
EARN 字典学习基本原理 1.4 1.5 1.6 (s)awl 1.7 1.8 19 Impedance(g/cc*m/s)x103
字典学习基本原理

03 字典学习基本原理 解析字典 基于解析构造字典方法往往通过事先定义好的 某种数学变换或者分析变换来生成字典原子, 该方法虽然构造简单,计算复杂度低,但原子 形态过于单一,无法最佳匹配结构复杂的样本 字典 数据。 学习字典 基于学习构造字典方法是通过优化相应的字典 学习代价函数,获得能够对信号进行稀疏表示 的字典。该方法基于最优化思想从训练样本中 自适应的找到最匹配的样本集基向量,相比于 解析字典方法,其生成的字典原子表征能力更 强,能够适应特定问题并产生更好的稀疏性。 Yang,J.Wright,J.Huang,T.Ma,Y.Image Super-Resolution Via Sparse Representation[J].IEEE Transactions on Image Processing.2010,1911):2861-2873
字典 解析字典 基于解析构造字典方法往往通过事先定义好的 某种数学变换或者分析变换来生成字典原子, 该方法虽然构造简单,计算复杂度低,但原子 形态过于单一,无法最佳匹配结构复杂的样本 数据。 学习字典 基于学习构造字典方法是通过优化相应的字典 学习代价函数,获得能够对信号进行稀疏表示 的字典。该方法基于最优化思想从训练样本中 自适应的找到最匹配的样本集基向量,相比于 解析字典方法,其生成的字典原子表征能力更 强,能够适应特定问题并产生更好的稀疏性。 字典学习基本原理 Yang, J.Wright, J.Huang, T.Ma, Y. Image Super-Resolution Via Sparse Representation[J]. IEEE Transactions on Image Processing, 2010, 19(11):2861-2873
字典学习基本原理 {D,4)argmin{Y-DA) D.A Y A st.i:alo≤K 44 ↓ × a (D,4)=arg minly-D+ ddd d st.i:D≤1
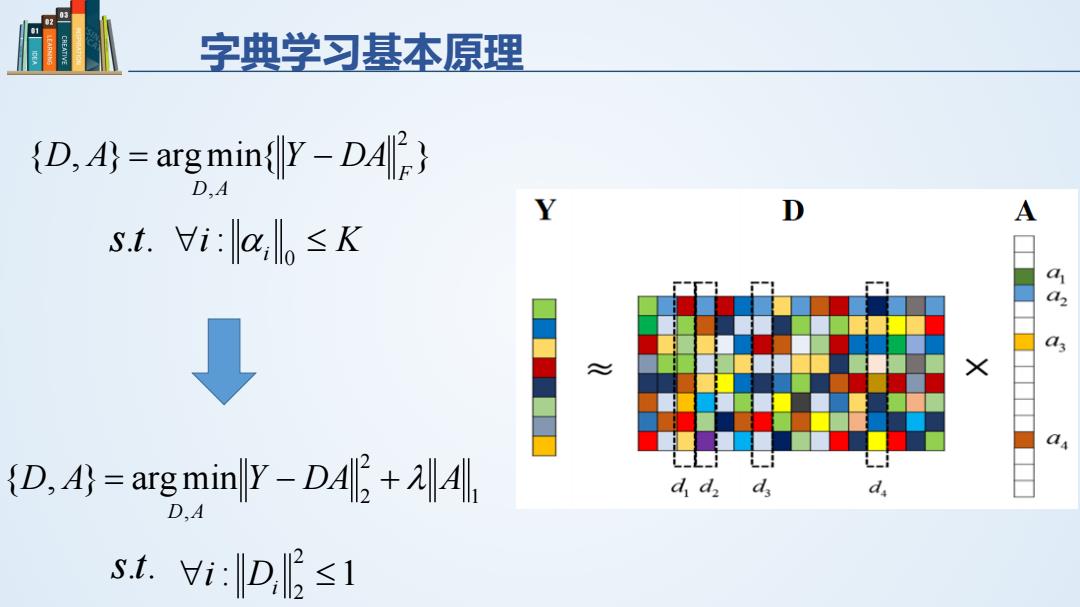
字典学习基本原理 { , } argmin{ } 2 , F D A D A = Y − DA s.t. ∀i i ≤ K 0 : α 1 2 2 , {D, A} argmin Y DA A D A = − + λ s.t. : 1 2 2 ∀i Di ≤

字典学习基本原理 14 1.5 16 (s)aw!.L 1.7 1. Impedance(g/ce*m/s)x103 Bin She,Yao jun Wang,2019,Seismic impedance inversion using dictionary learning-based sparse representation and nonlocal similarity,Interpretation 2019,SE51-SE67
字典学习基本原理 Bin She, Yao jun Wang, 2019, Seismic impedance inversion using dictionary learning-based sparse representation and nonlocal similarity, Interpretation 2019, SE51-SE67

字典学习基本原理 Yang,J.Wright,J.Huang,T.Ma,Y.Image Super-Resolution Via Sparse Representation[J].IEEE Transactions on Image Processing,2010,1911):2861-2873
字典学习基本原理 Yang, J.Wright, J.Huang, T.Ma, Y. Image Super-Resolution Via Sparse Representation[J]. IEEE Transactions on Image Processing, 2010, 19(11):2861-2873