
第7卷第4期 智能系统学报 Vol.7 No.4 2012年8月 CAAI Transactions on Intelligent Systems Aug.2012 D0I:10.3969/j.issn.16734785.201111014 基于文本的新闻事件多版本发现模型 肖融,孔亮,张岩 (北京大学教育部机器感知重点实验室,北京100871) 摘要:信息时代的发展让越来越多的新闻事件充斥人们的生活,对于一件特定的新闻事件,目前已有很多算法可 以帮助人们进行事件追踪和发现.提出一种CDW算法,帮助读者对于一件具有多个版本描述的新闻事件进行多个 不同版本的发现.这个算法将文档集映射到话题层,通过提取每个话题的流行词,以得到文档集中具有高区分度的 特征.然后根据这些特征对文档集进行聚类,最后得到事件的多个版本.通过在2个实际数据集上进行实验,实验结 果表明,该算法与以往的相关算法相比是十分有效的 关键词:多版本事件:高区分度:聚类模型;话题分析 中图分类号:TP18文献标志码:A文章编号:16734785(2012)040307-08 A text clustering model for diverse versions discovery XIAO Rong,KONG Liang,ZHANG Yan (Key Laboratory on Machine Perception of MOE,Peking University,Beijing 100871,China) Abstract:The development of information technology brings numerous news and events to our daily life.Although previous researches have provided various algorithms to detect and track events,few of them focus on uncovering the diversified versions of an event.In this paper,a novel algorithm CDW which is capable of discovering different versions of one event according to the news reports was proposed.First,documents were mapped to the topic layer to get the information of each topic.Then the highly-differentiated words of each topic were extracted to cluster the documents.At last,various versions of one event were got.Experiments conducted on two data sets show that the algorithm given in this paper is effective and outperforms various related algorithms,including classical methods such as K-means and linear discriminant analysis (LDA). Keywords:diverse versions discovery;highly-differentiated words;clustering model;topic analysis 人们生活在信息时代,每天都在接收大量的信 韩国天安舰沉船事件,有报道称是朝鲜所为,有报道 息,从各种媒体渠道浏览各种新闻事件.有些新闻事 称是美国的阴谋,还有报道说是南北交火时沉没等 件只有基于事件本身的客观性报道,比如《哈利波 这一类新闻事件的众多报道就会出现对于同一事件 特7》上映,莫斯科发生大规模球迷骚乱,欧盟呼吁 有多个不同版本说法的现象,也就是本文所研究的 欧洲共同应对危机等.这类新闻报道主要是对所发 多版本事件. 生的新闻事实进行客观描述,一般所有的报道都相 随着话题发现与追踪技术(topic detection and 近似,不会众说纷纭.而有一些新闻事件由于具有开 tracking,TDT)21的发展日益成熟,很多网站都可以提 放性或者模糊性,导致各方面口径不一,就会出现所 供为用户组织归纳新闻事件的应用.通过话题发现与 谓的“罗生门”现象.比如流行天王Michael Jackson 追踪,用户可以清楚地知道新闻事件的发生和衍化过 的死因,有报道说是心脏病意外死亡,有报道称是自 程,也可以看到关于事件的各种报道.TDT源于199%年 杀,有报道称是私人医生误杀或谋杀等.再比如对于 美国国防高级研究计划委员会提出的需要一种能自动 确定新闻报道流中话题结构的技术3].随后,DARPA、 收稿日期:2011-11-24. 基金项目:国家自然科学基金资助项目(61703081) 卡内基·梅隆大学、Dgon系统公司以及马萨诸塞大 通信作者:肖融.E-mail:xrsmile@gmail..com. 学的研究人员定义了DT的相关内容,并检验信息检

·308 智能系统学报 第7卷 索中基于主题的技术在TDT中的应用情况,这些研究 是一个有效的事件多版本发现算法需要具备的性 及评测被命名为TDT pilot6.TDT是一项综合的技术, 质并且,为了使多版本发现的工作更有意义,本文 需要较多的自然语言处理理论和技术作为支撑.话题 认为这样的算法必须是足够强健的(qualitatively 发现技术可以看作是一种按事件的聚类,研究者常采 strong)l18] 用的算法有agglomerative聚类、增量K-means聚类、增 首先,这里先要声明几个符号表示的意义.令 量聚类等.话题追踪的常用技术有Rocchio分类方法、 D={d,d:+1,…,dn}表示对于某一特定新闻事件所 决策树方法、基于HMM的语言模型等0 搜集的n个文档的集合,其中每一篇文档d,i= 然而,对于多版本的新闻事件,简单的组织归纳 1:n,用bag of words表示(o1,w2,…,0a).多版本发 难以满足用户对于不同版本报道的信息获取的需 现的目标在于发现m个不同的版本V={"1,2,…, 求.对于存在多个版本的事件,读者很难面对庞大的 "m}来描述一个事件,其中每一种版本:(i=1: 新闻数据而自行鉴别事件的版本,如果存在一个算 m),用一种词的分布表示.对于某一事件的多版本 法可以为读者找出一共存在多少个版本,每一个版 发现也就是找到关于这一事件的不同方面、不同说 本的描述是什么,那么对于读者获取相关新闻信息 法或不同观点等,让用户能够一目了然地看到这一 将会十分有用 事件的不同角度和层面. 遗憾的是,目前关于事件多版本发现的研究很 为了得到有效的多个版本描述,一个关于新闻 少,没有太多有价值的相关文献.对于多版本发现最 事件的多版本发现算法需要满足以下3个特性: 直接的考虑就是进行简单的聚类分析.聚类是数据 1)多样性.即给定一个文档集合D作为输入, 挖掘技术中极为重要的组成部分,是在事先不规定 多版本发现算法需要在不改变相似度函数的情况 分组规则的情况下,将数据按照其自身特征划分成 下,找到m(m>1)个不同的版本:,i=1:m.也就 不同的簇(cluster),不同簇的数据之间差距越大、越 是说算法不依赖于相似度函数的形式。 明显越好,而每个簇内部的数据之间要尽量相似,差 2)区别性.得到的每一个版本:(i=1:m)应该 距越小越好.常见的聚类算法有K-means算法、 是显著不同的.这里指的是任意2个版本之间应该 Birch算法、Dbscan算法、Clique算法、神经网络方法 具有高度不相似度 等4].但是单纯的聚类方法具有很多局限性.由 3)高质性.得到的每一个版本':((i=1:m)应该 于对于同一事件的新闻报道在内容主体上通常具有 是关于相似度函数表现强健的(qualitatively 高度的相似性,简单的聚类方法无法将其中不同的 8 trong). “声音”有效地区分开来.文献[15]提出了一种基于 可以证明,本文介绍的多版本发现算法满足以 图模型的事件多版本发现算法.该算法是基于语义 上提到的多样性、区别性和高质性, 的迭代算法,通过提取流行词并将之过滤来降低同 2 ,CDW:基于文本的事件多版本发现模型 一特定事件的文档之间的紧密联系性.然后构建词 图以发现词与词之间的层次关系.根据社区发现算 2.1CDW算法框架 法6,构建虚拟文档来表示每一版本的中心.最后 CDW(clustering by highly-differentiated words) 根据Rocchio分类算法「来进行多版本的分类, 对于事件的多版本发现,最朴素、最直接的做法就是 尽管本文在内容上借鉴上述一些前人的工作, 对文档进行简单的聚类.然而,由于大数据集文档间 但无论从算法思想还是效果上都有很大创新.一方 存在复杂的语义关联和高度的相似性,仅仅简单的 面,它提出了话题层的概念,建立了文档集与话题层 聚类方法无法得到区分度高的版本类别,“区别性” 的映射关系,利用LDA将文档集合引申到话题空 方面的表现很差.为了解决这个问题,本文提出的 间,然后对每一话题进行特征提取.另一方面,它提 CDW事件多版本发现算法将整个问题分为2部分: 出了一种有效的提取高区分度特征的方法.该方法 首先,需要找到具有高区分度的特征;其次,将文档 过滤掉了文本集之间相似性的部分,有效地提取出 进行特征向量化,并且进行文本聚类.进一步具体分 文档集之间的差异性特征,从而提高多版本发现的 析,本文算法可以分为以下3步: 效率和准确度, 1)寻找区分度高的特征.每一篇文档都可以被 基本定义 表示成a bag of words,对于大数据集来说,不经筛选 无疑会造成维数灾难.为了得到更利于区分文档的特 关于事件的多版本发现,这里首先要讨论的就 征并去掉干扰噪音,本算法将文档集引申到话题层

第4期 肖融,等:基于文本的新闻事件多版本发现模型 ·309· 通过运用词频过滤和提取popular words等方法,对特 进行聚类.这样,就得到了文档的初步类别信息. 征进行筛选和降维,最终得到区分度较高的特征. 方法步骤如下[2]: 2)特征向量化,构建处理后的文档.需要将所 1)初始化.确定K的值,以及抽样数目和参数. 有文档用经过筛选的高区分度特征进行向量化表 进行LDA分析,得到词-话题矩阵. 示.这里,本算法利用的是TF-DF加权技术 2)矩阵每一行为一个词的特征向量,对其进行 3)文本聚类.经过特征筛选和特征表示,已经 聚类 得到了经过处理的文档特征向量.然后,用K-means 首先,利用LDA分析将文档集映射到话题层, 方法01进行文本聚类,得到最终的多版本 给定一个文档集合D,每个文档d包含一个词 图1展示了CDW算法的流程框架.下面将对 序列{01,02,…,0n.在集合D对应的LDA模型 这3步做进一步具体说明. 中,首先假设话题数目固定为K,然后经过LDA分 析得到每个文档属于每个话题的概率. 然后进行文本聚类.在DA分析后,获得一个 过滤公共词 词-话题的矩阵,每一行是词在文本上的分布,每行 有K维.之后把词的特征向量进行聚类,根据最大 提取 隶属原则,将每篇文章划为概率最大的话题.这样就 LDA ·高区分度 特征 完成了文档集到话题层的映射. 2.2.3 popular words的提取算法 提取popular words 通过之前2步对特征集的降维和提取,至此已经 将文档集进行了话题的映射并且得到了初步的聚类 -----------------------4 结果.现在,需要对每一类进行提取popular words,从 文档特征向量化 而得到每一类最具代表性的词.这里所用到的提取方 法是基于文献[25]中提到的关键词提取方法,并加以 改进运用.本文认为,并往往在重要的句子中.有代表 文本聚类 性的词往往和其他有代表性的词共同出现并且,句 图1CDW算法框架 子和词能够根据他们的连接结构计算排名.所以,首 Fig.1 The framework of CDW algorithm 先计算句子排名,找到重要的句子集,从而减少句子 2.2高区分度特征的生成策略 的影响构建句子连接关系图G,句子s:和边的权 词汇是文档最基础的组成单元,也是最常用的 值F(s,s)定义如下: 特征表示.然而,如果将一篇文档包含的所有词语都 IF(s)=maxCo(s) 作为这篇文档的特征,那么对于大数据集来说可能 Length(s;) 会造成维数灾难.所以,必须提取出对于区分文档版 式中:maxCo(s:,s)表示s:和s之间相同词的个数, 本最有效的词语,以进行降维 Length(s)表示s的长度.然后构造邻接矩阵Ms,利 2.2.1根据词频过滤公共词 用PageRank26的思想,对M3进行迭代计算得到每 词频过滤是进行特征筛选时最基础的手段.经 一个SRank(s:),其代表句子i的重要程度, 过分析可知,对于同一事件的文档集中频率较高的 下一步根据句子的重要程度计算词的重要程 词通常是描述客观事件本身的词,并不具有版本信 度.其基本思想与句子的计算和排名近似.同样建立 息.所以,本算法首先统计数据集中的每一个词出现 词链接关系无向图Gm,词i与词j之间边的权值定 在文档中的数目作为这个词的频率,这里设定一个 义如下: 阈值d,将频率高于阈值d的词全部筛掉.另外也过 support(ij)=>SRank(s,). ijep 滤掉频率为1的词. 式中:p代表句子s。中的词集,SRank(s,)代表sp的 2.2.2基于LDA分析的话题映射与聚类 重要程度.,然后利用PageRank算法思想进行排名, 本算法利用LDA分析21]对词频过滤后的特征 得到每一个词的WRank(w:).根据WRank(w;)的大 集进行进一步特征提取,这样做的目的是进一步降 小,排名靠前的词为popular words. 维,并且将文档集映射到不同的话题.然后,对文档集 最后将每一类得到的popular words合并去重到

·310 智能系统学报 第7卷 一个集合中,作为最终得到的具有高区分度的特征 2)提取每一个话题的特征; 集合 3)合并所有话题的特征,过滤掉公共部分,找 2.3特征向量化 到具有特性的特征词项; 在这一步中,需要将原始数据集用得到的高区 4)将原始文档集用提取出的特征表示,进行聚类 分度特征词进行表示.对文档进行向量化最常用的 最终得到不同版本的文档集, 方法就是计算每个词的TT-DF权值,作为这一特征 的特征值.TP-DP2]实际上是TP*DP,F为词 3实验与评价 频,IDF为反文档频率.计算公式如下: 3.1实验数据集 TFij= nij 为了展示CDW算法的有效性,作者在2个真 ∑ 实的数据集上进行了实验.一个是韩国的天安舰沉 I DI 没事件,包括533篇文档,分别来自英国广播BBC、 IDF,logd:d 英国天空广播、美国之音、美国纽约时报、朝日新闻、 最后,TT-IDF=TFwi×IDF 朝鲜日报等,以下简称为CS.另一个是台湾连胜文 2.4文本聚类 枪击案,包括391篇文档,分别来自腾讯、雅虎、新 最后,对处理后的数据集进行文本聚类这里用 浪、搜狐、人民网、凤凰网等,以下简称为LSW. 的是K-means聚类算法93o.K-均值聚类(K-means 韩国天安舰事件发生于2010年3月26日,韩 clustering)是MacQueen提出的一种非监督实时聚 国军方称其一艘导弹护卫舰“天安舰”因发生不明 类算法,在最小化误差函数的基础上将数据划分为 原因的爆炸事故而沉没.由于确切的原因一直无法 预定的类别数K.设定类别数目K,然后将数据对象 调查清楚,所以关于此次沉没事件的原因引发了很 划分为K个聚类以便使所获得的聚类满足:同一聚 大争议.类似地,台湾连胜文枪击案发生于2010年 类中的对象相似度较高;不同聚类中的对象相似度 11月26日,当时正值台湾5市选举,连战的儿子连 较小. 胜文在助选时头部遭到枪击,由于正值政治敏感时 2.5文档集与话题层的映射关系 期,关于此次枪击案凶手的动机就成了一大疑点: 图2展示了CDW事件多版本算法中文档集与 表1CS和LSW数据集说明 话题层的映射关系以及整个算法的流程。 Table 1 Illustration of data sets CS and LSW 过滤后 高区分度 数据集文档数词条数 的词数 特征数 文档集 CS 533 9842 6749 879 目目目目 LSW 391 7477 4952 650 数据集CS中,经过去停用词和词根还原后的 词条一共有9842个,利用词频过滤后有6749个, 话题1 话题2 话题m 最后提取到的高区分度特征词为879个.数据集 话题层 LSW中,经过去停用词和词根还原后的词条一共有 7477个,利用词频过滤后有4952个,最后提取到 特征1 特征2 特征m 的高区分度特征词为650个。 3.2评估方法 对于一个事件的新闻报道,很难通过逐篇浏览 特征向量化和文个聚类 来确定每一篇报道属于哪一个版本.所以,本文采用 高区分度特征 一个逐对判别的方法来评估CDW算法的效用。 在逐对判别方法中,这里关注的是某一对文档 图2文档与话题层的映射关系 是否属于同一版本,首先,需要构建标准测试集.作 Fig.2 Mapping between documents and topics 者从CS数据集中随机选取了200对文档,从LSW 通过图示和之前的算法介绍,总结如下: 数据集中随机选取了150对文档,并且确保每一对 1)建立文档集与话题层之间的映射关系,将文 文档都不同.然后,把每一对文档给志愿者浏览,让 档映射到不同的话题中; 他们投票决定每一对文档是否属于同一版本.如果
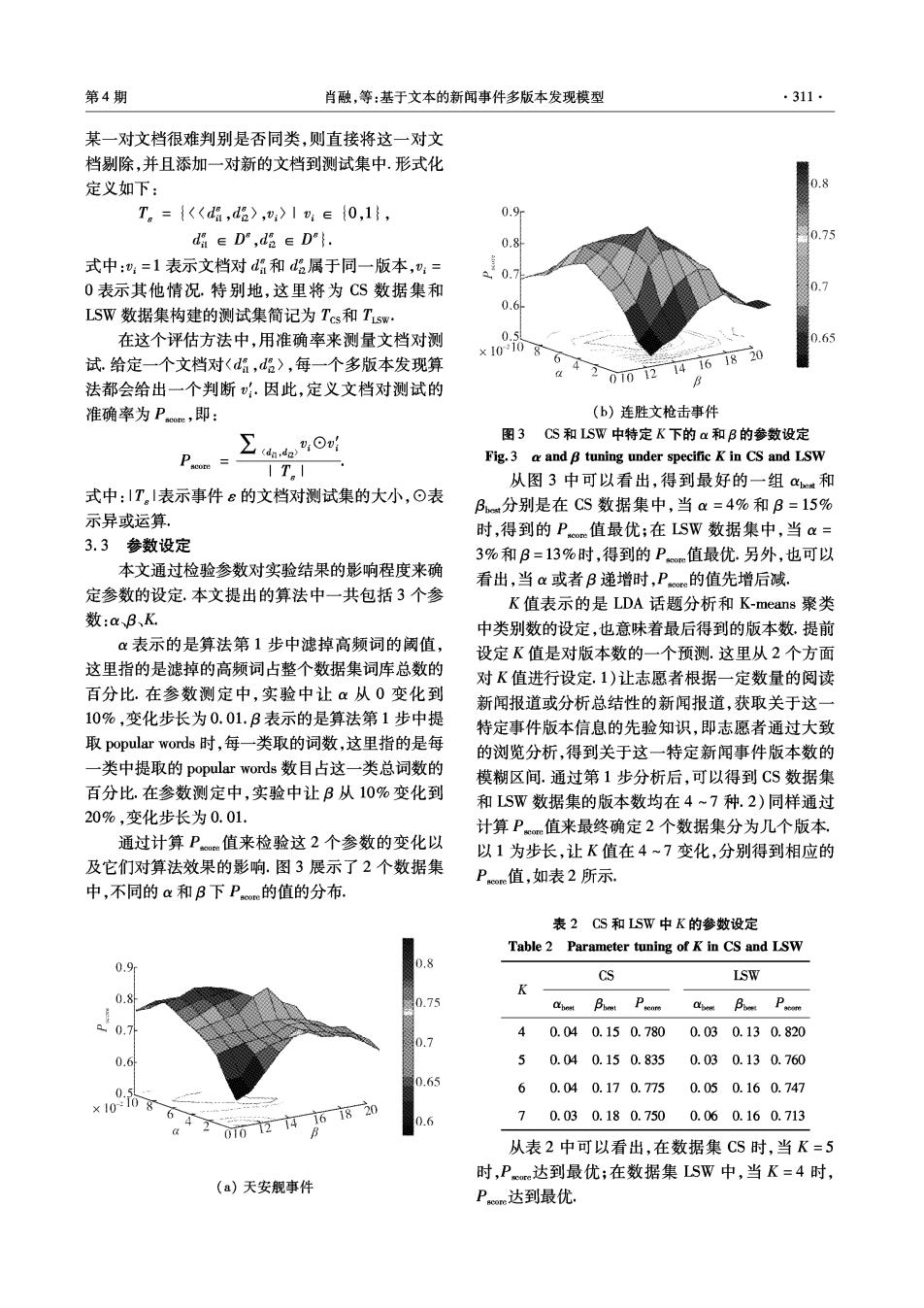
第4期 肖融,等:基于文本的新闻事件多版本发现模型 311· 某一对文档很难判别是否同类,则直接将这一对文 档剔除,并且添加一对新的文档到测试集中.形式化 定义如下: T。={〈d,d>,:〉1∈{0,1}, 0.9 d∈D,d∈D"}. 0.8 式中::=1表示文档对d和d属于同一版本,:= 0.7 0表示其他情况.特别地,这里将为CS数据集和 07 LSW数据集构建的测试集简记为Tcs和Tsw: 0.6 在这个评估方法中,用准确率来测量文档对测 0.s/ 0.65 ×10168 试.给定一个文档对〈d,d〉,每一个多版本发现算 6420101214161820 法都会给出一个判断.因此,定义文档对测试的 B 准确率为Pe,即: (b)连胜文枪击事件 ∑4he,0 图3CS和LSW中特定K下的a和B的参数设定 Fig.3 a and B tuning under specific K in CS and LSW 1T。 从图3中可以看出,得到最好的一组和 式中:IT。I表示事件ε的文档对测试集的大小,⊙表 B分别是在CS数据集中,当a=4%和B=15% 示异或运算. 时,得到的Pm值最优;在SW数据集中,当a= 3.3参数设定 3%和B=13%时,得到的P值最优.另外,也可以 本文通过检验参数对实验结果的影响程度来确 看出,当a或者B递增时,P的值先增后减。 定参数的设定.本文提出的算法中一共包括3个参 K值表示的是LDA话题分析和K-means聚类 数:aB、K 中类别数的设定,也意味着最后得到的版本数.提前 α表示的是算法第1步中滤掉高频词的阈值, 设定K值是对版本数的一个预测.这里从2个方面 这里指的是滤掉的高频词占整个数据集词库总数的 对K值进行设定,1)让志愿者根据一定数量的阅读 百分比.在参数测定中,实验中让α从0变化到 新闻报道或分析总结性的新闻报道,获取关于这一 10%,变化步长为0.01.B表示的是算法第1步中提 特定事件版本信息的先验知识,即志愿者通过大致 取popular words时,每一类取的词数,这里指的是每 的浏览分析,得到关于这一特定新闻事件版本数的 一类中提取的popular words数目占这一类总词数的 模糊区间.通过第1步分析后,可以得到CS数据集 百分比.在参数测定中,实验中让B从10%变化到 和LSW数据集的版本数均在4~7种.2)同样通过 20%,变化步长为0.01. 计算P.值来最终确定2个数据集分为几个版本, 通过计算P值来检验这2个参数的变化以 以1为步长,让K值在4~7变化,分别得到相应的 及它们对算法效果的影响.图3展示了2个数据集 Po心值,如表2所示. 中,不同的a和B下Pm的值的分布. 表2CS和LSW中K的参数设定 Table 2 Parameter tuning of K in CS and LSW 0.9 0.8 CS LSW K 0.8 0.75 Bhont Cpem Buet Psoome 0.71 4 0.040.150.780 0.030.130.820 0.7 0.6 5 0.040.150.835 0.030.130.760 0.65 0.5 6 0.040.170.775 0.050.160.747 ×1068 .6 70.030.180.7500.060.160.713 从表2中可以看出,在数据集CS时,当K=5 时,Pc达到最优;在数据集LSW中,当K=4时, (a)天安舰事件 Po心达到最优