
LECTURE 3-MEMORY AND DATA LOCALITY
LECTURE 3 – MEMORY AND DATA LOCALITY

Memory access efficiency Tiled Matrix Multiplication Tiled Matrix Multiplication Kernel Handling Boundary Conditions in Tiling Tiled Kernel for Arbitrary Matrix Dimensions Universityf Electr Science and TachnoloChina
Memory access efficiency Tiled Matrix Multiplication Tiled Matrix Multiplication Kernel Handling Boundary Conditions in Tiling Tiled Kernel for Arbitrary Matrix Dimensions

OBIECTIVE .To learn to effectively use the CUDA memory types in a parallel program .Importance of memory access efficiency Registers,shared memory,global memory .Scope and lifetime 电子料发女学 University of ElectriScience and TachnolopChina O
▪To learn to effectively use the CUDA memory types in a parallel program ▪ Importance of memory access efficiency ▪ Registers, shared memory, global memory ▪ Scope and lifetime
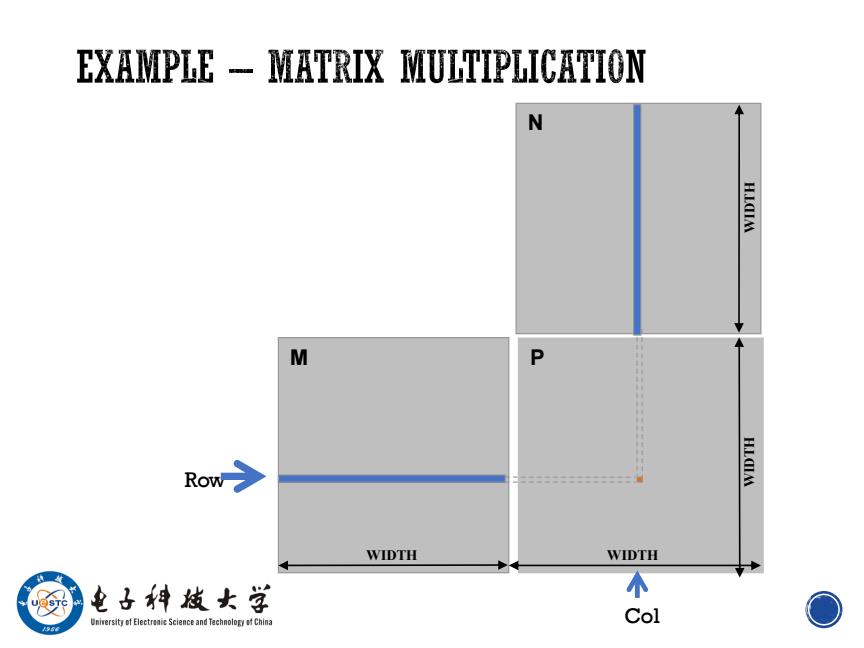
EXAMPLE-MATRIX MULTIPLICATION N H.LQIM M P Row H.LCIA WIDTH WIDTH 电子料效女学 个 niversitof Electr Science and TachnoloChina Col O
M N P WIDTH WIDTH WIDTH Row WIDTH Col

A BASIC MATRIX MULTIPLICATION global void MatrixMulKernel(float*M,float*N,float*P,int Width) /Calculate the row index of the p element and M int Row blockIdx.y*blockDim.y+threadIdx.y; /Calculate the column index of P and N int Col blockIdx.x*blockDim.x+threadIdx.x; if ((Row Width)&&(Col Width)){ float Pvalue 0; /each thread computes one element of the block sub-matrix for (int k 0;k Width;++k){ Pvalue +M[Row*Width+k]*N[k*Width+Col]; P[Row*Width+Col]Pvalue; 电子料烛女学 University of Electreaie Science and Technolory of China O
__global__ void MatrixMulKernel(float* M, float* N, float* P, int Width) { // Calculate the row index of the P element and M int Row = blockIdx.y*blockDim.y+threadIdx.y; // Calculate the column index of P and N int Col = blockIdx.x*blockDim.x+threadIdx.x; if ((Row < Width) && (Col < Width)) { float Pvalue = 0; // each thread computes one element of the block sub-matrix for (int k = 0; k < Width; ++k) { Pvalue += M[Row*Width+k]*N[k*Width+Col]; } P[Row*Width+Col] = Pvalue; } }