
第12卷第3期 智能系统学报 Vol.12 No.3 2017年6月 CAAI Transactions on Intelligent Systems Jun.2017 D0I:10.11992/is.201705004 网络出版地址:http:/kns.cmki.net/kcms/detail/23.1538.TP.20170703.1854.018.html 基于粗糙集相对分类信息熵和 粒子群优化的特征选择方法 翟俊海12,刘博3,张素芳4 (1.河北大学河北省机器学习与计算智能重点实验室,河北保定071002:2.浙江师范大学数理与信息工程学院,浙 江金华321004:3.河北大学计算机科学与技术学院,河北保定071002:4.中国气象局气象干部培训学院河北分 院,河北保定071000) 摘要:特征选择是指从初始特征全集中,依据既定规则筛选出特征子集的过程,是数据挖掘的重要预处理步骤。 通过剔除冗余属性,以达到降低算法复杂度和提高算法性能的目的。针对离散值特征选择问题,提出了一种将粗糙 集相对分类信息嫡和粒子群算法相结合的特征选择方法,依托粒子群算法,以相对分类信息嫡作为适应度函数,并 与其他基于进化算法的特征选择方法进行了实验比较,实验结果表明本文提出的方法具有一定的优势。 关键词:数据挖掘:特征选择:数据预处理:粗糙集:决策表:粒子群算法:信息嫡:适应度函数 中图分类号:TP181文献标志码:A文章编号:1673-4785(2017)03-0397-08 中文引用格式:翟俊海,刘博,张素芳.基于粗糙集相对分类信息熵和粒子群优化的特征选择方法[J].智能系统学报,2017,12(3): 397-404. 英文引用格式:ZHAI Junhai,LIU Bo,ZHANG Sufang.A feature selection approach based on rough set relative classification information entropy and particle swarm optimization[.CAAI transactions on intelligent systems,2017,12(3):397-404. A feature selection approach based on rough set relative classification information entropy and particle swarm optimization ZHAI Junhai2,LIU Bo3,ZHANG Sufang" (1.Key Lab of Machine Learning and Computational Intelligence,Hebei University,Baoding 071002,China;2.College of Mathematics,Physics and Information Engineering,Zhejiang Normal University,Jinhua 321004,China;3.College of Computer Science and Technology,Hebei University,Baoding 071002,China;4.Hebei Branch of Meteorological Cadres Training Institute, China Meteorological Administration,Baoding 071000,China) Abstract:Feature selection,an important step in data mining,is a process that selects a subset from an original feature set based on some criteria.Its purpose is to reduce the computational complexity of the learning algorithm and to improve the performance of data mining by removing irrelevant and redundant features.To deal with the problem of discrete values,a feature selection approach was proposed in this paper.It uses a particle swarm optimization algorithm to search the optimal feature subset.Further,it employs relative classification information entropy as a fitness function to measure the significance of the feature subset.Then,the proposed approach was compared with other evolutionary algorithm-based methods of feature selection.The experimental results confirm that the proposed approach outperforms genetic algorithm-based methods. Keywords:data mining;feature selection;data preprocessing;rough set;decision table;particle swarm optimization;information entropy;fitness function 特征选择1-]是数据挖掘的重要预处理步骤, 集的评价准则或启发式确定后,特征选择问题从某 通过删除不必要特征,以达到降低算法复杂度,提 种意义上来说就是在特征空间中搜索最优特征子 高算法的性能。特征子集的评价至关重要,特征子 集问题。研究人员提出了许多特征选择算法,这些 算法有的是从设计特征子集搜索的方法考虑的,有 收稿日期:2017-05-07.网络出版日期:2017-07-03. 基金项目:国家自然科学基金项目(71371063):河北省自然科学基金的是从设计评价特征子集重要性的度量考虑的。 项目(F2017201026):浙江省计算机科学与技术重中之重学 科(浙江师范大学)资助项目. 特征选择方法主要有筛选法(6 ilter method)、封 通信作者:翟俊海.E-mail:mcjh@126.com
第 12 卷第 3 期 智 能 系 统 学 报 Vol.12 №.3 2017 年 6 月 CAAI Transactions on Intelligent Systems Jun. 2017 DOI:10.11992 / tis. 201705004 网络出版地址:http: / / kns.cnki.net / kcms/ detail / 23.1538.TP.20170703.1854.018.html 基于粗糙集相对分类信息熵和 粒子群优化的特征选择方法 翟俊海1, 2 , 刘博3 , 张素芳4 (1.河北大学 河北省机器学习与计算智能重点实验室,河北 保定 071002; 2. 浙江师范大学 数理与信息工程学院,浙 江 金华 321004; 3. 河北大学 计算机科学与技术学院,河北 保定 071002; 4. 中国气象局 气象干部培训学院河北分 院,河北 保定 071000) 摘 要:特征选择是指从初始特征全集中,依据既定规则筛选出特征子集的过程,是数据挖掘的重要预处理步骤。 通过剔除冗余属性,以达到降低算法复杂度和提高算法性能的目的。 针对离散值特征选择问题,提出了一种将粗糙 集相对分类信息熵和粒子群算法相结合的特征选择方法,依托粒子群算法,以相对分类信息熵作为适应度函数,并 与其他基于进化算法的特征选择方法进行了实验比较,实验结果表明本文提出的方法具有一定的优势。 关键词:数据挖掘;特征选择;数据预处理;粗糙集;决策表;粒子群算法;信息熵;适应度函数 中图分类号:TP181 文献标志码:A 文章编号:1673-4785(2017)03-0397-08 中文引用格式:翟俊海,刘博,张素芳.基于粗糙集相对分类信息熵和粒子群优化的特征选择方法[J]. 智能系统学报, 2017, 12(3): 397-404. 英文引用格式:ZHAI Junhai,LIU Bo,ZHANG Sufang. A feature selection approach based on rough set relative classification information entropy and particle swarm optimization[J]. CAAI transactions on intelligent systems, 2017, 12(3): 397-404. A feature selection approach based on rough set relative classification information entropy and particle swarm optimization ZHAI Junhai 1,2 , LIU Bo 3 , ZHANG Sufang 4 (1. Key Lab of Machine Learning and Computational Intelligence, Hebei University, Baoding 071002, China; 2. College of Mathematics, Physics and Information Engineering, Zhejiang Normal University, Jinhua 321004, China; 3. College of Computer Science and Technology, Hebei University, Baoding 071002, China; 4. Hebei Branch of Meteorological Cadres Training Institute, China Meteorological Administration, Baoding 071000, China) Abstract:Feature selection, an important step in data mining, is a process that selects a subset from an original feature set based on some criteria. Its purpose is to reduce the computational complexity of the learning algorithm and to improve the performance of data mining by removing irrelevant and redundant features. To deal with the problem of discrete values, a feature selection approach was proposed in this paper. It uses a particle swarm optimization algorithm to search the optimal feature subset. Further, it employs relative classification information entropy as a fitness function to measure the significance of the feature subset. Then, the proposed approach was compared with other evolutionary algorithm⁃based methods of feature selection. The experimental results confirm that the proposed approach outperforms genetic algorithm⁃based methods. Keywords: data mining; feature selection; data preprocessing; rough set; decision table; particle swarm optimization; information entropy; fitness function 收稿日期:2017-05-07. 网络出版日期:2017-07-03. 基金项目:国家自然科学基金项目(71371063); 河北省自然科学基金 项目(F2017201026); 浙江省计算机科学与技术重中之重学 科(浙江师范大学)资助项目. 通信作者:翟俊海. E⁃mail: mczjh@ 126.com. 特征选择[1-2] 是数据挖掘的重要预处理步骤, 通过删除不必要特征,以达到降低算法复杂度,提 高算法的性能。 特征子集的评价至关重要,特征子 集的评价准则或启发式确定后,特征选择问题从某 种意义上来说就是在特征空间中搜索最优特征子 集问题。 研究人员提出了许多特征选择算法,这些 算法有的是从设计特征子集搜索的方法考虑的,有 的是从设计评价特征子集重要性的度量考虑的。 特征选择方法主要有筛选法(filter method )、封

·398 智能系统学报 第12卷 装法(wrapper method)和嵌人法(embedded 算法的第一部专著Swarm Intelligence2)出版后,粒 method)3种分类。筛选法独立于学习算法,它依据 子群算法才得到广泛应用。为解决PS0算法在连 启发式(如依赖度、互信息、不一致性等)搜索整体 续空间中的局限性,Kennedy等]提出了离散二进 最优解。因为这类特征选择算法独立于数据挖掘 制PS0算法。在此基础上,Chuang等列提出了一 算法,所以通用性好,适应各种数据挖掘任务,研究 种改进的二进制粒子群算法(IBPSO),有效简化了 也最为广泛。实际上,粗糙集领域中的属性约简方 特征选择,并在医疗诊断基因表达领域取得了较好 法就是这类方法的一种典型代表[3-)。Swiniarski 的效果:Chuang等f3o基于Catfish机制,提出了一种 等)针对模式识别问题,系统地研究了特征选择的 二进制粒子群特征选择算法,可避免过早收敛的问 粗糙集方法;Jensen等[6)提出了基于模糊粗糙集的 题;Wang等[3]提出了一种基于粗糙集的粒子群算 方法,但是它在某些情况下不收敛:Bhatt等]针对 法,具有较强的搜索能力能更快地寻找到最优解; 文献[6]中的问题,深人研究模糊粗糙集特征选择 Cervante等]提出了基于信息嫡的BPSO方法,测 算法的收敛性,得出了非常有价值的结论:Jensen 试结果非常理想。Liu等〔)提出了一种集成邻域信 等[]研究了模糊粗糙集特征选择算法的可扩展性 息和粒子群算法的特征选择方法,结合粒子加权提 问题,并提出了相应的方法:钱宇华等)提出了基 高了算法的稳定性;Fog等面向高维和数据流 于粗糙集正域逼近的属性约简(或特征选择)加速 格式的大数据,提出了一种基于粒子群算法的特征 方法,该方法具有很高的计算效率,受到了广泛关 选择方法,提高测试精度的同时降低了处理 注:胡清华等[]在邻域粗糙集框架下研究了异构特 时间3)。 征选择问题,提出的特征选择算法可以处理实数值 本文选择相对分类信息熵作为适应度函数,用 异构特征选择问题。 粒子群算法搜索最优特征子集,并与其他进化算法 除了基于粗糙集知识的算法,其他特征选择问 进行了实验比较,实验结果表明本文所提的方法更 题代表性的工作还包括基于一致性的方法[2,1-2] 为有效。 基于互信息的方法[-]及基于依赖度的方 1 法等[16-7]。 基础知识 封装法以算法性能为标准衡量特征子集,由 1.1粒子群算法 Kohavi等于1997年提出[18]。多年来,一些专家学 粒子群算法是一种群体搜索行为。群体由若 者沿着封装法的思路做出了大量研究:Sindhwani等 千个粒子p:组成,P:包含位置信息x和速度信息 将多层感知器和SVM相结合,提出了基于最大输出 。位置信息x表示P:在第k次迭代时其位置信 信息的特征选择算法[19]:Yang等提出了一种随机 息,速度信息表示P:在第k次迭代时移动的速度 扰动特征选择方法,具有较好表示能力[20。封装法 和方向。从一组初始粒子(初始种群)出发,通过一 过于依赖学习算法,对于全部筛选出的特征子集, 次次迭代,不断更新速度和位置信息,每个粒子不 必须重复分类器训练的过程,虽然最终得到的特征 断向gbest和pbest靠近,最终找到整体最优解。方 子集比较理想,但复杂度太高,代价过大。 法过程如图1所示,具体步骤见第2节。 在嵌入法中,特征选择与分类器的构造同步完 粒子群算法应用的关键是问题编码和粒子适 成。实际上,著名的D3算法[2和CART算法[ 应度评价标准。在问题编码上,显然二进制编码是 都可以看作嵌入式特征选择方法。基于神经网络 最为合适的。在粒子适应度评价标准上,一个合适 剪枝思想,Setiono等[2]提出了一种特征选择算法。 的适应度函数对特征子集的选择影响很大,因此适 该算法通过计算删除某个特征(剪枝)对神经网络 应度函数的设计是尤为关键的。 性能的影响来选择特征。在此基础上,Shen等提出 1.2粗糙集 了基于SVM的敏感度特征选择算法2]。而后, 定义1设DT=(U,AUD,V,f月为知识涉及的 Perkins等提出了Grafting嵌人式特征选择算法[2]。 决策表。其中,U={x1,x2,…,xn}为论域;A={a1, 粒子群算法由Kennedy提出[2],逐渐被专家学 a2,…,am}是描述对象的属性集合:D={d,即目标 者广泛接受和应用。但是直到2001年关于粒子群 概念唯一;V为属性值域;f:U×A→V为信息函数
装 法 ( wrapper method ) 和 嵌 入 法 ( embedded method)3 种分类。 筛选法独立于学习算法,它依据 启发式(如依赖度、互信息、不一致性等) 搜索整体 最优解。 因为这类特征选择算法独立于数据挖掘 算法,所以通用性好,适应各种数据挖掘任务,研究 也最为广泛。 实际上,粗糙集领域中的属性约简方 法就是这类方法的一种典型代表[3-4] 。 Swiniarski 等[5]针对模式识别问题,系统地研究了特征选择的 粗糙集方法;Jensen 等[6] 提出了基于模糊粗糙集的 方法,但是它在某些情况下不收敛;Bhatt 等[7] 针对 文献[6]中的问题,深入研究模糊粗糙集特征选择 算法的收敛性,得出了非常有价值的结论;Jensen 等[8]研究了模糊粗糙集特征选择算法的可扩展性 问题,并提出了相应的方法;钱宇华等[9] 提出了基 于粗糙集正域逼近的属性约简(或特征选择) 加速 方法,该方法具有很高的计算效率,受到了广泛关 注;胡清华等[10]在邻域粗糙集框架下研究了异构特 征选择问题,提出的特征选择算法可以处理实数值 异构特征选择问题。 除了基于粗糙集知识的算法,其他特征选择问 题代表性的工作还包括基于一致性的方法[2,11-12] 、 基于 互 信 息 的 方 法[13-15] 及 基 于 依 赖 度 的 方 法等[16-17] 。 封装法以算法性能为标准衡量特征子集,由 Kohavi 等于 1997 年提出[18] 。 多年来,一些专家学 者沿着封装法的思路做出了大量研究;Sindhwani 等 将多层感知器和 SVM 相结合,提出了基于最大输出 信息的特征选择算法[19] ;Yang 等提出了一种随机 扰动特征选择方法,具有较好表示能力[20] 。 封装法 过于依赖学习算法,对于全部筛选出的特征子集, 必须重复分类器训练的过程,虽然最终得到的特征 子集比较理想,但复杂度太高,代价过大。 在嵌入法中,特征选择与分类器的构造同步完 成。 实际上,著名的 ID3 算法[21] 和 CART 算法[22] 都可以看作嵌入式特征选择方法。 基于神经网络 剪枝思想,Setiono 等[23] 提出了一种特征选择算法。 该算法通过计算删除某个特征(剪枝)对神经网络 性能的影响来选择特征。 在此基础上,Shen 等提出 了基于 SVM 的敏感度特征选择算法[24] 。 而后, Perkins 等提出了 Grafting 嵌入式特征选择算法[25] 。 粒子群算法由 Kennedy 提出[26] ,逐渐被专家学 者广泛接受和应用。 但是直到 2001 年关于粒子群 算法的第一部专著 Swarm Intelligence [27] 出版后,粒 子群算法才得到广泛应用。 为解决 PSO 算法在连 续空间中的局限性,Kennedy 等[28] 提出了离散二进 制 PSO 算法。 在此基础上,Chuang 等[29] 提出了一 种改进的二进制粒子群算法( IBPSO),有效简化了 特征选择,并在医疗诊断基因表达领域取得了较好 的效果;Chuang 等[30]基于 Catfish 机制,提出了一种 二进制粒子群特征选择算法,可避免过早收敛的问 题;Wang 等[31] 提出了一种基于粗糙集的粒子群算 法,具有较强的搜索能力能更快地寻找到最优解; Cervante 等[32]提出了基于信息熵的 BPSO 方法,测 试结果非常理想。 Liu 等[33]提出了一种集成邻域信 息和粒子群算法的特征选择方法,结合粒子加权提 高了算法的稳定性;Fong 等[34] 面向高维和数据流 格式的大数据,提出了一种基于粒子群算法的特征 选择 方 法, 提 高 测 试 精 度 的 同 时 降 低 了 处 理 时间[34] 。 本文选择相对分类信息熵作为适应度函数,用 粒子群算法搜索最优特征子集,并与其他进化算法 进行了实验比较,实验结果表明本文所提的方法更 为有效。 1 基础知识 1.1 粒子群算法 粒子群算法是一种群体搜索行为。 群体由若 干个粒子 pi 组成,pi 包含位置信息 x k i 和速度信息 v k i 。 位置信息 x k i 表示 pi 在第 k 次迭代时其位置信 息,速度信息 v k i 表示 pi 在第 k 次迭代时移动的速度 和方向。 从一组初始粒子(初始种群)出发,通过一 次次迭代,不断更新速度和位置信息,每个粒子不 断向 gbest 和 pbest 靠近,最终找到整体最优解。 方 法过程如图 1 所示,具体步骤见第 2 节。 粒子群算法应用的关键是问题编码和粒子适 应度评价标准。 在问题编码上,显然二进制编码是 最为合适的。 在粒子适应度评价标准上,一个合适 的适应度函数对特征子集的选择影响很大,因此适 应度函数的设计是尤为关键的。 1.2 粗糙集 定义 1 设 DT = (U,A∪D,V,f)为知识涉及的 决策表。 其中,U = { x1 ,x2 ,…,xn } 为论域;A = { a1 , a2 ,…,am }是描述对象的属性集合;D = {d},即目标 概念唯一;V 为属性值域; f:U×A→V 为信息函数。 ·398· 智 能 系 统 学 报 第 12 卷

第3期 翟俊海,等:基于粗糙集相对分类信息嫡和粒子群优化的特征选择方法 ·399. 开始 定理1给定决策表DT=(U,AUD,V,f),假 初始化粒子群 设A1,ACA且ACA2,则H(U/A2)≤H(U/A)。 定理1保证了本文提出的方法的收敛性,即能 计算每个粒子的适应度值 够以很高概率找到整体最优解。 更新pbest、gbest粒子位置和速度 算法1基于粒子群算法的特征选择算法。 输入离散值决策表DT=(U,AUD,V,f),群 是否满足 结束条件 体大小N、惯性系数W、常量系数c,和c,、数据集维 数D。 Y 输出结果○ 输出A'二A。 1)随机初始化大小为N的种群: 图1PS0算法流程图 Fig.I The flowchart of particle swarm optimization 2)repeat; algorithm 3)for(i=1;isN;i=i+1); 定义2对于任意条件属性子集BCA,B的等 4)用式(6)计算种群中每一个个体的适应 价关系为 度值; IND(B)={(x,y)∈U×UVb∈B, 5)更新历史最佳位置best: b(x)=b(y)} (1)》 6)end for; 式中b(x)和b(y)分别是对象x和y在属性b上的 7)更新全局最佳位置gbest; 属性值。 8)for(i=1;isN;i=i+1); 定义3令XCU,BCA,X关于B的下近似为 9)for(d=1;dsD;d=d+1); BX=x[x] (2)》 10)更新速度信息a 定义4令XCU,BCA,X关于B的上近似为 11)更新位置信息xa; 12)end for; BX={xl[x]B∩X≠} (3) 定义5令X二U,BCA,X关于B的边界域为 13)end for; 14)until(满足终止条件时); BN(X)=BX-BX (4) 15)输出A'。 2基于粗糙集相对分类信息熵的粒子 本文选择适用于离散值特征选择的二进制粒 群特征选择方法 子群算法,问题的解可用d维0-1向量表示,其中d 是属性个数。向量的第i个分量为0或1表示属性 首先定义适用于特征选择问题的适应度函数。 是否被选择。特征选择的过程分为以下几步。 对于形如DT=(U,AUD,V,f)的决策表,BC 1)随机产生N。个0-1向量(粒子)作为初始粒 A,B和D对U的划分表示为 子群,其中N。是种群的大小。 U/B=X,+X2+…+Xm 2)利用式(6)计算所有粒子的适应度值。 U/D=Y,+Y2+…+Yk 3)更新粒子历史最优点pbest:将所有粒子的适应 定义6划分U/B相对于U/D的概率分布为 度值和其历史最佳点pbest做比对,择优更新pbest。 x n y P三X (5) 4)更新全局最最优点gbest:将所有粒子的适应 定义7划分U/B相对于U/D的相对分类信 度值和全局最优点gbest做比对,择优更新gbest。 息熵为 5)根据上一步更新得到的pbest和gbest,更新 粒子的速度和位置。其中速度是根据上一步得到 H(UWB)=-X TUPylogaPy (6) 的pbest和gbest按照公式(7)进行更新: 相对分类信息嫡反映的不一致程度与其值成 =wv c rand(pbest -x)+ 正比,因此值越小效果越好。本文所选择的适应度 czrand(gbest -x) (7) 函数,即(6)式定义的相对分类信息熵,可通过定理 这里需要注意的是,P:的位置信息x中的每个 1的证明来验证其合理性3]。 x只能取0或1,相应的速度信息也发生了改变,用
图 1 PSO 算法流程图 Fig. 1 The flowchart of particle swarm optimization algorithm 定义 2 对于任意条件属性子集 B⊆A,B 的等 价关系为 IND(B) = {(x,y) ∈ U × U ∀b ∈ B, b(x) = b(y)} (1) 式中 b(x)和 b(y)分别是对象 x 和 y 在属性 b 上的 属性值。 定义 3 令 X⊆U,B⊆A,X 关于 B 的下近似为 BX = {x [x] B ⊆ X} (2) 定义 4 令 X⊆U,B⊆A,X 关于 B 的上近似为 BX = {x [x] B ∩ X ≠ ⌀} (3) 定义 5 令 X⊆U,B⊆A,X 关于 B 的边界域为 BN(X) = BX - BX (4) 2 基于粗糙集相对分类信息熵的粒子 群特征选择方法 首先定义适用于特征选择问题的适应度函数。 对于形如 DT = (U,A∪D,V, f )的决策表,B⊆ A,B 和 D 对 U 的划分表示为 U/ B = X1 + X2 + … + Xm U/ D = Y1 + Y2 + … + Yk 定义 6 划分 U/ B 相对于 U/ D 的概率分布为 pij = Xi ∩ Yj Xi (5) 定义 7 划分 U/ B 相对于 U/ D 的相对分类信 息熵为 H(U/ B) = - ∑ m i = 1 ∑ k j = 1 Xi U pij log2 pij (6) 相对分类信息熵反映的不一致程度与其值成 正比,因此值越小效果越好。 本文所选择的适应度 函数,即(6)式定义的相对分类信息熵,可通过定理 1 的证明来验证其合理性[35] 。 定理 1 给定决策表 DT = (U,A∪D,V, f ) ,假 设 A1 ,A2⊆A 且 A1⊆A2 ,则 H(U/ A2 )≤H(U/ A1 )。 定理 1 保证了本文提出的方法的收敛性,即能 够以很高概率找到整体最优解。 算法 1 基于粒子群算法的特征选择算法。 输入 离散值决策表 DT = (U,A∪D,V,f ),群 体大小 N、惯性系数 w、常量系数 c1 和 c2 、数据集维 数 D。 输出 A′⊆A。 1)随机初始化大小为 N 的种群; 2)repeat; 3)for(i = 1;i≤N;i = i+1) ; 4) 用式 ( 6) 计算种群中每一个个体的适应 度值; 5)更新历史最佳位置 best; 6)end for; 7)更新全局最佳位置 gbest; 8)for(i = 1;i≤N;i = i+1) ; 9)for(d = 1;d≤D;d = d+1); 10)更新速度信息 vid ; 11)更新位置信息 xid ; 12)end for; 13)end for; 14)until(满足终止条件时); 15)输出 A′。 本文选择适用于离散值特征选择的二进制粒 子群算法,问题的解可用 d 维 0-1 向量表示,其中 d 是属性个数。 向量的第 i 个分量为 0 或 1 表示属性 是否被选择。 特征选择的过程分为以下几步。 1)随机产生 N0 个 0-1 向量(粒子)作为初始粒 子群,其中 N0 是种群的大小。 2)利用式(6)计算所有粒子的适应度值。 3)更新粒子历史最优点 pbest:将所有粒子的适应 度值和其历史最佳点 pbest 做比对,择优更新 pbest。 4)更新全局最最优点 gbest:将所有粒子的适应 度值和全局最优点 gbest 做比对,择优更新 gbest。 5)根据上一步更新得到的 pbest 和 gbest,更新 粒子的速度和位置。 其中速度是根据上一步得到 的 pbest 和 gbest 按照公式(7)进行更新: v k+1 i = wv k i + c1 rand(pbest - x k i ) + c2 rand(gbest - x k i ) (7) 这里需要注意的是,pi 的位置信息 x k i 中的每个 x k id只能取 0 或 1,相应的速度信息也发生了改变,用 第 3 期 翟俊海,等:基于粗糙集相对分类信息熵和粒子群优化的特征选择方法 ·399·
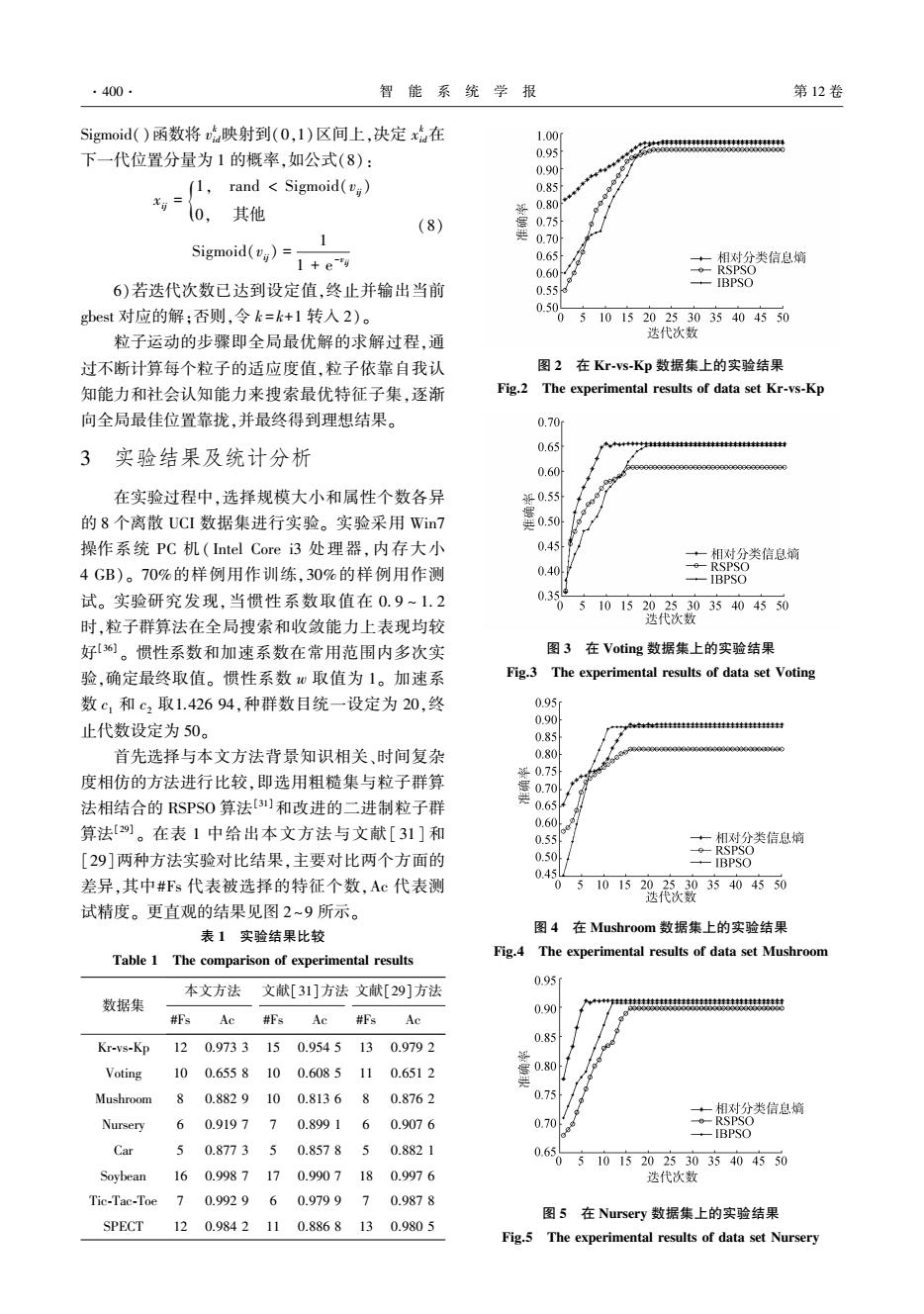
·400 智能系统学报 第12卷 Sigmoid()函数将v映射到(0,1)区间上,决定x在 1.00 5 下一代位置分量为1的概率,如公式(8): 0.95 0.90 (1,rand Sigmoid(v;) 0.85 0,其他 解0.80 (8) 0.75 Sigmoid()=1 要0.70 1+e-y 0.65 +相对分类信息嫡 0.60 RSPSO 6)若迭代次数已达到设定值,终止并输出当前 IBPSO 0.55& gbest对应的解:否则,令k=k+1转入2)。 0.5 05101520253035404550 粒子运动的步骤即全局最优解的求解过程,通 迭代次数 过不断计算每个粒子的适应度值,粒子依靠自我认 图2在Kr-vs-Kp数据集上的实验结果 知能力和社会认知能力来搜索最优特征子集,逐渐 Fig.2 The experimental results of data set Kr-vs-Kp 向全局最佳位置靠拢,并最终得到理想结果。 0.70 0.65 *+4+4H4# 3实验结果及统计分析 0.60 在实验过程中,选择规模大小和属性个数各异 部0.55 的8个离散UCI数据集进行实验。实验采用Win7 操作系统PC机(Intel Core i3处理器,内存大小 0.45 ·相对分类信息镝 4GB)。70%的样例用作训练,30%的样例用作测 0.40 -e-RSPSO IBPSO 试。实验研究发现,当惯性系数取值在0.9~1.2 035 5 101520253035404550 时,粒子群算法在全局搜索和收敛能力上表现均较 迭代次数 好。惯性系数和加速系数在常用范围内多次实 图3在Voting数据集上的实验结果 验,确定最终取值。惯性系数心取值为1。加速系 Fig.3 The experimental results of data set Voting 数c1和c2取1.42694,种群数目统一设定为20,终 0.95m 0.90 止代数设定为50。 0.85 首先选择与本文方法背景知识相关、时间复杂 0.80 0.75 度相仿的方法进行比较,即选用粗糙集与粒子群算 0.70 法相结合的RSPS0算法[3)]和改进的二进制粒子群 0.654 0.60 算法[9。在表1中给出本文方法与文献[31]和 0.55 +一相对分类信息嫡 0.50 RSPSO [29]两种方法实验对比结果,主要对比两个方面的 -IBPSO 0.4 差异,其中#Fs代表被选择的特征个数,Ac代表测 0510152025.3035404550 迭代次数 试精度。更直观的结果见图2~9所示。 表1实验结果比较 图4在Mushroom数据集上的实验结果 Table 1 The comparison of experimental results Fig.4 The experimental results of data set Mushroom 0.95r 本文方法文献[31]方法文献[29]方法 数据集 0.90 思 #Fs Ac #Fs Ac #Fs Ac 0.85 Kr-vs-Kp 120.9733150.9545130.9792 Voting 100.6558100.6085110.6512 0.80 舞 Mushroom 8 0.8829100.81368 0.8762 0.75 一相对分类信息嫡 Nursery 60.919770.899160.9076 0.70 RSPSO ·-IBPSO Car 50.877350.85785 0.8821 0.6505101520253035404550 Soybean 160.9987170.9907180.9976 迭代次数 Tic-Tac-Toe70.992960.97997 0.9878 图5在Nursery数据集上的实验结果 SPECT120.984211 0.8868130.9805 Fig.5 The experimental results of data set Nursery
Sigmoid()函数将 v k id映射到(0,1)区间上,决定 x k id在 下一代位置分量为 1 的概率,如公式(8): xij = 1, rand < Sigmoid(vij) {0, 其他 Sigmoid(vij) = 1 1 + e -vij (8) 6)若迭代次数已达到设定值,终止并输出当前 gbest 对应的解;否则,令 k = k+1 转入 2)。 粒子运动的步骤即全局最优解的求解过程,通 过不断计算每个粒子的适应度值,粒子依靠自我认 知能力和社会认知能力来搜索最优特征子集,逐渐 向全局最佳位置靠拢,并最终得到理想结果。 3 实验结果及统计分析 在实验过程中,选择规模大小和属性个数各异 的 8 个离散 UCI 数据集进行实验。 实验采用 Win7 操作系统 PC 机( Intel Core i3 处理器,内存大小 4 GB)。 70%的样例用作训练,30%的样例用作测 试。 实验研究发现,当惯性系数取值在 0 9 ~ 1 2 时,粒子群算法在全局搜索和收敛能力上表现均较 好[36] 。 惯性系数和加速系数在常用范围内多次实 验,确定最终取值。 惯性系数 w 取值为 1。 加速系 数 c1 和 c2 取1.426 94,种群数目统一设定为 20,终 止代数设定为 50。 首先选择与本文方法背景知识相关、时间复杂 度相仿的方法进行比较,即选用粗糙集与粒子群算 法相结合的 RSPSO 算法[31]和改进的二进制粒子群 算法[29] 。 在表 1 中给出本文方法与文献[ 31] 和 [29]两种方法实验对比结果,主要对比两个方面的 差异,其中#Fs 代表被选择的特征个数,Ac 代表测 试精度。 更直观的结果见图 2~9 所示。 表 1 实验结果比较 Table 1 The comparison of experimental results 数据集 本文方法 文献[31]方法 文献[29]方法 #Fs Ac #Fs Ac #Fs Ac Kr⁃vs⁃Kp 12 0.973 3 15 0.954 5 13 0.979 2 Voting 10 0.655 8 10 0.608 5 11 0.651 2 Mushroom 8 0.882 9 10 0.813 6 8 0.876 2 Nursery 6 0.919 7 7 0.899 1 6 0.907 6 Car 5 0.877 3 5 0.857 8 5 0.882 1 Soybean 16 0.998 7 17 0.990 7 18 0.997 6 Tic⁃Tac⁃Toe 7 0.992 9 6 0.979 9 7 0.987 8 SPECT 12 0.984 2 11 0.886 8 13 0.980 5 图 2 在 Kr⁃vs⁃Kp 数据集上的实验结果 Fig.2 The experimental results of data set Kr⁃vs⁃Kp 图 3 在 Voting 数据集上的实验结果 Fig.3 The experimental results of data set Voting 图 4 在 Mushroom 数据集上的实验结果 Fig.4 The experimental results of data set Mushroom 图 5 在 Nursery 数据集上的实验结果 Fig.5 The experimental results of data set Nursery ·400· 智 能 系 统 学 报 第 12 卷

第3期 翟俊海,等:基于粗糙集相对分类信息嫡和粒子群优化的特征选择方法 ·401. 0.90 通过上述实验,我们可以看出采用相对分类信 0.80 息熵作适应度函数的粒子群算法与单纯粗糙集知 0.70 识作为适应度函数的粒子群算法相比,在实验精度 盖0a0 和筛选特征个数方面要明显占优。 接下来实验中,比较粒子群算法和遗传算法在 0.504 +相对分类信息嫡 处理特征选择上的优劣,对比方法为文献[35]中的 0.40 ◆-RSPSO -IBPSO 采用相同适应度函数的遗传特征选择方法。从#Fs、 0.3 05 101520253035404550 Ac、σ和Time4个方面进行了比较,结果列于表2 迭代次数 和表3中。其中,#Fs表示选出的特征数,Ac表示测 图6在Car数据集上的实验结果 试精度,c表示分类标准差,Time表示运行时间。 Fig.6 The experimental results of data set Car 更直观的实验结果如图10~17所示。 1.00 广88555288555555558555582港853 表2与遗传算法比较的实验结果(1) 0.95 Table 2 The experimental results compared with genetic algorithm(1) 0.90 本文方法 文献[35]方法 共0.85 数据集 #Fs Ac #Fs Ac 0.80 十相对分类信息嫡 RSPSO Kr-vs-Kp 12 0.9733 13 0.9516 ·-IBPSO 0.7505101520253035404550 Voting 10 0.6558 y 0.6224 迭代次数 Mushroom 8 0.8829 10 0.8371 图7在Sovbean数据集上的实验结果 Fig.7 The experimental results of data set Soybean Nursery 6 0.9197 > 0.9021 1.00 Car 5 0.8773 5 0.8628 0.99 0.98 Soybean 16 0.9987 9 0.9979 0.97 银0.96 Tic-Tac-Toe 7 0.9929 7 0.9935 0.95 共0.94 0.93 SPECT 12 0.9842 0.9769 0.92 +一相对分类信息嫡 --RSPSO 0.91 表3与遗传算法比较的实验结果(2) -IBPSO 0.9 5101520253035404550 Table 3 The experimental results compared with 0 迭代次数 genetic algorithm(2) 图8在Tic-Tac-Toe数据集上的实验结果 本文方法 文献[35]方法 数据集 Fig.8 The experimental results of data set Tic-Tac-Toe a Time a Time 1.00 Kr-vs-Kp 2.27×103415.25764.75×103508.5847 0.98 0.96 Voting 4.62×10324.31667.15×103 26.0479 0.94 Mushroom1.08×10-485.12186.68×10-3 96.0086 0.92 营0.90 0.88 Nursery 8.72×10-32311.14381.04×10-22653.8612 0.86 +相对分类信息熵 Car 5.19×10-3 10.52683.97×10-310.2885 0.84 --RSPSO 0.82 -IBPSO Sovbean2.01×10-335.17362.59×10-364.1101 0.8 05101520253035404550 迭代次数 Tic-Tac-Toe3.68×10-312.16356.02×10319.9828 图9在SPECT数据集上的实验结果 SPECT5.43×10-320.56397.52×10329.7611 Fig.9 The experimental results of data set SPECT
图 6 在 Car 数据集上的实验结果 Fig.6 The experimental results of data set Car 图 7 在 Soybean 数据集上的实验结果 Fig.7 The experimental results of data set Soybean 图 8 在 Tic⁃Tac⁃Toe 数据集上的实验结果 Fig.8 The experimental results of data set Tic⁃Tac⁃Toe 图 9 在 SPECT 数据集上的实验结果 Fig.9 The experimental results of data set SPECT 通过上述实验,我们可以看出采用相对分类信 息熵作适应度函数的粒子群算法与单纯粗糙集知 识作为适应度函数的粒子群算法相比,在实验精度 和筛选特征个数方面要明显占优。 接下来实验中,比较粒子群算法和遗传算法在 处理特征选择上的优劣,对比方法为文献[35]中的 采用相同适应度函数的遗传特征选择方法。 从#Fs、 Ac、σ 和 Time 4 个方面进行了比较,结果列于表 2 和表 3 中。 其中,#Fs 表示选出的特征数,Ac 表示测 试精度,σ 表示分类标准差,Time 表示运行时间。 更直观的实验结果如图 10~17 所示。 表 2 与遗传算法比较的实验结果(1) Table 2 The experimental results compared with genetic algorithm(1) 数据集 本文方法 文献[35]方法 #Fs Ac #Fs Ac Kr⁃vs⁃Kp 12 0.973 3 13 0.951 6 Voting 10 0.655 8 12 0.622 4 Mushroom 8 0.882 9 10 0.837 1 Nursery 6 0.919 7 7 0.902 1 Car 5 0.877 3 5 0.862 8 Soybean 16 0.998 7 19 0.997 9 Tic⁃Tac⁃Toe 7 0.992 9 7 0.993 5 SPECT 12 0.984 2 15 0.976 9 表 3 与遗传算法比较的实验结果(2) Table 3 The experimental results compared with genetic algorithm(2) 数据集 本文方法 文献[35]方法 σ Time σ Time Kr⁃vs⁃Kp 2.27×10 -3 415.257 6 4.75×10 -3 508.584 7 Voting 4.62×10 -3 24.316 6 7.15×10 -3 26.047 9 Mushroom 1.08×10 -4 85.121 8 6.68×10 -3 96.008 6 Nursery 8.72×10 -3 2311.143 8 1.04×10 -2 2 653.861 2 Car 5.19×10 -3 10.526 8 3.97×10 -3 10.288 5 Soybean 2.01×10 -3 35.173 6 2.59×10 -3 64.110 1 Tic⁃Tac⁃Toe 3.68×10 -3 12.163 5 6.02×10 -3 19.982 8 SPECT 5.43×10 -3 20.563 9 7.52×10 -3 29.761 1 第 3 期 翟俊海,等:基于粗糙集相对分类信息熵和粒子群优化的特征选择方法 ·401·