察值和最小 观察值的差数,称为极差,亦即整个样本的变异幅度。 从表3.4中查到最大观察值为254g,最小观察值为75g, 极差为254-75=179g

3.确定组数和组距(class interval)根据极差分为若 干组,每组的距离相等,称为组距。在确定组数和组距 时应考虑: (1)观察值个数的多少; (2)极差的大小; (3)便于计算; (4)能反映出资料的真实面貌等方面。 样本大小(即样本内包含观察值的个数的多少)与组 数多少的关系可参照表3.5来确定
3. 确定组数和组距( class interval ) 根据极差分为若 干组,每组的距离相等,称为组距。 在确定组数和组距 时应考虑: (1)观察值个数的多少; (2)极差的大小; (3)便于计算; (4)能反映出资料的真实面貌等方面。 样本大小(即样本内包含观察值的个数的多少)与组 数多少的关系可参照表3.5来确定

组数确定后,还须 表3.5样本容量与组数多少的关系 确定组距。组距=极差) 样本内观察值的个数 分组时的组数 组数。以表3.4中140行 50 5-10 水稻产量为例,样本内 100 8-16 200 10—20 观察值的个数为140, 300 12-24 查表3.5可分为8一16组, 500 15-30 假定分为12组, 1000 20—40 则组距为179/12=14.9g,为分组方便起见,可以15g作为组距
表3.5 样本容量与组数多少的关系 样本内观察值的个数 分组时的组数 50 5—10 100 8—16 200 10—20 300 12—24 500 15—30 1000 20—40 组数确定后,还须 确定组距。组距=极差/ 组数。以表3.4中140行 水稻产量为例,样本内 观察值的个数为140, 查表3.5可分为8—16组, 假定分为12组, 则组距为179/12=14.9g,为分组方便起见,可以15g作为组距