
第二章、经典单方程计量经济学模型:多元线性回归模型 一、内容提要 本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的 情形相同。主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方 面的应用等方面。只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。 本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。与一元回 归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性 这一假设:在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是 否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的 内在联系。 本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如 何转化为线性回归模型的常见类型与方法。这里需要注意各回归参数的具体经济含义。 本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约 束检验。参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检 验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与 邹氏预测检验两种类型的检验。检验都是以F检验为主要检验工具,以受约束模型与无约 束模型是否有显著差异为检验基点。参数的非线性约束检验主要包括最大似然比检验、沃尔 德检验与拉格朗日乘数检验。它们仍以估计无约束模型与受约束模型为基础,但以最大似然 原理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的X分布为检验统计 量的分布特征。非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。 二、典型例题分析 例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为 Y=10.36-0.094X1+0.131X2+0.210X3 R2=0.214 式中,Y为劳动力受教育年数,X为该劳动力家庭中兄弟姐妹的个数,X,与X,分别为母
第二章、经典单方程计量经济学模型:多元线性回归模型 一、内容提要 本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的 情形相同。主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方 面的应用等方面。只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。 本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。与一元回 归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性 这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是 否对被解释变量有显著线性影响关系的联合性 F 检验,并讨论了 F 检验与拟合优度检验的 内在联系。 本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如 何转化为线性回归模型的常见类型与方法。这里需要注意各回归参数的具体经济含义。 本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约 束检验。参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检 验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与 邹氏预测检验两种类型的检验。检验都是以 F 检验为主要检验工具,以受约束模型与无约 束模型是否有显著差异为检验基点。参数的非线性约束检验主要包括最大似然比检验、沃尔 德检验与拉格朗日乘数检验。它们仍以估计无约束模型与受约束模型为基础,但以最大似然 原理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的 2 χ 分布为检验统计 量的分布特征。非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。 二、典型例题分析 例 1.某地区通过一个样本容量为 722 的调查数据得到劳动力受教育的一个回归方程为 1 2 210 3 Y = 10.36 − 0.094X + 0.131X + 0. X R2 =0.214 式中,Y 为劳动力受教育年数,X1为该劳动力家庭中兄弟姐妹的个数,X 2 与 X3分别为母

亲与父亲受到教育的年数。问 (1)X,是否具有预期的影响?为什么?若X,与X,保持不变,为了使预测的受教育水 平减少一年,需要X,增加多少? (2)请对X2的系数给予适当的解释。 (3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数为12年,另一 个的父母受教育的年数为16年,则两人受教育的年数预期相差多少? 解答: (1)预期X,对劳动者受教育的年数有影响。因此在收入及支出预算约束一定的条件下, 子女越多的家庭,每个孩子接受教育的时间会越短。 根据多元回归模型偏回归系数的含义,X,前的参数估计值-0.094表明,在其他条件不 变的情况下,每增加1个兄弟姐妹,受教育年数会减少0.094年,因此,要减少1年受教育 的时间,兄弟姐妹需增加1/0.094=10.6个。 (2)X,的系数表示当兄弟姐妹数与父亲受教育的年数保持不变时,母亲每增加1年 受教育的机会,其子女作为劳动者就会预期增加0.131年的受教育机会。 (3)首先计算两人受教育的年数分别为 10.36+0.131×12+0.210×12=14.452 10.36+0.131×16+0.210×16=15.816 因此,两人的受教育年限的差别为15.816-14.452=1.364 例2.以企业研发支出(R&D)占销售额的比重为被解释变量(Y),以企业销售额(X,) 与利润占销售额的比重(X,)为解释变量,一个有32容量的样本企业的估计结果如下: Y=0.472+0.321og(X,)+0.05X2 (1.37)(0.22) (0.046) R2=0.099 其中括号中为系数估计值的标准差。 (1)解释log(X)的系数。如果X,增加10%,估计Y会变化多少个百分点?这在经济 上是一个很大的影响吗? (2)针对R&D强度随销售额的增加而提高这一备择假设,检验它不随X,而变化的假 设。分别在5%和10%的显著性水平上进行这个检验。 (3)利润占销售额的比重X,对R&D强度Y是否在统计上有显著的影响? 解答: (1)log(X,)的系数表明在其他条件不变时,1og(X)变化1个单位,Y变化的单位数
亲与父亲受到教育的年数。问 (1)X1是否具有预期的影响?为什么?若 X 2 与 X3保持不变,为了使预测的受教育水 平减少一年,需要 X1增加多少? (2)请对 X 2 的系数给予适当的解释。 (3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数为 12 年,另一 个的父母受教育的年数为 16 年,则两人受教育的年数预期相差多少? 解答: (1)预期 X1对劳动者受教育的年数有影响。因此在收入及支出预算约束一定的条件下, 子女越多的家庭,每个孩子接受教育的时间会越短。 根据多元回归模型偏回归系数的含义, X1前的参数估计值-0.094 表明,在其他条件不 变的情况下,每增加 1 个兄弟姐妹,受教育年数会减少 0.094 年,因此,要减少 1 年受教育 的时间,兄弟姐妹需增加 1/0.094=10.6 个。 (2) X 2 的系数表示当兄弟姐妹数与父亲受教育的年数保持不变时,母亲每增加 1 年 受教育的机会,其子女作为劳动者就会预期增加 0.131 年的受教育机会。 (3)首先计算两人受教育的年数分别为 10.36+0.131×12+0.210×12=14.452 10.36+0.131×16+0.210×16=15.816 因此,两人的受教育年限的差别为 15.816-14.452=1.364 例 2.以企业研发支出(R&D)占销售额的比重为被解释变量(Y ),以企业销售额( X1) 与利润占销售额的比重( X 2 )为解释变量,一个有 32 容量的样本企业的估计结果如下: 0.099 (1.37) (0.22) (0.046) 0.472 0.32log( ) 0.05 2 1 2 = = + + R Y X X 其中括号中为系数估计值的标准差。 (1)解释 log( X1 )的系数。如果 X1增加 10%,估计Y 会变化多少个百分点?这在经济 上是一个很大的影响吗? (2)针对 R&D 强度随销售额的增加而提高这一备择假设,检验它不随 X1而变化的假 设。分别在 5%和 10%的显著性水平上进行这个检验。 (3)利润占销售额的比重 X 2 对 R&D 强度Y 是否在统计上有显著的影响? 解答: (1)log( X1 )的系数表明在其他条件不变时,log( X1 )变化 1 个单位,Y 变化的单位数
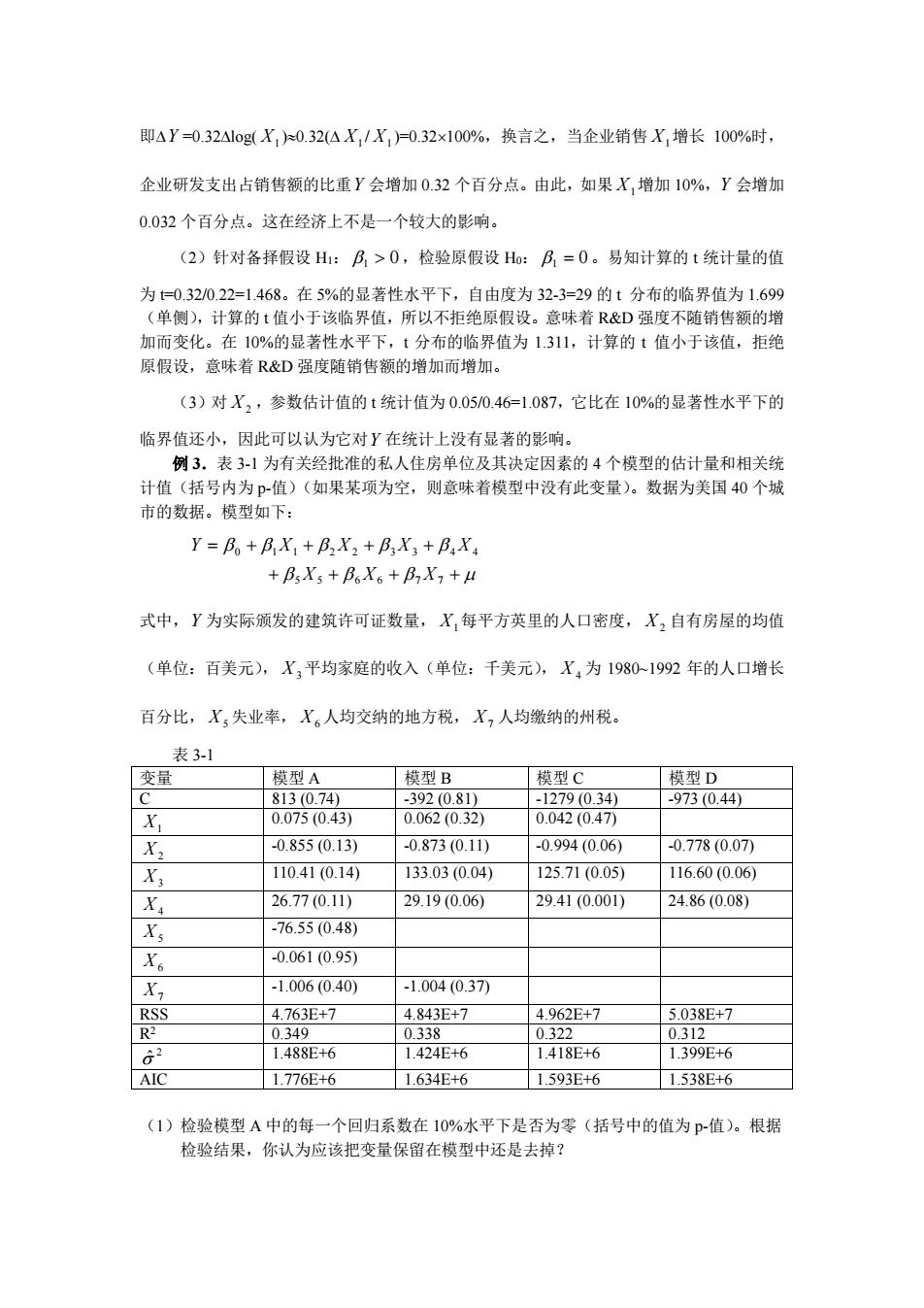
即△Y=0.32△l0g(X,)0.32(△X,/X,)=0.32×100%,换言之,当企业销售X,增长100%时, 企业研发支出占销售额的比重Y会增加0.32个百分点。由此,如果X,增加10%,Y会增加 0.032个百分点。这在经济上不是一个较大的影响。 (2)针对备择假设H:B,>0,检验原假设Ho:B,=0。易知计算的t统计量的值 为=0.32/0.22=1.468。在5%的显著性水平下,自由度为32-3=29的t分布的临界值为1.699 (单侧),计算的t值小于该临界值,所以不拒绝原假设。意味着R&D强度不随销售额的增 加而变化。在10%的显著性水平下,t分布的临界值为1.311,计算的t值小于该值,拒绝 原假设,意味着R&D强度随销售额的增加而增加。 (3)对X2,参数估计值的t统计值为0.05/0.46=1.087,它比在10%的显著性水平下的 临界值还小,因此可以认为它对Y在统计上没有显著的影响。 例3.表3-1为有关经批准的私人住房单位及其决定因素的4个模型的估计量和相关统 计值(括号内为p-值)(如果某项为空,则意味着模型中没有此变量)。数据为美国40个城 市的数据。模型如下: Y=Bo+Bx+Bx2+Bx3+BX +BX5+B6X6+B,X,+4 式中,Y为实际颁发的建筑许可证数量,X,每平方英里的人口密度,X,自有房屋的均值 (单位:百美元),X,平均家庭的收入(单位:千美元),X4为1980-1992年的人口增长 百分比,X,失业率,X。人均交纳的地方税,X,人均缴纳的州税。 表3-1 变量 模型A 模型B 模型C 模型D C 813(0.74) -392(0.81) -1279(0.34) -973(0.44) X 0.075(0.43) 0.062(0.32) 0.042(0.47 X2 -0.855(0.13) -0.873(0.11) -0.994(0.06) -0.778(0.07 X3 110.41(0.14) 133.03(0.04) 125.71(0.05) 116.60(0.06) X 26.77(0.11) 29.19(0.06) 29.41(0.001) 24.86(0.08) X -76.55(0.48) Xo -0.061(0.95) X -1.006(0.40) -1.004(0.37 RSS 4.763E+7 4.843E+7 4.962E+7 5.038E+7 R2 0.349 0.338 0.322 0.312 62 1.488E+6 1.424E+6 1.418E+6 1.399E+6 AIC 1.776E+6 1.634E+6 1.593E+6 1.538E+6 (1)检验模型A中的每一个回归系数在10%水平下是否为零(括号中的值为p-值)。根据 检验结果,你认为应该把变量保留在模型中还是去掉?
即∆Y =0.32∆log( X1 )≈0.32(∆ X1 / X1 )=0.32×100%,换言之,当企业销售 X1增长 100%时, 企业研发支出占销售额的比重Y 会增加 0.32 个百分点。由此,如果 X1增加 10%,Y 会增加 0.032 个百分点。这在经济上不是一个较大的影响。 (2)针对备择假设 H1: β1 > 0 ,检验原假设 H0: β1 = 0。易知计算的 t 统计量的值 为 t=0.32/0.22=1.468。在 5%的显著性水平下,自由度为 32-3=29 的 t 分布的临界值为 1.699 (单侧),计算的 t 值小于该临界值,所以不拒绝原假设。意味着 R&D 强度不随销售额的增 加而变化。在 10%的显著性水平下,t 分布的临界值为 1.311,计算的 t 值小于该值,拒绝 原假设,意味着 R&D 强度随销售额的增加而增加。 (3)对 X 2 ,参数估计值的 t 统计值为 0.05/0.46=1.087,它比在 10%的显著性水平下的 临界值还小,因此可以认为它对Y 在统计上没有显著的影响。 例 3.表 3-1 为有关经批准的私人住房单位及其决定因素的 4 个模型的估计量和相关统 计值(括号内为 p-值)(如果某项为空,则意味着模型中没有此变量)。数据为美国 40 个城 市的数据。模型如下: β β β µ β β β β β + + + + = + + + + 5 5 6 6 7 7 0 1 1 2 2 3 3 4 4 X X X Y X X X X 式中,Y 为实际颁发的建筑许可证数量, X1每平方英里的人口密度, X 2 自有房屋的均值 (单位:百美元), X3平均家庭的收入(单位:千美元), X 4 为 1980~1992 年的人口增长 百分比, X5失业率, X6人均交纳的地方税, X7 人均缴纳的州税。 表 3-1 变量 模型 A 模型 B 模型 C 模型 D C 813 (0.74) -392 (0.81) -1279 (0.34) -973 (0.44) X1 0.075 (0.43) 0.062 (0.32) 0.042 (0.47) X 2 -0.855 (0.13) -0.873 (0.11) -0.994 (0.06) -0.778 (0.07) X3 110.41 (0.14) 133.03 (0.04) 125.71 (0.05) 116.60 (0.06) X 4 26.77 (0.11) 29.19 (0.06) 29.41 (0.001) 24.86 (0.08) X5 -76.55 (0.48) X6 -0.061 (0.95) X7 -1.006 (0.40) -1.004 (0.37) RSS 4.763E+7 4.843E+7 4.962E+7 5.038E+7 R2 0.349 0.338 0.322 0.312 2 σˆ 1.488E+6 1.424E+6 1.418E+6 1.399E+6 AIC 1.776E+6 1.634E+6 1.593E+6 1.538E+6 (1)检验模型 A 中的每一个回归系数在 10%水平下是否为零(括号中的值为 p-值)。根据 检验结果,你认为应该把变量保留在模型中还是去掉?

(2)在模型A中,在10%水平下检验联合假设H0:B,=0(i=1,5,6,7)。说明被择假设,计 算检验统计值,说明其在零假设条件下的分布,拒绝或接受零假设的标准。说明你的 结论。 (3)哪个模型是“最优的”?解释你的选择标准。 (4)说明最优模型中有哪些系数的符号是“错误的”。说明你的预期符号并解释原因。确认 其是否为正确符号。 解答: (1)直接给出了p一值,所以没有必要计算t~统计值以及查t分布表。根据题意,如果p 值<0.10,则我们拒绝参数为零的原假设。 由于表中所有参数的p一值都超过了10%,所以没有系数是显著不为零的。但由此去掉所 有解释变量,则会得到非常奇怪的结果。其实正如我们所知道的,多元回去归中去掉变量时 一定要谨慎,要有所选择。本例中,X2、X3、X4的P值仅比01稍大一点,在略掉X X。、X,的模型C中,这些变量的系数都是显著的。 (2)针对联合假设H。:B,=0(i=1,5,6,7),其对应的备择假设为H1:阝(i=1,5,6,7) 中至少有一个不为零。检验假设H。,实际上就是参数的约束性检验,非约束模型为模型A, 约束模型为模型D,检验统计值为 F=(RSe-RsSu)k,-kr)_5.038e+7-4.763e+7)7-3》=0.462 RSSu /(n-ku -1) (4.763e+7)/(40-8) 显然,在H。假设下,上述统计量满足F分布,在10%的显著性水平下,自由度为(4,32) 的F分布的临界值位于2.09和2.14之间。显然,计算的F值小于临界值,我们不能拒绝H。, 所以B,(i=1,5,6,7)是联合不显著的。 (3)模型D中的3个解释变量全部通过显著性检验。尽管R值相对较小、残差平方和 相对较大,但相对来说其AC值最低,所以我们选择该模型为最优的模型。 (4)随着收入的增加,我们预期住房需要会随之增加。所以可以预期B,>0,事实上其估 计值确是大于零的。同样地,随着人口的增加,住房需求也会随之增加,所以我们预期B4>0, 事实上其估计值也是如此。随着房屋价格的上升,我们预期对住房的需求人数减少,即我们 预期B,估计值的符号为负,回归结果与直觉相符。出乎预料的是,地方税与州税为不显著 的。由于税收的增加将使可支配收入降低,所以我们预期住房的需求将下降。虽然模型A 是这种情况,但它们的影响却非常微弱。 例4、在经典线性模型基本假定下,对含有三个自变量的多元回归模型:
(2)在模型 A 中,在 10%水平下检验联合假设 H0:β i =0(i=1,5,6,7)。说明被择假设,计 算检验统计值,说明其在零假设条件下的分布,拒绝或接受零假设的标准。说明你的 结论。 (3)哪个模型是“最优的”?解释你的选择标准。 (4)说明最优模型中有哪些系数的符号是“错误的”。说明你的预期符号并解释原因。确认 其是否为正确符号。 解答: (1)直接给出了 p-值,所以没有必要计算 t-统计值以及查 t 分布表。根据题意,如果 p- 值<0.10,则我们拒绝参数为零的原假设。 由于表中所有参数的 p-值都超过了 10%,所以没有系数是显著不为零的。但由此去掉所 有解释变量,则会得到非常奇怪的结果。其实正如我们所知道的,多元回去归中去掉变量时 一定要谨慎,要有所选择。本例中, X 2 、 X3、 X 4 的 p-值仅比 0.1 稍大一点,在略掉 X5、 X6、 X7 的模型 C 中,这些变量的系数都是显著的。 (2)针对联合假设 H0 :β i =0( i =1,5,6,7),其对应的备择假设为 H1 :β i ( i =1,5,6,7) 中至少有一个不为零。检验假设 H0 ,实际上就是参数的约束性检验,非约束模型为模型 A, 约束模型为模型 D,检验统计值为 0.462 (4.763 7)/(40 8) (5.038 7 4.763 7)/(7 3) /( 1) ( )/( ) = + − + − + − = − − − − = e e e RSS n k RSS RSS k k F U U R U U R 显然,在 H0 假设下,上述统计量满足 F 分布,在 10%的显著性水平下,自由度为(4,32) 的 F 分布的临界值位于 2.09 和 2.14 之间。显然,计算的 F 值小于临界值,我们不能拒绝 H0 , 所以 β i ( i =1,5,6,7)是联合不显著的。 (3)模型 D 中的 3 个解释变量全部通过显著性检验。尽管 2 R 值相对较小、残差平方和 相对较大,但相对来说其 AIC 值最低,所以我们选择该模型为最优的模型。 (4)随着收入的增加,我们预期住房需要会随之增加。所以可以预期 β 3 >0,事实上其估 计值确是大于零的。同样地,随着人口的增加,住房需求也会随之增加,所以我们预期 β 4 >0, 事实上其估计值也是如此。随着房屋价格的上升,我们预期对住房的需求人数减少,即我们 预期 β 3估计值的符号为负,回归结果与直觉相符。出乎预料的是,地方税与州税为不显著 的。由于税收的增加将使可支配收入降低,所以我们预期住房的需求将下降。虽然模型 A 是这种情况,但它们的影响却非常微弱。 例 4、在经典线性模型基本假定下,对含有三个自变量的多元回归模型:

Y=B。+BX1+B2X2+E,X3+ 你想检验的虚拟假设是H。:阝-2阝2=1。 (1)用月,B2的方差及其协方差求出Var(B,-2B2)。 (2)写出检验H。:阝-2B2=1的t统计量。 (3)如果定义B-2B2=0,写出一个涉及B。、0、阝2和B3的回归方程,以便能直 接得到B估计值0及其标准误。 解答: (1)由数理统计学知识易知 Var(B-2B2)=Var(B)-4Cov(B .B)+4Var(B.) (2)由数理统计学知识易知 1=月-28,-1,其中5e房-20,)为(店-2月,)的标准差。 se(B1-2B2) (3)由阝,-2阝2=0知B1=0+2B2,代入原模型得 Y=B。+(0+2B2)X1+B2X2+F3X3+4 =B。+X1+B2(2X1+X2)+B3X3+4 这就是所需的模型,其中日估计值日及其标准误都能通过对该模型进行估计得到。 例5、对于涉及到三个变量Y、X,、X,的数据做以下回归: I Y:=do+aXu+u ⅡY,=B。+FX2+42 III Yi=Yo+Xu+r2X2i+3i 问在什么条件下才能有à1=氵,及B,=2,即多元回归与各自的一元回归所得的参数估计 值相同。 解答:由回归模型I与Ⅱ分别知: ∑xy
Y = β 0 + β1X1 + β 2 X 2 + β 3X3 + µ 你想检验的虚拟假设是 H0 : 2 1 β1 − β 2 = 。 (1)用 1 2 ˆ , β ˆ β 的方差及其协方差求出 ) ˆ 2 ˆ ( Var β1 − β 2 。 (2)写出检验 H0 : 2 1 β1 − β 2 = 的 t 统计量。 (3)如果定义 β1 − 2β 2 = θ ,写出一个涉及 β 0 、θ 、 β 2 和 β 3的回归方程,以便能直 接得到θ 估计值θ ˆ及其标准误。 解答: (1)由数理统计学知识易知 ) ˆ ) 4 ( ˆ , ˆ ) 4 ( ˆ ) ( ˆ 2 ˆ ( Var β1 − β 2 = Var β1 − Cov β1 β 2 + Var β 2 (2)由数理统计学知识易知 ) ˆ 2 ˆ ( 1 ˆ 2 ˆ 1 2 1 2 β β β β − − − = se t ,其中 ) ˆ 2 ˆ (β1 − β 2 se 为 ) ˆ 2 ˆ (β1 − β 2 的标准差。 (3)由 β1 − 2β 2 = θ 知 β1 = θ + 2β 2 ,代入原模型得 β θ β β µ β θ β β β µ = + + + + + = + + + + + 0 1 2 1 2 3 3 0 2 1 2 2 3 3 (2 ) ( 2 ) X X X X Y X X X 这就是所需的模型,其中θ 估计值θ ˆ及其标准误都能通过对该模型进行估计得到。 例 5、对于涉及到三个变量Y 、 X1、 X 2 的数据做以下回归: I Yi = α 0 +α1X1i + µ1i II Yi = β 0 + β1X 2i + µ 2i III Yi 0 1X1i 2 X 2i µ3i = γ + γ + γ + 问在什么条件下才能有 1 1 αˆ = γˆ 及 1 2 ˆ ˆ β = γ ,即多元回归与各自的一元回归所得的参数估计 值相同。 解答:由回归模型 I 与 II 分别知: ∑ ∑= 2 1 1 1 ˆ i i i x x y α , ∑ ∑= 2 2 2 1 ˆ i i i x x y β