
第3章统计描述讲义 SPSS基本统计分析是进行其他统计分析的基础和前提。通过基本统计方法的学习,可 以对要分析数据的总体特征有比较准确的把握,从而有助于选择其他更为深入的统计分析方 法。 本章主要介绍如何在SPSS中进行平均数、中位数、众数、方差、百分位、须数、峰度 偏度、探索分析、交叉联列表分析、多选项分析、基本统计报表制作等的操作。 3.1均值(Mean)和均值标准误差(S.E.mean) 3.11统计学上的定义和计算公式 定义:均值(平均值、平均数)表示的是某变量所有取值的集中趋势或平均水平。例如, 学生某门学科的平均成绩、公司员工的平均收入、某班级学生的平均身高等。 计算公式如下。 总体平均数:若一组数据X1,X2,XN,代表一个大小为N的有限总体,则其总 体平均数为 样本平均数:若一组数据xl,x2,.,m,代表一个大小为n的有限样本,则其样本平 均数为 样本数据来自总体。样本的统计描述量可以反映总体数据的特征,但由于抽样等原因, 使得样本数据不一定能够完全准确地反映总体,它可能与总体的真实值之间存在一定的差 异。进行不同次抽样,会得到若干个不同的样本均值,它们与总体均值存在着不同的差异。 均值标准误差(Standard Error of Mean,S.E.mean)就是描述这些样本均值与总体 均值之间平均差异程度的统计量。 3.1.2SPSS中实现过程 研究问题 求某班级学生在一次数学测验中的平均成绩,数据如表31所示。 数学成绩 9988795954897956899923897050 67788956 表31某班级的数学成绩 实现步骤 图3-l在菜单中选择“Frequencies”命令 图3-2“Frequencies”对话框(一) 图3-3“Frequencies:Statistics”对话框(一) 3.13结果和讨论
第 3 章 统计描述讲义 SPSS 基本统计分析是进行其他统计分析的基础和前提。通过基本统计方法的学习,可 以对要分析数据的总体特征有比较准确的把握,从而有助于选择其他更为深入的统计分析方 法。 本章主要介绍如何在 SPSS 中进行平均数、中位数、众数、方差、百分位、频数、峰度、 偏度、探索分析、交叉联列表分析、多选项分析、基本统计报表制作等的操作。 3.1 均值(Mean)和均值标准误差(S.E.mean) 3.1.1 统计学上的定义和计算公式 定义:均值(平均值、平均数)表示的是某变量所有取值的集中趋势或平均水平。例如, 学生某门学科的平均成绩、公司员工的平均收入、某班级学生的平均身高等。 计算公式如下。 总体平均数:若一组数据 X1,X2,.,XN,代表一个大小为 N 的有限总体,则其总 体平均数为 样本平均数:若一组数据 x1,x2,.,xn,代表一个大小为 n 的有限样本,则其样本平 均数为 样本数据来自总体。样本的统计描述量可以反映总体数据的特征,但由于抽样等原因, 使得样本数据不一定能够完全准确地反映总体,它可能与总体的真实值之间存在一定的差 异。进行不同次抽样,会得到若干个不同的样本均值,它们与总体均值存在着不同的差异。 均值标准误差(Standard Error of Mean,S.E. mean)就是描述这些样本均值与总体 均值之间平均差异程度的统计量。 3.1.2 SPSS 中实现过程 研究问题 求某班级学生在一次数学测验中的平均成绩,数据如表 3-1 所示。 数 学 成 绩 99 88 79 59 54 89 79 56 89 99 23 89 70 50 67 78 89 56 表 3-1 某班级的数学成绩 实现步骤 图 3-1 在菜单中选择“Frequencies”命令 图 3-2 “Frequencies”对话框(一) 图 3-3 “Frequencies:Statistics”对话框(一) 3.1.3 结果和讨论

3.2中位数(Median) 32.1统计学上的定义和计算公式 定义:把一组数据按递增或递减的顺序排列,处于中间位置上的变量值就是中位数。它 是一种位置代表值,所以不会受到极端数值的影响,具有较高的稳健性 计算公式:一个大小为的数列,要求其中位数,首先应把该数列按大小顺序排列好,如 果为奇数,那么该数列的中位数就是位置上的数:如果N为偶数,中位数则是该数列中 第与第+1位置上两个数值的平均数。 3.2.2SPSS中实现过程 研究问题 求某班级学生身高的中位数,数据如表32所示。 表3-2某班级学生的身高 身高(cm) 174168164174176150183162171146 189167 实现步骤 图3-4“Frequencies:Statistics”对话框(二) 32.3结果和时论 3.3众数(Mode) 3.3.1统计学上的定义和计算公式 定义:众数是指一组数据中,出现次数最多的那个变量值。众数在描述数据集中趋势方 面有一定的意义。例如,制鞋厂可以根据消费者所需鞋的尺码的众数来安排生产。 计算公式:手工计算众数比较麻烦,需要统计数据的次数分布。 3.3.2SSS中实现过程 研究问愿 求某医院当天出生新生儿的体重的众数,数据如表33所示 表33新生儿的体重 体重(斤) 876754568756 765.57 4 实现步 图3-5“Frequencies.Statistics”对话框(三) 33.3结果和讨论
3.2 中位数(Median) 3.2.1 统计学上的定义和计算公式 定义:把一组数据按递增或递减的顺序排列,处于中间位置上的变量值就是中位数。它 是一种位置代表值,所以不会受到极端数值的影响,具有较高的稳健性。 计算公式:一个大小为的数列,要求其中位数,首先应把该数列按大小顺序排列好,如 果为奇数,那么该数列的中位数就是位置 上的数;如果 N 为偶数,中位数则是该数列中 第 与第 +1 位置上两个数值的平均数。 3.2.2 SPSS 中实现过程 研究问题 求某班级学生身高的中位数,数据如表 3-2 所示。 表 3-2 某班级学生的身高 身高(cm) 174 168 164 174 176 150 183 162 171 146 189 167 实现步骤 图 3-4 “Frequencies:Statistics”对话框(二) 3.2.3 结果和讨论 3.3 众数(Mode) 3.3.1 统计学上的定义和计算公式 定义:众数是指一组数据中,出现次数最多的那个变量值。众数在描述数据集中趋势方 面有一定的意义。例如,制鞋厂可以根据消费者所需鞋的尺码的众数来安排生产。 计算公式:手工计算众数比较麻烦,需要统计数据的次数分布。 3.3.2 SPSS 中实现过程 研究问题 求某医院当天出生新生儿的体重的众数,数据如表 3-3 所示。 表 3-3 新生儿的体重 体重(斤) 8 7 6 7 5 4 5 6 8 7 5 6 4 7 6 5.5 7 4 实现步骤 图 3-5 “Frequencies:Statistics”对话框(三) 3.3.3 结果和讨论

3.4全距(Rage) 3.4.1统计学上的定义和计算公式 定义:全距也称为极差,是数据的最大值与最小值之间的绝对差。在相同样本容量情况 下的两组数据,全距大的一组数据要比全距小的一组数据更为分散: 计算公式:最大值一最小值。 3.4.2SPSS中实现过程 研究问题 求某班级学生数学成绩的全距,数据如表34所示。 表34某班级的数学成绩 数学成绩 99887959548979568999238970 50 67788956 实现步骤 图3-6“Frequencies:.Statistics”对话框(四) 3.43结果和讨论 3.5方差(Variance)和标准差(Standard Deviation) 35.1统计学上的定义和计算公式 定义:方差是所有变量值与平均数偏差平方的平均值,它表示了一组数据分布的离散程 度的平均值。标准差是方差的平方根,它表示了一组数据关于平均数的平均离散程度。方差 和标准差越大,说明变量值之间的差异越大,距离平均数这个“中心”的离散趋势越大。 3.5.2SPSS中实现过程 研究问题 求某班级学生数学成绩的方差和标准差,数据如表31所示。 实现步骤 图3-7在菜单中选择“Descriptives”命令 图3-8“Descriptives”对话框(一) 图3-9“Descriptives::Options”对话框(一) 3.5.3结果和讨论 3.6四分位数(Quartiles)?、十分位数(Deciles)和百分位数(Percentiles) 3.6.1统计学上的定义 定义:四分位数是将一组个案由小到大(或由大到小)排序后,用3个点将全部数据分 为四等份,与3个点上相对应的变量称为四分位数,分别记为Q1(第一四分位数)、Q2(第
3.4 全距(Range) 3.4.1 统计学上的定义和计算公式 定义:全距也称为极差,是数据的最大值与最小值之间的绝对差。在相同样本容量情况 下的两组数据,全距大的一组数据要比全距小的一组数据更为分散。 计算公式:最大值-最小值。 3.4.2 SPSS 中实现过程 研究问题 求某班级学生数学成绩的全距,数据如表 3-4 所示。 表 3-4 某班级的数学成绩 99 88 79 59 54 89 79 56 89 99 23 89 70 50 67 78 89 56 实现步骤 图 3-6 “Frequencies:Statistics”对话框(四) 3.4.3 结果和讨论 3.5 方差(Variance)和标准差(Standard Deviation) 3.5.1 统计学上的定义和计算公式 定义:方差是所有变量值与平均数偏差平方的平均值,它表示了一组数据分布的离散程 度的平均值。标准差是方差的平方根,它表示了一组数据关于平均数的平均离散程度。方差 和标准差越大,说明变量值之间的差异越大,距离平均数这个“中心”的离散趋势越大。 3.5.2 SPSS 中实现过程 研究问题 求某班级学生数学成绩的方差和标准差,数据如表 3-1 所示。 实现步骤 图 3-7 在菜单中选择“Descriptives”命令 图 3-8 “Descriptives”对话框(一) 图 3-9 “Descriptives:Options”对话框(一) 3.5.3 结果和讨论 3.6 四分位数(Quartiles)、十分位数(Deciles)和百分位数(Percentiles) 3.6.1 统计学上的定义 定义:四分位数是将一组个案由小到大(或由大到小)排序后,用 3 个点将全部数据分 为四等份,与 3 个点上相对应的变量称为四分位数,分别记为 Q1(第一四分位数)、Q2(第

二四分位数)、Q3(第三四分位数)。其中,Q3到Q1之间的距离的一半又称为四分位差, 记为Q。四分位差越小,说明中间的数据越集中:四分位数越大,则意味着中间部分的数据 越分散。 十分位数是将一组数据由小到大(或由大到小)排序后,用9个点将全部数据分为十等 份,与9个点位置上相对应的变量称为十分位数,分别记为D1,D2,D9,表示10% 的数据落在D1下,20%的数据落在D2下,.,90%落在D9下。 百分位数是将一组数据由小到大(或由大到小)排序后分割为100等份,与99个分割 点位置上相对应的变量称为百分位数,分别记为P1,P2,.,P99,表示1%的数据落在P叫 下,2%的数据落在P2下,99%落在P99下。 3.6.2SPSS中实现过程 研究问题1 求某班级学生数学成绩的四分位数,数据如表31所示。 实现步骤 图3-10“Frequencies Statistics”对话框(五) 研究问题2 测量54个某种机械零件的重量(克),求零件重量的D6,数据如表35所示。 表35零件的重量 零件重量(克) 4651595446533752505149444944 43465647 5252504755494752524245406063 54405550 5646495346554445575250495548 58425259 实现步骤 图3-1l“Frequencies:Statistics”对话框(六) 图3-12“Frequencies::Statistics”对话框(七) 研究问题3 测量出54个某种机械零件的重量(克),求零件重量的P37,数据如表3-5所示 实现步骤 图3-12“Frequencies:Statistics”对话框(七) 3.63结果和讨论 研究问颗1的程序运行结果如下表所示
二四分位数)、Q3(第三四分位数)。其中,Q3 到 Q1 之间的距离的一半又称为四分位差, 记为 Q。四分位差越小,说明中间的数据越集中;四分位数越大,则意味着中间部分的数据 越分散。 十分位数是将一组数据由小到大(或由大到小)排序后,用 9 个点将全部数据分为十等 份,与 9 个点位置上相对应的变量称为十分位数,分别记为 D1,D2,.,D9,表示 10% 的数据落在 D1 下,20%的数据落在 D2 下,.,90%落在 D9 下。 百分位数是将一组数据由小到大(或由大到小)排序后分割为 100 等份,与 99 个分割 点位置上相对应的变量称为百分位数,分别记为 P1,P2,.,P99,表示 1%的数据落在 P1 下,2%的数据落在 P2 下,.,99%落在 P99 下。 3.6.2 SPSS 中实现过程 研究问题 1 求某班级学生数学成绩的四分位数,数据如表 3-1 所示。 实现步骤 图 3-10 “Frequencies:Statistics”对话框(五) 研究问题 2 测量 54 个某种机械零件的重量(克),求零件重量的 D6,数据如表 3-5 所示。 表 3-5 零件的重量 46 51 59 54 46 53 37 52 50 51 49 44 49 44 43 46 56 47 52 52 50 47 55 49 47 52 52 42 45 40 60 63 54 40 55 50 56 46 49 53 46 55 44 45 57 52 50 49 55 48 58 42 52 59 实现步骤 图 3-11 “Frequencies:Statistics”对话框(六) 图 3-12 “Frequencies:Statistics”对话框(七) 研究问题 3 测量出 54 个某种机械零件的重量(克),求零件重量的 P37,数据如表 3-5 所示。 实现步骤 图 3-12 “Frequencies:Statistics”对话框(七) 3.6.3 结果和讨论 研究问题 1 的程序运行结果如下表所示
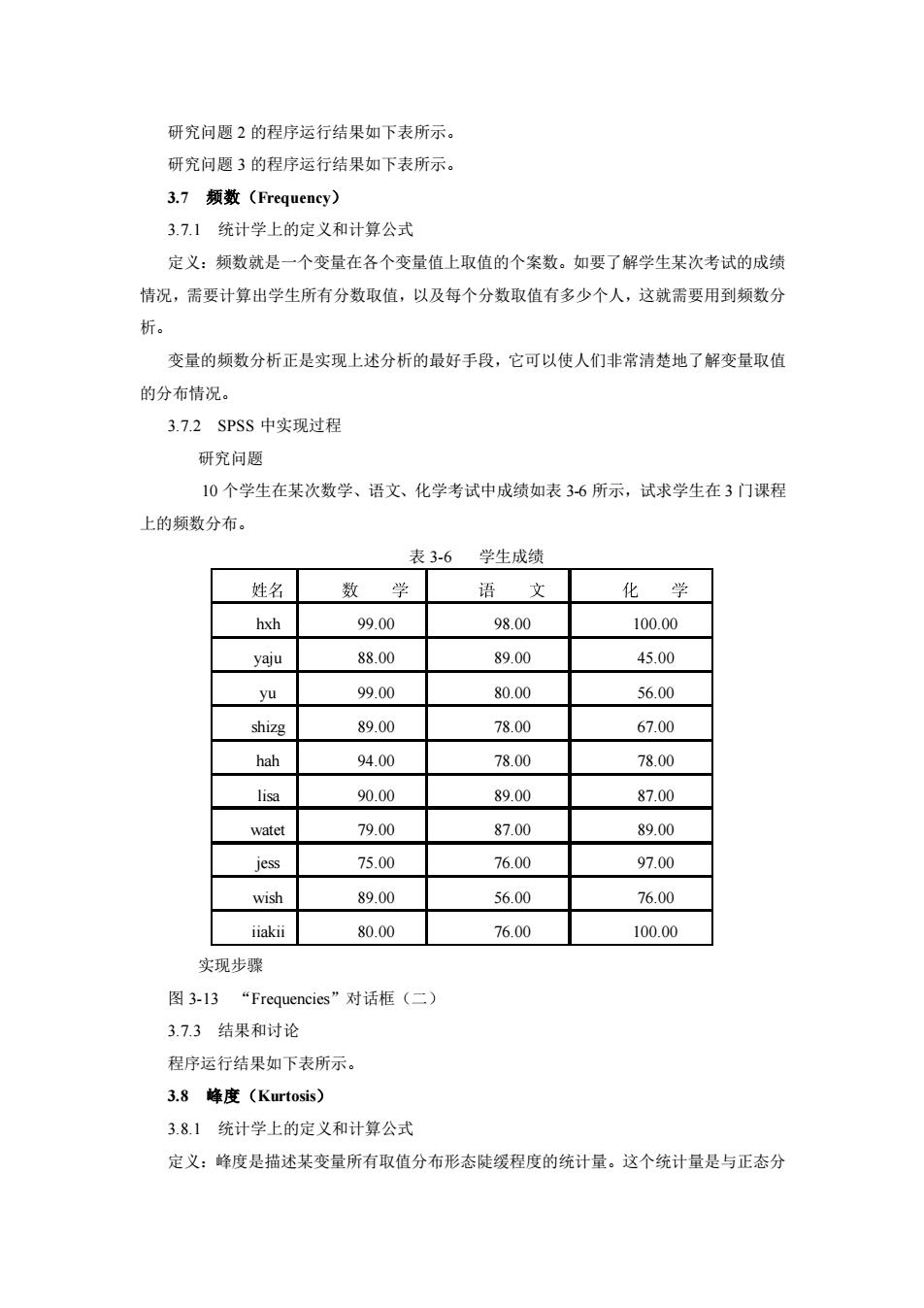
研究问题2的程序运行结果如下表所示。 研究问愿3的程序运行结果如下表所示。 3.7须数(Frequency) 3.71统计学上的定义和计算公式 定义:频数就是一个变量在各个变量值上取值的个案数。如要了解学生某次考试的成绩 情况,需要计算出学生所有分数取值,以及每个分数取值有多少个人,这就需要用到频数分 析。 变量的频数分析正是实现上述分析的最好手段,它可以使人们非常清楚地了解变量取值 的分布情况。 3.7.2SPSS中实现过程 研究问题 10个学生在某次数学、语文、化学考试中成绩如表3-6所示,试求学生在3门课程 上的频数分布。 表3-6学生成绩 姓名 数 语文 化学 hxh 99.00 98.00 100.00 yaju 88.00 89.00 45.00 yu 9900 80.00 56.00 shizg 89.00 78.00 67.00 hah 94.00 78.00 78.00 lisa 90.00 89.00 87.00 watet 79.00 87.00 89.00 jess 75.00 76.00 97.00 wish 89.00 56.00 76.00 iiakii 80.00 76.00 100.00 实现步骤 图3-13“Frequencies'”对话框(二) 3.7.3结果和讨论 程序运行结果如下表所示。 3.8峰度(Kurtosis) 3.8.1统计学上的定义和计算公式 定义:峰度是描述某变量所有取值分布形态陡缓程度的统计量。这个统计量是与正态分
研究问题 2 的程序运行结果如下表所示。 研究问题 3 的程序运行结果如下表所示。 3.7 频数(Frequency) 3.7.1 统计学上的定义和计算公式 定义:频数就是一个变量在各个变量值上取值的个案数。如要了解学生某次考试的成绩 情况,需要计算出学生所有分数取值,以及每个分数取值有多少个人,这就需要用到频数分 析。 变量的频数分析正是实现上述分析的最好手段,它可以使人们非常清楚地了解变量取值 的分布情况。 3.7.2 SPSS 中实现过程 研究问题 10 个学生在某次数学、语文、化学考试中成绩如表 3-6 所示,试求学生在 3 门课程 上的频数分布。 表 3-6 学生成绩 hxh 99.00 98.00 100.00 yaju 88.00 89.00 45.00 yu 99.00 80.00 56.00 shizg 89.00 78.00 67.00 hah 94.00 78.00 78.00 lisa 90.00 89.00 87.00 watet 79.00 87.00 89.00 jess 75.00 76.00 97.00 wish 89.00 56.00 76.00 iiakii 80.00 76.00 100.00 实现步骤 图 3-13 “Frequencies”对话框(二) 3.7.3 结果和讨论 程序运行结果如下表所示。 3.8 峰度(Kurtosis) 3.8.1 统计学上的定义和计算公式 定义:峰度是描述某变量所有取值分布形态陡缓程度的统计量。这个统计量是与正态分