
通常,人们根据样本间的某种距离或者相似性 来定义聚类,即把相似的(或距离近的)样本聚为 同一类,而把不相似的(或距离远的)样本归在其 他类。 聚类的目标:组内的对象相互之间时相似的 (相关的),而不同组中的对象是不同的(不相关 的)。组内的相似性越大,组间差别越大,聚类就 越好
通常,人们根据样本间的某种距离或者相似性 来定义聚类,即把相似的(或距离近的)样本聚为 同一类,而把不相似的(或距离远的)样本归在其 他类。 聚类的目标:组内的对象相互之间时相似的 (相关的),而不同组中的对象是不同的(不相关 的)。组内的相似性越大,组间差别越大,聚类就 越好
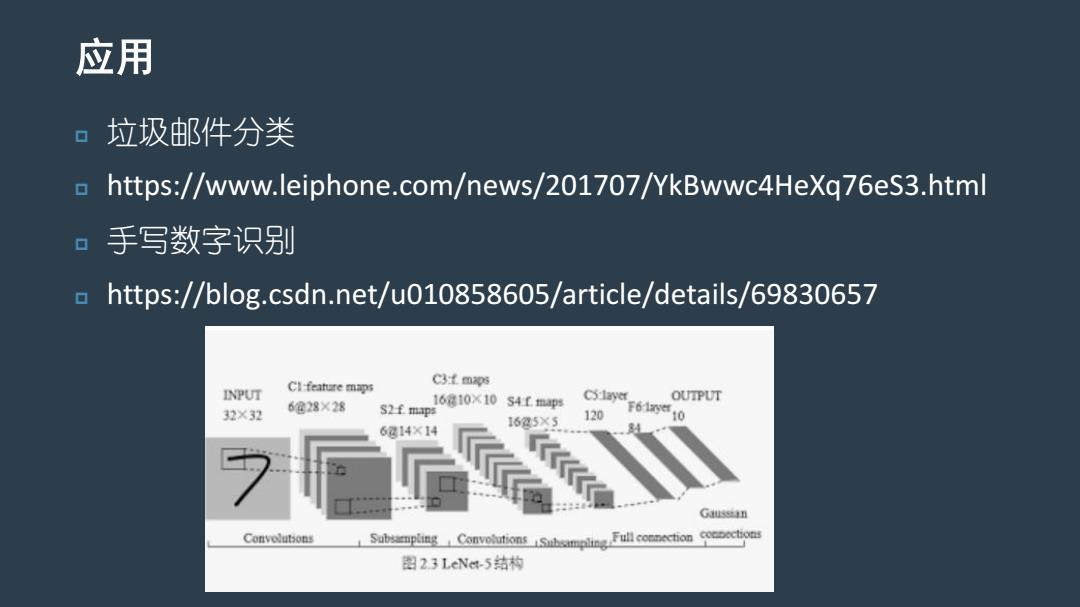
应用 垃圾邮件分类 o https://www.leiphone.com/news/201707/YkBwwc4HeXq76eS3.html 0 手写数字识别 https://blog.csdn.net/u010858605/article/details/69830657 C3:t maps INPUT Cl-feature maps TPUT 32×32 6@28×28 S2f maps 16810x10 54t maps CSlayer 16g5X5 120 r61010 6814×14 Gusszan Convolutions SubnConvouionFllcooo 图23 LeNet-5结构
应用 垃圾邮件分类 https://www.leiphone.com/news/201707/YkBwwc4HeXq76eS3.html 手写数字识别 https://blog.csdn.net/u010858605/article/details/69830657

PART 2 KNN算法 别和其他坏学生在一起,否则你也会和他们一样
PART 2 KNN算法 别和其他坏学生在一起,否则你也会和他们一样

定义 在分类算法中,K最近邻是最普通也是最 好理解的算法。它的主要思想是通过离待预 测样本最近的K个样本的类别来判断当前样本 的类别
定义 在分类算法中,K最近邻是最普通也是最 好理解的算法。它的主要思想是通过离待预 测样本最近的K个样本的类别来判断当前样本 的类别

家长们希望孩子成为好学生,可能为此 不惜重金购买学区房或者上私立学校,一个 原因之一是这些优秀的学校里有更多的优秀 学生,与其他优秀学生走的更近
家长们希望孩子成为好学生,可能为此 不惜重金购买学区房或者上私立学校,一个 原因之一是这些优秀的学校里有更多的优秀 学生,与其他优秀学生走的更近