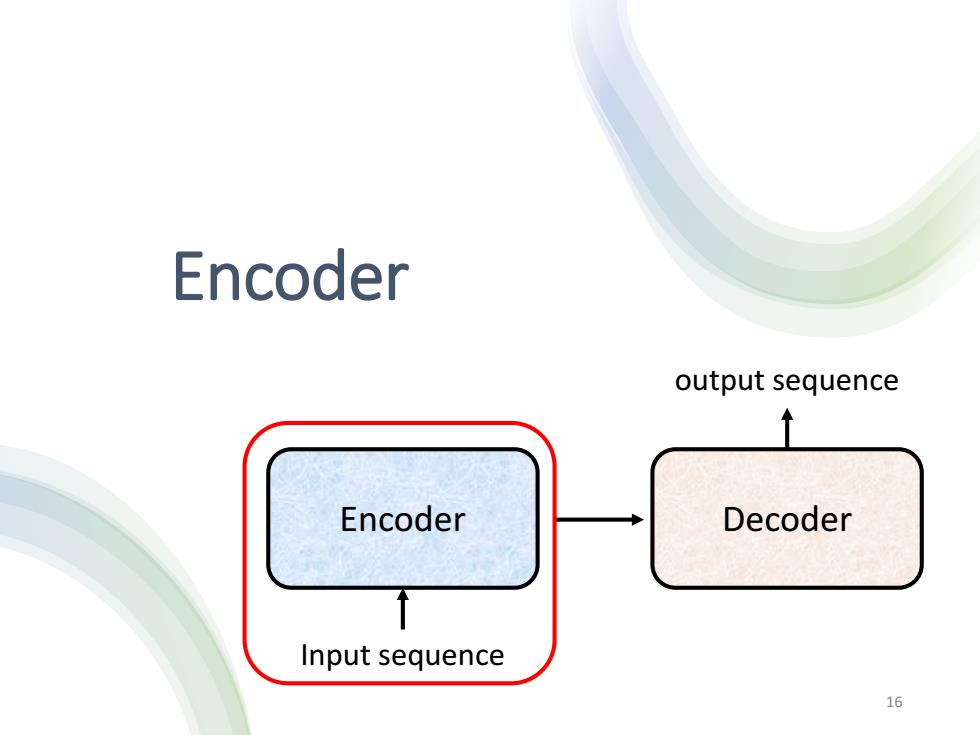
Encoder output sequence Encoder Decoder Input sequence 16
Encoder Encoder Decoder Input sequence output sequence 16
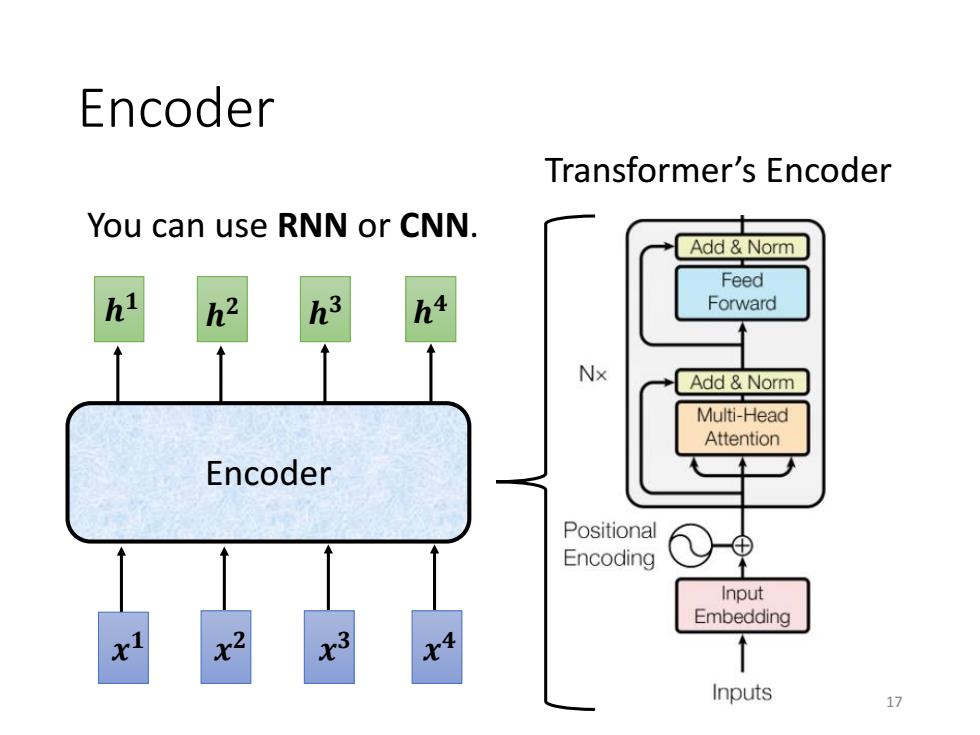
Encoder Transformer's Encoder You can use RNN or CNN. Add Norm Feed hi h2 Forward Nx Add Norm Multi-Head Attention Encoder Positional Encoding ⊕ 个 Input Embedding 2 ↑ Inputs 11
Encoder Encoder 𝒉 𝟒 𝒉 𝟑 𝒉 𝒉 𝟏 𝟐 𝒙 𝟒 𝒙 𝟑 𝒙 𝟐 𝒙 𝟏 Transformer’s Encoder You can use RNN or CNN. 17
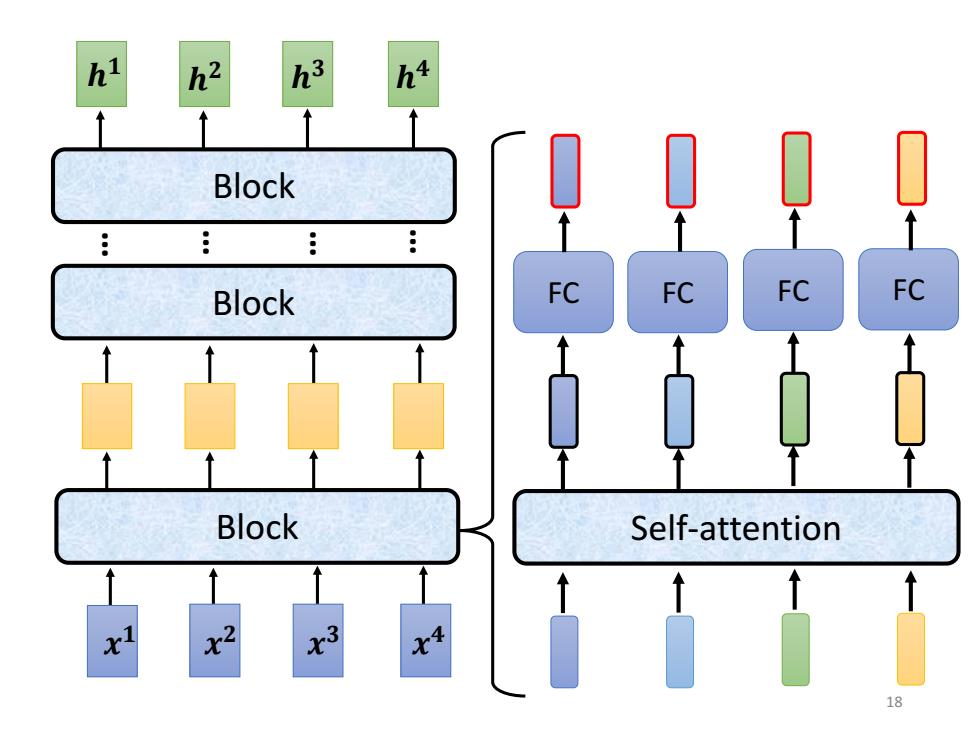
h2 h3 h4 Block Block FC FC FC FC Block Self-attention 3 .4 18
𝒉 𝟒 𝒉 𝟑 𝒉 𝒉 𝟏 𝟐 𝒙 𝟒 𝒙 𝟑 𝒙 𝟐 𝒙 𝟏 Block Block Block … … … … FC FC FC FC Self-attention 18
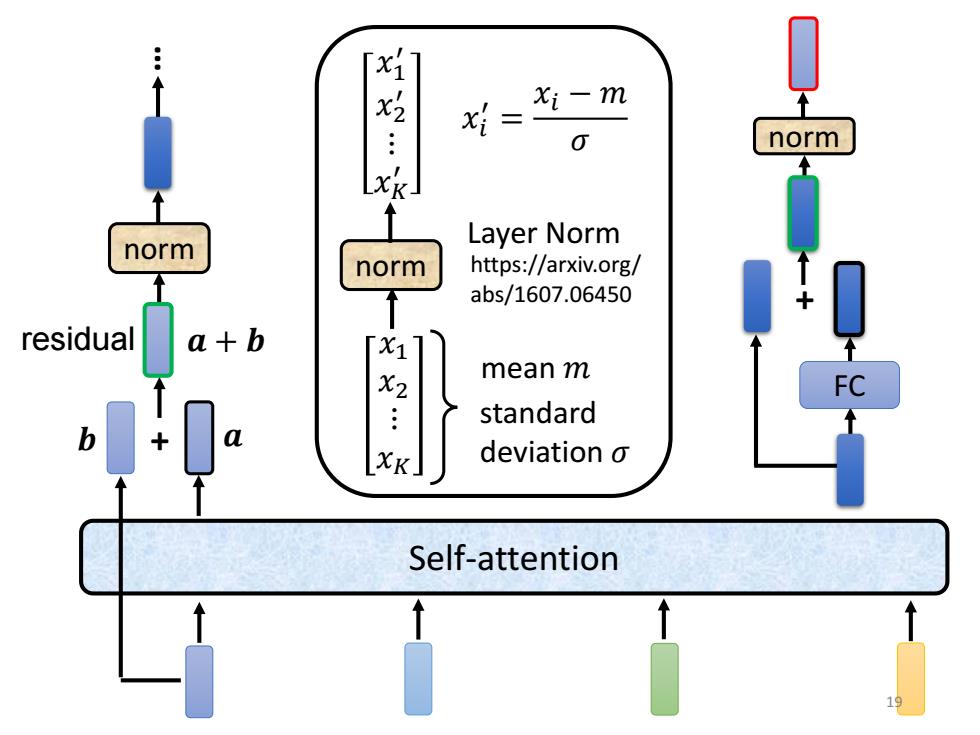
「xi1 xi Xi- m x= 0 norm x Layer Norm norm norm https://arxiv.org/ abs/1607.06450 residual a+b x1 mean m FC standard deviation o Self-attention
Self-attention + norm norm … norm 𝑥1 𝑥2 ⋮ 𝑥𝐾 𝑥1 ′ 𝑥2 ′ ⋮ 𝑥𝐾 ′ mean 𝑚 https://arxiv.org/ abs/1607.06450 Layer Norm 𝑥𝑖 ′ = 𝑥𝑖 − 𝑚 𝜎 standard deviation 𝜎 + 𝒃 𝒂 𝒂 + 𝒃 FC residual 19
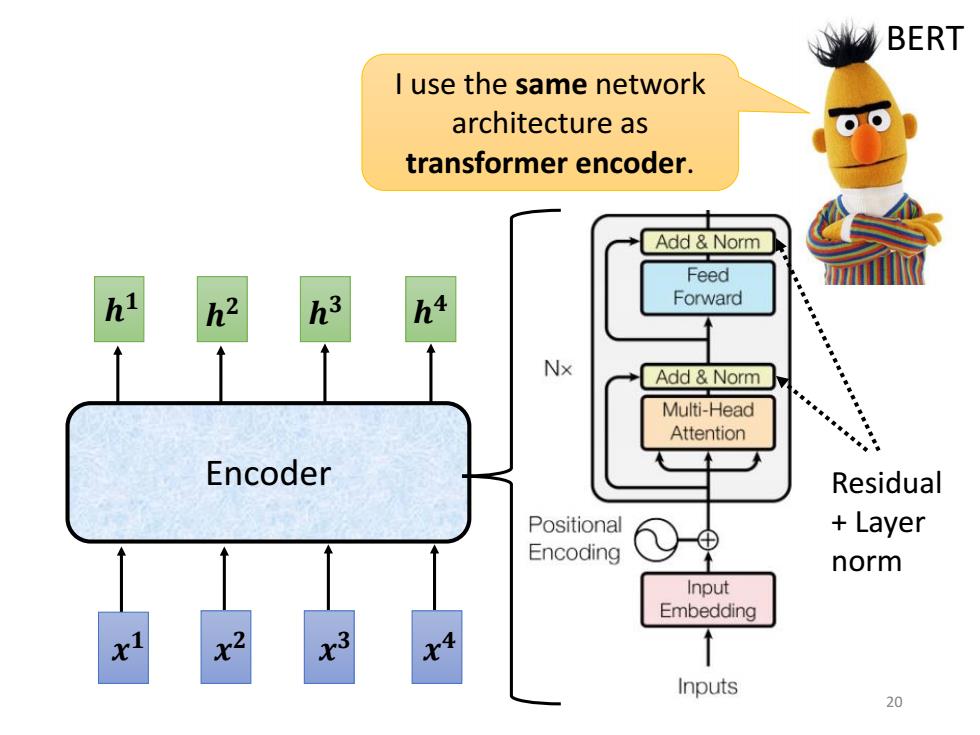
BERT I use the same network architecture as transformer encoder. Add Norm Feed h2 h3 Forward Nx Add Norm Multi-Head Attention Encoder Residual Positional Layer Encoding norm Input Embedding 2 3 Inputs 20
Encoder 𝒉 𝟒 𝒉 𝟑 𝒉 𝒉 𝟏 𝟐 𝒙 𝟒 𝒙 𝟑 𝒙 𝟐 𝒙 𝟏 I use the same network architecture as transformer encoder. BERT Residual + Layer norm 20