
如何构建好的集成 期望结果 期望结果 个体1(精度33.3%) 个体1(精度33.3%) 个体2(精度33.3%) 集成(精度33.3%) 个体2(精度33.3%) 集成(精度0%) 个体3(精度33.3%) 个体3(精度33.3%) 投票 投票 个体必须有差异 个体精度不能太低 EE-4 IA.Krogh &Vedelsby,NIPS94] 个体学习器越精确、差异越大,集成越好
期望结果 个体1 (精度33.3%) 个体2 (精度33.3%) 个体3 (精度33.3%) 集成(精度33.3%) 投票 个体必须有差异 期望结果 个体1 (精度33.3%) 个体2 (精度33.3%) 个体3 (精度33.3%) 集成 (精度0%) 投票 个体精度不能太低 E E A = − 个体学习器越精确、差异越大,集成越好 [A. Krogh & J. Vedelsby, NIPS94] 如何构建好的集成

个体越多越好吗? 既然多个个体的集成比单个个体更好,那么是 不是个体越多越好? 更多的个体意味着: ·在预测时需要更大的计算开销,因为要计算更多的个体预测 ·更大的存储开销,因为有更多的个体需要保存 个体的增加将使得个体间的差异越来越难以获得
既然多个个体的集成比单个个体更好,那么是 不是个体越多越好? 更多的个体意味着: • 在预测时需要更大的计算开销,因为要计算更多的个体预测 • 更大的存储开销,因为有更多的个体需要保存 个体的增加将使得个体间的差异越来越难以获得 个体越多越好吗?

选择性集成 Many Could be Better Than All:在有一组个体学习 器可用时,从中选择一部分进行集成,可能比用所有 个体学习器进行集成更好 [Z.-H.Zhou et al.,AIJ02] 从一组个体学习器中排除出去的个体(k)应满足: 分类 (2w-1)22C,≤2w22C4+N2E 回归 立Sgn((Sumn,+,)d)s0 jesum s1 遗憾的是,上述公式在解决实际问题时难以直接使用
( ) 2 2 1 1 1 2 1 2 N N N ij ik k i j i i k N C N C N E = = = − + Many Could be Better Than All:在有一组个体学习 器可用时,从中选择一部分进行集成,可能比用所有 个体学习器进行集成更好 [Z.-H. Zhou et al., AIJ02] 从一组个体学习器中排除出去的个体(k)应满足: 分类 (( ) ) 1 1 0 j m j kj j j j j Sum Sgn Sum f d = + 选择性集成 回归 遗憾的是,上述公式在解决实际问题时难以直接使用
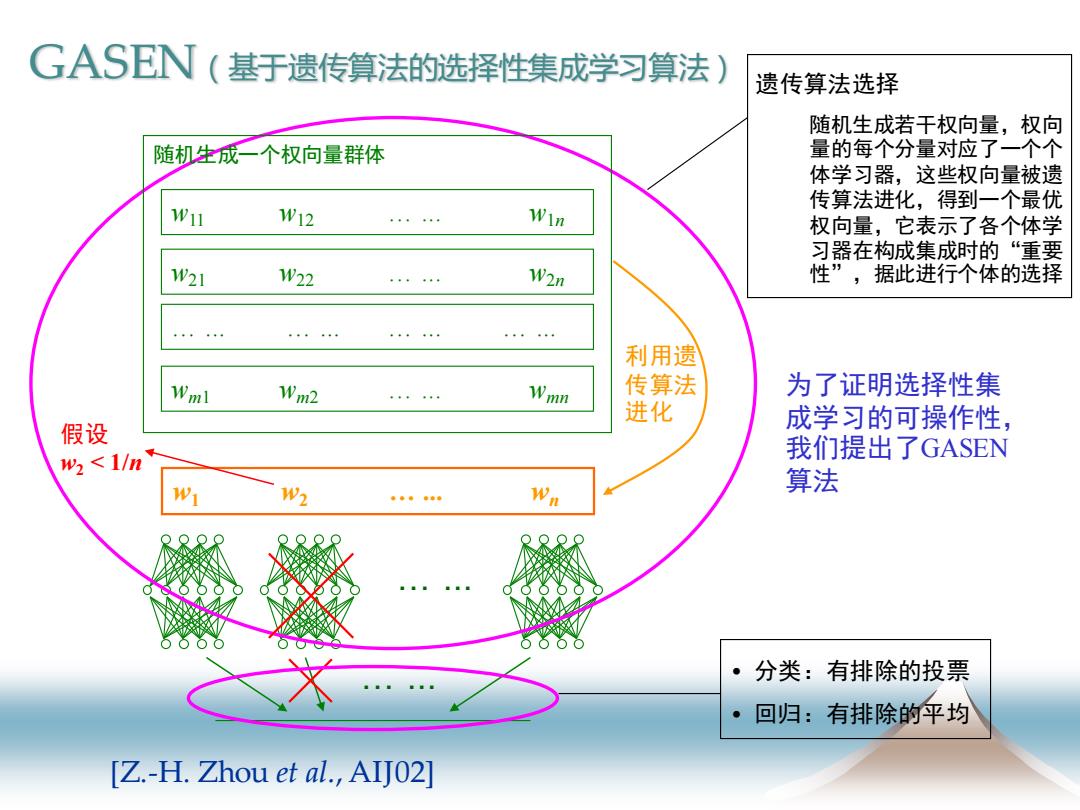
GASEN(基于遗传算法的选择性集成学习算法) 遗传算法选择 随机生成若干权向量,权向 随机生成一个权向量群体 量的每个分量对应了一个个 体学习器,这些权向量被遗 传算法进化,得到一个最优 W11 W12 。。。。。 Win 权向量,它表示了各个体学 习器在构成集成时的“重要 1W21 1W22 W2n 性”,据此进行个体的选择 …4…。4… 。。…… ·◆·。。 ”444”4 利用遗 Wml Wm2 Wmn 传算法 为了证明选择性集 进化 假设 成学习的可操作性, w<1/n 我们提出了GASEN W2 Wn 算法 第象象非非草 。 分类:有排除的投票 回归:有排除的平均 [Z.-H.Zhou et al.,AIJ02
… ... w1 w2 … ... wn 利用遗 传算法 进化 … ... 遗传算法选择 随机生成若干权向量,权向 量的每个分量对应了一个个 体学习器,这些权向量被遗 传算法进化,得到一个最优 权向量,它表示了各个体学 习器在构成集成时的“重要 性”,据此进行个体的选择 假设 w2 < 1/n • 分类:有排除的投票 • 回归:有排除的平均 为了证明选择性集 成学习的可操作性, 我们提出了GASEN 算法 w11 w12 … ... w1n w21 w22 … ... w2n wm1 wm2 … ... wmn 随机生成一个权向量群体 … ... … ... … ... … ... [Z.-H. Zhou et al., AIJ02] GASEN(基于遗传算法的选择性集成学习算法)