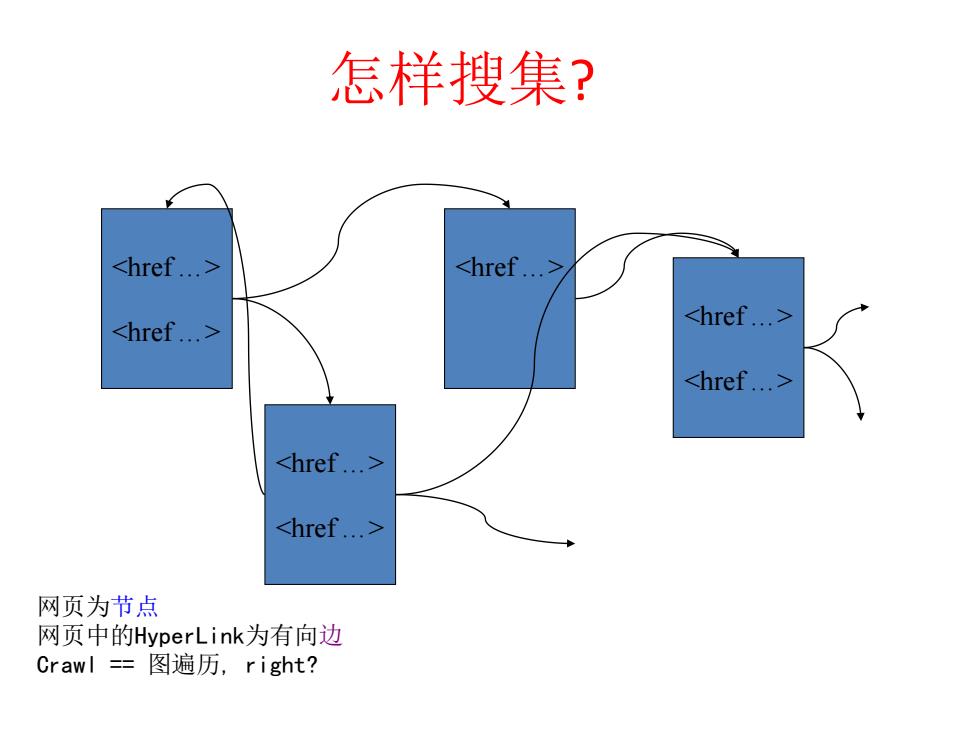
怎样搜集? <href...> <href...> <href...> <href...> <href...> href..≥ <href...> 网页为节点 网页中的HyperLink为有向边 Crawl=图遍历,right?
怎样搜集? <href …> <href …> <href …> <href …> <href …> <href …> <href …> 网页为节点 网页中的HyperLink为有向边 Crawl == 图遍历, right?
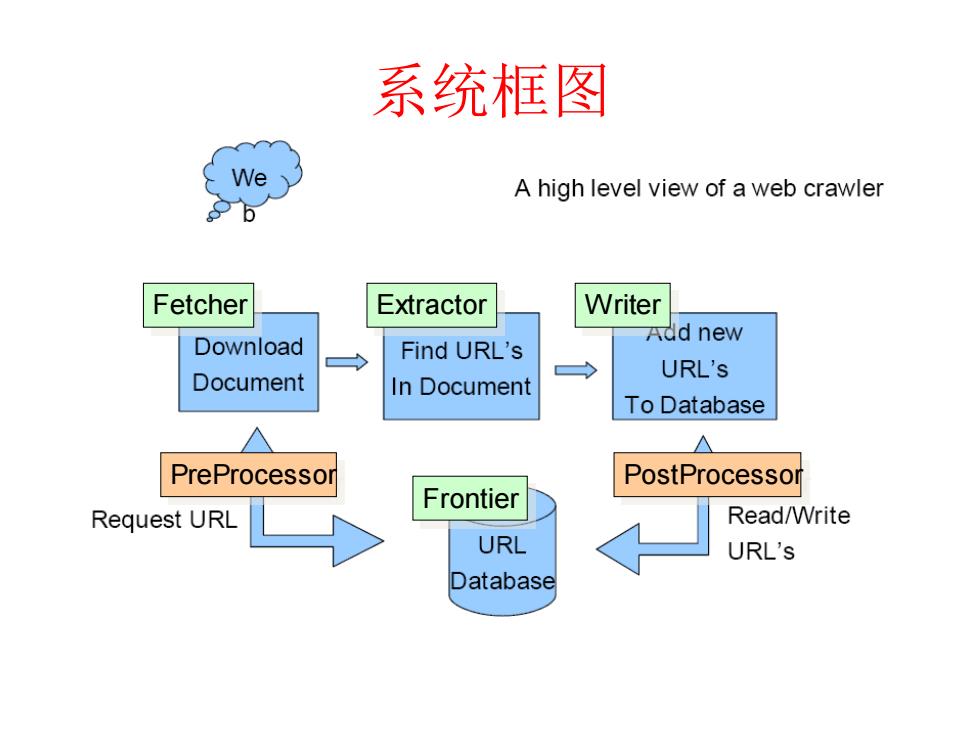
系统框图 A high level view of a web crawler Fetcher Extractor Writer Add new Download Find URL's ◇ URL's Document In Document To Database △ △ PreProcessor PostProcessor Frontier Request URL Read/Write URL URL's Database
系统框图 Frontier Fetcher Extractor Writer PreProcessor PostProcessor

Core Algorithms I PROCEDURE SPIDER (G) Let ROOT :any URL from G Initialize STACK <stack data structure> Let STACK push(ROOT,STACK) Initialize COLLECTION <big file of URL-page pairs> While STACK is not empty, URLeu :POP(STACK) PAGE :1ook-up (URLeurr) STORE (<URL,PAGE>,COLLECTION) For every URL:in PAGE, push (URL;,STACK) Return COLLECTION
Core Algorithms I PROCEDURE SPIDER1(G) Let ROOT := any URL from G Initialize STACK <stack data structure> Let STACK := push(ROOT, STACK) Initialize COLLECTION <big file of URL-page pairs> While STACK is not empty, URLcurr := pop(STACK) PAGE := look-up(URLcurr) STORE(<URLcurr, PAGE>, COLLECTION) For every URLi in PAGE, push(URLi, STACK) Return COLLECTION

Review of Algorithm I PROCEDURE SPIDER (G) 重复搜集, Let ROOT :any URL from G 遇到回路会无限循环 Initia1 ize STACK<stack dataG如果不连通呢? Let STACK push (ROOT,STA G如果大到STACK容纳不下呢? Initialize COLLECTION <big •要控制搜集G的一部分呢? While STACK is not empty, URLeurr :pop (STACK) PAGE :look-up(URLeurr) STORE(<URLCUEE,PAGE>,COLLECTION) For every URLi in PAGE, push (URLi,STACK) Return COLLECTION
Review of Algorithm I PROCEDURE SPIDER1(G) Let ROOT := any URL from G Initialize STACK <stack data structure> Let STACK := push(ROOT, STACK) Initialize COLLECTION <big file of URL-page pairs> While STACK is not empty, URLcurr := pop(STACK) PAGE := look-up(URLcurr) STORE(<URLcurr, PAGE>, COLLECTION) For every URLi in PAGE, push(URLi, STACK) Return COLLECTION •重复搜集, •遇到回路会无限循环 •G如果不连通呢? •G如果大到STACK容纳不下呢? •要控制搜集G的一部分呢?

A More Complete Correct Algorithm PROCEDURE SPIDER(G,{SEEDS } Initialize COLLECTION <big fil STACK Initialize VISITED <big hash-t 用disk-based heap结构实现 For every ROOT in SEEDS Initialize STACK <stack data structure> Let STACK push (ROOT,STACK) While STACK is not empty, Do URLcurr :pop (STACK) Until URLcurr is not in VISITED insert-hash (URLcurr,VISITED) PAGE look-up (URLcurr) STORE (<URLcur:PAGE>,COLLECTION) For every URL:in PAGE, Push(URL生,STACK) Return COLLECTION
A More Complete Correct Algorithm PROCEDURE SPIDER4(G, {SEEDS}) Initialize COLLECTION <big file of URL-page pairs> Initialize VISITED <big hash-table> For every ROOT in SEEDS Initialize STACK <stack data structure> Let STACK := push(ROOT, STACK) While STACK is not empty, Do URLcurr := pop(STACK) Until URLcurr is not in COLLECTION insert-hash(URLcurr, VISITED) PAGE := look-up(URLcurr) STORE(<URLcurr, PAGE>, COLLECTION) For every URLi in PAGE, push(URLi, STACK) Return COLLECTION Until URLcurr is not in VISITED STACK 用disk-based heap结构实现