
面些毛子种枝大票 知识表示学习 XIDIAN UNIVERSITY 什么是知识表示学习? ● 简单的说,知识表示学习就是将知识图谱中的实体和关系表示成 低维向量。 ●基于实体和关系的表示,就可以完成各种推理、预测任务。 2
知识表示学习 2 • 什么是知识表示学习? 简单的说,知识表示学习就是将知识图谱中的实体和关系表示成 低维向量。 基于实体和关系的表示,就可以完成各种推理、预测任务

历安毛子代枚大浮 知识表示学习 XIDIAN UNIVERSITY ▣知识表示学习的方法有哪些: ·基于翻译的表示学习方法。 把表示学习看成翻译空间的翻译操作 ·图神经网络方法。 R-GCN Input DistMult 图神经网络由于其天然的可以处理 函 图结构数据,而知识图谱属于图结 h7Mt Score 构数据,因此展现出了良好的表达 能力,与传统的神经网络作出区分。 Encoder Decoder ·基于信息融合的方法。 在翻译模型的基础上融合语言信息。 3
知识表示学习 3 知识表示学习的方法有哪些: • 基于翻译的表示学习方法。 把表示学习看成翻译空间的翻译操作 • 图神经网络方法。 • 基于信息融合的方法。 在翻译模型的基础上融合语言信息。 Score Encoder Decoder T h M t Input R-GCN DistMult 图神经网络由于其天然的可以处理 图结构数据,而知识图谱属于图结 构数据,因此展现出了良好的表达 能力,与传统的神经网络作出区分
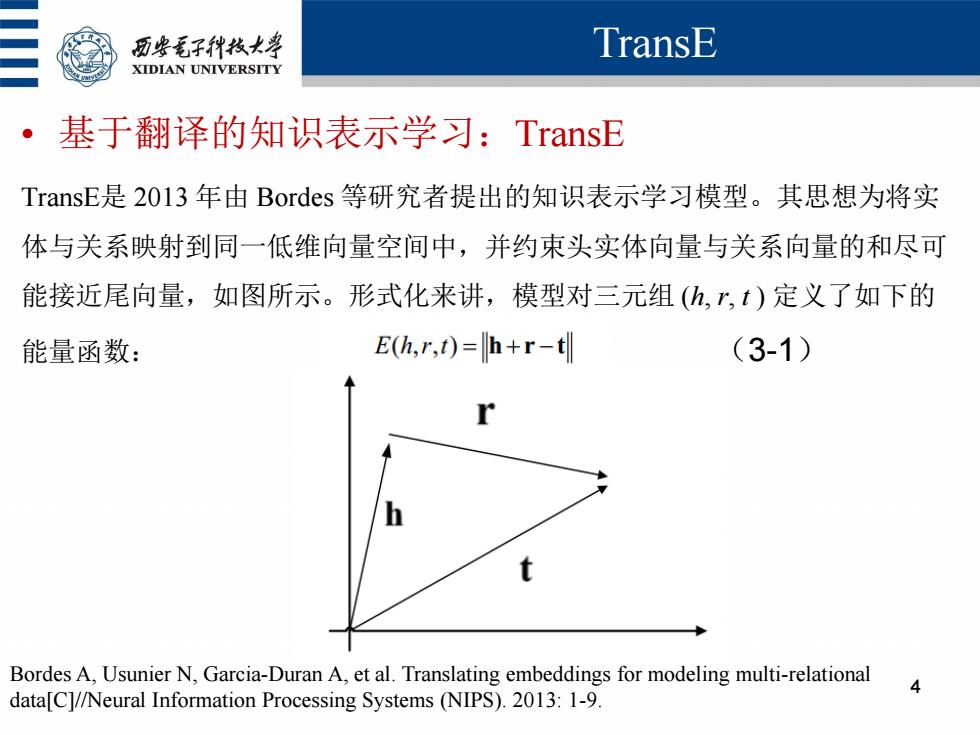
历安毛子代枚大学 TransE XIDIAN UNIVERSITY 。基于翻译的知识表示学习:TransE TransE是2013年由Bordes等研究者提出的知识表示学习模型。其思想为将实 体与关系映射到同一低维向量空间中,并约束头实体向量与关系向量的和尽可 能接近尾向量,如图所示。形式化来讲,模型对三元组(h,r,t)定义了如下的 能量函数: E(h,r,t)=h+r-t (3-1) Bordes A,Usunier N,Garcia-Duran A,et al.Translating embeddings for modeling multi-relational data[C]//Neural Information Processing Systems (NIPS).2013:1-9
TransE 4 • 基于翻译的知识表示学习:TransE TransE是 2013 年由 Bordes 等研究者提出的知识表示学习模型。其思想为将实 体与关系映射到同一低维向量空间中,并约束头实体向量与关系向量的和尽可 能接近尾向量,如图所示。形式化来讲,模型对三元组 (h, r, t ) 定义了如下的 能量函数: (3-1) Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[C]//Neural Information Processing Systems (NIPS). 2013: 1-9

历安毛子代枚大学 TransE XIDIAN UNIVERSITY ·基于翻译的知识表示学习:TransE 对于正例三元组,能量函数的值应非常小,对于负例三元组,能量函数的值应 该非常大。因此,在训练中,TrasnE使用了最大化间隔的损失函数进行优化 ,损失函数定义如下 L=∑∑max(y+Eh,t)-Eh,,t),0) (3-2) (hrt)eS(ri)eS 其中,y为正负例三元组得分的最大间隔,(h,,)为正例三元组,(h,,t)为 负例三元组。 5
TransE 5 • 基于翻译的知识表示学习:TransE 对于正例三元组,能量函数的值应非常小,对于负例三元组,能量函数的值应 该非常大。因此,在训练中,TrasnE 使用了最大化间隔的损失函数进行优化 ,损失函数定义如下 (3-2) 其中,γ为正负例三元组得分的最大间隔,(ℎ,r,t) 为正例三元组,(ℎ’,r,t’) 为 负例三元组

历安毛子代枚大学 TransR XIDIAN UNIVERSITY ·基于翻译的知识表示学习:TransR 问题:知识图谱中的复杂关系有一对多、多对一和多对多三种。以职业这个关系 为例子,我们从谷歌搜索引擎获取有(姚明,职业,运动员)和(姚明,职业, 企业家)。按照TransE的假设,会使运动员与企业家的向量表示接近,但事实 上两者有很大的差别。为缓解以上问题,人们相继提出TransR模型1],TransH 模型[2],TransD模型[3] 方法:TransR模型是2015年由Lin等人提出的知识表示学习模型,将实体与关 系映射到不同的空间中。翻译操作在关系空间进行:通过关系矩阵,将实体由实 体空间转换到关系空间。在关系空间中使得头实体映射向量与关系向量的和与尾 实体向量接近,以此为目标进行表示学习。 [1]Lin Y,Liu Z,Sun M,et al.Learning entity and relation embeddings for knowledge graph completion[C]//Proceedings of the AAAI Conference on Artificial Intelligence.2015,29(1)
TransR 6 • 基于翻译的知识表示学习:TransR 问题:知识图谱中的复杂关系有一对多、多对一和多对多三种。以职业这个关系 为例子,我们从谷歌搜索引擎获取有(姚明,职业,运动员)和(姚明,职业, 企业家)。按照 TransE 的假设,会使运动员与企业家的向量表示接近,但事实 上两者有很大的差别。为缓解以上问题,人们相继提出 TransR 模型[1],TransH 模型[2],TransD 模型[3] 方法:TransR模型是 2015 年由 Lin 等人提出的知识表示学习模型,将实体与关 系映射到不同的空间中。翻译操作在关系空间进行:通过关系矩阵,将实体由实 体空间转换到关系空间。在关系空间中使得头实体映射向量与关系向量的和与尾 实体向量接近,以此为目标进行表示学习。 [1]Lin Y, Liu Z, Sun M, et al. Learning entity and relation embeddings for knowledge graph completion[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2015, 29(1)