
第12卷第4期 智能系统学报 Vol.12 No.4 2017年8月 CAAI Transactions on Intelligent Systems Aug.2017 D0I:10.11992/is.201610004 网s络出版地址:http:/kns.cnki.net/kcms/detail/23.1538.tp.20170407.1744.008.html 依概率收敛的改进粒子群优化算法 钱伟懿,李明 (渤海大学数理学院,辽宁锦州121013) 摘要:粒子群优化算法是一种随机优化算法,但它不依概率1收敛到全局最优解。因此提出一种新的依概率收敛 的粒子群优化算法。在该算法中,首先引入了具有探索和开发能力的两个变异算子,并依一定概率对粒子当前最好 位置应用这两个算子,然后证明了该算法是依概率1收敛到ε最优解。最后,把该算法应用到13个典型的测试函数 中,并与其他粒子群优化算法比较,数值结果表明所给出的算法能够提高求解精度和收敛速度。 关键词:粒子群优化算法:随机优化算法:变异算子:依概率收敛:全局优化:进化计算:启发式算法:高斯分布 中图分类号:TP301.6文献标志码:A文章编号:1673-4785(2017)04-0511-08 中文引用格式:钱伟懿,李明.依概率收敛的改进粒子群优化算法[J].智能系统学报,2017,12(4):511-518. 英文引用格式:QIAN Weiyi,LI Ming..mproved particle swarm optimization algorithmwith probability convergence[J].CAAI transactions on intelligent systems,2017,12(4):511-518. Improved particle swarm optimization algorithm with probability convergence QIAN Weiyi,LI Ming (College of Mathematics and Physics,Bohai University,Jinzhou 121013,China) Abstract:The particle swarm optimization (PSO)algorithm is a stochastic optimization algorithm that does not converge to a global optimal solution on the basis of probability 1.In this paper,we present a new probability-based convergent PSO algorithm that introduces two mutation operators with exploration and exploitation abilities,which are applied to the previous best position of a particle with a certain probability.This algorithm converges to the- optimum solution on the basis of probability 1.We applied the proposed algorithm in 13 typical test functions and compared its performance with that of other PSO algorithms.Our numerical results show that the proposed algorithm can improve solution precision and convergence speed. Keywords:particle swarm optimization;stochastic optimization algorithm;mutation operator;probability convergence;global optimization;evolutionary computation;heuristic algorithm;Gaussian distribution 粒子群优化算法是Kennedy等)在1995年提 结合1):3)在PS0算法引入一些改进PS0算法性 出的一种群体搜索的随机优化算法。由于PSO算 能的其他算子,比如,把高斯扰动策略加入粒子群 法的参数少而且易操作,所以在实际问题中得到了 优化算法中[,把均匀设计方法引入到粒子群优化 广泛的应用。对PSO算法的研究主要有以下几个 算法中),把变异策略)、精英策略1)、局部搜索 方面:1)对PS0算法自身参数的改进,这方面的工 策略[20]及邻域搜索策略[21]引入到粒子群优化算法 作主要关于惯性权重的自适应改进2-)和对学习因 中:4)PS0算法的理论分析,比如,基于线性系统理 子的改进9-川;2)将其他进化算法与PS0相结合, 论研究PS0收敛性2-2],基于随机过程研究PS0 比如,遗传算法与PS0算法结合2-),差分进化算 收敛性[2),但是粒子群算法不依概率收敛[2。本 法与PS0算法结合[14,模拟退火算法与PS0算法 文给出了一种依概率1收敛的PS0算法,该算法在 标准粒子群优化算法实施位置更新后按一定概率 收稿日期:2016-10-05.网络出版日期:2017-04-07. 对较好的粒子实施具有开发能力的变异操作,对较 基金项目:国家自然科学基金项目(11371071):辽宁省数育厅科学研究 差的粒子实施具有探索能力的变异操作,从而平衡 项目(L2013426). 通信作者:钱伟懿.E-mail:qianweiyi2008@163.com. 了算法的全局搜索能力和局部搜索能力,提高了算
第 12 卷第 4 期 智 能 系 统 学 报 Vol.12 №.4 2017 年 8 月 CAAI Transactions on Intelligent Systems Aug. 2017 DOI:10.11992 / tis.201610004 网络出版地址:http: / / kns.cnki.net / kcms/ detail / 23.1538.tp.20170407.1744.008.html 依概率收敛的改进粒子群优化算法 钱伟懿,李明 (渤海大学 数理学院,辽宁 锦州 121013) 摘 要:粒子群优化算法是一种随机优化算法,但它不依概率 1 收敛到全局最优解。 因此提出一种新的依概率收敛 的粒子群优化算法。 在该算法中,首先引入了具有探索和开发能力的两个变异算子,并依一定概率对粒子当前最好 位置应用这两个算子,然后证明了该算法是依概率 1 收敛到 ε⁃最优解。 最后,把该算法应用到 13 个典型的测试函数 中,并与其他粒子群优化算法比较,数值结果表明所给出的算法能够提高求解精度和收敛速度。 关键词:粒子群优化算法;随机优化算法;变异算子;依概率收敛;全局优化;进化计算;启发式算法;高斯分布 中图分类号:TP301.6 文献标志码:A 文章编号:1673-4785(2017)04-0511-08 中文引用格式:钱伟懿,李明.依概率收敛的改进粒子群优化算法[J]. 智能系统学报, 2017, 12(4): 511-518. 英文引用格式:QIAN Weiyi,LI Ming. Improved particle swarm optimization algorithmwith probability convergence [ J]. CAAI transactions on intelligent systems, 2017, 12(4): 511-518. Improved particle swarm optimization algorithm with probability convergence QIAN Weiyi, LI Ming (College of Mathematics and Physics, Bohai University, Jinzhou 121013, China) Abstract:The particle swarm optimization ( PSO) algorithm is a stochastic optimization algorithm that does not converge to a global optimal solution on the basis of probability 1. In this paper, we present a new probability⁃based convergent PSO algorithm that introduces two mutation operators with exploration and exploitation abilities, which are applied to the previous best position of a particle with a certain probability. This algorithm converges to the⁃ optimum solution on the basis of probability 1.We applied the proposed algorithm in 13 typical test functions and compared its performance with that of other PSO algorithms. Our numerical results show that the proposed algorithm can improve solution precision and convergence speed. Keywords: particle swarm optimization; stochastic optimization algorithm; mutation operator; probability convergence; global optimization; evolutionary computation; heuristic algorithm; Gaussian distribution 收稿日期:2016-10-05. 网络出版日期:2017-04-07. 基金项目:国家自然科学基金项目(11371071);辽宁省教育厅科学研究 项目(L2013426). 通信作者:钱伟懿. E⁃mail:qianweiyi2008@ 163.com. 粒子群优化算法是 Kennedy 等[1] 在 1995 年提 出的一种群体搜索的随机优化算法。 由于 PSO 算 法的参数少而且易操作,所以在实际问题中得到了 广泛的应用。 对 PSO 算法的研究主要有以下几个 方面:1)对 PSO 算法自身参数的改进,这方面的工 作主要关于惯性权重的自适应改进[2-9] 和对学习因 子的改进[9-11] ;2)将其他进化算法与 PSO 相结合, 比如,遗传算法与 PSO 算法结合[12-13] ,差分进化算 法与 PSO 算法结合[14] ,模拟退火算法与 PSO 算法 结合[15] ;3)在 PSO 算法引入一些改进 PSO 算法性 能的其他算子,比如,把高斯扰动策略加入粒子群 优化算法中[16] ,把均匀设计方法引入到粒子群优化 算法中[17] ,把变异策略[18] 、精英策略[19] 、局部搜索 策略[20]及邻域搜索策略[21] 引入到粒子群优化算法 中;4)PSO 算法的理论分析,比如,基于线性系统理 论研究 PSO 收敛性[22-25] ,基于随机过程研究 PSO 收敛性[26] ,但是粒子群算法不依概率收敛[26] 。 本 文给出了一种依概率 1 收敛的 PSO 算法,该算法在 标准粒子群优化算法实施位置更新后按一定概率 对较好的粒子实施具有开发能力的变异操作,对较 差的粒子实施具有探索能力的变异操作,从而平衡 了算法的全局搜索能力和局部搜索能力,提高了算

.512. 智能系统学报 第12卷 法的效率,另外,证明了该算法依概率1收敛到ε- P实施式(4)或式(5)的变异操作,即当f(P)≤∫ 最优解。实验结果表明,提出的算法能够提高全局 时,对P按概率μ实施式(5)的变异操作,当f(P)> 搜索能力,算法的收敛速度明显加快。 f时,对P按概率u实施式(4)的变异操作,其中 Ne 1标准PS0算法 ), (7) 标准粒子群算法中,粒子群由N。个粒子组成, [(-(P)) 在时刻k,第i个粒子在d维空间中速度和位置的更 fs-f(P) f(P)≤fe 新公式为 u= (8) a(f(Pi)-fv) v=ovi cir(pi -xia)+car2(pa -x) fu -fave f(P)>fv (1) 城=x始+城 式中:f=max{f(P)},a是一个自适应参数,它 (2) 1iN 式中:i=1,2,…,N。,d=1,2,…,D,D为决策变量的 被定义为 维数,ω为惯性权重,x=(x始,x点,…,x0)表示粒子i a=1-0.8 (9) 的当前的位置;=(,哈,…,)是粒子i的当前 由式(8)知,对适应值较好的粒子实施局部搜 的速度;P=(p哈,p哈,…,P)是粒子i当前最优位 索的概率较大,而对适应值较差的粒子实施全局搜 置,P=(p,P点,…,P)是全局最优位置;c1、2是 索的概率较大。由于当算法迭代到后期,粒子比较 加速度因子,12是0~1之间的随机数。第k次迭 代的惯性权重表示为 集中,从而导致-或)-接近1,若a -可或 fef(p)fa-fe =(@stan -@end (3) 大,那么实施式(4)或式(5)的变异操作的粒子较 多,从而导致算法运算时间长,因此按式(9)实行单 式中:wat、w分别为最初和最终的惯性权重,K 调递减策略。 是最大迭代步。 位置与速度越界处理: 2 改进的PSO算法 , 儿≤站≤山 la+rand()·(u4-la), 其他 提高PS0算法性能的有效方法之一就是平衡 (10) 算法的探索能力和开发能力。我们的目的是对粒 子所经历的最好位置进行操作,一方面能够使其跳 站,n≤话≤ 出局部最优;另一方面使其具有一定的局部搜索能 =min' 姑1<an (11) 力。为此,给出两个变异算子: P=P·p,N(0,c2) (4) 式中:=0.5l4,8"=0.5u4o 改进PSO0算法的流程如下: P=P+p,N(0,2) (5) 1)设置参数,随机初始化粒子的位置和速度, 式中:P1>1和P2>1是常数,N(0,o2)是具有时变标 计算各粒子的适应度,确定每个粒子的经历过的最 准差σ的高斯分布的随机变量,σ表示为 优位置及全局最优位置,令k=1: 00--小 2)按式(3)计算惯性权重,并按式(1)和式(2) (6) 进行速度与位置更新: 式中:0m和σ是标准差σ的最终和初始值,k是 3)按式(10)和式(11)进行越界处理: 当前迭代步,K是最大迭代步。因为P,N(0,σ2) 4)对粒子i(i=1,2,…,N)计算其适应值,更 的值比1大或比1小,又因为P·P1N(0,σ2)是一 新其经历过的最优位置P和全局最优位置P, 个随机值,所以它比P大或小,这样P可能远离 并按式(7)计算fe: P,因此说式(4)具有一定的全局搜索能力。另一 5)若f(P)≤f,按式(9)计算a,按式(8)计 算u,在[0,l]选取一个随机数and,若rand<u,则 方面,式(5)表明在P附近搜索,因此式(5)具有一 按式(6)计算σ,按式(5)更新粒子经历过的最优位 定的局部搜索能力。 如果每次都对P实施式(4)或式(5)的变异操 置,得到P,转7): 作,那么导致算法运行时间长,因此按一定概率μ对 6)若fP)>f,按式(9)计算a,按式(8)计
法的效率,另外,证明了该算法依概率 1 收敛到 ε⁃ 最优解。 实验结果表明,提出的算法能够提高全局 搜索能力,算法的收敛速度明显加快。 1 标准 PSO 算法 标准粒子群算法中,粒子群由 Np 个粒子组成, 在时刻 k,第 i 个粒子在 d 维空间中速度和位置的更 新公式为 v k+1 id = ωv k id + c1 r1(p k id - x k id ) + c2 r2(p k gd - x k id ) (1) x k+1 id = x k id + v k+1 id (2) 式中:i = 1,2,…,Np,d = 1,2,…,D,D 为决策变量的 维数,ω 为惯性权重,x k i = (x k i1 ,x k i2 ,…,x k iD)表示粒子 i 的当前的位置;v k i = (v k i1 ,v k i2 ,…,v k iD )是粒子 i 的当前 的速度;P k i = ( p k i1 ,p k i2 ,…,p k iD ) 是粒子 i 当前最优位 置,P k g = ( p k g1 ,p k g2 ,…,p k gD )是全局最优位置;c1 、c2 是 加速度因子,r1 、r2 是 0~1 之间的随机数。 第 k 次迭 代的惯性权重表示为 ωk = (ωstart - ωend ) Kmax - k Kmax æ è ç ö ø ÷ + ωend (3) 式中:ωstart、ωend分别为最初和最终的惯性权重,Kmax 是最大迭代步。 2 改进的 PSO 算法 提高 PSO 算法性能的有效方法之一就是平衡 算法的探索能力和开发能力。 我们的目的是对粒 子所经历的最好位置进行操作,一方面能够使其跳 出局部最优;另一方面使其具有一定的局部搜索能 力。 为此,给出两个变异算子: P -k id = P k id·ρ1N(0,σ 2 ) (4) P -k id = P k id + ρ2N(0,σ 2 ) (5) 式中:ρ1>1 和 ρ2>1 是常数,N(0,σ 2 )是具有时变标 准差 σ 的高斯分布的随机变量,σ 表示为 σ = σmax - (σmax - σmin ) k Kmax (6) 式中:σmax和 σmin是标准差 σ 的最终和初始值,k 是 当前迭代步,Kmax是最大迭代步。 因为 ρ1N(0,σ 2 ) 的值比 1 大或比 1 小,又因为 P k id·ρ1N(0,σ 2 )是一 个随机值,所以它比 P k id 大或小,这样 P -k id 可能远离 P k id ,因此说式(4)具有一定的全局搜索能力。 另一 方面,式(5)表明在 P k id附近搜索,因此式(5)具有一 定的局部搜索能力。 如果每次都对P k i 实施式(4)或式(5)的变异操 作,那么导致算法运行时间长,因此按一定概率 μ 对 P k i 实施式(4)或式(5)的变异操作,即当 f(P k i )≤f ave 时,对P k i 按概率 μ 实施式(5)的变异操作,当f(P k i )> f ave时,对P k i 按概率 μ 实施式(4)的变异操作,其中 f ave = 1 Np ∑ Np j = 1 f(P k j ), (7) μ = α(f ave - f(P k i )) f ave - f(P k g ) , f(P k i ) ≤ f ave α(f(P k i ) - f ave) fmax - f ave , f(P k i ) > f ave ì î í ï ïï ï ïï (8) 式中:fmax = max 1≤i≤Np { f(P k i )},α 是一个自适应参数,它 被定义为 α = 1 - 0.8 k Kmax (9) 由式(8)知,对适应值较好的粒子实施局部搜 索的概率较大,而对适应值较差的粒子实施全局搜 索的概率较大。 由于当算法迭代到后期,粒子比较 集中,从而导致 f ave -f(P k i ) f ave -f(P k g ) 或 f(P k i )-f ave fmax -f ave 接近 1,若 α 大,那么实施式(4) 或式(5) 的变异操作的粒子较 多,从而导致算法运算时间长,因此按式(9)实行单 调递减策略。 位置与速度越界处理: x k+1 id = x k+1 id , l d ≤ x k+1 id ≤ ud l d + rand()·(ud - l { d ), 其他 (10) v k+1 id = v k+1 id , vmin ≤ v k+1 id ≤ vmax vmin , v k+1 id < vmin vmax, v k+1 id > vmax ì î í ï ï ï ï (11) 式中:v min d = 0.5l d ,v max d = 0.5ud 。 改进 PSO 算法的流程如下: 1)设置参数,随机初始化粒子的位置和速度, 计算各粒子的适应度,确定每个粒子的经历过的最 优位置及全局最优位置,令 k = 1; 2)按式(3)计算惯性权重,并按式(1)和式(2) 进行速度与位置更新; 3) 按式(10)和式(11)进行越界处理; 4) 对粒子 i(i = 1,2,…,Np )计算其适应值,更 新其经历过的最优位置P k+1 i 和全局最优位置P k+1 g , 并按式(7)计算 f ave; 5) 若 f(P k+1 i )≤f ave,按式(9)计算 α,按式(8)计 算 μ,在[0,1]选取一个随机数 rand,若 rand< μ,则 按式(6)计算 σ,按式(5)更新粒子经历过的最优位 置,得到P -k+1 i ,转 7); 6)若 f(P k+1 i )>f ave,按式(9)计算 α,按式(8)计 ·512· 智 能 系 统 学 报 第 12 卷

第4期 钱伟懿,等:依概率收敛的改进粒子群优化算法 ·513· 算u,在[0,1]选取一个随机数rand,若rand<u,则 B。;如果P(new)=P,则结论是显然的。 按(6)式计算σ,按(4)式更新粒子经历过的最优位 引理3H重E④,P由算法生成的,则存在 置,得到P; p>0,使得 7)令 pr(P1∈BI重=)≥p p,fp)<fP) 式中pr表示概率测度。 p+(new)= p1,fp)≥fp) 证明如果P实施变异算子(4)或(5)操作, 8)令P'=P'(new),更新P'; 则令X(P)=1,否则令X(P)=0,由算法步骤5)和 9)判断是否满足终止条件(本文采用最大迭代 步骤6)及式(8)有 步),若满足则输出结果,否则令k=k+1,转2)。 pr(K(P')=1)=a,pr(X(P1)=0)=1-a 3 收敛性分析 于是 本文考虑如下全局优化问题: pr(P1∈BI=D)≥pr(X(P)=1)· minimize f(x) pr(P1∈B.1电=D)1X(P)=1)= subject to x∈S 式中:f:S→R是实值函数,S={xmm≤x≤xm}, a·pr(P1eB.I重=D)1X(P')=1)= a·pr(p'(new)∈B.I中=Φ) xm=(l1,l2,…,ln),xmm=(1,42,…,4o)。 由引理2有 定义1设f(x)是实值函数,x”∈S,若对任意 x∈S, pr(P∈BI=)≥a·pr(P∈B|=) f(x·)≤f(x) 由于P的每个分量是独立的,再由式(5)知, 则称x·为S的全局最优解。 随机变量P+1的密度函数为 定义2对任意ε>0,设 1 D B.={x∈Sllf(x)-f(x·)|<el} g(1,x2,“,xD)= exp(- 则称B。为e最优解集,x∈B。被称为6-最优解。 2Top2 本文假设u(B)>0,其中μ为勒贝格测度。 于是 由定义1和2得: pr(p'∈B|电=)= x结=点+ω点+c(p点-xa)+cr2(p-x) ng(x1,x2,…,xo)dxd2…dxo≥ (12) 由式(12)可看出,在第k+1代粒子群中第i个 √22 exp(-D 2m2 D 粒子的状态由x、、P、P决定,所以令9:=(x,”, u(B.) P:,P)∈T,其中T=SxVxSXSER"。 式中m=m,,lu,}。 定义3设中,=1重|重=(9,…,P,),9:∈ 1 D a加(B.),则 2m2 令p= exp(-D- T,i=1,…,N},则称中为状态空间,中∈中称为 mP2) 状态。 pr(P∈BI重=Φ)≥p>0。 定义4设2={ω1ω=(中,中2,中,…), 定理1设(中,中2,少,…)∈2是由算法任意 重∈中p,Hk,则称n为样本空间,w∈2称为状 生成的状态序列,则序列{p}依概率1收敛到c-最 态序列,其中重=(,,…,吹),=(,,P, 优解,即 P)。 lim pr{pg∈Be}=1 由改进算法可知,f(P)≤f(P),所以有如下 证明由算法可知,中+1只与Φ。有关,所以Φ, 引理。 ④2,中,…是马尔可夫过程,由马尔可夫过程性质及 引理1对Hk≥1,若P∈B,则P∈Bo 引理1可知 pr(PI生B)=pr(PEB) 引理2对Vi,k,若PeB。,那么P(new)∈B。 Πpr(PI年BIP华B)≤ 证明如果P(new)=p,由算法7)知f(p)≥ f(P),再由P∈B。有P∈B.,从而P'(new)∈ Πpr(P生B.lP生B)
算 μ,在[0,1]选取一个随机数 rand,若 rand< μ,则 按(6)式计算 σ,按(4)式更新粒子经历过的最优位 置,得到P -k+1 i ; 7)令 P k+1 i (new) = P - k+1 i , f(P - k+1 i ) < f(P k+1 i ) P k+1 i , f(P - k+1 i ) ≥ f(P k+1 { i ) ; 8) 令P k+1 i =P k+1 i (new),更新P k+1 g ; 9) 判断是否满足终止条件(本文采用最大迭代 步),若满足则输出结果,否则令 k = k+1,转 2)。 3 收敛性分析 本文考虑如下全局优化问题: minimize f(x) subject to x ∈ S 式中:f:S →R 是实值函数, S = { xmin ≤x ≤xmax }, xmin = (l 1 ,l 2 ,…,lD),xmax = (u1 ,u2 ,…,uD)。 定义 1 设 f(x)是实值函数,x ∗ ∈S,若对任意 x∈S, f(x ∗ ) ≤ f(x) 则称 x ∗为 S 的全局最优解。 定义 2 对任意 ε>0,设 Bε = x ∈ S f(x) - f(x ∗ { ) < ε } 则称 Bε 为 ε 最优解集,x∈Bε 被称为 ε⁃最优解。 本文假设 μ(Bε )>0, 其中 μ 为勒贝格测度。 由定义 1 和 2 得: x k+1 id = x k id + ωk v k id + c1 r1(p k id - x k id ) + c2 r2(p k gd - x k id ) (12) 由式(12)可看出,在第 k+1 代粒子群中第 i 个 粒子的状态由x k i 、v k i 、P k i 、P k g 决定,所以令 φi = (xi,vi, Pi,Pg )∈Γ,其中 Γ = S×V×S×S∈R 4D 。 定义 3 设 ΦNp = {Φ 丨Φ = (φ1,…,φNp ),φi ∈ Γ,i = 1,…,Np}, 则称 ΦNp为状态空间,Φ∈ΦNp称为 状态。 定义 4 设 Ω = {ω | ω = ( Φ1 , Φ2 , Φ3 ,…), Φk ∈ΦNp,∀k}, 则称 Ω 为样本空间,ω∈Ω 称为状 态序列,其中Φk = (φ k 1 ,φ k 2 ,…,φ k Np ),φ k i = ( x k i ,v k i ,P k i , P k g )。 由改进算法可知,f(P k+1 g )≤f(P k g ),所以有如下 引理。 引理 1 对∀k≥1,若 P k g∈Bε ,则P k+1 g ∈Bε 。 引理 2 对∀i,k,若P -k i ∈Bε,那么P k+1 i (new) ∈Bε 。 证明 如果P k i(new)= P k i ,由算法 7)知 f(P -k i )≥ f(P k i ),再由P -k i ∈Bε 有 P k i ∈Bε ,从而 P k+1 i ( new) ∈ Bε ;如果P k i(new)= P -k i ,则结论是显然的。 引理 3 ∀Φ∈ΦNp ,P k+1 g 由算法生成的,则存在 ρ>0,使得 pr(P k+1 g ∈ Bε | Φk = Φ) ≥ ρ 式中 pr 表示概率测度。 证明 如果P k i 实施变异算子(4) 或(5) 操作, 则令 χ(P -k i )= 1,否则令 χ(P -k i )= 0,由算法步骤 5)和 步骤 6)及式(8)有 pr(χ( P -k+1 g ) = 1) = α,pr(χ( P -k+1 g ) = 0) = 1 - α 于是 pr(P k+1 g ∈ Bε | Φk = Φ) ≥ pr(χ( P -k+1 g ) = 1)· pr((P k+1 g ∈ Bε | Φk = Φ) | χ( P -k+1 g ) = 1) = α·pr((P k+1 g ∈ Bε | Φk = Φ) | χ( P -k+1 g ) = 1) = α·pr(P k+1 g (new) ∈ Bε | Φk = Φ) 由引理 2 有 pr(P k+1 g ∈Bε | Φk = Φ) ≥α·pr(P -k+1 g ∈Bε | Φk = Φ) 由于P -k+1 g 的每个分量是独立的,再由式(5)知, 随机变量P -k+1 g 的密度函数为 g(x1,x2,…,xD) = 1 2πσρ2 æ è ç ö ø ÷ D exp( - ∑ D d = 1 (xd - p k+1 gd ) 2 2σ 2 ρ 2 2 ) 于是 pr( p -k+1 g ∈ Bε Φk = Φ) = ∫ Bε g(x1 ,x2 ,…,xD)dx1 dx2…dxD ≥ 1 2πσmax ρ2 æ è ç ö ø ÷ D exp( - D 2m 2 σmin 2 ρ 2 2 )μ(Bε ) 式中 m = max 1≤i≤D { | l i | , | ui | }。 令 ρ = 1 2πσmax ρ2 æ è ç ö ø ÷ D exp(-D 2m 2 σmin 2 ρ 2 2 )μ(Bε ),则 pr(P k+1 g ∈ Bε | Φk = Φ) ≥ ρ > 0。 定理 1 设(Φ1 ,Φ2 ,Φ3 ,…)∈Ω 是由算法任意 生成的状态序列,则序列 p k g { } 依概率 1 收敛到 ε⁃最 优解,即 lim k→¥ pr{p k g ∈ Bε } = 1 证明 由算法可知,Φk+1只与Φk 有关,所以Φ1 , Φ2 ,Φ3 ,…是马尔可夫过程,由马尔可夫过程性质及 引理 1 可知 pr(P k+1 g ∉ Bε ) = pr(P 1 g ∉ Bε )· ∏ k t = 1 pr(P t+1 g ∉ Bε P t g ∉ Bε ) ≤ ∏ k t = 1 pr(P t+1 g ∉ Bε P t g ∉ Bε ) 第 4 期 钱伟懿,等:依概率收敛的改进粒子群优化算法 ·513·
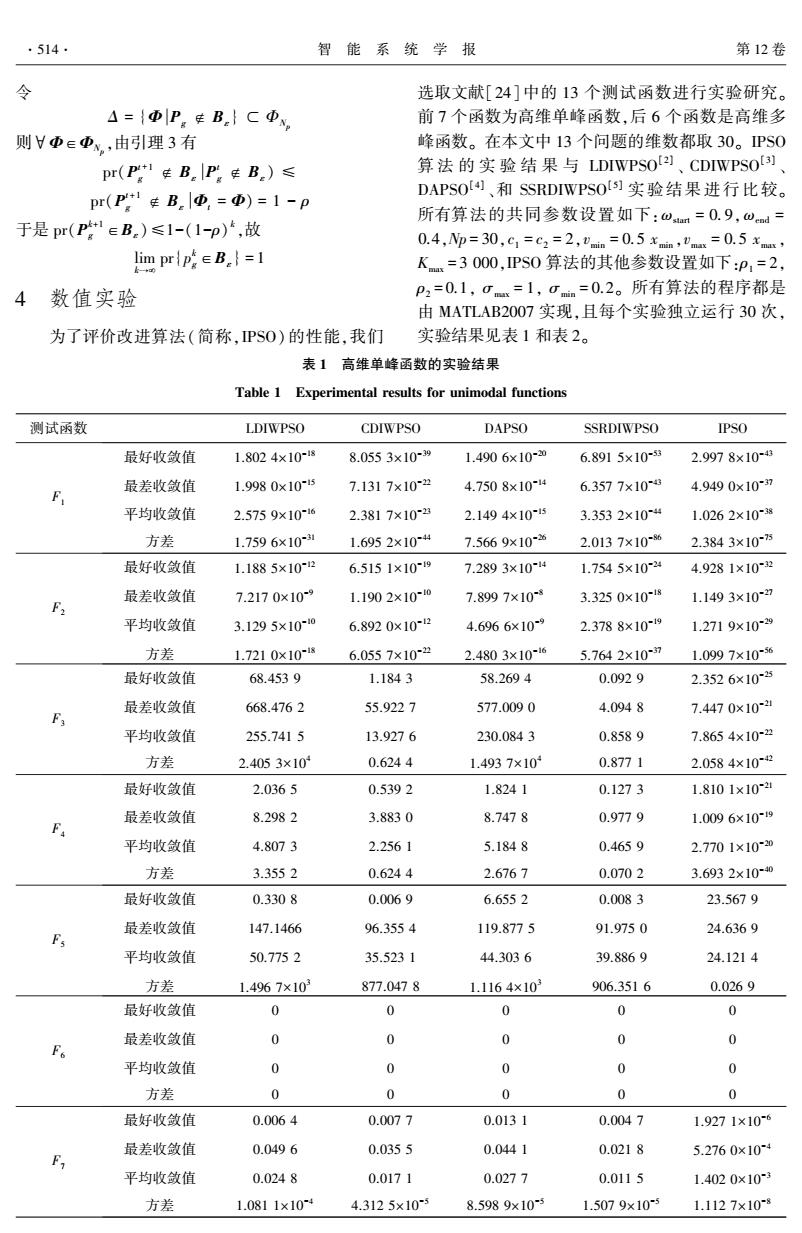
,514 智能系统学报 第12卷 令 选取文献[24]中的13个测试函数进行实验研究。 △={ΦP.EB}CΦy 前7个函数为高维单峰函数,后6个函数是高维多 则HΦ∈中,由引理3有 峰函数。在本文中13个问题的维数都取30。PS0 pr(P”生BlP生B)≤ 算法的实验结果与LDIWPSO2]、CDIWPSO) pr(P生B|④,=D)=1-p DAPSO[4、和SSRDIWPSOL]实验结果进行比较。 所有算法的共同参数设置如下:oam=0.9,ωmd= 于是pr(PeB)≤1-(1-p),故 0.4,p=30,G1=c2=2,"n=0.5xin,"m.=0.5x, lim pripB=1 Km=3000,PS0算法的其他参数设置如下:P,=2, 数值实验 P2=0.1,0mx=1,0mm=0.2。所有算法的程序都是 由MATLAB2007实现,且每个实验独立运行30次, 为了评价改进算法(简称,PS0)的性能,我们 实验结果见表1和表2。 表1 高维单峰函数的实验结果 Table 1 Experimental results for unimodal functions 测试函数 LDIWPSO CDIWPSO DAPSO SSRDIWPSO IPSO 最好收敛值 1.8024×1018 8.0553×10~39 1.4906x10-20 6.8915x10-8 2.9978×1048 最差收敛值 1.9980x105 7.1317×102 4.7508×1014 6.3577×108 4.9490×10~37 平均收敛值 2.5759×10-16 2.3817×10-2 2.1494×10-15 3.3532×104 1.0262×10~8 方差 1.7596x1031 1.6952×104 7.5669x10-2 2.0137×10-6 2.3843×105 最好收敛值 1.1885×1012 6.5151×109 7.2893×1014 1.7545×1024 4.9281×1032 最差收敛值 7.2170×109 1.1902×10~0 7.8997×10 3.3250×1018 1.1493×10 平均收敛值 3.1295×100 6.8920x102 4.6966×109 2.3788×1019 1.2719x1029 方差 1.7210×10~ 6.0557x102 2.4803×10~16 5.7642×107 1.0997×10~56 最好收敛值 68.4539 1.1843 58.2694 0.0929 2.3526×1025 最差收敛值 668.4762 55.9227 577.0090 4.0948 7.4470×10 平均收敛值 255.7415 13.9276 230.0843 0.8589 7.8654×10-2 方差 2.4053×10 0.6244 1.4937×10 0.8771 2.0584×10 最好收敛值 2.0365 0.5392 1.8241 0.1273 1.8101×1024 最差收敛值 8.2982 3.8830 8.7478 0.9779 1.0096×10-9 平均收敛值 4.8073 2.2561 5.1848 0.4659 2.7701×1020 方差 3.3552 0.6244 2.6767 0.0702 3.6932×100 最好收敛值 0.3308 0.0069 6.6552 0.0083 23.5679 最差收敛值 147.1466 96.3554 119.8775 91.9750 24.6369 平均收敛值 50.7752 35.5231 44.3036 39.8869 24.1214 方差 1.4967×103 877.0478 1.1164×103 906.3516 0.0269 最好收敛值 0 0 0 0 0 最差收敛值 0 0 0 0 0 平均收敛值 0 0 0 0 0 方差 0 0 0 0 0 最好收敛值 0.0064 0.0077 0.0131 0.0047 1.9271×106 最差收敛值 0.0496 0.0355 0.0441 0.0218 5.2760×104 平均收敛值 0.0248 0.0171 0.0277 0.0115 1.4020×10-3 方差 1.0811×10 4.3125×10 8.5989x10 1.5079×10 1.1127×108
令 Δ = {Φ Pg ∉ Bε } ⊂ ΦNp 则∀Φ∈ΦNp ,由引理 3 有 pr(P t+1 g ∉ Bε P t g ∉ Bε ) ≤ pr(P t+1 g ∉ Bε Φt = Φ) = 1 - ρ 于是 pr(P k+1 g ∈Bε )≤1-(1-ρ) k ,故 lim k→¥ pr{p k g∈Bε } = 1 4 数值实验 为了评价改进算法(简称,IPSO) 的性能,我们 选取文献[24]中的 13 个测试函数进行实验研究。 前 7 个函数为高维单峰函数,后 6 个函数是高维多 峰函数。 在本文中 13 个问题的维数都取 30。 IPSO 算 法 的 实 验 结 果 与 LDIWPSO [2] 、 CDIWPSO [3] 、 DAPSO [4] 、和 SSRDIWPSO [5] 实验结果进行比较。 所有算法的共同参数设置如下:ωstart = 0. 9,ωend = 0.4,Np = 30,c1 = c2 = 2,vmin = 0.5 xmin ,vmax = 0.5 xmax, Kmax = 3 000,IPSO 算法的其他参数设置如下:ρ1 = 2, ρ2 = 0.1, σmax = 1, σmin = 0.2。 所有算法的程序都是 由 MATLAB2007 实现,且每个实验独立运行 30 次, 实验结果见表 1 和表 2。 表 1 高维单峰函数的实验结果 Table 1 Experimental results for unimodal functions 测试函数 LDIWPSO CDIWPSO DAPSO SSRDIWPSO IPSO F1 最好收敛值 1.802 4×10 -18 8.055 3×10 -39 1.490 6×10 -20 6.891 5×10 -53 2.997 8×10 -43 最差收敛值 1.998 0×10 -15 7.131 7×10 -22 4.750 8×10 -14 6.357 7×10 -43 4.949 0×10 -37 平均收敛值 2.575 9×10 -16 2.381 7×10 -23 2.149 4×10 -15 3.353 2×10 -44 1.026 2×10 -38 方差 1.759 6×10 -31 1.695 2×10 -44 7.566 9×10 -26 2.013 7×10 -86 2.384 3×10 -75 F2 最好收敛值 1.188 5×10 -12 6.515 1×10 -19 7.289 3×10 -14 1.754 5×10 -24 4.928 1×10 -32 最差收敛值 7.217 0×10 -9 1.190 2×10 -10 7.899 7×10 -8 3.325 0×10 -18 1.149 3×10 -27 平均收敛值 3.129 5×10 -10 6.892 0×10 -12 4.696 6×10 -9 2.378 8×10 -19 1.271 9×10 -29 方差 1.721 0×10 -18 6.055 7×10 -22 2.480 3×10 -16 5.764 2×10 -37 1.099 7×10 -56 F3 最好收敛值 68.453 9 1.184 3 58.269 4 0.092 9 2.352 6×10 -25 最差收敛值 668.476 2 55.922 7 577.009 0 4.094 8 7.447 0×10 -21 平均收敛值 255.741 5 13.927 6 230.084 3 0.858 9 7.865 4×10 -22 方差 2.405 3×10 4 0.624 4 1.493 7×10 4 0.877 1 2.058 4×10 -42 F4 最好收敛值 2.036 5 0.539 2 1.824 1 0.127 3 1.810 1×10 -21 最差收敛值 8.298 2 3.883 0 8.747 8 0.977 9 1.009 6×10 -19 平均收敛值 4.807 3 2.256 1 5.184 8 0.465 9 2.770 1×10 -20 方差 3.355 2 0.624 4 2.676 7 0.070 2 3.693 2×10 -40 F5 最好收敛值 0.330 8 0.006 9 6.655 2 0.008 3 23.567 9 最差收敛值 147.1466 96.355 4 119.877 5 91.975 0 24.636 9 平均收敛值 50.775 2 35.523 1 44.303 6 39.886 9 24.121 4 方差 1.496 7×10 3 877.047 8 1.116 4×10 3 906.351 6 0.026 9 F6 最好收敛值 0 0 0 0 0 最差收敛值 0 0 0 0 0 平均收敛值 0 0 0 0 0 方差 0 0 0 0 0 F7 最好收敛值 0.006 4 0.007 7 0.013 1 0.004 7 1.927 1×10 -6 最差收敛值 0.049 6 0.035 5 0.044 1 0.021 8 5.276 0×10 -4 平均收敛值 0.024 8 0.017 1 0.027 7 0.011 5 1.402 0×10 -3 方差 1.081 1×10 -4 4.312 5×10 -5 8.598 9×10 -5 1.507 9×10 -5 1.112 7×10 -8 ·514· 智 能 系 统 学 报 第 12 卷
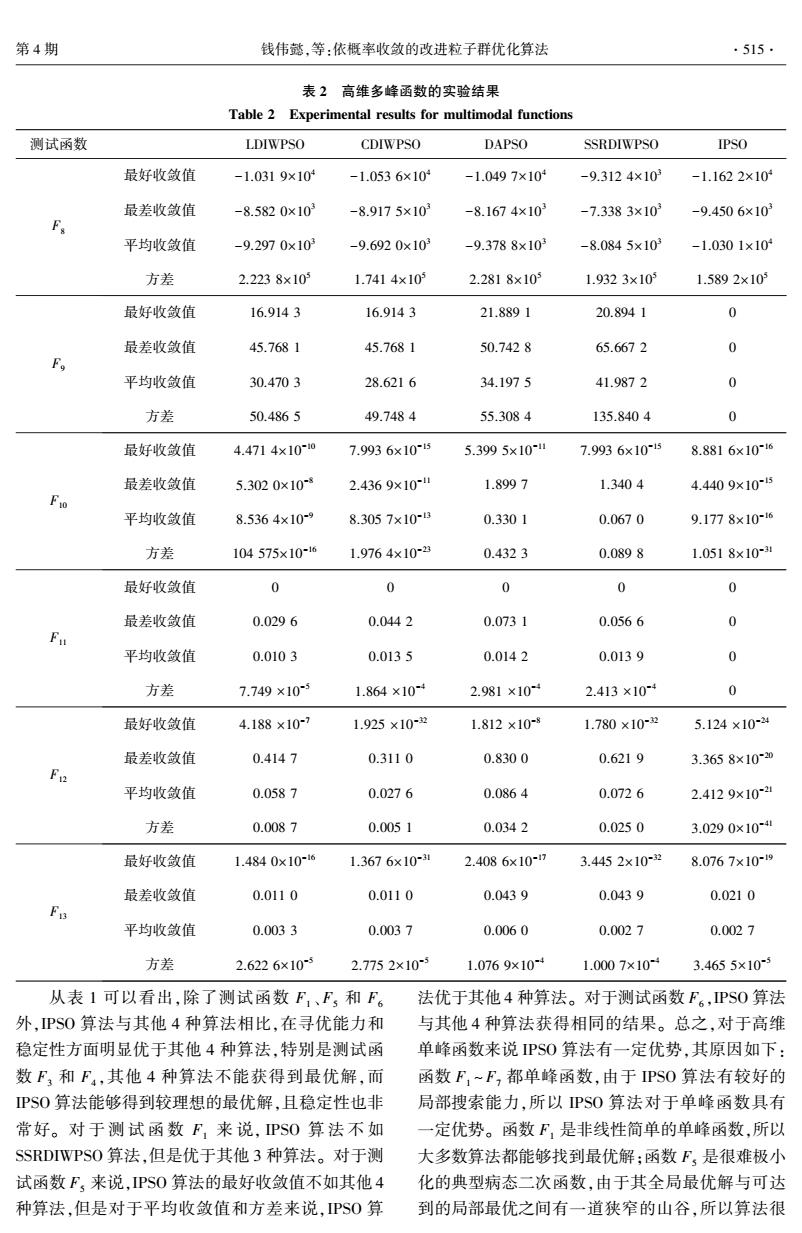
第4期 钱伟懿,等:依概率收敛的改进粒子群优化算法 ·515 表2高维多峰函数的实验结果 Table 2 Experimental results for multimodal functions 测试函数 LDIWPSO CDIWPSO DAPSO SSRDIWPSO IPSO 最好收敛值 -1.0319×10 -1.0536×10 -1.0497×104 -9.3124×103 -1.1622×10 最差收敛值 -8.5820×103 -8.9175×103 -8.1674×103 -7.3383×10 -9.4506×10 平均收敛值 -9.2970×10 -9.6920x10 -9.3788×103 -8.0845×103 -1.0301×10 方差 2.2238×10 1.7414×105 2.2818×105 1.9323×10 1.5892×10 最好收敛值 16.9143 16.9143 21.8891 20.8941 0 最差收敛值 45.7681 45.7681 50.7428 65.6672 0 平均收敛值 30.4703 28.6216 34.1975 41.9872 0 方差 50.4865 49.7484 55.3084 135.8404 0 最好收敛值 4.4714×100 7.9936×10-5 5.3995×10-11 7.9936×105 8.8816×10-6 最差收敛值 5.3020×10 2.4369×10" 1.8997 1.3404 4.4409×105 平均收敛值 8.5364×10-9 8.3057×10B 0.3301 0.0670 9.1778×10-16 方差 104575×10-16 1.9764×10-23 0.4323 0.0898 1.0518×10-31 最好收敛值 0 0 0 0 最差收敛值 0.0296 0.0442 0.0731 0.0566 0 平均收敛值 0.0103 0.0135 0.0142 0.0139 0 方差 7.749×105 1.864×10 2.981×10 2.413×10 0 最好收敛值 4.188×10-7 1.925×10-2 1.812×10 1.780×102 5.124×10-24 最差收敛值 0.4147 0.3110 0.8300 0.6219 3.3658×10-20 平均收敛值 0.0587 0.0276 0.0864 0.0726 2.4129×10-21 方差 0.0087 0.0051 0.0342 0.0250 3.0290×104 最好收敛值 1.4840×10-6 1.3676×10- 2.4086x10-7 3.4452×10-2 8.0767×10~9 最差收敛值 0.0110 0.0110 0.0439 0.0439 0.0210 平均收敛值 0.0033 0.0037 0.0060 0.0027 0.0027 方差 2.6226×10 2.7752×10 1.0769x10+ 1.0007×104 3.4655×10 从表1可以看出,除了测试函数F,、F,和F 法优于其他4种算法。对于测试函数F。,PS0算法 外,PS0算法与其他4种算法相比,在寻优能力和 与其他4种算法获得相同的结果。总之,对于高维 稳定性方面明显优于其他4种算法,特别是测试函 单峰函数来说PSO算法有一定优势,其原因如下: 数F,和F4,其他4种算法不能获得到最优解,而 函数F,~F,都单峰函数,由于PS0算法有较好的 PSO算法能够得到较理想的最优解,且稳定性也非 局部搜索能力,所以PS0算法对于单峰函数具有 常好。对于测试函数F,来说,PS0算法不如 一定优势。函数F,是非线性简单的单峰函数,所以 SSRDIWPS0算法,但是优于其他3种算法。对于测 大多数算法都能够找到最优解:函数F,是很难极小 试函数F,来说,IPS0算法的最好收敛值不如其他4 化的典型病态二次函数,由于其全局最优解与可达 种算法,但是对于平均收敛值和方差来说,PS0算 到的局部最优之间有一道狭窄的山谷,所以算法很
表 2 高维多峰函数的实验结果 Table 2 Experimental results for multimodal functions 测试函数 LDIWPSO CDIWPSO DAPSO SSRDIWPSO IPSO F8 最好收敛值 -1.031 9×10 4 -1.053 6×10 4 -1.049 7×10 4 -9.312 4×10 3 -1.162 2×10 4 最差收敛值 -8.582 0×10 3 -8.917 5×10 3 -8.167 4×10 3 -7.338 3×10 3 -9.450 6×10 3 平均收敛值 -9.297 0×10 3 -9.692 0×10 3 -9.378 8×10 3 -8.084 5×10 3 -1.030 1×10 4 方差 2.223 8×10 5 1.741 4×10 5 2.281 8×10 5 1.932 3×10 5 1.589 2×10 5 F9 最好收敛值 16.914 3 16.914 3 21.889 1 20.894 1 0 最差收敛值 45.768 1 45.768 1 50.742 8 65.667 2 0 平均收敛值 30.470 3 28.621 6 34.197 5 41.987 2 0 方差 50.486 5 49.748 4 55.308 4 135.840 4 0 F10 最好收敛值 4.471 4×10 -10 7.993 6×10 -15 5.399 5×10 -11 7.993 6×10 -15 8.881 6×10 -16 最差收敛值 5.302 0×10 -8 2.436 9×10 -11 1.899 7 1.340 4 4.440 9×10 -15 平均收敛值 8.536 4×10 -9 8.305 7×10 -13 0.330 1 0.067 0 9.177 8×10 -16 方差 104 575×10 -16 1.976 4×10 -23 0.432 3 0.089 8 1.051 8×10 -31 F11 最好收敛值 0 0 0 0 0 最差收敛值 0.029 6 0.044 2 0.073 1 0.056 6 0 平均收敛值 0.010 3 0.013 5 0.014 2 0.013 9 0 方差 7.749 ×10 -5 1.864 ×10 -4 2.981 ×10 -4 2.413 ×10 -4 0 F12 最好收敛值 4.188 ×10 -7 1.925 ×10 -32 1.812 ×10 -8 1.780 ×10 -32 5.124 ×10 -24 最差收敛值 0.414 7 0.311 0 0.830 0 0.621 9 3.365 8×10 -20 平均收敛值 0.058 7 0.027 6 0.086 4 0.072 6 2.412 9×10 -21 方差 0.008 7 0.005 1 0.034 2 0.025 0 3.029 0×10 -41 F13 最好收敛值 1.484 0×10 -16 1.367 6×10 -31 2.408 6×10 -17 3.445 2×10 -32 8.076 7×10 -19 最差收敛值 0.011 0 0.011 0 0.043 9 0.043 9 0.021 0 平均收敛值 0.003 3 0.003 7 0.006 0 0.002 7 0.002 7 方差 2.622 6×10 -5 2.775 2×10 -5 1.076 9×10 -4 1.000 7×10 -4 3.465 5×10 -5 从表 1 可以看出,除了测试函数 F1 、F5 和 F6 外,IPSO 算法与其他 4 种算法相比,在寻优能力和 稳定性方面明显优于其他 4 种算法,特别是测试函 数 F3 和 F4 ,其他 4 种算法不能获得到最优解,而 IPSO 算法能够得到较理想的最优解,且稳定性也非 常好。 对 于 测 试 函 数 F1 来 说, IPSO 算 法 不 如 SSRDIWPSO 算法,但是优于其他 3 种算法。 对于测 试函数 F5 来说,IPSO 算法的最好收敛值不如其他 4 种算法,但是对于平均收敛值和方差来说,IPSO 算 法优于其他 4 种算法。 对于测试函数 F6 ,IPSO 算法 与其他 4 种算法获得相同的结果。 总之,对于高维 单峰函数来说 IPSO 算法有一定优势,其原因如下: 函数 F1 ~ F7 都单峰函数,由于 IPSO 算法有较好的 局部搜索能力,所以 IPSO 算法对于单峰函数具有 一定优势。 函数 F1 是非线性简单的单峰函数,所以 大多数算法都能够找到最优解;函数 F5 是很难极小 化的典型病态二次函数,由于其全局最优解与可达 到的局部最优之间有一道狭窄的山谷,所以算法很 第 4 期 钱伟懿,等:依概率收敛的改进粒子群优化算法 ·515·