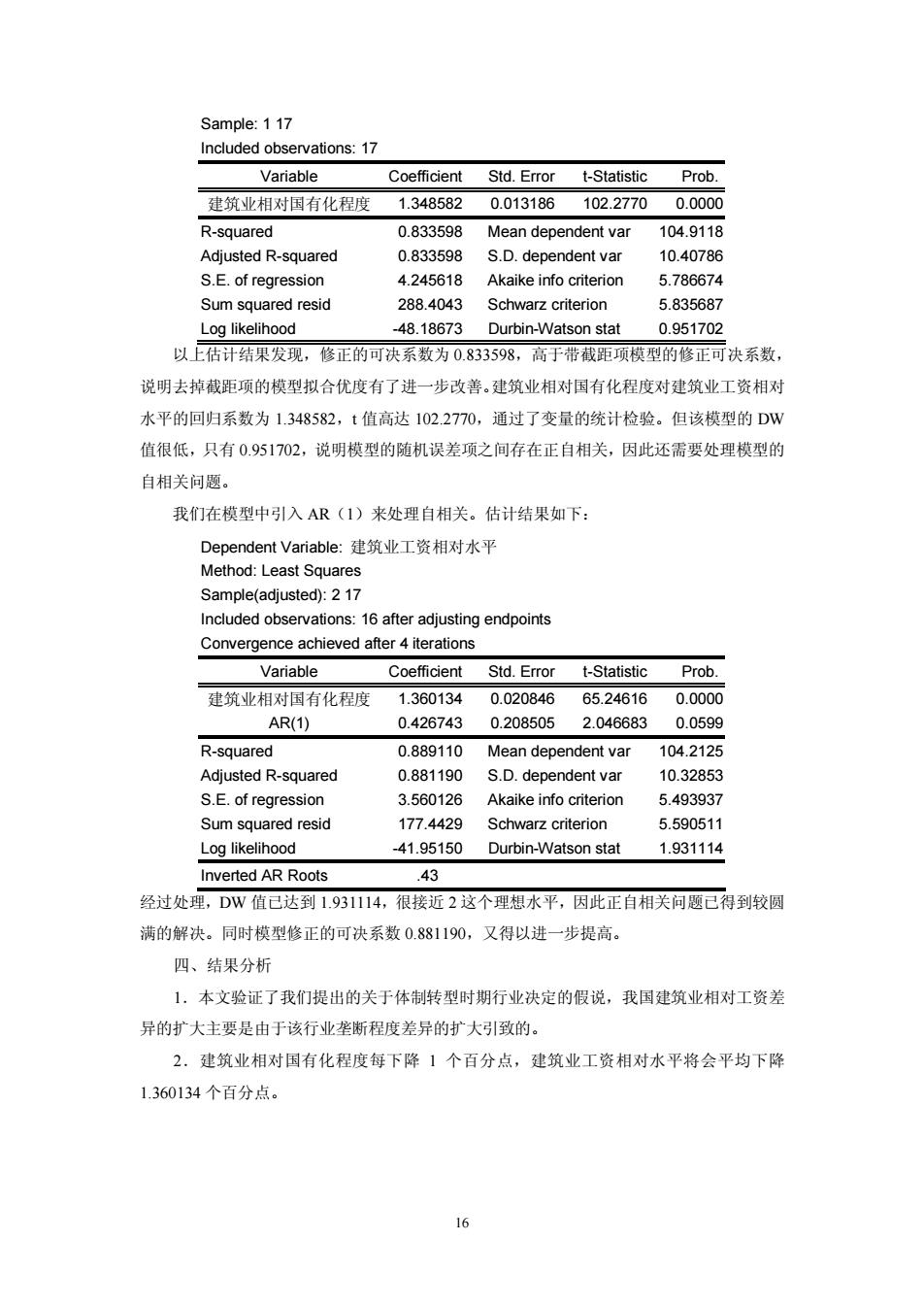
Sample:117 Included observations:17 Variable Coefficient Std.Error t-Statistic Prob. 建筑业相对国有化程度 1.3485820.013186 102.27700.0000 R-squared 0.833598 Mean dependent var 104.9118 Adiusted R-squared 0.833598 s.D.dependent var 10.40786 S.E.of regression 4245618 Akaike info criterion 5.786674 Sum ed resid 288.4043 Schw rit 5.835687 Log likelihood -48.18673 Durbin-Watson stat 0.95170 以上估计结果发现,修正的可决系数为0.833598。高于带截距项模型的修正可决系数 说明去掉截距项的模型拟合优度有了进一步改善。建筑业相对国有化程度对建筑业工资相对 水平的回归系数为1.348582,t值高达102,2770,通过了变量的统计检验。但该模型的DW 值很低,只有0.951702,说明模型的随机误差项之间存在正自相关,因此还需要处理模型的 自相关问题。 我们在模型中引入AR(1)来处理自相关。估计结果如下: Dependent variable:建筑业工路相对水平 Method:Least Squares Sampe(adjusted):17 Included observations:16 after adjusting endpoints Convergence achieved after 4 iterations Coefficient Std. t-Statistic Prob. 建惊业相对国有化程府 1.360134 0.020846 65.24616 0.0000 AR(1) 04267430.208505 2.046683 0.0599 R-squared 0.889110 Mean dependent va 104.2125 Adjusted R-squared 0.881190 S.D.dependent var 10.32853 S.E of rearession 3.560126 Akaike info criterion 5.493937 Sum squared resid 177.4429 Schwarz criterion 5.590511 Log likelihood 41.95150 Durbin-Watson stat 1.931114 Inverted AR Roots .43 经过处理,DW值已达到1.931114,很接近2这个理想水平,因此正自相关问题已得到较圆 满的解决。同时模型修正的可决系数0.881190,又得以进一步提高。 四、结果分析 1.本文验证了我们提出的关于体制转型时期行业决定的假说,我国建筑业相对工资差 异的扩大主要是由于该行业垄断程度差异的扩大引致的。 2.建筑业相对国有化程度每下降1个百分点,建筑业工资相对水平将会平均下降 1.360134个百分点
16 Sample: 1 17 Included observations: 17 Variable Coefficient Std. Error t-Statistic Prob. 建筑业相对国有化程度 1.348582 0.013186 102.2770 0.0000 R-squared 0.833598 Mean dependent var 104.9118 Adjusted R-squared 0.833598 S.D. dependent var 10.40786 S.E. of regression 4.245618 Akaike info criterion 5.786674 Sum squared resid 288.4043 Schwarz criterion 5.835687 Log likelihood -48.18673 Durbin-Watson stat 0.951702 以上估计结果发现,修正的可决系数为 0.833598,高于带截距项模型的修正可决系数, 说明去掉截距项的模型拟合优度有了进一步改善。建筑业相对国有化程度对建筑业工资相对 水平的回归系数为 1.348582,t 值高达 102.2770,通过了变量的统计检验。但该模型的 DW 值很低,只有 0.951702,说明模型的随机误差项之间存在正自相关,因此还需要处理模型的 自相关问题。 我们在模型中引入 AR(1)来处理自相关。估计结果如下: Dependent Variable: 建筑业工资相对水平 Method: Least Squares Sample(adjusted): 2 17 Included observations: 16 after adjusting endpoints Convergence achieved after 4 iterations Variable Coefficient Std. Error t-Statistic Prob. 建筑业相对国有化程度 1.360134 0.020846 65.24616 0.0000 AR(1) 0.426743 0.208505 2.046683 0.0599 R-squared 0.889110 Mean dependent var 104.2125 Adjusted R-squared 0.881190 S.D. dependent var 10.32853 S.E. of regression 3.560126 Akaike info criterion 5.493937 Sum squared resid 177.4429 Schwarz criterion 5.590511 Log likelihood -41.95150 Durbin-Watson stat 1.931114 Inverted AR Roots .43 经过处理,DW 值已达到 1.931114,很接近 2 这个理想水平,因此正自相关问题已得到较圆 满的解决。同时模型修正的可决系数 0.881190,又得以进一步提高。 四、结果分析 1.本文验证了我们提出的关于体制转型时期行业决定的假说,我国建筑业相对工资差 异的扩大主要是由于该行业垄断程度差异的扩大引致的。 2.建筑业相对国有化程度每下降 1 个百分点,建筑业工资相对水平将会平均下降 1.360134 个百分点

案例分析四中国税收增长的分析一多元线性回归模型的应用 一、研究的目的要求 改革开放以来,随着经济体制改革的深化和经济的快速增长,中国的财政收支状况发生 很大变化,中央和地方的税收收入1978年为519.28亿元,到2002年已增长到17636,45 亿元,25年间增长了33倍,平均每年增长%。为了研究影响中国税收收入增长的主要原 因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经 济模型。 影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看, 经济整体增长是税收增长的基本源泉。(2)公共财政的需求,税收收入是财政收入的主体, 社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算支出所表现的公共 财政的需求对当年的税收收入可能会有一定的影响。(3)物价水平。我国的税制结构以流 转税为主,以现行价格计算的GDP等指标和经营者的收入水平都与物价水平有关。(4) 税收政策因素。我国自1978年以来经历了两次大的税制政革,一次是19841985年的国有 企业利改税,另一次是1994年的全国范围内的新税制改革。税制改革对税收会产生影响, 特别是1985年税收陡增215.42%.但是第二次税制做革对税收增长速度的影响不是非常大。 因此,可以从以上几个方面,分析各种因素对中国税收增长的具体影响 二、棋型设定 为了全面反映中国税收增长的全貌,选择包括中央和地方税收 的“国家财政收入”中的“各项税收”(简称“税收收入”)作为被解释变量,以反映国家税 收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表:选择中央和地方 “财政支出”作为公共财政需求的代表:选择“商品零售物价指数”作为物价水平的代表。 由于财税体制的改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大, 可暂不考虑税制政革对税收增长的影响。所以解释变量设定为可观测的“国内生产总值”、 “财政支出”、“商品零售物价指数”等变量。从《中国统计年鉴》收集到以下数据(见表 33):
17 案例分析四 中国税收增长的分析——多元线性回归模型的应用 一、研究的目的要求 改革开放以来,随着经济体制改革的深化和经济的快速增长,中国的财政收支状况发生 很大变化,中央和地方的税收收入 1978 年为 519.28 亿元,到 2002 年已增长到 17636.45 亿元,25 年间增长了 33 倍,平均每年增长 %。为了研究影响中国税收收入增长的主要原 因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经 济模型。 影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看, 经济整体增长是税收增长的基本源泉。(2)公共财政的需求,税收收入是财政收入的主体, 社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算支出所表现的公共 财政的需求对当年的税收收入可能会有一定的影响。(3)物价水平。我国的税制结构以流 转税为主,以现行价格计算的 GDP 等指标和经营者的收入水平都与物价水平有关。(4) 税收政策因素。我国自 1978 年以来经历了两次大的税制改革,一次是 1984-1985 年的国有 企业利改税,另一次是 1994 年的全国范围内的新税制改革。税制改革对税收会产生影响, 特别是1985年税收陡增215.42%。但是第二次税制改革对税收增长速度的影响不是非常大。 因此,可以从以上几个方面,分析各种因素对中国税收增长的具体影响。 二、模型设定 为了全面反映中国税收增长的全貌,选择包括中央和地方税收 的“国家财政收入”中的“各项税收”(简称“税收收入”)作为被解释变量,以反映国家税 收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方 “财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。 由于财税体制的改革难以量化,而且 1985 年以后财税体制改革对税收增长影响不是很大, 可暂不考虑税制改革对税收增长的影响。所以解释变量设定为可观测的“国内生产总值”、 “财政支出”、“商品零售物价指数”等变量。从《中国统计年鉴》收集到以下数据(见表 3.3):
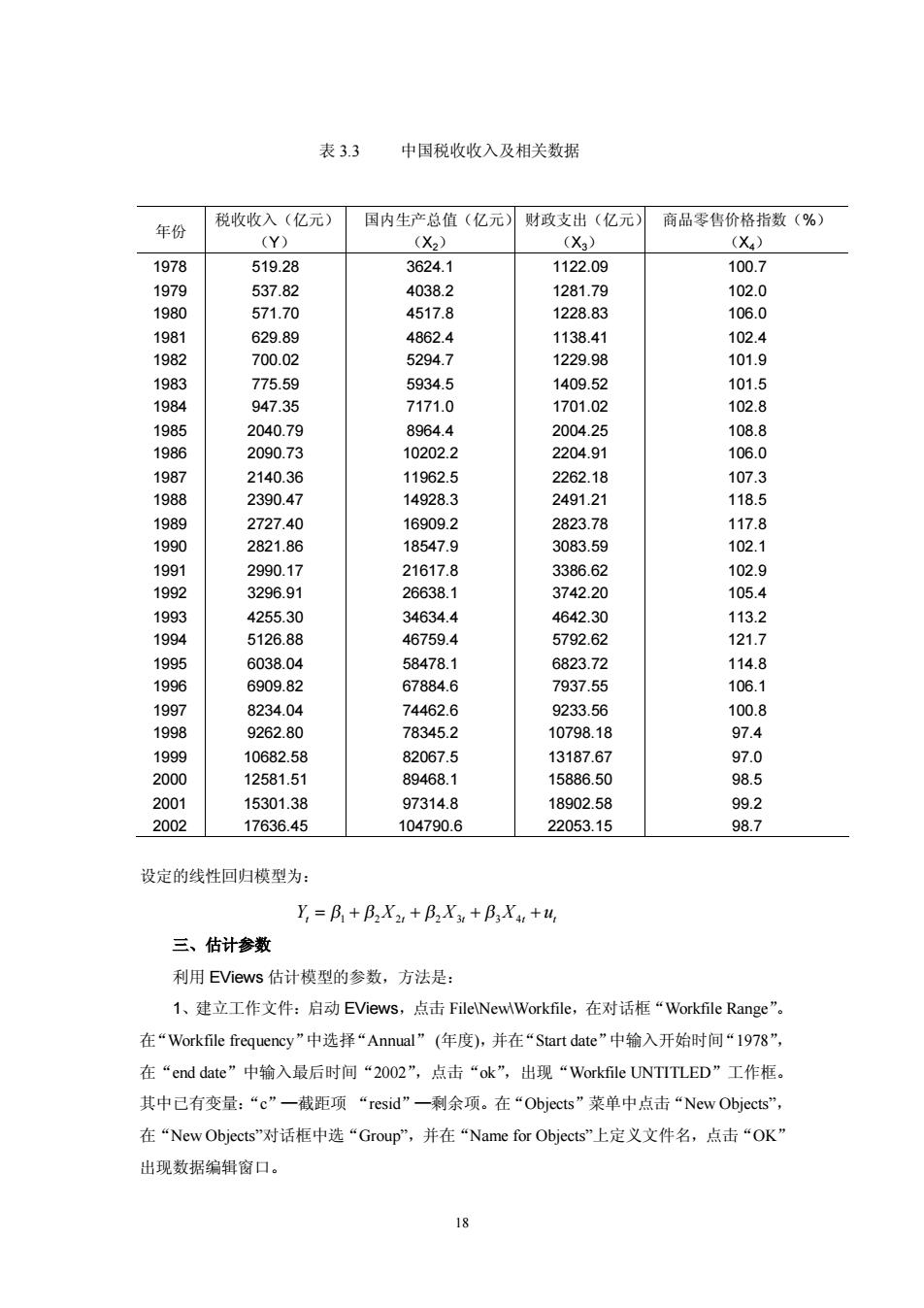
表33 中国税收收入及相关数据 年份 税收收入(亿元)国内生产总值(亿元)财政支出(亿元)商品零售价格指数(%) (Y) (X2) X3) (X4) 1978 519.28 3624.1 1122.09 100.7 1979 537.82 4038.2 1281.79 102.0 1980 571.70 4517.8 122883 106.0 198 629.89 102.4 1982 700.02 775.59 5934.5 947.3 7171.0 1985 2040.79 8964.4 2004.25 108.8 1986 2090.73 10202.2 2204.91 106.0 1987 2140.36 11962.5 2262.18 107.3 1988 2390.47 14928.3 2491.21 118.5 1989 272740 16909.2 2823.78 117.8 1990 2821.86 18547.9 308359 102.1 1991 2990.17 3386.62 1992 3296.91 3742.20 34634 46759.4 1995 6038,04 58478.1 6823.72 114.8 199 6909.82 67884.6 7937.55 106.1 1997 8234.04 74462.6 9233.56 100.8 1998 9262.80 78345.2 10798.18 97.4 1999 10682.58 82067.5 1318767 97.0 2000 1258151 8g4681 1588650 98.5 2001 1530138 973148 18902.58 99.2 2002 17636.45 104790.6 22053.15 98.7 设定的线性回归模型为: Y=B++BX+BX+u 三、估计参数 利用EViews估计模型的参数,方法是: 1、建立工作文件:启动EViews,点击FilelNewWorkfile,在对话框“Workfile Range”。 在“Workfile frequency”中选择“Annual'”(年度,并在“Startdate”中输入开始时间“1978”, 在“end date”中输入最后时间“2O02”,点击“ok”,出现“Workfile UNTITLED”工作框 其中已有变量:“c”一截距项“resid”一利余项。在“Objects”莱单中点击“New Objects” 在“NewObjects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK 出现数据编辑窗口
18 表 3.3 中国税收收入及相关数据 设定的线性回归模型为: Yt = b1 + b2X2t + b b 2X3t + + 3 4 X u t t 三、估计参数 利用 EViews 估计模型的参数,方法是: 1、建立工作文件:启动 EViews,点击 File\New\Workfile,在对话框“Workfile Range”。 在“Workfile frequency”中选择“Annual” (年度),并在“Start date”中输入开始时间“1978”, 在“end date”中输入最后时间“2002”,点击“ok”,出现“Workfile UNTITLED”工作框。 其中已有变量:“c”—截距项 “resid”—剩余项。在“Objects”菜单中点击“New Objects”, 在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK” 出现数据编辑窗口。 年份 税收收入(亿元) (Y) 国内生产总值(亿元) (X2) 财政支出(亿元) (X3) 商品零售价格指数(%) (X4) 1978 519.28 3624.1 1122.09 100.7 1979 537.82 4038.2 1281.79 102.0 1980 571.70 4517.8 1228.83 106.0 1981 629.89 4862.4 1138.41 102.4 1982 700.02 5294.7 1229.98 101.9 1983 775.59 5934.5 1409.52 101.5 1984 947.35 7171.0 1701.02 102.8 1985 2040.79 8964.4 2004.25 108.8 1986 2090.73 10202.2 2204.91 106.0 1987 2140.36 11962.5 2262.18 107.3 1988 2390.47 14928.3 2491.21 118.5 1989 2727.40 16909.2 2823.78 117.8 1990 2821.86 18547.9 3083.59 102.1 1991 2990.17 21617.8 3386.62 102.9 1992 3296.91 26638.1 3742.20 105.4 1993 4255.30 34634.4 4642.30 113.2 1994 5126.88 46759.4 5792.62 121.7 1995 6038.04 58478.1 6823.72 114.8 1996 6909.82 67884.6 7937.55 106.1 1997 8234.04 74462.6 9233.56 100.8 1998 9262.80 78345.2 10798.18 97.4 1999 10682.58 82067.5 13187.67 97.0 2000 12581.51 89468.1 15886.50 98.5 2001 15301.38 97314.8 18902.58 99.2 2002 17636.45 104790.6 22053.15 98.7

2、输入数据:点击“Quik”下拉菜单中的“Empty Group”,出现“Group'”窗口数据编 辑框,点第一列与“os”对应的格,在命令栏输入“Y”,点下行键“↓”,即将该序列命 名为Y,并依此输入Y的数据。用同样方法在对应的列命名X,、X、X,并输入相应的数 据。或者在EViews命令框直接键入“data Y XXX4”,回车出现“Group窗口数 据编辑框,在对应的Y、X、X、X下输入响应的数据。 3、估计参数:点击“Procs“下拉菜单中的“Make Equation”,在出现的对话框的“Equation Specification”栏中键入“YCX2XX,”,在“Estimation Settings”栏中选择“Least Sqares'”(最小二乘法),点“ok”,即出现回归结果: 表3.4 Date070505 me:16:54 Included observations:25 Variable Coefficient Std.Error t-Statistic Prob. 2582.791 940.6128 0012 0.02206 2.745860 000 0.000 7 A0gRsquared 09g706 Mean de ke 41 Log likelihood 2.6890 F-statist 2717.238 Durbin-Watson stat 0.94854 Prob(F-statistic) 0.0000 根据表3.4中数据,模型估计的结果为: Y,=-2582.791+0.022067X2+0.702104X3+23.98541X (940.6128)(0.0056) (0.0332) (8.7363) t=(-2.7459)(3.9566) (21.1247) (2.7449) R2=0.9974F2-0.9971F=2717.238d=21 四、模型检验 1、经济意义检验 模型估计结果说明,在假定其它变量不变的情况下,当年GDP每增长1亿元,税收收 入就会增长0.02207亿元:在假定其它变量不变的情况下,当年财政支出每增长1亿元,税 收收入会增长0.7021亿元:在假定其它变量不变的情况下,当年零售商品物价指数上涨 个百分点,税收收入就会增长23.9854亿元。这与理论分析和经验判断相一致。 9
19 2、输入数据:点击“Quik”下拉菜单中的“Empty Group”,出现“Group”窗口数据编 辑框,点第一列与“obs”对应的格,在命令栏输入“Y”,点下行键“↓”,即将该序列命 名为 Y,并依此输入 Y 的数据。用同样方法在对应的列命名 X2、X3、X4,并输入相应的数 据。或者在 EViews 命令框直接键入“data Y X 2 X3 X4 . ”,回车出现“Group”窗口数 据编辑框,在对应的 Y、X2、X3、X4下输入响应的数据。 3、估计参数:点击“Procs“下拉菜单中的“Make Equation”,在出现的对话框的“Equation Specification”栏中键入“Y C X2 X3 X4”,在“Estimation Settings”栏中选择“Least Sqares”(最小二乘法),点“ok”,即出现回归结果: 表 3.4 根据表 3.4 中数据,模型估计的结果为: ^ 2 3 4 2582.791 0.022067 0.702104 23.98541 Yi = - + X + + X X (940.6128) (0.0056) (0.0332) (8.7363) t= (-2.7459) (3.9566) (21.1247) (2.7449) 2 R = 0.9974 2 R = 0.9971 F=2717.238 df=21 四、模型检验 1、经济意义检验 模型估计结果说明,在假定其它变量不变的情况下,当年 GDP 每增长 1 亿元,税收收 入就会增长 0.02207 亿元;在假定其它变量不变的情况下,当年财政支出每增长 1 亿元,税 收收入会增长 0.7021 亿元;在假定其它变量不变的情况下,当年零售商品物价指数上涨一 个百分点,税收收入就会增长 23.9854 亿元。这与理论分析和经验判断相一致

2、统计检验 (1)拟合优度:由表34中数据可以得到:R2=0.9974,修正的可决系数为 R2-0.9971,这说明模型对样本的拟合很好。 (2)F检验:针对H。:B,=B=B:=0,给定显若性水平Q=0.05,在F分布表中查 出自由度为k1=3和nk-21的临界值E(3,20=3.075.由表34中得到F=2717238,由 于F=2717.238F(3,2)=3.075,应拒绝原假设。:B,=月=B,=0,说明回归方程显 著,即“国内生产总值”、“财政支出”、“商品零售物价指数”等变量联合起来确实对“税收 收入”有显著影响。 (3)1检验:分别针对H,:B,=0(=L2,34),给定显若性水平a=0.05,查t分布 表得自由度为mk=21临鄂值⅓-)=2.080 由表34中数据可得,与月、B:、B B对应的t统计量分别为2.7459、3.9566、21.1247、2.7449,其绝对值均大于 '-)=2.08 ,这说明分别都应当拒绝:B,=0(=l2,34),也就是说,当在 其它解释变最不变的情况下,解释变量“国内生产总值”(X入、“财政支出”(X人“商 品零售物价指数”(X4)分别对被解释变量“税收收入”Y都有显著的影响。 案例分析五中国A股新股抑价率多因素回归分析 1、新股的抑价发行 PO抑价是指发行定价存在若低估现象,即新股发行定价低于新股的市场价值,表现为 新股发行价格明显低于新股上市首日收盘价格,上市首日就能获得显著的超额回报。 市场化的发行制度下,新股发行的定价过程是发行企业、承销商和投资者之间多次谈判 的结果。一个有效的PO市场是不应该存在超常收益率的。但国外许多学者研究发现,在 一些发行市场化的市场中,尽管承销商通过努力平衡对发行股票的供给和需求来得到最佳发 行价格。但首日收益率(即新股上市首日收盘价相对于发行价的收益率)仍然显著为正,即 存在着显著的新股发行抑价现象。发行是证券市场运行的基础,而首次公开发行(nitial Public Offering缩写为PO)是股份公司由少数人持股向公众持股转变的重要步骤。发行定 价是发行业务中的核心环节,定价是否合理不仅关系到发行人、投资者以及承销商的切身利 益,而且关系到发行市场的监管乃至证券市场资源配置功能的发挥。O抑价率是衡量新股 发行定价是否合理的重要指标。如果PO抑价率小于0,即新股上市首日就跌破发行价,说 明定价过高:如果PO抑价率显著大于0,即上市首日就获得显著的超额收益,就说明新股 存在定价过低的现象。从各国的发行实践看,新股发行定价适度低于二级市场上市价格是普 遍存在的,这是由于股票市场PO发行中特有的信息不对称和信息不确定性等多种因素造 成的。 2、中国PO抑价率多因素模型分析 20
20 2、统计检验 (1)拟合优度:由表 3.4 中数据可以得到: 2 R = 0.9974 ,修正的可决系数为 2 R = 0.9971,这说明模型对样本的拟合很好。 (2)F 检验:针对 0 2 3 4 H : 0 b = b b = = ,给定显著性水平a = 0.05,在 F 分布表中查 出自由度为 k-1=3 和 n-k=21 的临界值 F (3, 21) 3.075 a = 。由表 3.4 中得到 F=2717.238,由 于 F=2717.238> F (3, 21) 3.075 a = ,应拒绝原假设 0 2 3 4 H : 0 b = b b = = ,说明回归方程显 著,即“国内生产总值”、“财政支出”、“商品零售物价指数”等变量联合起来确实对“税收 收入”有显著影响。 (3)t 检验:分别针对 H0 : 0 ( 1, 2,3, 4) j b = =j ,给定显著性水平a = 0.05,查 t 分布 表得自由度为 n-k=21 临界值 2 ta (n k - =) 2.080 。由表 3.4 中数据可得,与 ^ b1 、 ^ b2 、 ^ b3 、 ^ b4 对 应 的 t 统 计 量 分 别 为 -2.7459 、 3.9566 、 21.1247 、 2.7449 , 其 绝 对 值 均 大 于 2 ta (n k - =) 2.080 ,这说明分别都应当拒绝 H0 : 0 ( 1, 2,3, 4) j b = =j ,也就是说,当在 其它解释变量不变的情况下,解释变量“国内生产总值”( X2 )、“财政支出”( X3 )、“商 品零售物价指数”( X4 )分别对被解释变量“税收收入”Y 都有显著的影响。 案例分析五 中国 A 股新股抑价率多因素回归分析 1、新股的抑价发行 IPO 抑价是指发行定价存在着低估现象,即新股发行定价低于新股的市场价值,表现为 新股发行价格明显低于新股上市首日收盘价格,上市首日就能获得显著的超额回报。 市场化的发行制度下,新股发行的定价过程是发行企业、承销商和投资者之间多次谈判 的结果。一个有效的 IPO 市场是不应该存在超常收益率的。但国外许多学者研究发现,在 一些发行市场化的市场中,尽管承销商通过努力平衡对发行股票的供给和需求来得到最佳发 行价格。但首日收益率(即新股上市首日收盘价相对于发行价的收益率) 仍然显著为正,即 存在着显著的新股发行抑价现象。发行是证券市场运行的基础,而首次公开发行(Initial Public Offering 缩写为 IPO)是股份公司由少数人持股向公众持股转变的重要步骤。发行定 价是发行业务中的核心环节,定价是否合理不仅关系到发行人、投资者以及承销商的切身利 益,而且关系到发行市场的监管乃至证券市场资源配置功能的发挥。IPO 抑价率是衡量新股 发行定价是否合理的重要指标。如果 IPO 抑价率小于 0,即新股上市首日就跌破发行价,说 明定价过高;如果 IPO 抑价率显著大于 0,即上市首日就获得显著的超额收益,就说明新股 存在定价过低的现象。从各国的发行实践看,新股发行定价适度低于二级市场上市价格是普 遍存在的,这是由于股票市场 IPO 发行中特有的信息不对称和信息不确定性等多种因素造 成的。 2、中国 IPO 抑价率多因素模型分析