
第11卷第6期 智能系统学报 Vol.11 No.6 2016年12月 CAAI Transactions on Intelligent Systems Dec.2016 D0I:10.11992/is.201611021 网络出版地址:http://www.cnki.net/kcms/detail,/23.1538.TP.20170116.1503.004.html 大数据与深度学习综述 马世龙,乌尼日其其格,李小平 (北京航空航天大学软件开发环境国家重点实验室,北京100191) 摘要:大数据时代改变了基于数理统计的传统数据科学,促进了数据分析方法的创新,从机器学习和多层神经网 络演化而来的深度学习是当前大数据处理与分析的研究前沿。从机器学习到深度学习,经历了早期的符号归纳机 器学习、统计机器学习、神经网络和20世纪末开始的数据挖掘等几十年的研究和实践,发现深度学习可以挖掘大数 据的潜在价值。本文给出大数据和深度学习的综述,特别是,给出了各种深层结构及其学习算法之间关联的图谱, 给出了深度学习在若干领域应用的知名案例。最后,展望了大数据上深度学习的发展与挑战。 关键词:大数据:机器学习:深层结构:深度学习:神经网铬:人工智能:学习算法:派生树 中图分类号:TP311文献标志码:A文章编号:1673-4785(2016)06-0728-15 中文引用格式:马世龙,乌尼日其其格,李小平.大数据与深度学习综述[J].智能系统学报,2016,11(6):728-742. 英文引用格式:MA Shilong,WUNIRI Qiqige,LI Xiaoping..Deep learning with big data:state of the art and development[J]. CAAI Transactions on Intelligent Systems,2016,11(6):728-742. Deep learning with big data:state of the art and development MA Shilong,WUNIRI Qiqige,LI Xiaoping (State Key Laboratory of Software Development Environment,Beihang University,Beijing 100191,China) Abstract:As the era of the big data arrives,it is accompanied by profound changes to traditional data science based on statistics.Big data also pushes innovations in the methods of data analysis.Deep learning that evolves from ma- chine learning and multilayer neural networks are currently extremely active research areas.From the symbolic ma- chine learning and statistical machine learning to the artificial neural network,followed by data mining in the 90s, this has built a solid foundation for deep learning(DL)that makes it a notable tool for discovering the potential val- ue behind big data.This survey compactly summarized big data and DL,proposed a generative relationship tree of the major deep networks and the algorithms,illustrated a broad area of applications based on DL,and highlighted the challenges to DL with big data,as well as identified future trends. Keywords:big data;machine learning;deep network;deep learning;neural network;artificial intelligence; learning algorithm;derivation tree 大数据不仅为企业带来丰厚的利润,也开启了理统计的传统数据科学,促进了新的数据分析方法 科学研究的第四范式,即数据密集型科学发现)。 的创新,从机器学习和多层神经网络演化而来的深 学术界和产业界对大数据的认识正逐步清晰化并形 度学习是当前大数据处理和分析方法的研究前沿。 成共识。大数据时代同时也改变了基于概率论和数 1大数据及其挑战 收稿日期:2016-11-15. 大数据(big data)的概念自1996年由John 基金项目:国家自然科学基金项目(61003016,61300007,61305054) 科技部基本科研业务费重点科技创新类项目(YWF-14 、Mashey!2]提出以来,经历了一段时间的众说纷纭,带 SXY-007):软件开发环境国家重点实验室自主探索基金项 着产业界的事实数据,不断进入学术界的研究领域, SKLSDE-2012ZX-28 ,SKLSDE-2014ZX-06). 通信作者:李小平.E-mail:lce.rex@163.com. 引领了一个时代[)的到来
第 11 卷第 6 期 智 能 系 统 学 报 Vol.11 №.6 2016 年 12 月 CAAI Transactions on Intelligent Systems Dec. 2016 DOI:10.11992 / tis.201611021 网络出版地址:http: / / www.cnki.net / kcms/ detail / 23.1538.TP.20170116.1503.004.html 大数据与深度学习综述 马世龙,乌尼日其其格,李小平 (北京航空航天大学 软件开发环境国家重点实验室,北京 100191) 摘 要:大数据时代改变了基于数理统计的传统数据科学,促进了数据分析方法的创新,从机器学习和多层神经网 络演化而来的深度学习是当前大数据处理与分析的研究前沿。 从机器学习到深度学习,经历了早期的符号归纳机 器学习、统计机器学习、神经网络和 20 世纪末开始的数据挖掘等几十年的研究和实践,发现深度学习可以挖掘大数 据的潜在价值。 本文给出大数据和深度学习的综述,特别是,给出了各种深层结构及其学习算法之间关联的图谱, 给出了深度学习在若干领域应用的知名案例。 最后,展望了大数据上深度学习的发展与挑战。 关键词:大数据;机器学习;深层结构;深度学习;神经网络;人工智能;学习算法;派生树 中图分类号: TP311 文献标志码:A 文章编号:1673-4785(2016)06-0728-15 中文引用格式:马世龙,乌尼日其其格,李小平. 大数据与深度学习综述[J]. 智能系统学报, 2016, 11(6): 728-742. 英文引用格式:MA Shilong, WUNIRI Qiqige, LI Xiaoping. Deep learning with big data: state of the art and development[ J]. CAAI Transactions on Intelligent Systems, 2016, 11(6): 728-742. Deep learning with big data: state of the art and development MA Shilong, WUNIRI Qiqige, LI Xiaoping (State Key Laboratory of Software Development Environment, Beihang University, Beijing 100191, China) Abstract:As the era of the big data arrives, it is accompanied by profound changes to traditional data science based on statistics. Big data also pushes innovations in the methods of data analysis. Deep learning that evolves from ma⁃ chine learning and multilayer neural networks are currently extremely active research areas. From the symbolic ma⁃ chine learning and statistical machine learning to the artificial neural network, followed by data mining in the 90s, this has built a solid foundation for deep learning (DL) that makes it a notable tool for discovering the potential val⁃ ue behind big data. This survey compactly summarized big data and DL, proposed a generative relationship tree of the major deep networks and the algorithms, illustrated a broad area of applications based on DL, and highlighted the challenges to DL with big data, as well as identified future trends. Keywords: big data; machine learning; deep network; deep learning; neural network; artificial intelligence; learning algorithm; derivation tree 收稿日期:2016-11-15. 基金项目:国家自然科学基金项目( 61003016, 61300007, 61305054); 科技部基本科研业务费重点科技创新类 项 目 ( YWF⁃14⁃ JSJXY⁃007);软件开发环境国家重点实验室自主探索基金项 目(SKLSDE⁃2012ZX⁃28,SKLSDE⁃2014ZX⁃06). 通信作者:李小平. E⁃mail:lee.rex@ 163.com. 大数据不仅为企业带来丰厚的利润,也开启了 科学研究的第四范式,即数据密集型科学发现[1] 。 学术界和产业界对大数据的认识正逐步清晰化并形 成共识。 大数据时代同时也改变了基于概率论和数 理统计的传统数据科学,促进了新的数据分析方法 的创新,从机器学习和多层神经网络演化而来的深 度学习是当前大数据处理和分析方法的研究前沿。 1 大数据及其挑战 大数据 ( big data) 的 概 念 自 1996 年 由 John Mashey [2]提出以来,经历了一段时间的众说纷纭,带 着产业界的事实数据,不断进入学术界的研究领域, 引领了一个时代[3]的到来

第6期 马世龙,等:大数据与深度学习综述 .729. 1.1大数据特点和界定 特点,但最早的3个V仍被视作大数据应具备的3 从21世纪初开始,产业界开始意识到数据产生的 个特征,贯穿于大数据生命周期中的各个阶段[) 规模和速度可能会对基础设施特别是存储设备造成压 从而也形成了学术界和产业界认同趋于一致的大数 力)。根据Martin Hilbert的一项统计人类信息总量的 据定义,如表2所示。 研究,在2000年,数字存储信息只占全球数据量的 表2大数据定义 1/4,其他75%的信息尚都存储在报纸、胶片、黑胶唱片 Table 2 Big data definitions 和盒式磁带这类媒介上:但经过短短的几年时间,到了 机构 定义 2007年,人类大约存储了300EB的数据,其中只有7% 需要新处理模式才能具有更强的决策力、 是存储在报纸、书籍、图片等媒介上的模拟数据,其余 Gartner 洞察发现力和流程优化能力的海量、 全部是数字数据。数字数据的总量以每40个月翻一 高增长率和多样化的信息资产( 番的速度积累。注:PB(PetaBytes拍字节)=1024TB= 种规模大到在获取、存储、管理、分析方面大 20字节,EB(ExaBytes艾字节)=1024PB=20字节,ZB 大超出了传统数据库软件工具能力范围的数据 麦肯锡 (ZettaBytes泽字节)=1024EB=2"字节,YB(Yotta- 集合,具有海量数据规模、快速数据流转、多样 Bytes尧字节)=1024ZB=20字节。 数据类型和价值密度低等四大特征 大数据是指利用常用软件工具捕获,管理和处 然而有了规模和速度就是大数据吗?研究人员在 Wiki 理数据所耗时间超过可容忍时间的数据集[) 不同时期对大数据的特点进行了总结。首当其冲的是 1.2大数据存储与处理现状 2O01年,META集团分析师Doug Laney给出大数据的 3V特征),分别为规模性(Volume)、多样性(Variety) 早在2000年,美国斯隆数字巡天项目启动,其 位于新墨西哥州的望远镜,在短短几周内收集到的 和高速性(Velocity)。10年后,DC在此基础上又提出 第4个特征,即数据的价值(Value)[o。2012年BM则 数据比天文学历史上总共收集的数据还要多。云平 认为大数据的第4个特征是指真实性(Veracity)[-】。 台D0M0公司从2010年开始做过一份有趣的统 后来,有人将上述所有特征合起来称为大数据的5V特 计一“数据从不休息”,将不同社交网络每分钟产 征,也有人从不同的应用视角和需求出发,又提出了粘 生的数据进行比较,并形象地给出了它们的数据总 性(Viscosity)、邻近性(Vicinity)、模糊性(Vague)等多 量[)。据统计,某社交网络产生的评论数在 种不同的特征,形成了3+xV的大数据特征[)。这些特 2010一2011年期间为每分钟60余万条,而在 征的具体含义,如表1。 2013一2015期间迅速增长为每分钟410余万条。 表1大数据特征 据另一个统计,2015年美国股市每天的成交量可高 Table 1 Big data characteristics 达70亿股。Google每天要处理超过24PB的数据, 名称 含义 这个数据处理量是美国国家图书馆所有纸质出版物 规模可从数百TB到数十数百PB、 所含数据量的千倍之多4。由此说明,除了互联网 规模性(Volume) 甚至到EB规模 之外,物联网、移动终端乃至传统的产业都在迅速产 包括各种格式和形态的数据, 生大量的数据。研究人员对大数据的产生方式进行 多样性(Variety) 如文本、图像、音频、视频 了分类),并指出大数据产生方式经历了被动生 需要在一定的时间限度下 实效性(Velocity) 成、主动生成、自动生成3个阶段],如表3所示。 得到及时处理 表3大数据产生阶段 价值密度低,需要通过分析挖掘 价值密度(Value) Table 3 Big data generating 和利用产生商业价值 阶段 方式 特点 采集的数据的质量影响分析 真实性(Veracity) 运营式系统阶段,伴随一定的运 结果的准确性 被动 营活动数据被动产生并保存 易变性(Variability) 指数据流的格式变化多样 用户原创内容阶段,尤其是在Web2.0 粘性(Viscosity) 指数据流之间的关联性是否强 时代,社交网络的出现以及以智能手机 邻近性(Vicinity) 获取数据资源的距离 2 主动 平板电脑为代表的新型移动设备的使 传播性(Virality) 数据在网络中传播的速度 用率上升,爆炸式地、主动地产生UGC 有效性(Volatility) 数据的有效性及存储期限 (user generated content)数据 因采集手段的多样性和局限性 模糊性(Vague) 感知式系统阶段,随着带有处理 获取的数据具有模糊性 自动 功能的传感器广泛布置于社会各处, 随着应用的不同研究人员给出了众多的大数据 源源不断地、自动地产生新的数据
1.1 大数据特点和界定 从 21 世纪初开始,产业界开始意识到数据产生的 规模和速度可能会对基础设施特别是存储设备造成压 力[2] 。 根据 Martin Hilbert 的一项统计人类信息总量的 研究[4] ,在 2000 年,数字存储信息只占全球数据量的 1/ 4,其他 75%的信息尚都存储在报纸、胶片、黑胶唱片 和盒式磁带这类媒介上;但经过短短的几年时间,到了 2007 年,人类大约存储了 300 EB 的数据,其中只有 7% 是存储在报纸、书籍、图片等媒介上的模拟数据,其余 全部是数字数据。 数字数据的总量以每 40 个月翻一 番的速度积累。 注:PB(PetaBytes 拍字节)= 1 024 TB= 2 50字节,EB(ExaBytes 艾字节)= 1 024PB = 2 60字节,ZB (ZettaBytes 泽字节) = 1 024 EB= 2 70 字节,YB(Yotta⁃ Bytes 尧字节)= 1 024 ZB=2 80字节。 然而有了规模和速度就是大数据吗? 研究人员在 不同时期对大数据的特点进行了总结。 首当其冲的是 2001 年,META 集团分析师 Doug Laney 给出大数据的 3V 特征[5] ,分别为规模性(Volume)、多样性(Variety) 和高速性(Velocity)。 10 年后,IDC 在此基础上又提出 第 4 个特征,即数据的价值(Value) [6] 。 2012 年 IBM 则 认为大数据的第 4 个特征是指真实性(Veracity) [7-8] 。 后来,有人将上述所有特征合起来称为大数据的 5V 特 征,也有人从不同的应用视角和需求出发,又提出了粘 性(Viscosity)、邻近性(Vicinity)、模糊性(Vague)等多 种不同的特征,形成了 3+xV 的大数据特征[9] 。 这些特 征的具体含义,如表 1。 表 1 大数据特征 Table 1 Big data characteristics 名称 含义 规模性(Volume) 规模可从数百 TB 到数十数百 PB、 甚至到 EB 规模 多样性(Variety) 包括各种格式和形态的数据, 如文本、图像、音频、视频 实效性(Velocity) 需要在一定的时间限度下 得到及时处理 价值密度(Value) 价值密度低,需要通过分析挖掘 和利用产生商业价值 真实性(Veracity) 采集的数据的质量影响分析 结果的准确性 易变性(Variability) 指数据流的格式变化多样 粘性(Viscosity) 指数据流之间的关联性是否强 邻近性(Vicinity) 获取数据资源的距离 传播性(Virality) 数据在网络中传播的速度 有效性(Volatility) 数据的有效性及存储期限 模糊性(Vague) 因采集手段的多样性和局限性, 获取的数据具有模糊性 随着应用的不同研究人员给出了众多的大数据 特点,但最早的 3 个 V 仍被视作大数据应具备的 3 个特征,贯穿于大数据生命周期中的各个阶段[9] , 从而也形成了学术界和产业界认同趋于一致的大数 据定义,如表 2 所示。 表 2 大数据定义 Table 2 Big data definitions 机构 定义 Gartner 需要新处理模式才能具有更强的决策力、 洞察发现力和流程优化能力的海量、 高增长率和多样化的信息资产[10] 麦肯锡 一种规模大到在获取、存储、管理、分析方面大 大超出了传统数据库软件工具能力范围的数据 集合,具有海量数据规模、快速数据流转、多样 数据类型和价值密度低等四大特征[11] Wiki 大数据是指利用常用软件工具捕获、管理和处 理数据所耗时间超过可容忍时间的数据集[12] 1.2 大数据存储与处理现状 早在 2000 年,美国斯隆数字巡天项目启动,其 位于新墨西哥州的望远镜,在短短几周内收集到的 数据比天文学历史上总共收集的数据还要多。 云平 台 DOMO 公司从 2010 年开始做过一份有趣的统 计———“数据从不休息”,将不同社交网络每分钟产 生的数据进行比较,并形象地给出了它们的数据总 量[13] 。 据 统 计, 某 社 交 网 络 产 生 的 评 论 数 在 2010—2011 年 期 间 为 每 分 钟 60 余 万 条, 而 在 2013—2015 期间迅速增长为每分钟 410 余万条。 据另一个统计,2015 年美国股市每天的成交量可高 达 70 亿股。 Google 每天要处理超过 24 PB 的数据, 这个数据处理量是美国国家图书馆所有纸质出版物 所含数据量的千倍之多[14] 。 由此说明,除了互联网 之外,物联网、移动终端乃至传统的产业都在迅速产 生大量的数据。 研究人员对大数据的产生方式进行 了分类[15] ,并指出大数据产生方式经历了被动生 成、主动生成、自动生成 3 个阶段[15] ,如表 3 所示。 表 3 大数据产生阶段 Table 3 Big data generating 阶段 方式 特点 1 被动 运营式系统阶段,伴随一定的运 营活动数据被动产生并保存 2 主动 用户原创内容阶段,尤其是在 Web2.0 时代,社交网络的出现以及以智能手机、 平板电脑为代表的新型移动设备的使 用率上升,爆炸式地、主动地产生 UGC (user generated content)数据 3 自动 感知式系统阶段,随着带有处理 功能的传感器广泛布置于社会各处, 源源不断地、自动地产生新的数据 第 6 期 马世龙,等:大数据与深度学习综述 ·729·
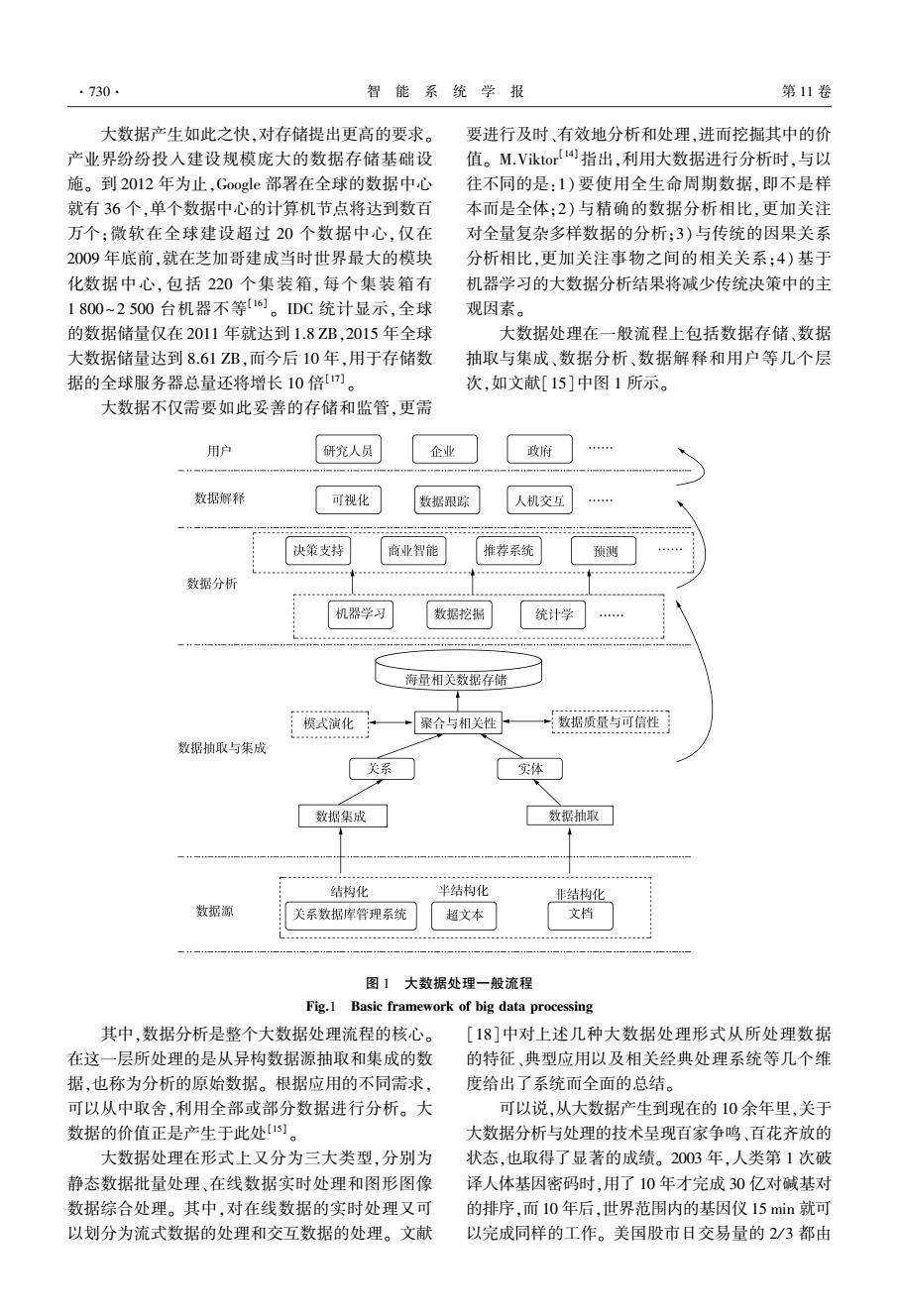
.730 智能系统学报 第11卷 大数据产生如此之快,对存储提出更高的要求。 要进行及时、有效地分析和处理,进而挖掘其中的价 产业界纷纷投入建设规模庞大的数据存储基础设 值。M.Viktor!指出,利用大数据进行分析时,与以 施。到2012年为止,Google部署在全球的数据中心 往不同的是:1)要使用全生命周期数据,即不是样 就有36个,单个数据中心的计算机节点将达到数百 本而是全体:2)与精确的数据分析相比,更加关注 万个;微软在全球建设超过20个数据中心,仅在 对全量复杂多样数据的分析:3)与传统的因果关系 2009年底前,就在芝加哥建成当时世界最大的模块 分析相比,更加关注事物之间的相关关系:4)基于 化数据中心,包括220个集装箱,每个集装箱有 机器学习的大数据分析结果将减少传统决策中的主 1800~2500台机器不等16。DC统计显示,全球 观因素。 的数据储量仅在2011年就达到1.8ZB,2015年全球 大数据处理在一般流程上包括数据存储、数据 大数据储量达到8.61ZB,而今后10年,用于存储数 抽取与集成、数据分析、数据解释和用户等几个层 据的全球服务器总量还将增长10倍[。 次,如文献[15]中图1所示。 大数据不仅需要如此妥善的存储和监管,更需 用户 研究人员 企业 政府 数据解释 可视化 数据跟踪 人机交互 决策支持 商业智能 推荐系统 预测 数据分析 机器学习 数据挖据 统计学 海量相关数据存储 模式演化 聚合与相关性 数据质量与可信性 数据抽取与集成 关系 实体 数据集成 数据抽取 结构化 半结构化 非结构化 数据源 关系数据库管理系统 超文本 文档 ”””。。””。““”“”小。中”““ ””。+““““。““。”“4。”小。。。 图1大数据处理一般流程 Fig.1 Basic framework of big data processing 其中,数据分析是整个大数据处理流程的核心。 [18]中对上述几种大数据处理形式从所处理数据 在这一层所处理的是从异构数据源抽取和集成的数 的特征、典型应用以及相关经典处理系统等几个维 据,也称为分析的原始数据。根据应用的不同需求, 度给出了系统而全面的总结。 可以从中取舍,利用全部或部分数据进行分析。大 可以说,从大数据产生到现在的10余年里,关于 数据的价值正是产生于此处]。 大数据分析与处理的技术呈现百家争鸣、百花齐放的 大数据处理在形式上又分为三大类型,分别为 状态,也取得了显著的成绩。2003年,人类第1次破 静态数据批量处理、在线数据实时处理和图形图像 译人体基因密码时,用了10年才完成30亿对碱基对 数据综合处理。其中,对在线数据的实时处理又可 的排序,而10年后,世界范围内的基因仪15min就可 以划分为流式数据的处理和交互数据的处理。文献 以完成同样的工作。美国股市日交易量的2/3都由
大数据产生如此之快,对存储提出更高的要求。 产业界纷纷投入建设规模庞大的数据存储基础设 施。 到 2012 年为止,Google 部署在全球的数据中心 就有 36 个,单个数据中心的计算机节点将达到数百 万个;微软在全球建设超过 20 个数据中心,仅在 2009 年底前,就在芝加哥建成当时世界最大的模块 化数据中心, 包括 220 个集装箱, 每个集装箱有 1 800~2 500 台机器不等[16] 。 IDC 统计显示,全球 的数据储量仅在 2011 年就达到 1.8 ZB,2015 年全球 大数据储量达到 8.61 ZB,而今后 10 年,用于存储数 据的全球服务器总量还将增长 10 倍[17] 。 大数据不仅需要如此妥善的存储和监管,更需 要进行及时、有效地分析和处理,进而挖掘其中的价 值。 M.Viktor [14]指出,利用大数据进行分析时,与以 往不同的是:1) 要使用全生命周期数据,即不是样 本而是全体;2) 与精确的数据分析相比,更加关注 对全量复杂多样数据的分析;3)与传统的因果关系 分析相比,更加关注事物之间的相关关系;4) 基于 机器学习的大数据分析结果将减少传统决策中的主 观因素。 大数据处理在一般流程上包括数据存储、数据 抽取与集成、数据分析、数据解释和用户等几个层 次,如文献[15]中图 1 所示。 图 1 大数据处理一般流程 Fig.1 Basic framework of big data processing 其中,数据分析是整个大数据处理流程的核心。 在这一层所处理的是从异构数据源抽取和集成的数 据,也称为分析的原始数据。 根据应用的不同需求, 可以从中取舍,利用全部或部分数据进行分析。 大 数据的价值正是产生于此处[15] 。 大数据处理在形式上又分为三大类型,分别为 静态数据批量处理、在线数据实时处理和图形图像 数据综合处理。 其中,对在线数据的实时处理又可 以划分为流式数据的处理和交互数据的处理。 文献 [18]中对上述几种大数据处理形式从所处理数据 的特征、典型应用以及相关经典处理系统等几个维 度给出了系统而全面的总结。 可以说,从大数据产生到现在的 10 余年里,关于 大数据分析与处理的技术呈现百家争鸣、百花齐放的 状态,也取得了显著的成绩。 2003 年,人类第 1 次破 译人体基因密码时,用了 10 年才完成 30 亿对碱基对 的排序,而 10 年后,世界范围内的基因仪 15 min 就可 以完成同样的工作。 美国股市日交易量的 2/ 3 都由 ·730· 智 能 系 统 学 报 第 11 卷

第6期 马世龙,等:大数据与深度学习综述 ·731· 建立在数学模型和算法之上的计算机程序自动完成, 位四。机器学习的研究从其热衷度上大致分为3 这些程序运用海量数据,能够预测利益和降低风险。 个阶段。 2009年Go0gle公司一家就为美国政府贡献了540亿 首先是20世纪五六十年代,机器学习的萌芽时 美元的利润。大数据已经成为企业、政府、机构决策 期。1959年,Arthur Samuel设计了一个具有学习能 的重要源泉,基于大数据分析的应用也成为人们衣食 力的下棋程序,可以通过一次次的对弈改善程序自 住行必不可少的工具。 身的棋艺。该程序不仅在4年后,战胜其设计者本 1.3大数据面临的挑战 人,7年后还战胜了美国一位保持8不败战绩的冠 如果说大数据产生之初所面临的挑战主要表现 军】。1956年,Frank Rosenblatt提出了一种基于 在如何及时收集和合理存储上[),那么10余年后的 神经网络的数学模型一感知机,采用线性优化的方 今天,大数据所面临的更多是如何有效地分析大数 法模拟人类学习的神经系统2。同期,Widrow提 据[90。大数据分析是指大数据内容上的分析与 出最小均方误差(least mean square,LMS)算法开 计算。由于大数据的众多特点,诸多传统方法如数 启了对自适应元素的训练]。这些探索使得机器 据挖掘不能直接应用于大数据集场景,大数据分析 学习第一次成为热门研究。 面临新的挑战,包括[9,15,18。 然而,1969年人工智能之父Marvin Minsky指 1)传统算法主要基于内存,随着数据规模的空 出单层感知机无法处理线性不可分问题,如异或 前扩大,它们的时空开销(计算复杂度)变得难于容 (同或)的分类:以及基于“黑箱”原理无法将模型与 忍。如何应对大批量的数据,将其装入内存并高效 现实世界直接对应等问题[26-],使得机器学习的研 运行成为新的挑战。 究一度进入低谷。虽然Widrow和Winter提出的 2)为了支持全数据量的实时数据处理,由于有 Madaline算法通过分段线性化的思想能够解决异或 时无法永久化存储,同时数据使用环境持续变化,使 的分类问题,但仍然不能彻底解决感知机所面临的 得无法掌握数据整个生命周期的特征。如何通过传 挑战。但是,这一尝试却开启了研究人员基于符号 统批量算法,基于历史数据构建无偏训练集成为新 归纳的机器学习和集成机器学习的探索[2)。同时, 的挑战。 20世纪70年代随着有限样本统计理论引入机器学 3)在大数据环境下,数据生产和采集的能力日 习,涌现了基于人工神经网络(artificial neural net- 益增强,这导致数据在规模增大的同时呈现出新的 wok,ANN)上的众多统计机器学习算法,最著名包 特点:属性数量大而稀疏、数据体量大而高噪声、数 括支持向量机(SVM)[2)、高斯混合模型(GMM)【2 据高维而复杂多样。如何处理高维、高噪声、稀疏数 以及逻辑回归(LR)。从而机器学习在一段冷静时 据成为新的挑战。 期之后第2次成为研究热点。 4)虽然机器学习善于处理非确定性的复杂问 进入20世纪80年代后期,Rumelhart提出多层 题,但是对于大数据处理与分析的场景,由于大数据 感知机从而解决了线性不可分的问题[)。但由于 的复杂多样性,机器学习在统计分析、学习目标和学 数据产生速度的不断提升,多层感知机也变得对其 习效率方面遇到了新的挑战。 无法适应,机器学习的算法亟待改进[2]。与此同 大数据分析所涉及的关键技术包括深度学习、 时,在神经网络领域Paul Werbos提出反向传播 知识计算和可视化等1)。其中深度学习是一种基 (back propagation,BP)算法使线性不可分的问题在 于机器学习、数据挖掘技术以及神经网络理论,分析 复杂神经网络上也能得以解决[3。从此,机器学习 大数据潜在价值的过程。本文,后续将围绕深度学 进入第3个阶段,即快速发展时期。在这一阶段,不 习进行综述,并最后给出这两个热门研究领域在未 断涌现出更优秀的算法],推动了人工智能在语音 来的一些可能性。 识别、图形图像处理以及自然语言处理方面的进展。 2从机器学习到深度学习 但机器学习在几十年的发展中,仍有很多问题 未能解决。其中包括:BP算法随着神经网络层次的 2.1机器学习发展历程 加深,参数优化效果无法传递到前层,从而导致容易 如果说人的学习是通过观察获得某种技能的过 出现局部最优解3)或过拟合问题34;此外,由于机 程,那么机器学习就是在用计算机模仿这一过 器学习在实际应用中需要手工设计特征和线性分类 程)。机器学习被认为是计算机拥有智能的根本 器,它不仅依赖领域专家的知识,还需要人在学习过 途径,在人工智能发展的早期阶段占据了重要地 程中参与这使得学习耗时耗力。而且,这种机器学
建立在数学模型和算法之上的计算机程序自动完成, 这些程序运用海量数据,能够预测利益和降低风险。 2009 年 Google 公司一家就为美国政府贡献了 540 亿 美元的利润。 大数据已经成为企业、政府、机构决策 的重要源泉,基于大数据分析的应用也成为人们衣食 住行必不可少的工具。 1.3 大数据面临的挑战 如果说大数据产生之初所面临的挑战主要表现 在如何及时收集和合理存储上[2] ,那么 10 余年后的 今天,大数据所面临的更多是如何有效地分析大数 据[19-20] 。 大数据分析是指大数据内容上的分析与 计算。 由于大数据的众多特点,诸多传统方法如数 据挖掘不能直接应用于大数据集场景,大数据分析 面临新的挑战,包括[9, 15, 18] : 1)传统算法主要基于内存,随着数据规模的空 前扩大,它们的时空开销(计算复杂度)变得难于容 忍。 如何应对大批量的数据,将其装入内存并高效 运行成为新的挑战。 2)为了支持全数据量的实时数据处理,由于有 时无法永久化存储,同时数据使用环境持续变化,使 得无法掌握数据整个生命周期的特征。 如何通过传 统批量算法,基于历史数据构建无偏训练集成为新 的挑战。 3)在大数据环境下,数据生产和采集的能力日 益增强,这导致数据在规模增大的同时呈现出新的 特点:属性数量大而稀疏、数据体量大而高噪声、数 据高维而复杂多样。 如何处理高维、高噪声、稀疏数 据成为新的挑战。 4)虽然机器学习善于处理非确定性的复杂问 题,但是对于大数据处理与分析的场景,由于大数据 的复杂多样性,机器学习在统计分析、学习目标和学 习效率方面遇到了新的挑战。 大数据分析所涉及的关键技术包括深度学习、 知识计算和可视化等[18] 。 其中深度学习是一种基 于机器学习、数据挖掘技术以及神经网络理论,分析 大数据潜在价值的过程。 本文,后续将围绕深度学 习进行综述,并最后给出这两个热门研究领域在未 来的一些可能性。 2 从机器学习到深度学习 2.1 机器学习发展历程 如果说人的学习是通过观察获得某种技能的过 程,那么 机 器 学 习 就 是 在 用 计 算 机 模 仿 这 一 过 程[21] 。 机器学习被认为是计算机拥有智能的根本 途径,在人工智能发展的早期阶段占据了重要地 位[22] 。 机器学习的研究从其热衷度上大致分为 3 个阶段。 首先是 20 世纪五六十年代,机器学习的萌芽时 期。 1959 年,Arthur Samuel 设计了一个具有学习能 力的下棋程序,可以通过一次次的对弈改善程序自 身的棋艺。 该程序不仅在 4 年后,战胜其设计者本 人,7 年后还战胜了美国一位保持 8 不败战绩的冠 军[23] 。 1956 年,Frank Rosenblatt 提出了一种基于 神经网络的数学模型—感知机,采用线性优化的方 法模拟人类学习的神经系统[24] 。 同期,Widrow 提 出最小均方误差( least mean square, LMS) 算法开 启了对自适应元素的训练[25] 。 这些探索使得机器 学习第一次成为热门研究。 然而,1969 年人工智能之父 Marvin Minsky 指 出单层感知机无法处理线性不可分问题,如异或 (同或)的分类;以及基于“黑箱”原理无法将模型与 现实世界直接对应等问题[26-27] ,使得机器学习的研 究一度进入低谷。 虽然 Widrow 和 Winter 提出的 Madaline 算法通过分段线性化的思想能够解决异或 的分类问题,但仍然不能彻底解决感知机所面临的 挑战。 但是,这一尝试却开启了研究人员基于符号 归纳的机器学习和集成机器学习的探索[27] 。 同时, 20 世纪 70 年代随着有限样本统计理论引入机器学 习,涌现了基于人工神经网络( artificial neural net⁃ work,ANN)上的众多统计机器学习算法,最著名包 括支持向量机(SVM) [28] 、高斯混合模型(GMM) [29] 以及逻辑回归(LR)。 从而机器学习在一段冷静时 期之后第 2 次成为研究热点。 进入 20 世纪 80 年代后期,Rumelhart 提出多层 感知机从而解决了线性不可分的问题[30] 。 但由于 数据产生速度的不断提升,多层感知机也变得对其 无法适应,机器学习的算法亟待改进[26] 。 与此同 时,在神经网络领域 Paul Werbos 提出反向传播 (back propagation,BP)算法使线性不可分的问题在 复杂神经网络上也能得以解决[31] 。 从此,机器学习 进入第 3 个阶段,即快速发展时期。 在这一阶段,不 断涌现出更优秀的算法[32] ,推动了人工智能在语音 识别、图形图像处理以及自然语言处理方面的进展。 但机器学习在几十年的发展中,仍有很多问题 未能解决。 其中包括:BP 算法随着神经网络层次的 加深,参数优化效果无法传递到前层,从而导致容易 出现局部最优解[33]或过拟合问题[34] ;此外,由于机 器学习在实际应用中需要手工设计特征和线性分类 器,它不仅依赖领域专家的知识,还需要人在学习过 程中参与这使得学习耗时耗力。 而且,这种机器学 第 6 期 马世龙,等:大数据与深度学习综述 ·731·

.732 智能系统学报 第11卷 习无法很好地处理自然数据(无标签数据),同时不 Boltzmann machine,DBM)。DBN是由GE Hinton于 易应用于深层的网络3]。然而解决这些问题,促成 20O6年提出的一种串联堆叠RBM形成的深层模 了机器学习新的分支—深度学习的研究。 型[4。该模型在训练阶段将一层RBM的输出作为 2.2多层结构和深度学习 另一层RBM的输入,由此逐步训练隐藏层的高阶数 深度学习也叫无监督特征学习(unsupervised 据相关性,最后采用BP对权值进行微调。而DBM feature learning),即可以无需人为设计特征提取,特 是一种特殊的BM。不同的是,除了有一个可视层 征从数据中学习而来。深度学习实质上是多层表示 之外,它具有多个隐藏层,并且只有相邻隐藏层的单 学习(representation learning)方法的非线性组合。 元之间才可以有连接。它们之间的对比如图3]。 表示学习是指从数据中学习表示(或特征),以便在 分类和预测时提取数据中有用信息[6]。深度学习 从原始数据开始将每层表示(或特征)逐层转换为 更高层更抽象的表示,从而发现高维数据中错综复 杂的结构]。 深度学习的发展不仅源于机器学习的丰厚积 累,同时也受到统计力学的启发。1985年D.H Ackley等基于玻尔兹曼分布,提出了一种具有无监 (a)深度置信网络(b)深度玻尔滋曼机 督学习能力的神经网络玻尔兹曼机(Boltzmann ma- 图3深度置信网络和深度玻尔兹曼机 chine,BM)[)。该模型是一种对称耦合的随机反馈 Fig.3 A DBN and a DBM 型二值单元神经网络,由可视单元和多个隐藏单元 对于一个RBM,如果把隐藏层的层数增加,可以 组成,用可视单元和隐单元表示随机网络与随机环 得到一个DBM:如果在靠近可视层的部分使用贝叶 境的学习模型,用权值表示单元之间的相关性。通 斯信念网络(即有向图模型),而在最远离可视层的部 过该模型能够描述变量之间的相互高阶作用,但其 分使用RBM,则可以得到一个DBN。由于RBM的训 算法复杂,不易应用3]。次年P.Smolensky基于他 练中采用对比散度CD算法[]可以快速得到训练,使 本人所提出的调和论给出了一种受限的玻尔兹曼机 得深度置信网络的训练速度也大幅度提升。 模型(RBM)。该模型将BM限定为两层网络,一个 在深度学习发展的10年中,基于上述两种网络 可视单元层和一个隐藏单元层。并且进一步限定层 结构的深度学习算法不时涌现,使其成为一门广袤 内神经元之间相互独立,无连接,层间的神经元才可 的学科。根据文献[43-45],本文对现有深度学习 以相互连接。如图2所示[3。 算法之间的派生关系进行梳理,形成如图4所示的 树形结构 该图通过节点和有向边展示了不同深层结构之 间的派生关系。派生关系表示深度网络是在网络结 构或训练算法上的微调或改进。有些深度学习算法 是在原有某个深度学习算法的基础上对其网络结构 进行了调整而形成,例如堆叠自动编码器就是受DBN 启发,将其中的RBM替换为AE而形成,如图4中 (a)一般玻尔兹曼机(b)受限的玻尔兹曼机 2007年Yoshua等提出的SAE。而有些深度学习算法 图2一般玻尔兹曼机和受限的玻尔兹曼机 则是结合了多种已有深度学习算法派生而来,例如堆 Fig.2 A general BM and a RBM 叠卷积自动编码器就是在卷积网络中采用了自动编 RBM通过两层马尔可夫随机场,从训练样本得 码器AE而形成,如图4中2011年Masci提出的 到的隐藏层中神经元状态,并估计独立于数据的期 SCAE。采用有向边将文中所涉及的深度学习算法相 望值。该模型由于大幅度提高了BM的学习效 连接,可以形成一棵深度网络派生树。在深度学习的 率[0],被众多研究人员所借鉴,从而开启了深度学 整个发展过程中DBN,DBM、AE和CNN构成了早期 习的研究热潮。 的基础模型。后续的众多研究则是在此基础上提出 其中最为典型的深度结构包括深度置信网络 或改进的新的学习模型。关于更多派生模型的详细 (deep belief network,DBN)和深度玻尔兹曼机(deep 信息如表4所示
习无法很好地处理自然数据(无标签数据),同时不 易应用于深层的网络[35] 。 然而解决这些问题,促成 了机器学习新的分支———深度学习的研究。 2.2 多层结构和深度学习 深度学习也叫无监督特征学习( unsupervised feature learning),即可以无需人为设计特征提取,特 征从数据中学习而来。 深度学习实质上是多层表示 学习( representation learning) 方法的非线性组合。 表示学习是指从数据中学习表示(或特征),以便在 分类和预测时提取数据中有用信息[36] 。 深度学习 从原始数据开始将每层表示(或特征)逐层转换为 更高层更抽象的表示,从而发现高维数据中错综复 杂的结构[35] 。 深度学习的发展不仅源于机器学习的丰厚积 累,同时也受到统计力学的启发。 1985 年 D. H. Ackley 等基于玻尔兹曼分布,提出了一种具有无监 督学习能力的神经网络玻尔兹曼机(Boltzmann ma⁃ chine,BM) [37] 。 该模型是一种对称耦合的随机反馈 型二值单元神经网络,由可视单元和多个隐藏单元 组成,用可视单元和隐单元表示随机网络与随机环 境的学习模型,用权值表示单元之间的相关性。 通 过该模型能够描述变量之间的相互高阶作用,但其 算法复杂,不易应用[38] 。 次年 P. Smolensky 基于他 本人所提出的调和论给出了一种受限的玻尔兹曼机 模型(RBM)。 该模型将 BM 限定为两层网络,一个 可视单元层和一个隐藏单元层。 并且进一步限定层 内神经元之间相互独立,无连接,层间的神经元才可 以相互连接。 如图 2 所示[39] 。 (a) 一般玻尔兹曼机 (b)受限的玻尔兹曼机 图 2 一般玻尔兹曼机和受限的玻尔兹曼机 Fig.2 A general BM and a RBM RBM 通过两层马尔可夫随机场,从训练样本得 到的隐藏层中神经元状态,并估计独立于数据的期 望值。 该模型由于大幅度提高了 BM 的学习效 率[40] ,被众多研究人员所借鉴,从而开启了深度学 习的研究热潮。 其中最为典型的深度结构包括深度置信网络 (deep belief network,DBN)和深度玻尔兹曼机(deep Boltzmann machine,DBM)。 DBN 是由 GE Hinton 于 2006 年提出的一种串联堆叠 RBM 形成的深层模 型[41] 。 该模型在训练阶段将一层 RBM 的输出作为 另一层 RBM 的输入,由此逐步训练隐藏层的高阶数 据相关性,最后采用 BP 对权值进行微调。 而 DBM 是一种特殊的 BM。 不同的是,除了有一个可视层 之外,它具有多个隐藏层,并且只有相邻隐藏层的单 元之间才可以有连接。 它们之间的对比如图 3 [39] 。 (a) 深度置信网络 (b)深度玻尔兹曼机 图 3 深度置信网络和深度玻尔兹曼机 Fig.3 A DBN and a DBM 对于一个 RBM,如果把隐藏层的层数增加,可以 得到一个 DBM;如果在靠近可视层的部分使用贝叶 斯信念网络(即有向图模型),而在最远离可视层的部 分使用 RBM,则可以得到一个 DBN。 由于 RBM 的训 练中采用对比散度 CD 算法[42]可以快速得到训练,使 得深度置信网络的训练速度也大幅度提升。 在深度学习发展的 10 年中,基于上述两种网络 结构的深度学习算法不时涌现,使其成为一门广袤 的学科。 根据文献[43-45],本文对现有深度学习 算法之间的派生关系进行梳理,形成如图 4 所示的 树形结构。 该图通过节点和有向边展示了不同深层结构之 间的派生关系。 派生关系表示深度网络是在网络结 构或训练算法上的微调或改进。 有些深度学习算法 是在原有某个深度学习算法的基础上对其网络结构 进行了调整而形成,例如堆叠自动编码器就是受 DBN 启发,将其中的 RBM 替换为 AE 而形成,如图 4 中 2007 年 Yoshua 等提出的 SAE。 而有些深度学习算法 则是结合了多种已有深度学习算法派生而来,例如堆 叠卷积自动编码器就是在卷积网络中采用了自动编 码器 AE 而形成,如图 4 中 2011 年 Masci 提出的 SCAE。 采用有向边将文中所涉及的深度学习算法相 连接,可以形成一棵深度网络派生树。 在深度学习的 整个发展过程中 DBN、DBM、AE 和 CNN 构成了早期 的基础模型。 后续的众多研究则是在此基础上提出 或改进的新的学习模型。 关于更多派生模型的详细 信息如表 4 所示。 ·732· 智 能 系 统 学 报 第 11 卷