
第8卷第6期 智能系统学报 Vol.8 No.6 2013年12月 CAAI Transactions on Intelligent Systems Dec.2013 D0:10.3969/j.issn.1673-4785.201210036 网络出版地址:http://www.cnki.net/kcms/detail/23.1538.TP.20131030.1508.003.html Hadoop副本放置策略 邵秀丽,王亚光1,李云龙,刘一伟2 (1.南开大学信息技术科学学院,天津300071;2.北京大学数学科学学院,北京100871) 摘要:分布式文件系统(Hs)采用随机的副本放置策略使得系统在运行一段时间后会出现数据分布不均衡的情 况,从而降低数据的可靠性和读取速率.为解决Hds默认副本放置策略存在的问题,对Hs副本放置策略进行改进: 在副本放置选择时优先考虑存储使用率低的节点模拟实验一测试了机架数目对于算法的影响,结果显示改进后的 副本放置策略中,机架数目对集群的均衡性影响很小,显示出较好的均衡性模拟实验二测试了随着写入数据的增 加,比较了使用改进前后的副本放置策略集群中节点使用率的标准差,证实了改进后的副本放置策略在存储均衡方 面较原放置策略有着更好的表现 关键词:云存储:Hds:副本放置:存储均衡:存储节点 中图分类号:TP399文献标志码:A文章编号:1673-4785(2013)06-0489-08 中文引用格式:邵秀丽,王亚光,李云龙,等.Hado0p副本放置策略[J].智能系统学报,2013,8(6):489-496. 英文引用格式:SHAO Xiuli,WANG Yaguang,LI Yunlong,etal.Research on the replica placement strategy of Hadoop[J].CAAL Transactions on Intelligent Systems,2013,8(6):489-496. Research on the replica placement strategy of Hadoop SHAO Xiuli',WANG Yaguang',LI Yunlong',LIU Yiwei? (1.College of Information Technology Science,Nankai University,Tianjin 300071,China;2.College of Mathematical Sciences,Pe- king University,Beijing 100871,China) Abstract:Hadoop distributed file system applies the random replica placement strategy,which causes unbalanced data distribution after the system has operated for a while,resulting in lowering the data reliability and reading speed.In order to eliminate the defect of the replica placement strategy defaulted by the Hdfs,the strategy was im- proved.When the placement location of a replica is selected,a node with a low storage and use rate will be consid- ered as a priority.The first simulation experiment tested the effects caused by the number of racks on the algorithm. The results show that,for the improved replica placement strategy,the number of racks has little impact on the e- quilibrium of the group,the equilibrium is excellent.The second simulation experiment compared the standard difference of the node usage rates between the replica placement strategy groups before and after and found an im- provement following the increase of the data input.The results verify that the improved replica placement strategy has better performance with respect to storage equilibrium. Keywords:cloud storage;Hdfs;replica placement;storage equilibrium;storage node 为提高系统的可靠性,解决不可预知的灾难以 布式副本技术来存储数据. 及硬件错误对系统造成的损失,云存储系统采用分 哥伦比亚大学的K等提出了一种自稳定、全 分布、异步可升级的算法来放置副本,算法的目标是 收稿日期:2012-10-26.网络出版日期:2013-10-30 在网络中的结点上放置数据对象的多个副本,从网络 基金项目:天津市滨海新区科技项目资助项目(12 ZCDZGX46700、 13ZCZDGX02500) 中的任意一个结点出发都能够通过最短的路径访问 通信作者:邵秀丽.E-mail:shaoxl@nankai.edu.cm 到任意的副本;加州大学伯克利分校的Chen等)开
第 8 卷第 6 期 智 能 系 统 学 报 Vol.8 №.6 2013 年 12 月 CAAI Transactions on Intelligent Systems Dec. 2013 DOI:10.3969 / j.issn.1673⁃4785.201210036 网络出版地址:http: / / www.cnki.net / kcms/ detail / 23.1538.TP.20131030.1508.003.html Hadoop 副本放置策略 邵秀丽1 ,王亚光1 ,李云龙1 ,刘一伟2 (1.南开大学 信息技术科学学院,天津 300071; 2.北京大学 数学科学学院,北京 100871) 摘 要:分布式文件系统(Hdfs)采用随机的副本放置策略使得系统在运行一段时间后会出现数据分布不均衡的情 况,从而降低数据的可靠性和读取速率.为解决 Hdfs 默认副本放置策略存在的问题,对 Hdfs 副本放置策略进行改进: 在副本放置选择时优先考虑存储使用率低的节点.模拟实验一测试了机架数目对于算法的影响,结果显示改进后的 副本放置策略中,机架数目对集群的均衡性影响很小,显示出较好的均衡性.模拟实验二测试了随着写入数据的增 加,比较了使用改进前后的副本放置策略集群中节点使用率的标准差,证实了改进后的副本放置策略在存储均衡方 面较原放置策略有着更好的表现. 关键词:云存储;Hdfs;副本放置;存储均衡;存储节点 中图分类号: TP399 文献标志码:A 文章编号:1673⁃4785(2013)06⁃0489⁃08 中文引用格式:邵秀丽,王亚光,李云龙,等. Hadoop 副本放置策略[J]. 智能系统学报, 2013, 8(6): 489⁃496. 英文引用格式:SHAO Xiuli, WANG Yaguang, LI Yunlong, et al. Research on the replica placement strategy of Hadoop[J]. CAAI Transactions on Intelligent Systems, 2013, 8(6): 489⁃496. Research on the replica placement strategy of Hadoop SHAO Xiuli 1 , WANG Yaguang 1 , LI Yunlong 1 , LIU Yiwei 2 (1. College of Information Technology Science, Nankai University, Tianjin 300071, China; 2. College of Mathematical Sciences, Pe⁃ king University, Beijing 100871, China) Abstract:Hadoop distributed file system applies the random replica placement strategy, which causes unbalanced data distribution after the system has operated for a while, resulting in lowering the data reliability and reading speed . In order to eliminate the defect of the replica placement strategy defaulted by the Hdfs, the strategy was im⁃ proved. When the placement location of a replica is selected, a node with a low storage and use rate will be consid⁃ ered as a priority. The first simulation experiment tested the effects caused by the number of racks on the algorithm. The results show that, for the improved replica placement strategy, the number of racks has little impact on the e⁃ quilibrium of the group, the equilibrium is excellent. The second simulation experiment compared the standard difference of the node usage rates between the replica placement strategy groups before and after and found an im⁃ provement following the increase of the data input. The results verify that the improved replica placement strategy has better performance with respect to storage equilibrium. Keywords:cloud storage; Hdfs; replica placement; storage equilibrium; storage node 收稿日期:2012⁃10⁃26. 网络出版日期:2013⁃10⁃30. 基金项目:天津市滨海新区科技项目资助项目( 12ZCDZGX46700、 13ZCZDGX02500). 通信作者:邵秀丽. E⁃mail:shaoxl@ nankai.edu.cn. 为提高系统的可靠性,解决不可预知的灾难以 及硬件错误对系统造成的损失,云存储系统采用分 布式副本技术来存储数据. 哥伦比亚大学的 Ko 等[1]提出了一种自稳定、全 分布、异步可升级的算法来放置副本,算法的目标是 在网络中的结点上放置数据对象的多个副本,从网络 中的任意一个结点出发都能够通过最短的路径访问 到任意的副本;加州大学伯克利分校的 Chen 等[2] 开

·490 智能系统学报 第8卷 发设计了一个动态、高效及可升级的内容分发网络 3)随机函数:Hdfs的NetworkTopolog罗类中有保 SCAN sealable content aeeess network )SCAN 存所有节点信息的ArrayList..Hdfs在选择副本放置 Testry进行路由和定位,使用沿路缓存算法进行副本 位置时,调用随机选择函数chooseRandom,从n中随 放置:德克萨斯大学的MadhukarR等提出了一种协作 机选择一个数对应ArrayList中的节点就被选中为 的缓存放置算法[3),即给定一组协作的缓存、缓存之 副本存储的节点.该函数是只有2个参数的重载函 间的网络距离以及从每个缓存到每个对象的访问频 数,第1个参数是选择节点的范围,它可以是某个机 率的预测,决定在哪里放置对象,从而使平均访问开 架,默认为整个集群:第2个参数是不能选择节点的 销最小化;Karg©r等4提出了能适应节点数量的动态 范围,默认为空,可以设置为某个机架 变化的一致性哈希算法,但它只适用于存储节点同构 4)Hds在进行副本选择过程中,有可能出现参 的情况,当节点的存储容量和处理能力有差异时,数 数不合格或内存异常等现象,一旦出现运行异常, 据将不能够均匀地分布到系统当中. chooseRandom函数就会把异常信息返回客户端该 云存储系统的典型代表是Hdfs[s),它需将每个 函数的调用者 存储数据块的副本放置在多个机架的多个节点上, 2Hdfs默认副本放置策略 存储数据块的副本放置策略将直接影响数据存储的 均衡性以及访问数据块的速度.Hdfs系统采用随机 如图1所示,Hds的副本放置策略是将每一个 选择节点的副本放置策略,该策略在系统运行一段 数据项的副本放置在多个节点上.在客户端运行的 时间后会造成数据分布不均衡的问题,降低数据的 节点上放置第1个副本,在客户端的远程机架上随 可靠性和读取性能.因此,本文提出了基于节点使用 机选择一个节点放置第2个副本,在第2个副本所 率选择存储节点的Hds副本放置策略的改进算法, 在机架上随机选择一个节点放置第3个副本 引入了客户端存储阈值,允许副本在放置过程中穿 越多个机架,以实现各节点数据存储的相对均衡,实 文件写入 验验证了改进策略的有效性 云存储 客户端客户端2…客户端 系统 1 副本放置策路的相关概念 写入 访问层 分布式文件系统 内容为研究Hdfs的副本放置策略,先介绍相关 文件文件2…文件 文件与数据 概念如下: 应用 接口层 分块 块关联表 I)获取集群信息:Hdf的NetworkTopolog罗类实 、分块存储 基础 现对其拓扑结构的操纵,该类中包含添加、删除和获 管理层 块 块2 块风 取节点信息等函数.比如,Hdfs通过调用NetworkTo- 数据块与节 存储:副本放置策略 点关联表 pology类的chooseRandom来随机获取一个节点的 存储层 存储介质 信息,通过调用getNumOfLeaves来获取所有节点的 pc2 pen 数目 图1副本放置策略 2)集群拓扑(机架与节点):将Hdfs部署在多 Fig.1 The placement policy of duplication 台服务器上就形成了一个Hds的集群.如树状拓扑 结构的Hds集群,树根是一个大型交换机,交换机 分布式文件系统[6)的副本放置策略确定每一 之下可以是多个二级交换机,可以把每一个二级交 个数据块应该存放的位置,数据块与节点之间的关 换机设置为一个机架,每个机架之下连接多个节点 联被记录在数据块与节点关联表中,数据块最终会 Hds管理员可编写脚本文件来配置每个节点属 被存放在存储层的各个节点上。 于哪一个机架在进行机架配置时,应将相同交换机 2.1Hdfs默认副本放置策略的流程 下的节点设置为同一个机架就可实现合理的配置: Hds的分块存储文件在选择副本放置位置时, 一般把组成Hdfs集群的每一个服务器称为一 综合考虑了数据存储的可靠性、数据读写的带宽和负 个节点,对文件读写的客户端而言,其所在节点称为 载均衡等因素如将一个数据块所有副本都存储在一 本地节点,其他节点为远程节点就某一具体节点而 个节点上,则存储过程中所占用的带宽是最小的,因 言,称该节点所在的机架为本地机架,其他机架为远 为这可以减少数据块的网络传输,但该方案不提供有 程机架 效的冗余备份,一旦该节点发生故障,则该节点中存
发设计了一个动态、高效及可升级的内容分发网络 SCAN( sealable content aeeess network). SCAN 采 用 Testry 进行路由和定位,使用沿路缓存算法进行副本 放置;德克萨斯大学的 MadhukarR 等提出了一种协作 的缓存放置算法[3] ,即给定一组协作的缓存、缓存之 间的网络距离以及从每个缓存到每个对象的访问频 率的预测,决定在哪里放置对象,从而使平均访问开 销最小化;Karger 等[4]提出了能适应节点数量的动态 变化的一致性哈希算法,但它只适用于存储节点同构 的情况,当节点的存储容量和处理能力有差异时,数 据将不能够均匀地分布到系统当中. 云存储系统的典型代表是 Hdfs [5] ,它需将每个 存储数据块的副本放置在多个机架的多个节点上, 存储数据块的副本放置策略将直接影响数据存储的 均衡性以及访问数据块的速度.Hdfs 系统采用随机 选择节点的副本放置策略,该策略在系统运行一段 时间后会造成数据分布不均衡的问题,降低数据的 可靠性和读取性能.因此,本文提出了基于节点使用 率选择存储节点的 Hdfs 副本放置策略的改进算法, 引入了客户端存储阈值,允许副本在放置过程中穿 越多个机架,以实现各节点数据存储的相对均衡,实 验验证了改进策略的有效性. 1 副本放置策略的相关概念 内容为研究 Hdfs 的副本放置策略,先介绍相关 概念如下: 1)获取集群信息:Hdfs 的 NetworkTopology 类实 现对其拓扑结构的操纵,该类中包含添加、删除和获 取节点信息等函数.比如,Hdfs 通过调用 NetworkTo⁃ pology 类的 chooseRandom 来随机获取一个节点的 信息,通过调用 getNumOfLeaves 来获取所有节点的 数目. 2)集群拓扑(机架与节点):将 Hdfs 部署在多 台服务器上就形成了一个 Hdfs 的集群.如树状拓扑 结构的 Hdfs 集群,树根是一个大型交换机,交换机 之下可以是多个二级交换机,可以把每一个二级交 换机设置为一个机架,每个机架之下连接多个节点. Hdfs 管理员可编写脚本文件来配置每个节点属 于哪一个机架.在进行机架配置时,应将相同交换机 下的节点设置为同一个机架就可实现合理的配置. 一般把组成 Hdfs 集群的每一个服务器称为一 个节点,对文件读写的客户端而言,其所在节点称为 本地节点,其他节点为远程节点.就某一具体节点而 言,称该节点所在的机架为本地机架,其他机架为远 程机架. 3)随机函数:Hdfs 的 NetworkTopology 类中有保 存所有节点信息的 ArrayList.Hdfs 在选择副本放置 位置时,调用随机选择函数 chooseRandom,从 n 中随 机选择一个数对应 ArrayList 中的节点就被选中为 副本存储的节点.该函数是只有 2 个参数的重载函 数,第 1 个参数是选择节点的范围,它可以是某个机 架,默认为整个集群;第 2 个参数是不能选择节点的 范围,默认为空,可以设置为某个机架. 4)Hdfs 在进行副本选择过程中,有可能出现参 数不合格或内存异常等现象,一旦出现运行异常, chooseRandom 函数就会把异常信息返回客户端该 函数的调用者. 2 Hdfs 默认副本放置策略 如图 1 所示,Hdfs 的副本放置策略是将每一个 数据项的副本放置在多个节点上.在客户端运行的 节点上放置第 1 个副本,在客户端的远程机架上随 机选择一个节点放置第 2 个副本,在第 2 个副本所 在机架上随机选择一个节点放置第 3 个副本. 图 1 副本放置策略 Fig.1 The placement policy of duplication 分布式文件系统[6⁃7] 的副本放置策略确定每一 个数据块应该存放的位置,数据块与节点之间的关 联被记录在数据块与节点关联表中,数据块最终会 被存放在存储层的各个节点上. 2.1 Hdfs 默认副本放置策略的流程 Hdfs 的分块存储文件在选择副本放置位置时, 综合考虑了数据存储的可靠性、数据读写的带宽和负 载均衡等因素.如将一个数据块所有副本都存储在一 个节点上,则存储过程中所占用的带宽是最小的,因 为这可以减少数据块的网络传输,但该方案不提供有 效的冗余备份,一旦该节点发生故障,则该节点中存 ·490· 智 能 系 统 学 报 第 8 卷

第6期 邵秀丽,等:Hadoop副本放置策略 ·491. 储的这一数据块及其所有副本都会丢失.因此,Hds 的副本放置策略流程,其中标注了本文所实现的对副 对任意一数据块不在同一个节点上放置多个副本,而 本放置策略的改进工作,Hfs默认的副本放置策略选 是将副本尽可能分散存放[s.图2给出了Hfs默认 择3个节点,可以选择多个节点放置副本 改进策略: 需要考虑客户端 的负载情况客户端负载过 ReplicationTargetChooser 大则不在客户端放置副本 类的chooseTarget函数来进 使用Replication TargetChooser 类的chooseLocalRack在本地 行节点的选择 Replication TargetChooser 机架上选择1个节点 类的chooseLocalNode函数 尝试选择客户端节点作为第 使用NetworkTopology类的 1个节点 contains函数判断客户端是 成功 否是集群中的1个DataNode 成功 Replication TargetChooser 改进策略: 类的chooseRandom函数在 成功 返给Replication TargetChooser 类的chooseTarget函数选择的 不进行随机选择,选则 集群中随机选择1个节点作为 节点 使用率最低的节点 结果 之前的掬作都成功 使用Replication TargetChooser ReplicationTargetChooser 之前的 类的chooseRandom函数在本 失败 类的chooseRemoteRack函数 开始选择第 在远程机架上随机选择1个节 2个节点 操作产 生异常 地机架上选择1个节点 点 成功 返回给Replication TargetChooser 之前的操作出现异常 返回客户端 类的chooseTarget函数选择的节 节点 结束 点 之前的操作都成功 之前的操作 HReplicationTargetChooserchoose 出现异常 开始选择第3个节点 类的choose RemoteRack在远程机 返回最终所选 架上选择1个节点 的所有节点 使用NetworkTopology类的 ReplicationTargetChooserchoose isOnSameRack判断前2个 类的chooseLocalRack在第2个节点 使用Replication Target 节点是否在同1个机架上 N 的本地机架上选择]个节点 Chooser类的choose 之前的操作 Random函数在集群中 都成功 随机选择剩余的节点 改进策路: 不限制具体机架, 改进策略: 不限制机架的个数 开始选择剩 不使用随机函数, 不使用随机函数, 余的节点 选择使用率最低的 节点 选择使用率最低的节点. 图2默认副本放置策略 Fig.2 The flowchart of default replica placement l)HdFs副本放置策略是调用ReplicationTarget-- getChooserchooser类的chooseLocalRack函数,在客户 Chooser类的chooseTargrt函数来实现的.开始使用 端节点所在机架随机选择一个节点作为第1个节点, NetworkTopology类的contains函数,contains函数通 然后将这个节点的信息传给ReplicationTargetChoos- 过判断客户端所在根节点与集群的根节点是否一致 erchooser类中的chooseTargrt函数,且将这个节点的 来判断客户端是否在集群中. 信息记录在ReplicationTargetChooserchooser类中的一 2)如果客户端是集群中的一个节点,则调用 个DatanodeDescriptor类型的数组results中. ReplicationTargetChooser类的chooseLocalNode函数 4)如果客户端不是集群中的节点,则使用Rep 来尝试选择客户端节点作为第1个节点: licationTargetChooser类的chooseRandom函数在集群 3)客户端存储尝试失败时则调用Replication Tar- 中随机选择一个节点作为第1个节点,且将这个选
储的这一数据块及其所有副本都会丢失.因此,Hdfs 对任意一数据块不在同一个节点上放置多个副本,而 是将副本尽可能分散存放[8⁃9] .图 2 给出了 Hdfs 默认 的副本放置策略流程,其中标注了本文所实现的对副 本放置策略的改进工作,Hdfs 默认的副本放置策略选 择 3 个节点,可以选择多个节点放置副本. 图 2 默认副本放置策略 Fig.2 The flowchart of default replica placement 1)HdFs 副本放置策略是调用 ReplicationTarget⁃ Chooser 类的 chooseTargrt 函数来实现的.开始使用 NetworkTopology 类的 contains 函数,contains 函数通 过判断客户端所在根节点与集群的根节点是否一致 来判断客户端是否在集群中. 2)如果客户端是集群中的一个节点,则调用 ReplicationTargetChooser 类的 chooseLocalNode 函数 来尝试选择客户端节点作为第 1 个节点. 3)客户端存储尝试失败时则调用 ReplicationTar⁃ getChooserchooser 类的 chooseLocalRack 函数,在客户 端节点所在机架随机选择一个节点作为第 1 个节点, 然后将这个节点的信息传给 ReplicationTargetChoos⁃ erchooser 类中的 chooseTargrt 函数,且将这个节点的 信息记录在 ReplicationTargetChooserchooser 类中的一 个 DatanodeDescriptor 类型的数组 results 中. 4)如果客户端不是集群中的节点,则使用 Rep⁃ licationTargetChooser 类的 chooseRandom 函数在集群 中随机选择一个节点作为第 1 个节点,且将这个选 第 6 期 邵秀丽,等:Hadoop 副本放置策略 ·491·

·492 智能系统学报 第8卷 择的节点记录在数组results中. 空闲的节点,从而达到重新分配数据块的目的,最终 5)ReplicationTargetChooser chooseRemot- 达到整个集群的数据块分布均衡.在数据块重新分 eRack函数在第1个节点的远程机架上随机选择一 配的过程中,均衡器会尽量将一个数据块的复本分 个节点作为第2个节点.如果在远程机架上选择节 散到不同机架,以提高数据块的冗余,降低数据损坏 点失败,则使用ReplicationTargetChooser类的choos- 的可能性, eLocalRack函数在第1个节点的本地机架上随机选 Hdfs集群的管理员决定是否启动均衡器,启动 择一个节点作为第2个节点.将第2个节点记录在 后,会根据管理员设定的阀值来对集群进行均衡处 ReplicationTargetChooserchooser DatanodeDescriptor 理.阀值是每个节点的使用率(该节点上已经使用的 下的数组results中. 空间和节点的空间容量之间的比值)和集群的使用 6)选择第3个节点,如果前2个节点是在同一 率(集群中已使用的空间和集群的空间容量之间的 个机架上,则使用ReplicationTargetChooser类的 比值)之间的差值,默认的阀值是10%,管理员在启 chooseRemoteRack函数在前2个节点的远程机架上 动均衡器的时候,可以指定阀值的大小.在任何时 选择一个节点.如果所选择的前2个节点并不在同 刻,集群中只能运行一个均衡器 一个机架上面,则使用ReplicationTargetChooser类的 均衡器虽然可以解决数据块分布不均衡的问 chooseLocalRack函数在第2个节点的本地机架上随 题,但是存在着明显的问题: 机选择一个节点作为第3个节点,且存储第3个节 1)均衡器对于集群数据块均衡的调节具有滞 点信息在数组results中. 后性,它必须要在系统的不均衡状况超过阀值之后, 7)最终将results中的所有节点返回给副本选 才会进行调节 择函数的调用者 2)均衡器的运行和数据块的移动需要耗费一 2.2Hdfs副本放置策略的缺陷 定的资源,很可能一个数据块刚刚写入到集群中,就 Hfs默认副本放置策略综合考虑了多方面的 因为均衡性而被移动,这种情况下集群的资源使用 因素,在可靠性、读写效率,负载均衡方面都做了一 是很低效的, 定的权衡,是一个比较优秀的副本放置策略,但 3Hdfs副本放置策略的改进 Hdfs采用随机选择的副本放置策略.该策略没有考 虑到节点负载的情况,在数据均衡方面比较薄弱,这 Hds默认的副本放置策略存在的不足,以及 使数据损坏时需要恢复的数据块数量可能会很多, Hdfs提供的均衡器存在一些不尽人意的地方,本文 数据读取的速度会受到影响等问题 提出了对其改进的低使用率优先(low rate first)副 针对这一问题,Hdfs提供了解决方案一均衡 本放置策略, 器o.均衡器(balancer)是一个Hds的守护进程,启 3.1改进副本放置的流程 动之后,它会将数据块从负载较高的节点移到相对 图3是副本放置改进策略的流程. 判断本节点使用率 尝试选择本节点 与集群使用率的差 作为第1个节点 client是 是否高于阈值 datanode Y 开始选择 失败 成功 第1个节点 选择集群中使用率 选择本地节点为 client不是 最低的节点作为第 datanode 1个节点 第1个节点 尝试选择与第1个 选择该节点为第 节点不同机架并且 剩余节点选择在集 且使用率最低的节 成功 2个节点 群中使用率最低的 点作为第2个节点 在本机架选择使用 节点 远程机架无合适 率最低的节点作为 节点或者无远程机架 第2个节点 图3基于3副本放置策略的改进 Fig.3 The improved placement strategy based on three replicas 1)考虑到数据写入带宽问题,依然在客户端所 在的节点上写入第1个副本,但考虑了该节点的负载
择的节点记录在数组 results 中. 5) ReplicationTargetChooser 类 的 chooseRemot⁃ eRack 函数在第 1 个节点的远程机架上随机选择一 个节点作为第 2 个节点.如果在远程机架上选择节 点失败,则使用 ReplicationTargetChooser 类的 choos⁃ eLocalRack 函数在第 1 个节点的本地机架上随机选 择一个节点作为第 2 个节点.将第 2 个节点记录在 ReplicationTargetChooserchooser 类中 DatanodeDescriptor 下的数组 results 中. 6)选择第 3 个节点,如果前 2 个节点是在同一 个机 架 上, 则 使 用 ReplicationTargetChooser 类 的 chooseRemoteRack 函数在前 2 个节点的远程机架上 选择一个节点.如果所选择的前 2 个节点并不在同 一个机架上面,则使用 ReplicationTargetChooser 类的 chooseLocalRack 函数在第 2 个节点的本地机架上随 机选择一个节点作为第 3 个节点,且存储第 3 个节 点信息在数组 results 中. 7)最终将 results 中的所有节点返回给副本选 择函数的调用者. 2.2 Hdfs 副本放置策略的缺陷 Hdfs 默认副本放置策略综合考虑了多方面的 因素,在可靠性、读写效率,负载均衡方面都做了一 定的权衡, 是一个比较优秀的副本放置策略, 但 Hdfs 采用随机选择的副本放置策略.该策略没有考 虑到节点负载的情况,在数据均衡方面比较薄弱,这 使数据损坏时需要恢复的数据块数量可能会很多, 数据读取的速度会受到影响等问题. 针对这一问题,Hdfs 提供了解决方案———均衡 器[10] .均衡器(balancer)是一个 Hdfs 的守护进程,启 动之后,它会将数据块从负载较高的节点移到相对 空闲的节点,从而达到重新分配数据块的目的,最终 达到整个集群的数据块分布均衡.在数据块重新分 配的过程中,均衡器会尽量将一个数据块的复本分 散到不同机架,以提高数据块的冗余,降低数据损坏 的可能性. Hdfs 集群的管理员决定是否启动均衡器,启动 后,会根据管理员设定的阀值来对集群进行均衡处 理.阀值是每个节点的使用率(该节点上已经使用的 空间和节点的空间容量之间的比值)和集群的使用 率(集群中已使用的空间和集群的空间容量之间的 比值)之间的差值,默认的阀值是 10%,管理员在启 动均衡器的时候,可以指定阀值的大小.在任何时 刻,集群中只能运行一个均衡器. 均衡器虽然可以解决数据块分布不均衡的问 题,但是存在着明显的问题: 1)均衡器对于集群数据块均衡的调节具有滞 后性,它必须要在系统的不均衡状况超过阀值之后, 才会进行调节. 2)均衡器的运行和数据块的移动需要耗费一 定的资源,很可能一个数据块刚刚写入到集群中,就 因为均衡性而被移动,这种情况下集群的资源使用 是很低效的. 3 Hdfs 副本放置策略的改进 Hdfs 默认的副本放置策略存在的不足,以及 Hdfs 提供的均衡器存在一些不尽人意的地方,本文 提出了对其改进的低使用率优先( low rate first) 副 本放置策略. 3.1 改进副本放置的流程 图 3 是副本放置改进策略的流程. 图 3 基于 3 副本放置策略的改进 Fig.3 The improved placement strategy based on three replicas 1)考虑到数据写入带宽问题,依然在客户端所 在的节点上写入第 1 个副本,但考虑了该节点的负载 ·492· 智 能 系 统 学 报 第 8 卷
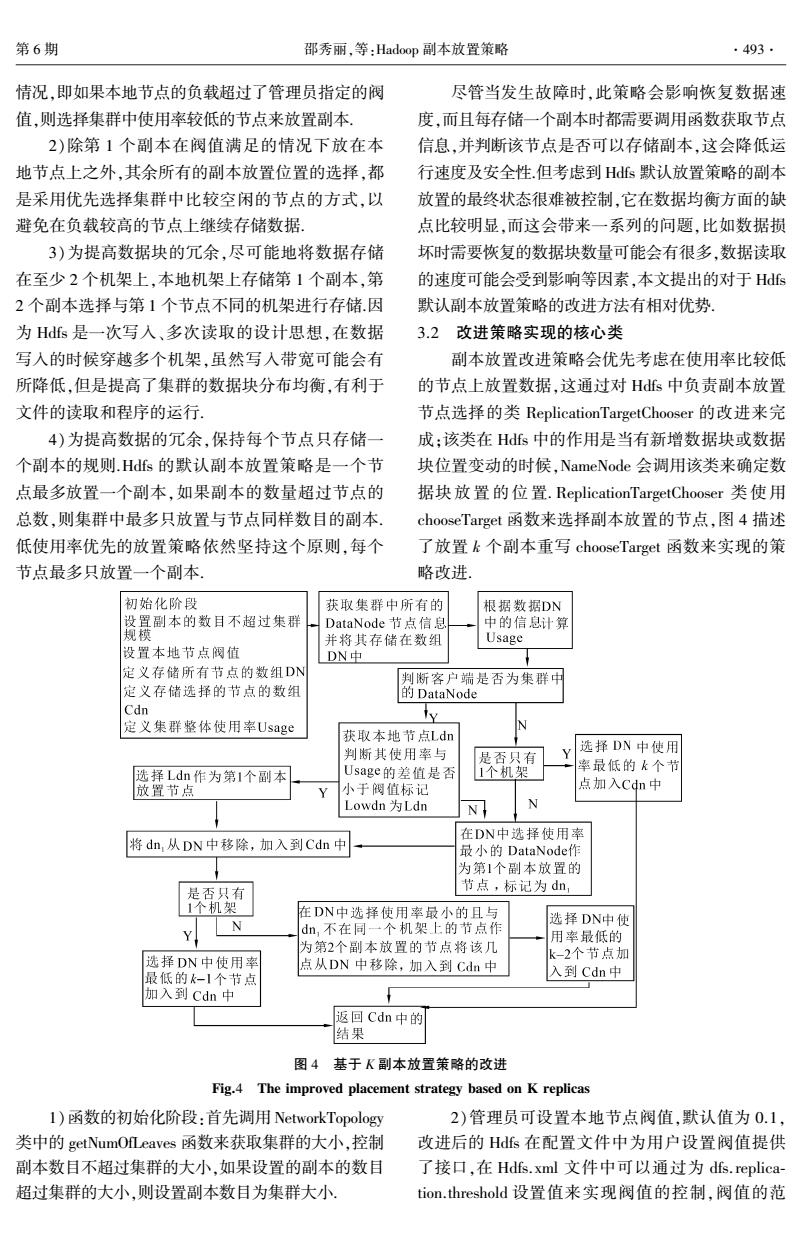
第6期 邵秀丽,等:Hadoop副本放置策略 ·493. 情况,即如果本地节点的负载超过了管理员指定的阀 尽管当发生故障时,此策略会影响恢复数据速 值,则选择集群中使用率较低的节点来放置副本」 度,而且每存储一个副本时都需要调用函数获取节点 2)除第1个副本在阀值满足的情况下放在本 信息,并判断该节点是否可以存储副本,这会降低运 地节点上之外,其余所有的副本放置位置的选择,都 行速度及安全性.但考虑到Hds默认放置策略的副本 是采用优先选择集群中比较空闲的节点的方式,以 放置的最终状态很难被控制,它在数据均衡方面的缺 避免在负载较高的节点上继续存储数据, 点比较明显,而这会带来一系列的问题,比如数据损 3)为提高数据块的冗余,尽可能地将数据存储 坏时需要恢复的数据块数量可能会有很多,数据读取 在至少2个机架上,本地机架上存储第1个副本,第 的速度可能会受到影响等因素,本文提出的对于Hfs 2个副本选择与第1个节点不同的机架进行存储因 默认副本放置策略的改进方法有相对优势. 为Hds是一次写入、多次读取的设计思想,在数据 3.2改进策略实现的核心类 写入的时候穿越多个机架,虽然写人带宽可能会有 副本放置改进策略会优先考虑在使用率比较低 所降低,但是提高了集群的数据块分布均衡,有利于 的节点上放置数据,这通过对Hs中负责副本放置 文件的读取和程序的运行 节点选择的类ReplicationTargetChooser的改进来完 4)为提高数据的冗余,保持每个节点只存储一 成:该类在Hdfs中的作用是当有新增数据块或数据 个副本的规则.Hfs的默认副本放置策略是一个节 块位置变动的时候,NameNode会调用该类来确定数 点最多放置一个副本,如果副本的数量超过节点的 据块放置的位置.ReplicationTargetChooser类使用 总数,则集群中最多只放置与节点同样数目的副本 chooseTarget函数来选择副本放置的节点,图4描述 低使用率优先的放置策略依然坚持这个原则,每个 了放置k个副本重写chooseTarget函数来实现的策 节点最多只放置一个副本 略改进。 初始化阶段 获取集群中所有的 根据数据DN 设置副本的数目不超过集群 DataNode节点信息 中的信息计算 规模 并将其存储在数组 Usage 设置本地节点阀值 DN中 定义存储所有节点的数组DN 判断客户端是否为集群中 定义存储选择的节点的数组 的DataNode Cdn y 定义集群整体使用率Usage 获取本地节点Ldn 判断其使用率与 是否只有 Y 选择DN中使用 选择Ldn作为第1个副本 Usage的差值是否 1个机架 率最低的k个节 放置节点 小于阀值标记 点加入Cdn中 Lowdn为Ldn N N 在DN中选择使用率 将dn,从DN中移除,加入到Cdn中 最小的DataNodef作 为第1个副本放置的 是否只有 节点,标记为dn, 1个机架 在DN中选择使用率最小的且与 N 选择DN中使 Y dn,不在同一个机架上的节点作 用率最低的 为第2个副本放置的节点将该几 选择DN中使用率 k-2个节点加 点从DN中移除,加入到Cdn中 最低的k-1个节点 入到Cdn中 加入到cdn中 返回Cdn中的 结果 图4基于K副本放置策略的改进 Fig.4 The improved placement strategy based on K replicas I)函数的初始化阶段:首先调用NetworkTopology 2)管理员可设置本地节点阀值,默认值为01, 类中的get NumOfLeaves函数来获取集群的大小,控制 改进后的Hfs在配置文件中为用户设置阀值提供 副本数目不超过集群的大小,如果设置的副本的数目 了接口,在Hdfs.xml文件中可以通过为dfs.replica- 超过集群的大小,则设置副本数目为集群大小 tion.threshold设置值来实现阀值的控制,阀值的范
情况,即如果本地节点的负载超过了管理员指定的阀 值,则选择集群中使用率较低的节点来放置副本. 2)除第 1 个副本在阀值满足的情况下放在本 地节点上之外,其余所有的副本放置位置的选择,都 是采用优先选择集群中比较空闲的节点的方式,以 避免在负载较高的节点上继续存储数据. 3)为提高数据块的冗余,尽可能地将数据存储 在至少 2 个机架上,本地机架上存储第 1 个副本,第 2 个副本选择与第 1 个节点不同的机架进行存储.因 为 Hdfs 是一次写入、多次读取的设计思想,在数据 写入的时候穿越多个机架,虽然写入带宽可能会有 所降低,但是提高了集群的数据块分布均衡,有利于 文件的读取和程序的运行. 4)为提高数据的冗余,保持每个节点只存储一 个副本的规则.Hdfs 的默认副本放置策略是一个节 点最多放置一个副本,如果副本的数量超过节点的 总数,则集群中最多只放置与节点同样数目的副本. 低使用率优先的放置策略依然坚持这个原则,每个 节点最多只放置一个副本. 尽管当发生故障时,此策略会影响恢复数据速 度,而且每存储一个副本时都需要调用函数获取节点 信息,并判断该节点是否可以存储副本,这会降低运 行速度及安全性.但考虑到 Hdfs 默认放置策略的副本 放置的最终状态很难被控制,它在数据均衡方面的缺 点比较明显,而这会带来一系列的问题,比如数据损 坏时需要恢复的数据块数量可能会有很多,数据读取 的速度可能会受到影响等因素,本文提出的对于 Hdfs 默认副本放置策略的改进方法有相对优势. 3.2 改进策略实现的核心类 副本放置改进策略会优先考虑在使用率比较低 的节点上放置数据,这通过对 Hdfs 中负责副本放置 节点选择的类 ReplicationTargetChooser 的改进来完 成;该类在 Hdfs 中的作用是当有新增数据块或数据 块位置变动的时候,NameNode 会调用该类来确定数 据块放置的位 置. ReplicationTargetChooser 类 使 用 chooseTarget 函数来选择副本放置的节点,图 4 描述 了放置 k 个副本重写 chooseTarget 函数来实现的策 略改进. 图 4 基于 K 副本放置策略的改进 Fig.4 The improved placement strategy based on K replicas 1)函数的初始化阶段:首先调用 NetworkTopology 类中的 getNumOfLeaves 函数来获取集群的大小,控制 副本数目不超过集群的大小,如果设置的副本的数目 超过集群的大小,则设置副本数目为集群大小. 2)管理员可设置本地节点阀值,默认值为 0.1, 改进后的 Hdfs 在配置文件中为用户设置阀值提供 了接口,在 Hdfs. xml 文件中可以通过为 dfs.replica⁃ tion.threshold 设置值来实现阀值的控制,阀值的范 第 6 期 邵秀丽,等:Hadoop 副本放置策略 ·493·