UST Cache Line Structure Memory address 0 1 Cache Line tag block(K words )VCD 2 Block (K words 。一行一块(字块),一块多个data,一个data一个word ● Tag:to identifies block,=内存块号? control bits:VCD 有效位(Valid):数据是否有效? ·无效数据:cold start/process migration/.first reference ·写操作的使无效法(Invalidated) Block - 重写位(overwrite,Dirty):数据是否修改? 2n.1 ·行替换时需要写回 Word Length -计数位(Count):访问频度? ·替换算法选择标识 Processor V Tag Data (K words) 256 … entries X32 32
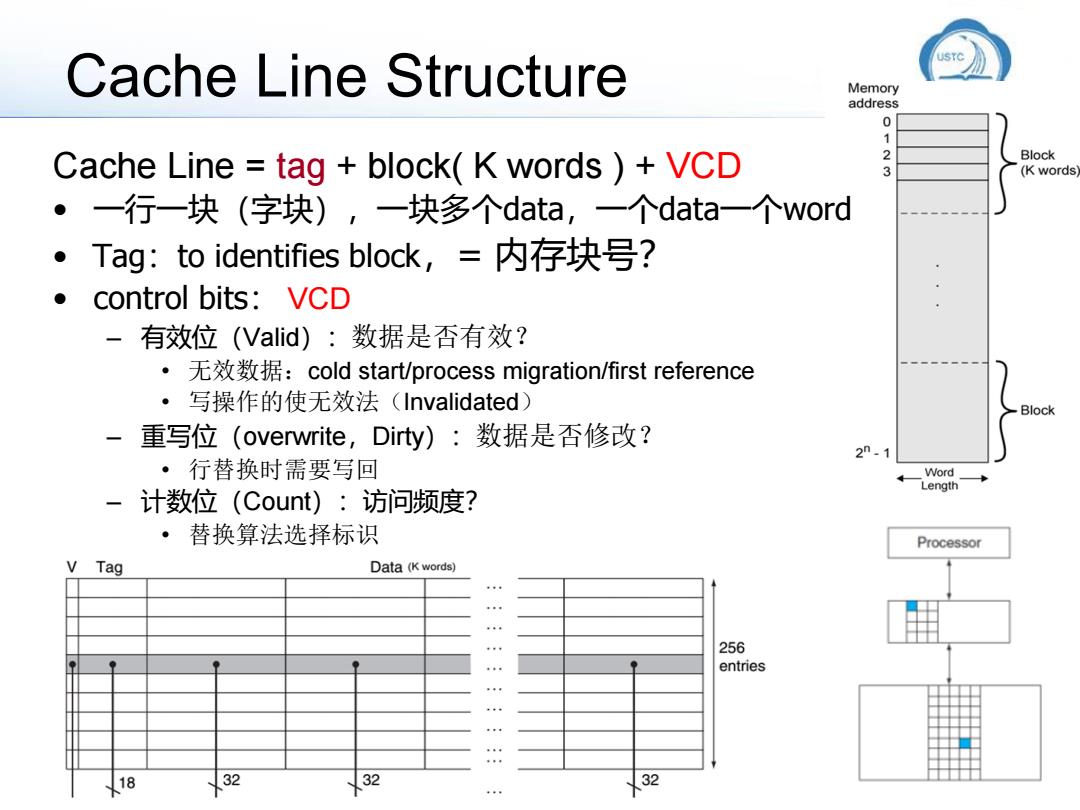
Cache Line Structure Cache Line = tag + block( K words ) + VCD • 一行一块(字块),一块多个data,一个data一个word • Tag:to identifies block,= 内存块号? • control bits: VCD – 有效位(Valid):数据是否有效? • 无效数据:cold start/process migration/first reference • 写操作的使无效法(Invalidated) – 重写位(overwrite,Dirty):数据是否修改? • 行替换时需要写回 – 计数位(Count):访问频度? • 替换算法选择标识
Cache读访问过程,$5.3.2 se》 开始 唐本:一般的读流程 CPU发出访存地址 并行 Registers Words Blocks N 命中? Cache Cache满? Processor Main Memory N Fetch I-Cache 访问Cache.取 访问MEM取出 将新的MEM块 执行替换算 Decode Memory 出信息送CPU 信息送CPU 调入Cache中 法腾出空位 Execute Memory D-Cache Write-back 结束 两个Cache同时miss? 并行:CPU主控制器+Cache:控制器 I$miss -阻塞式:CPU stall,等待读操作完成,重新取指 ·换入换出? D$miss:与引$类似,dirty时换出需要写MEM -阻塞非阻塞式(OOO)
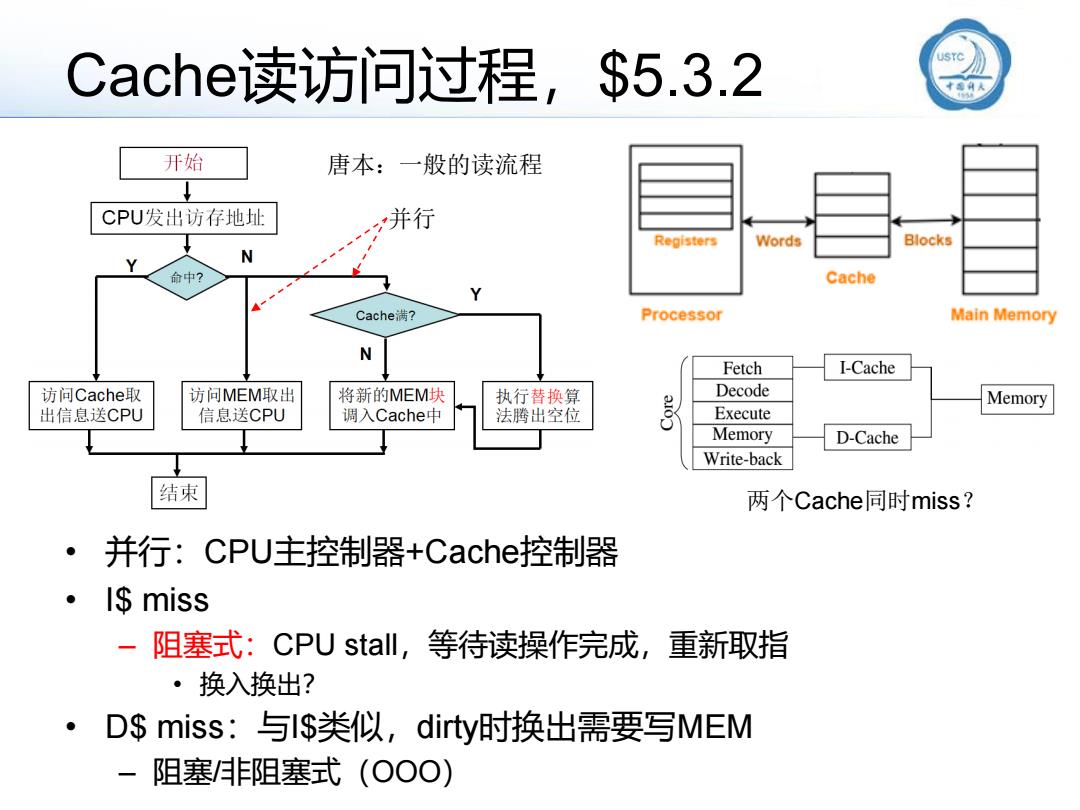
Cache读访问过程,$5.3.2 • 并行:CPU主控制器+Cache控制器 • I$ miss – 阻塞式:CPU stall,等待读操作完成,重新取指 • 换入换出? • D$ miss:与I$类似,dirty时换出需要写MEM – 阻塞/非阻塞式(OOO) 唐本:一般的读流程 两个Cache同时miss? 并行

write policy,$5.3.3 USTC Processor 命中 写透(Write-through/Store-through,写直达/"写穿透”) 同时写入Cache和MEM 写MEMe200cc:写缓冲(write buf,store buf)。满,阻塞 写▣(Write-back,"写返回”) 只写Cache,置Dirty(不一致),替换时再整行写回MEM(写回缓冲) 不命中 写分配(write allocate):从mem读入Cache)后再写 也称fetch on write,MIPS采用。 .CPU 写不分配no write allocate,write around):只写mem .cache 通常用于写操作较少或随机写 a 550 写透两者都可以,写回只用写分配 b 200 写无效法(Invalidated),多处理器cache写 .memory 只写主存,同时将各处理器的Cache.相应块Valid位置0 a .100 数据值与主存一致? b 200 写操作性能?
write policy,$5.3.3 • 命中 – 写透(Write-through/Store-through,写直达/“写穿透”) • 同时写入Cache和MEM • 写MEM≈200cc:写缓冲(write buf,store buf)。满,阻塞 – 写回(Write-back,“写返回”) • 只写Cache,置Dirty(不一致),替换时再整行写回MEM(写回缓冲) • 不命中 – 写分配(write allocate):从mem读入Cache后再写 • 也称fetch on write,MIPS采用。 – 写不分配(no write allocate,write around):只写mem • 通常用于写操作较少或随机写 – 写透两者都可以,写回只用写分配 • 写无效法(Invalidated):多处理器cache写 – 只写主存,同时将各处理器的Cache相应块Valid位置0 • 数据值与主存一致? • 写操作性能?
Cache与主存的不一致问题:$5.3.3 USTC .CPU .CPU .CPU 主机 processor memory .cache .cache cache a 100 a 550 a 100 l/○Interface I/O Interface .b' 200 b …200 b 200 (adapter) (adapter) *memory .memory .memory l/O device l/O device a 100 a 100 a 100 两种inconsistent场景: 1.CPU写操作 b •200 b 200 b 440 2.DMA写操作:HP“I/O一致性” 方法1:置valid位; 方法2:simple flush the cache before DMA write +1/O +/O +1/O ·CPU writes to a ·1O writes b
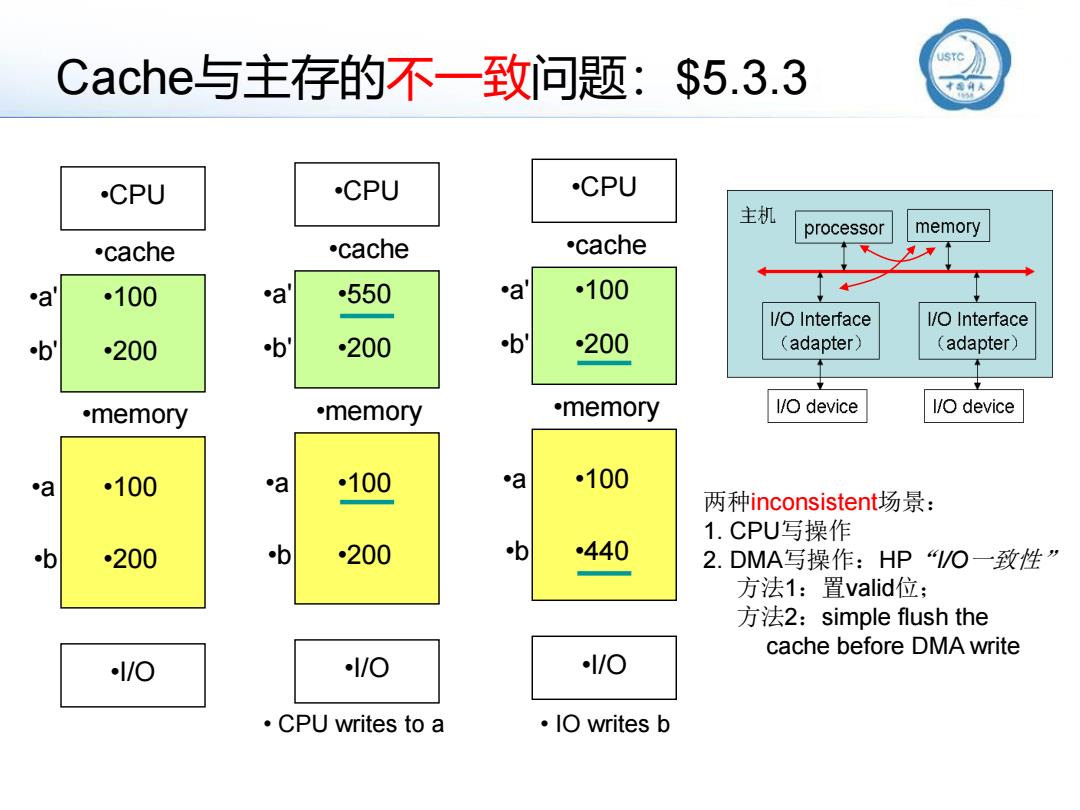
Cache与主存的不一致问题:$5.3.3 •CPU •I/O •a' •b' •b •a •cache •memory •100 •100 •200 •200 •CPU •I/O •a' •b' •b •a •cache •memory •550 •100 •200 •200 •CPU •I/O •a' •b' •b •a •cache •memory •100 •100 •440 •200 • CPU writes to a • IO writes b 两种inconsistent场景: 1. CPU写操作 2. DMA写操作:HP“I/O一致性” 方法1:置valid位; 方法2:simple flush the cache before DMA write
加速"写”操作:$5.3.3【精解】,$5.8.④ 结构:Store buf(=Write buf?.支持store-load旁路),Write-back buf 写回:不能直接写Cache,可流水化 命中: · CC1(=ppl的ME周期):sw写store buf,.指令完成。Cache控制器判断是否命中。 ·CC2(unused周期):写入D$,由Cache控制器完成。 miss:如需替换,则写回脏块->读入所需内存块(写分配)->cpu写 write-back buf:存放待写入mem的脏块,尽快开始读入内存块 写透:可直接写Cache,一个CC完成 write buf($5.8.4):按字访问 Store-to-load forwarding EX ME WB w L1 misses 1-$ Main Parallel SW D-$ Computer memory Organization and Design Store buffer write-back buffer write buffer 参考《Parallel Computer Organization and Design》Fig4.8、Fig7.3,Ixx重绘
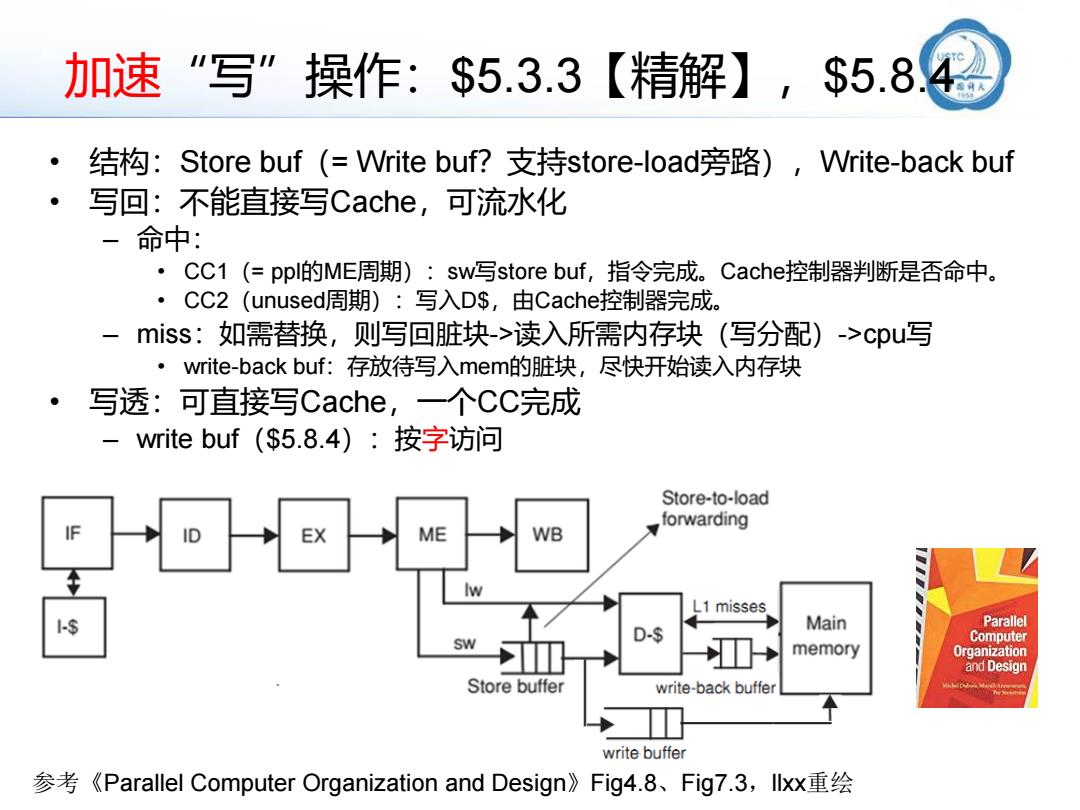
加速“写”操作:$5.3.3【精解】,$5.8.4 • 结构:Store buf(= Write buf?支持store-load旁路),Write-back buf • 写回:不能直接写Cache,可流水化 – 命中: • CC1(= ppl的ME周期):sw写store buf,指令完成。Cache控制器判断是否命中。 • CC2(unused周期):写入D$,由Cache控制器完成。 – miss:如需替换,则写回脏块->读入所需内存块(写分配)->cpu写 • write-back buf:存放待写入mem的脏块,尽快开始读入内存块 • 写透:可直接写Cache,一个CC完成 – write buf($5.8.4):按字访问 参考《Parallel Computer Organization and Design》Fig4.8、Fig7.3,llxx重绘