
第12卷第4期 智能系统学报 Vol.12 No.4 2017年8月 CAAI Transactions on Intelligent Systems Aug.2017 D0I:10.11992/is.201608010 基于分类词典的文本相似性度量方法 李海林,邹金串2 (1.华侨大学信息管理系,福建泉州362021:2.华侨大学现代应用统计与大数据研究中心,福建厦门361021) 摘要:针对现有基于语义知识规则分析的文本相似性度量方法存在时间复杂度高的局限性,提出基于分类词典的 文本相似性度量方法。利用汉语词法分析系统ICTCLAS对文本分词,运用TF×DF方法提取文本关键词,遍历分类 词典获取关键词编码,通过计算文本关键词编码的近似性来衡量原始文本之间的相似度。选取基于语义知识规则 和基于统计两个类别的相似性度量方法作为对比方法,通过传统聚类与KNN分类分别对相似性度量方法进行效果 验证。数值实验结果表明,新方法在聚类与分类实验中均能取得较好的实验结果,相较于其他基于语义分析的相似 性度量方法还具有良好的时间效率。 关键词:文本挖掘;语义分析;分类词典;关键词提取;词语编码;相似性度量;聚类;分类 中图分类号:TP301文献标志码:A文章编号:1673-4785(2017)04-0556-07 中文引用格式:李海林,邹金串.基于分类词典的文本相似性度量方法[J].智能系统学报,2017,12(4):556-562. 英文引用格式:LI Hailin,ZOU Jinchuan..Text similarity measure method based on classified dictionary[J].CAAI transactions on intelligent systems,2017,12(4):556-562. Text similarity measure method based on classified dictionary LI Hailin',ZOU Jinchuan2 (1.Department of Information Systems,Huaqiao University,Quanzhou 362021,China;2.Research Center of Applied Statistics and Big Data,Huaqiao University,Xiamen 361021,China) Abstract:Existing text-similarity measurement methods based on the semantic knowledge rules analysis have the limitation of high time complexity.In this paper,we propose a text-similarity measurement method based on the Classified Dictionary.First,we segmented texts using the Chinese Lexical Analysis System.Then,we extracted text keywords using the term frequency-inverse document frequency (tf idf)method and performed keywords coding by traversing the dictionary.By calculating the coding similarity of the text keywords,we can determine the similarity of the original texts.As our two comparison methods,we selected similarity measurement methods based on semantic knowledge rules and statistics.We verified our similarity measurement results using traditional clustering algorithms and the k-nearest neighbors classification method.Our numerical results show that our proposed method can obtain relatively good results in clustering and classification experiments.In addition, compared with other semantic analysis measurement methods,this method has better time efficiency. Keywords:data mining;semantic analysis;classified dictionary;keywords extraction;encoder;similarity measure; clustering;classification 大数据时代,相似性度量方法通常作为数据挖 挖掘技术与方法通常用于处理与分析非结构化文 掘任务的基础,使得相应的算法和技术能够在复杂 本数据,其中相似性度量质量的好坏将很大程度上 数据中发现具有潜在价值的信息与知识】,文本 影响文本挖掘质量和效率,与文本相关的数据挖掘 任务结合,也广泛存在于现实应用中,例如聚类与 收稿日期:2016-08-30. 分类、信息检索、机器学习、网络信息认定[到与人工 基金项目:国家自然科学基金项目(61300139):福建省自然科学基金项 智能等文本信息处理。 目(2015J01581):华侨大学中青年教师科研提升计划项目 (ZQN-PY220):华侨大学研究生科研创新能力培育计划项 根据文献[4]中提到的概念层次理论,文本相 目(1511307006). 通信作者:邹金串.E-mail:Zou_jinchuan@163.com. 似性度量建立在句子相似性度量之上,句子相似性
第 12 卷第 4 期 智 能 系 统 学 报 Vol.12 №.4 2017 年 8 月 CAAI Transactions on Intelligent Systems Aug. 2017 DOI:10.11992 / tis.201608010 基于分类词典的文本相似性度量方法 李海林1 ,邹金串2 (1.华侨大学 信息管理系,福建 泉州 362021; 2.华侨大学 现代应用统计与大数据研究中心,福建 厦门 361021) 摘 要:针对现有基于语义知识规则分析的文本相似性度量方法存在时间复杂度高的局限性,提出基于分类词典的 文本相似性度量方法。 利用汉语词法分析系统 ICTCLAS 对文本分词,运用 TF×IDF 方法提取文本关键词,遍历分类 词典获取关键词编码,通过计算文本关键词编码的近似性来衡量原始文本之间的相似度。 选取基于语义知识规则 和基于统计两个类别的相似性度量方法作为对比方法,通过传统聚类与 KNN 分类分别对相似性度量方法进行效果 验证。 数值实验结果表明,新方法在聚类与分类实验中均能取得较好的实验结果,相较于其他基于语义分析的相似 性度量方法还具有良好的时间效率。 关键词:文本挖掘;语义分析;分类词典;关键词提取;词语编码;相似性度量;聚类;分类 中图分类号:TP301 文献标志码:A 文章编号:1673-4785(2017)04-0556-07 中文引用格式:李海林,邹金串.基于分类词典的文本相似性度量方法[J]. 智能系统学报, 2017, 12(4): 556-562. 英文引用格式:LI Hailin, ZOU Jinchuan. Text similarity measure method based on classified dictionary[J]. CAAI transactions on intelligent systems, 2017, 12(4): 556-562. Text similarity measure method based on classified dictionary LI Hailin 1 , ZOU Jinchuan 2 (1. Department of Information Systems, Huaqiao University, Quanzhou 362021,China; 2.Research Center of Applied Statistics and Big Data, Huaqiao University, Xiamen 361021, China) Abstract:Existing text⁃similarity measurement methods based on the semantic knowledge rules analysis have the limitation of high time complexity. In this paper, we propose a text⁃similarity measurement method based on the Classified Dictionary. First, we segmented texts using the Chinese Lexical Analysis System. Then, we extracted text keywords using the term frequency⁃inverse document frequency (tf∗idf) method and performed keywords coding by traversing the dictionary. By calculating the coding similarity of the text keywords, we can determine the similarity of the original texts. As our two comparison methods, we selected similarity measurement methods based on semantic knowledge rules and statistics. We verified our similarity measurement results using traditional clustering algorithms and the k⁃nearest neighbors classification method. Our numerical results show that our proposed method can obtain relatively good results in clustering and classification experiments. In addition, compared with other semantic analysis measurement methods, this method has better time efficiency. Keywords: data mining; semantic analysis; classified dictionary; keywords extraction; encoder; similarity measure; clustering; classification 收稿日期:2016-08-30. 基金项目:国家自然科学基金项目(61300139);福建省自然科学基金项 目(2015J01581);华侨大学中青年教师科研提升计划项目 (ZQN-PY220);华侨大学研究生科研创新能力培育计划项 目(1511307006). 通信作者:邹金串.E⁃mail:Zou_jinchuan@ 163.com. 大数据时代,相似性度量方法通常作为数据挖 掘任务的基础, 使得相应的算法和技术能够在复杂 数据中发现具有潜在价值的信息与知识[1-2] ,文本 挖掘技术与方法通常用于处理与分析非结构化文 本数据,其中相似性度量质量的好坏将很大程度上 影响文本挖掘质量和效率,与文本相关的数据挖掘 任务结合,也广泛存在于现实应用中, 例如聚类与 分类、信息检索、机器学习、网络信息认定[3] 与人工 智能等文本信息处理。 根据文献[4] 中提到的概念层次理论,文本相 似性度量建立在句子相似性度量之上,句子相似性

第4期 李海林,等:基于分类词典的文本相似性度量方法 ·557. 度量进一步以词语的相似性为前提。因此,词语相 苏新春教授编写的《现代汉语分类词典》[1)与 似性度量结果的好坏直接影响文本相似性度量以 《同义词词林》在结构上具有相似性,但《现代汉语 及文本聚类、分类等后续文本挖掘任务与工作的 分类词典》对词语分类更细,词语间相似度只需通 质量。 过两个词语编码进行计算比较,相较于ZW_Sim方 词语相似度指在不同位置,词语可以互相替换 法,不需要对词语相似度进行分层计算,时间复杂 使用的程度,文本相似性度量通常分为基于语义知 度大大降低。基于距离的语义相似度计算主要包 识规则的相似性度量和基于统计的相似性度量。 括语义重合度(共同祖先节点数)、语义深度、语义 基于语义知识规则的文本相似度计算主要建立在 密度、语义距离等4个方面的度量。多级分类体系 基于Wordnets-)、MindNet)、FramNet[s劉等语义知 使得基于分类词典的相似性度量结果可以直接反 识库的基础上。20世纪90年代开始,涌现出大量 映两个词语在语义树中的重合度、深度与距离。在 基于Wordnet的语义相似度计算算法,主要针对外 此基础上,本文提出一种基于现代汉语分类词典的 文长文本的语义相似度计算。现有基于语义分 文本相似性度量方法(Similarity measure based on 析的中文文本相似性度量方法主要依托于同义词 Cidian,CD_Sim)。CD_Sim方法通过中科院研制出 词林o与知网山。刘群等以知网为依托,将词 的汉语词法分析系统对待分析文档进行分词等一 语相似性度量分为义原相似性度量、概念相似性度 系列基本处理,统计词语与文档间的词频矩阵,结 量和词语相似性度量3个步骤,并提出了基于知网 合T℉×DF算法构建词语文档的向量空间模型20, 的词语相似度计算方法(ZW_Sim)。由于该方法的 对向量空间模型进行标准化处理、排序等操作实现 适用性和有效性,部分学者在此基础上对该相似度 对文档的特征提取。通过AP聚类2)]、Kmeans聚 计算方法进行改进。林丽等1)在基于知网的词语 类[2]、谱聚类[2)3种聚类算法以及KNN分类(2]方 相似度计算中引入弱义原的概念,即通过计算除区 法对方法计算结果进行检验分析。方法理论简单 分能力弱的第一基本义原外的其他义原来计算词 易于应用,对降低同义词、同类词导致的误差有一 语相似度,以减少计算时间和提高计算精度:王小 定作用,在短文本相似度量应用中相较于基于统计 林[]在原始基于知网方法的基础上,改进不同类别 学的方法可以降低度量误差,相较于基于知识库的 义原在词语相似度计算中所占权重的计算方法提 方法简单易行。数值实验结果表明,CD_Sim方法 高计算精度,通过义项词性判断降低相似性计算复 在聚类与分类实验中均能取得较好的实验结果,证 杂度:张亮等[)利用知网,从义项的主类义原、主类 明了方法的可行性与度量效果。 义原框架和义项特性描述三方面综合分析词语相 1 相关理论基础 似度,并从语义特征相似度和句法特征相似度两方 面来描述词语相似度:田久乐等16]提出基于同义词 1.1现代汉语分类词典 词林的词语相似度计算方法(CL_Sim),并通过人工 我国现代汉语首部分类词典是《同义词词林》, 测试、非人工测试以及与ZW_Sim方法进行比较,证 按照词语的概义来对词语进行分类编排。但现在 明了方法的可行性;徐庆等)在此基础上对词语相 《同义词词林》一定程度上不能很好地反映当前语 似度计算公式进行改进,并将该方法应用于中文实 言现状。《现代汉语分类词典》在吸收前人成果的 体关系抽取,取得了较好的实验结果:郑红艳等[1劉 基础上,收录了8.3万条通用性词语,较《同义词词 将词林与TF×IDF方法相结合,过滤同义词并对词 林》新增常用词2.9万条,按五级语义层编排,包含 语权重赋值进行文本特征提取,新的方法具有更好 9个一级类,62个二级类,508个三级类,2057个四 的特征提取结果。各位学者将基于知网与词林的 级类,12659个五级类。 相似性度量方法在参数与时间复杂度方面不断完 《现代汉语分类词典》用5层编码代表分类词 善,使方法的准确性与时间效率都一定程度上有所 典的5层结构,例如“B03Cc04”是“灰浆”和“砂浆” 提高。基于语义知识库的相似性度量方法均需要 的编码,示例编码中各层编码意义如表1,表示“灰 对语义知识库多次遍历,各位学者虽不同程度提高 浆”和“砂浆”均是“具体物”类别下“材料”类别中 了方法的时间效率,但时间复杂度高的问题依然 “建筑材料”范畴内“水泥石灰沥青”小类中的“灰 存在。 浆”类别。若两个词语各级编码均相同,则二者是
度量进一步以词语的相似性为前提。 因此,词语相 似性度量结果的好坏直接影响文本相似性度量以 及文本聚类、分类等后续文本挖掘任务与工作的 质量。 词语相似度指在不同位置,词语可以互相替换 使用的程度,文本相似性度量通常分为基于语义知 识规则的相似性度量和基于统计的相似性度量。 基于语义知识规则的文本相似度计算主要建立在 基于 Wordnet [5-6] 、MindNet [7] 、 FramNet [8] 等语义知 识库的基础上。 20 世纪 90 年代开始,涌现出大量 基于 Wordnet 的语义相似度计算算法,主要针对外 文长文本的语义相似度计算[9] 。 现有基于语义分 析的中文文本相似性度量方法主要依托于同义词 词林[10]与知网[11] 。 刘群等[12] 以知网为依托,将词 语相似性度量分为义原相似性度量、概念相似性度 量和词语相似性度量 3 个步骤,并提出了基于知网 的词语相似度计算方法(ZW_Sim)。 由于该方法的 适用性和有效性,部分学者在此基础上对该相似度 计算方法进行改进。 林丽等[13] 在基于知网的词语 相似度计算中引入弱义原的概念,即通过计算除区 分能力弱的第一基本义原外的其他义原来计算词 语相似度,以减少计算时间和提高计算精度;王小 林[14]在原始基于知网方法的基础上,改进不同类别 义原在词语相似度计算中所占权重的计算方法提 高计算精度,通过义项词性判断降低相似性计算复 杂度;张亮等[15]利用知网,从义项的主类义原、主类 义原框架和义项特性描述三方面综合分析词语相 似度,并从语义特征相似度和句法特征相似度两方 面来描述词语相似度;田久乐等[16] 提出基于同义词 词林的词语相似度计算方法(CL_Sim),并通过人工 测试、非人工测试以及与 ZW_Sim 方法进行比较,证 明了方法的可行性;徐庆等[17]在此基础上对词语相 似度计算公式进行改进,并将该方法应用于中文实 体关系抽取,取得了较好的实验结果;郑红艳等[18] 将词林与 TF×IDF 方法相结合,过滤同义词并对词 语权重赋值进行文本特征提取,新的方法具有更好 的特征提取结果。 各位学者将基于知网与词林的 相似性度量方法在参数与时间复杂度方面不断完 善,使方法的准确性与时间效率都一定程度上有所 提高。 基于语义知识库的相似性度量方法均需要 对语义知识库多次遍历,各位学者虽不同程度提高 了方法的时间效率,但时间复杂度高的问题依然 存在。 苏新春教授编写的《现代汉语分类词典》 [19] 与 《同义词词林》在结构上具有相似性,但《现代汉语 分类词典》对词语分类更细,词语间相似度只需通 过两个词语编码进行计算比较,相较于 ZW_Sim 方 法,不需要对词语相似度进行分层计算,时间复杂 度大大降低。 基于距离的语义相似度计算主要包 括语义重合度(共同祖先节点数)、语义深度、语义 密度、语义距离等 4 个方面的度量。 多级分类体系 使得基于分类词典的相似性度量结果可以直接反 映两个词语在语义树中的重合度、深度与距离。 在 此基础上,本文提出一种基于现代汉语分类词典的 文本相似性度量方法( Similarity measure based on Cidian, CD_Sim)。 CD_Sim 方法通过中科院研制出 的汉语词法分析系统对待分析文档进行分词等一 系列基本处理,统计词语与文档间的词频矩阵,结 合 TF×IDF 算法构建词语文档的向量空间模型[20] , 对向量空间模型进行标准化处理、排序等操作实现 对文档的特征提取。 通过 AP 聚类[21] 、Kmeans 聚 类[22] 、谱聚类[23] 3 种聚类算法以及 KNN 分类[24] 方 法对方法计算结果进行检验分析。 方法理论简单、 易于应用,对降低同义词、同类词导致的误差有一 定作用,在短文本相似度量应用中相较于基于统计 学的方法可以降低度量误差,相较于基于知识库的 方法简单易行。 数值实验结果表明,CD_Sim 方法 在聚类与分类实验中均能取得较好的实验结果,证 明了方法的可行性与度量效果。 1 相关理论基础 1.1 现代汉语分类词典 我国现代汉语首部分类词典是《同义词词林》, 按照词语的概义来对词语进行分类编排。 但现在 《同义词词林》一定程度上不能很好地反映当前语 言现状。 《现代汉语分类词典》在吸收前人成果的 基础上,收录了 8.3 万条通用性词语,较《同义词词 林》新增常用词 2.9 万条,按五级语义层编排,包含 9 个一级类,62 个二级类,508 个三级类,2 057 个四 级类,12 659 个五级类。 《现代汉语分类词典》 用 5 层编码代表分类词 典的 5 层结构,例如“B03Cc04”是“灰浆”和“砂浆” 的编码,示例编码中各层编码意义如表 1,表示“灰 浆”和“砂浆”均是“具体物” 类别下“材料” 类别中 “建筑材料” 范畴内“水泥石灰沥青” 小类中的“灰 浆”类别。 若两个词语各级编码均相同,则二者是 第 4 期 李海林,等:基于分类词典的文本相似性度量方法 ·557·

·558. 智能系统学报 第12卷 同义词,相似度为1。 based on Cidian,CD_Sim)。方法侧重于词语相似度 表1分类词典编码方式示例 量方法的改进,最终应用于文本相似度量,且度量 Table 1 Example of coding method of classified dictionary 方法较基于统计学的方法可以一定程度降低同义 编码位 符号举例 类别名 级别 词、同类词导致的误差,故方法效果通过文本相似 B 具体物 第一级 度量结果进行对比衡量。方法以《现代汉语分类词 材料 典》作为语义知识库,以基于TF×IDF方法的向量空 2 3 第二级 间模型作为文本关键词提取依据,文本相似性度量 建筑材料 第三级 过程包括词语编码获取、词语相似度计算和文本相 4 水泥石灰沥青 第四级 似度计算3个步骤。 5 4 灰浆 第五级 2.1词语相似度计算 1.2 向量空间模型 基于语义知识库的词语相似度通常通过计算 向量空间模型是当前使用较多的文本表示方 义原相似度(ZW_Sim方法)或者词语编码相似度 法,向量空间矩阵为待分析文本样本词语-文档权 (CL_Sim方法)来计算。CD_Sim方法通过遍历分 重矩阵。假设待分析样本D中有n个文档d,(G=1, 类词典,在分类词典中搜索关键词,用该关键词在 2,…,n),用m个词语t,(i=1,2,…,m)在文档中出 分类词典中对应的编码替换关键词进行关键词相 现的频数组成的向量对一篇文档进行向量表示,根 似度计算。样本D中各文档以关键词编码集的形 据词语在该文档中出现的概率及在整个样本中出 式表示。 分类词典中每一个大类均可以看做一棵语义 现的概率对该特征词的重要性赋值权重,则样本 树,同一个节点下的叶子节点为同义词,且同义词 D表示为 编码相同。通常词语相似性通过其在语义树中的 1011 1012 位置进行度量计算,包括语义密度、语义深度、语义 1022 D'= 1021 心 (1) 重合度、语义距离四方面衡量。分类词典对所有词 语均采用5级分类,即所有词语语义深度相同,语义 102 重合度与语义距离可通过公式计算互换(见式 式中:心,表示第i个词语在第j篇文档中重要程度的 (8)),故可仅取其中一种衡量方式进行计算(涉及 权值。 时间复杂度,语义密度暂不考虑)。 词语权重的计算方法有多种,经典权重计算方 定义关键词A的编码为“a1a,aaa”,关键 法如TF×IDF算法: 词B的编码为“b,b2b3b,bs”,两关键词语义重合度计 0g=TFg×IDF (2) 算公式: 式中:TF,指特征词t,在文档d,中出现的次数Pg占 k,=A☒B= a,⑧6 (5) =1 文档d中总词数p:的比重: i=1时, TEy =Pa (3) 1,a:=b: Pi a:☒b:= (6) 0,a:≠b: DF,为逆文档频率,计算公式为 i>1时, IDF,=log(N) (4) 1,,a:=b:anda:-1☒b:-1=1 a:☒b:= (7) 式中:N为样本中文档总数,n:为样本中出现过特征 0, a:≠b: 词t的文档数。 任意两个编码(假设两编码前三位相同,后两 位不同)的语义重合度与语义距离在编码中可表示 2文本相似度计算 为式(8)形式: 针对目前基于语义知识规则的文本相似性度 a2 as 量方法存在计算过程中多次遍历语义知识库导致 0 0 0 ↓ (8) 方法时间复杂度高的局限性,提出了基于现代汉语 b: 分类词典的文本相似性度量方法(Similarity measure
同义词,相似度为 1。 表 1 分类词典编码方式示例 Table 1 Example of coding method of classified dictionary 编码位 符号举例 类别名 级别 1 B 具体物 第一级 2 3 材料 第二级 3 C 建筑材料 第三级 4 c 水泥石灰沥青 第四级 5 4 灰浆 第五级 1.2 向量空间模型 向量空间模型是当前使用较多的文本表示方 法,向量空间矩阵为待分析文本样本词语-文档权 重矩阵。 假设待分析样本 D 中有 n 个文档 dj(j = 1, 2,…,n),用 m 个词语 t i(i = 1,2,…,m)在文档中出 现的频数组成的向量对一篇文档进行向量表示,根 据词语在该文档中出现的概率及在整个样本中出 现的概率对该特征词的重要性赋值权重 wij,则样本 D 表示为 D′ = w11 w12 … w1j w21 w22 … w2j ︙ ︙ ︙ wi1 wi2 … wij é ë ê ê ê ê êê ù û ú ú ú ú úú (1) 式中:wij表示第 i 个词语在第 j 篇文档中重要程度的 权值。 词语权重的计算方法有多种,经典权重计算方 法如 TF×IDF 算法: wij = TFij × IDFi (2) 式中:TFij指特征词 t i 在文档 dj 中出现的次数 pij占 文档 dj 中总词数 pj 的比重: TFij = pij pj (3) IDFi 为逆文档频率,计算公式为 IDFi = log( N ni ) (4) 式中:N 为样本中文档总数,ni 为样本中出现过特征 词 t i 的文档数。 2 文本相似度计算 针对目前基于语义知识规则的文本相似性度 量方法存在计算过程中多次遍历语义知识库导致 方法时间复杂度高的局限性,提出了基于现代汉语 分类词典的文本相似性度量方法(Similarity measure based on Cidian, CD_Sim)。 方法侧重于词语相似度 量方法的改进,最终应用于文本相似度量,且度量 方法较基于统计学的方法可以一定程度降低同义 词、同类词导致的误差,故方法效果通过文本相似 度量结果进行对比衡量。 方法以《现代汉语分类词 典》作为语义知识库,以基于 TF×IDF 方法的向量空 间模型作为文本关键词提取依据,文本相似性度量 过程包括词语编码获取、词语相似度计算和文本相 似度计算 3 个步骤。 2.1 词语相似度计算 基于语义知识库的词语相似度通常通过计算 义原相似度( ZW_Sim 方法) 或者词语编码相似度 (CL_Sim 方法) 来计算。 CD_Sim 方法通过遍历分 类词典,在分类词典中搜索关键词,用该关键词在 分类词典中对应的编码替换关键词进行关键词相 似度计算。 样本 D 中各文档以关键词编码集的形 式表示。 分类词典中每一个大类均可以看做一棵语义 树,同一个节点下的叶子节点为同义词,且同义词 编码相同。 通常词语相似性通过其在语义树中的 位置进行度量计算,包括语义密度、语义深度、语义 重合度、语义距离四方面衡量。 分类词典对所有词 语均采用 5 级分类,即所有词语语义深度相同,语义 重合度与语义距离可通过公式计算互换 ( 见式 (8)),故可仅取其中一种衡量方式进行计算(涉及 时间复杂度,语义密度暂不考虑)。 定义 关键词 A 的编码为“ a1 a2 a3 a4 a5 ”,关键 词 B 的编码为“b1 b2 b3 b4 b5 ”,两关键词语义重合度计 算公式: k1 = A B = ∑ 5 i = 1 ai bi (5) i = 1 时, ai bi = 1, ai = bi 0, ai ≠ bi { (6) i>1 时, ai bi = 1, ai = bi and ai-1 bi-1 = 1 0, ai ≠ bi { (7) 任意两个编码(假设两编码前三位相同,后两 位不同)的语义重合度与语义距离在编码中可表示 为式(8)形式: a1⇔ b1 a2⇔ b2 a3⇔ b3 a4 ↓ b4 a5 b5 ← → (8) ·558· 智 能 系 统 学 报 第 12 卷
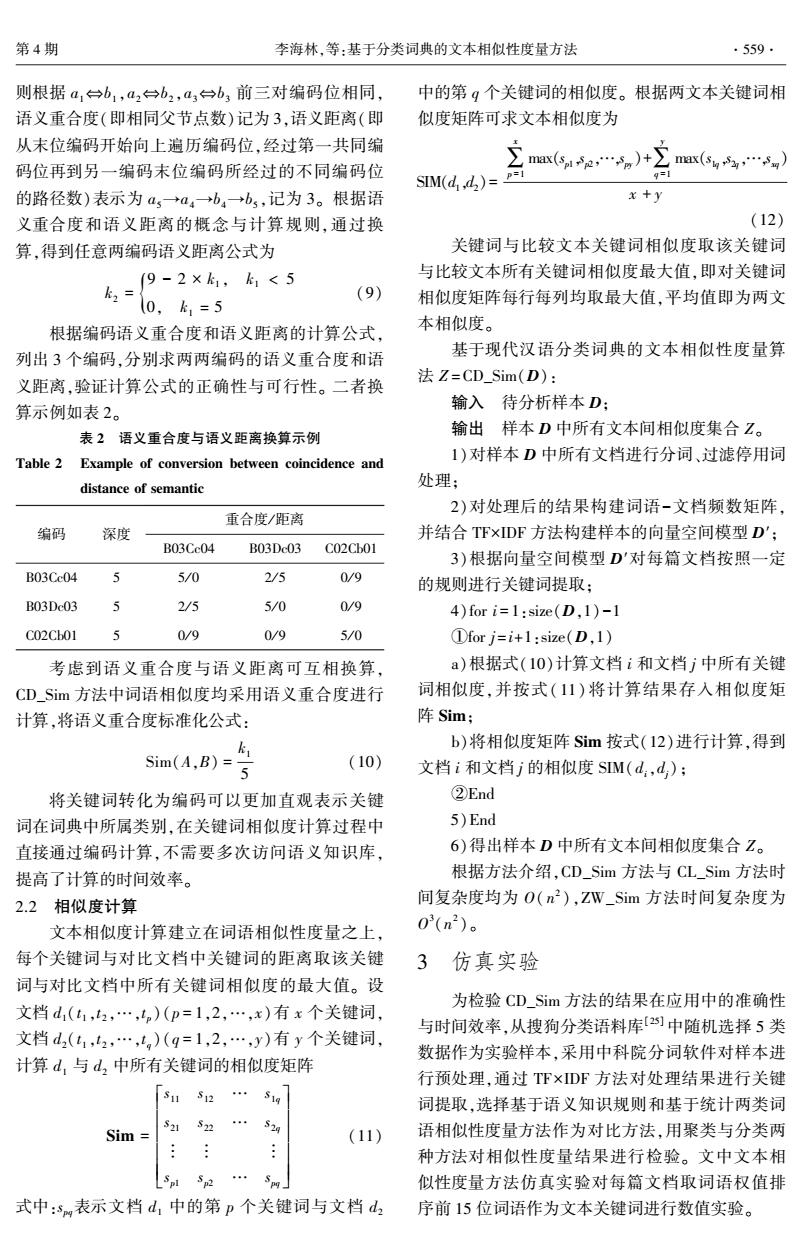
第4期 李海林,等:基于分类词典的文本相似性度量方法 ·559 则根据a,台b1,a2台b2,a3台b3前三对编码位相同, 中的第g个关键词的相似度。根据两文本关键词相 语义重合度(即相同父节点数)记为3,语义距离(即 似度矩阵可求文本相似度为 从末位编码开始向上遍历编码位,经过第一共同编 码位再到另一编码末位编码所经过的不同编码位 SM(d,42)= p=1 的路径数)表示为a,→a4→b4→b5,记为3。根据语 x+y 义重合度和语义距离的概念与计算规则,通过换 (12) 算,得到任意两编码语义距离公式为 关键词与比较文本关键词相似度取该关键词 (9-2×k1,k1<5 与比较文本所有关键词相似度最大值,即对关键词 k2= (9) (0,k1=5 相似度矩阵每行每列均取最大值,平均值即为两文 根据编码语义重合度和语义距离的计算公式, 本相似度。 列出3个编码,分别求两两编码的语义重合度和语 基于现代汉语分类词典的文本相似性度量算 义距离,验证计算公式的正确性与可行性。二者换 法Z=CD_Sim(D): 算示例如表2。 输入待分析样本D: 表2语义重合度与语义距离换算示例 输出样本D中所有文本间相似度集合Z。 Table 2 Example of conversion between coincidence and 1)对样本D中所有文档进行分词、过滤停用词 distance of semantic 处理; 2)对处理后的结果构建词语-文档频数矩阵, 重合度/距离 编码 深度 并结合TF×DF方法构建样本的向量空间模型D'; B03Cc04 B03Dc03 C02Cb01 3)根据向量空间模型D'对每篇文档按照一定 B03Cc04 5 5/0 2/5 0/9 的规则进行关键词提取; B03Dc03 2/5 5/0 0/9 4)for i=1:size(D,1)-1 C02Cbo1 5 0/9 0/9 5/0 ①forj=i+1:size(D,1) 考虑到语义重合度与语义距离可互相换算, a)根据式(10)计算文档i和文档j中所有关键 CD_Sim方法中词语相似度均采用语义重合度进行 词相似度,并按式(11)将计算结果存入相似度矩 计算,将语义重合度标准化公式: 阵Sim; b)将相似度矩阵Sim按式(12)进行计算,得到 Sim(A,B)= (10) 文档i和文档j的相似度SM(d:,d;): 将关键词转化为编码可以更加直观表示关键 ②End 词在词典中所属类别,在关键词相似度计算过程中 5)End 直接通过编码计算,不需要多次访问语义知识库, 6)得出样本D中所有文本间相似度集合Z。 提高了计算的时间效率。 根据方法介绍,CD_Sim方法与CL_Sim方法时 2.2相似度计算 间复杂度均为O(n2),ZW_Sim方法时间复杂度为 文本相似度计算建立在词语相似性度量之上, 03(n2)。 每个关键词与对比文档中关键词的距离取该关键 3仿真实验 词与对比文档中所有关键词相似度的最大值。设 为检验CD_Sim方法的结果在应用中的准确性 文档d1(1,2,…,lp)(p=1,2,…,x)有x个关键词, 与时间效率,从搜狗分类语料库2]中随机选择5类 文档d2(1,42,…,l)(9=1,2,…,y)有y个关键词, 数据作为实验样本,采用中科院分词软件对样本进 计算d,与d,中所有关键词的相似度矩阵 行预处理,通过T℉×DF方法对处理结果进行关键 S11 512.S1g 词提取,选择基于语义知识规则和基于统计两类词 S22 Sim= S21 52g (11) 语相似性度量方法作为对比方法,用聚类与分类两 种方法对相似性度量结果进行检验。文中文本相 似性度量方法仿真实验对每篇文档取词语权值排 式中:s表示文档d,中的第p个关键词与文档d 序前15位词语作为文本关键词进行数值实验
则根据 a1⇔b1 ,a2⇔b2 ,a3⇔b3 前三对编码位相同, 语义重合度(即相同父节点数)记为 3,语义距离(即 从末位编码开始向上遍历编码位,经过第一共同编 码位再到另一编码末位编码所经过的不同编码位 的路径数)表示为 a5→a4→b4→b5 ,记为 3。 根据语 义重合度和语义距离的概念与计算规则,通过换 算,得到任意两编码语义距离公式为 k2 = 9 - 2 × k1 , k1 < 5 0, k1 = 5 { (9) 根据编码语义重合度和语义距离的计算公式, 列出 3 个编码,分别求两两编码的语义重合度和语 义距离,验证计算公式的正确性与可行性。 二者换 算示例如表 2。 表 2 语义重合度与语义距离换算示例 Table 2 Example of conversion between coincidence and distance of semantic 编码 深度 重合度/ 距离 B03Cc04 B03Dc03 C02Cb01 B03Cc04 5 5 / 0 2 / 5 0 / 9 B03Dc03 5 2 / 5 5 / 0 0 / 9 C02Cb01 5 0 / 9 0 / 9 5 / 0 考虑到语义重合度与语义距离可互相换算, CD_Sim 方法中词语相似度均采用语义重合度进行 计算,将语义重合度标准化公式: Sim(A,B) = k1 5 (10) 将关键词转化为编码可以更加直观表示关键 词在词典中所属类别,在关键词相似度计算过程中 直接通过编码计算,不需要多次访问语义知识库, 提高了计算的时间效率。 2.2 相似度计算 文本相似度计算建立在词语相似性度量之上, 每个关键词与对比文档中关键词的距离取该关键 词与对比文档中所有关键词相似度的最大值。 设 文档 d1(t 1 ,t 2 ,…,t p)(p = 1,2,…,x)有 x 个关键词, 文档 d2(t 1 ,t 2 ,…,t q)(q = 1,2,…,y)有 y 个关键词, 计算 d1 与 d2 中所有关键词的相似度矩阵 Sim = s11 s12 … s1q s21 s22 … s2q ︙ ︙ ︙ sp1 sp2 … spq é ë ê ê ê ê êê ù û ú ú ú ú úú (11) 式中:spq表示文档 d1 中的第 p 个关键词与文档 d2 中的第 q 个关键词的相似度。 根据两文本关键词相 似度矩阵可求文本相似度为 SIM(d1,d2)= ∑ x p =1 max(sp1,sp2,…,spy)+∑ y q =1 max(s1q,s2q,…,sxq) x + y (12) 关键词与比较文本关键词相似度取该关键词 与比较文本所有关键词相似度最大值,即对关键词 相似度矩阵每行每列均取最大值,平均值即为两文 本相似度。 基于现代汉语分类词典的文本相似性度量算 法 Z =CD_Sim(D): 输入 待分析样本 D; 输出 样本 D 中所有文本间相似度集合 Z。 1)对样本 D 中所有文档进行分词、过滤停用词 处理; 2)对处理后的结果构建词语-文档频数矩阵, 并结合 TF×IDF 方法构建样本的向量空间模型 D′; 3)根据向量空间模型 D′对每篇文档按照一定 的规则进行关键词提取; 4)for i = 1:size(D,1)-1 ①for j = i+1:size(D,1) a)根据式(10)计算文档 i 和文档 j 中所有关键 词相似度,并按式(11) 将计算结果存入相似度矩 阵 Sim; b)将相似度矩阵 Sim 按式(12)进行计算,得到 文档 i 和文档 j 的相似度 SIM(di,dj); ②End 5)End 6)得出样本 D 中所有文本间相似度集合 Z。 根据方法介绍,CD_Sim 方法与 CL_Sim 方法时 间复杂度均为 O( n 2 ),ZW_Sim 方法时间复杂度为 O 3 (n 2 )。 3 仿真实验 为检验 CD_Sim 方法的结果在应用中的准确性 与时间效率,从搜狗分类语料库[25] 中随机选择 5 类 数据作为实验样本,采用中科院分词软件对样本进 行预处理,通过 TF×IDF 方法对处理结果进行关键 词提取,选择基于语义知识规则和基于统计两类词 语相似性度量方法作为对比方法,用聚类与分类两 种方法对相似性度量结果进行检验。 文中文本相 似性度量方法仿真实验对每篇文档取词语权值排 序前 15 位词语作为文本关键词进行数值实验。 第 4 期 李海林,等:基于分类词典的文本相似性度量方法 ·559·

·560 智能系统学报 第12卷 3.1实验数据与实验设计 算法,K值取[10,20,…,100]这10组数据值进行实 实验语料数据选自搜狗实验室提供的搜狗分 验,每种聚类检验方法中均取熵值最小且纯净度最 类语料库,该语料库包含了环境、计算机、交通、教 高的实验结果作为基于LSA的相似性度量算法的 育、经济、军事、体育、医药、艺术和政治10个类别文 实验结果。 本文档。 根据聚类实验结果分析,对4种相似性度量方 数值实验选取了环境、交通、政治、教育、体育5 法进行比较。AP聚类中,CD_Sim方法聚类结果最 个类别,每个类别随机选取20个文本文档共100个 好,但数值实验样本仅包含5类文档,CD_Sim方法 文本文档进行实验。实验中通过TF_DF特征选择 聚类数目达18种,存在一定的不合理性。在谱聚类 方法在100个文本中分别选择15个关键词进行相 算法中,CD_Sim方法聚类检验结果明显优于其他 似性度量,其中,由于基于统计方法的特殊性,该类 相似性度量方法,在4种相似性度量方法中,嫡值最 方法采用整个词语-文档权重矩阵进行相似度 小,纯净度最高。Kmeans聚类算法中,CD_Sim方法 计算。 实验结果纯净度较低、嫡值较大,但结果仍优于其 实验选择基于LSA的文本相似性度量方法、基 他相似性度量方法。 于词林的文本相似性度量方法和基于知网的语义 根据实验结果,对3种基于语义知识规则的相 相似性度量方法作为对比方法,分别采用AP聚类、 似性度量方法聚类实验结果进行比较分析,CD_Sim Kmeans聚类、谱聚类以及KNN分类对相似性度量 方法实验结果优于CL_Sim方法和ZW_Sim方法,聚 结果进行检验。 类熵值最小、纯净度最高。 3.2聚类分析 3.3分类实验 相似性度量结果的好坏直接影响文本聚类算 分类检验采用KNN算法进行分析,算法从每个 法的精度,在已知文档类别的样本中,聚类精度可 类别样本中均选取一半作为已知类别样本,剩下一 以反过来检验文本相似性度量结果的好坏。比较 半作为实验集,检验结果以分类准确率进行度量, 经典的基于距离矩阵的聚类算法有Kmeans,AP聚 分类算法K值分别取[1,2,…,10],得出10组不同 类及后来发展起来的谱聚类算法等。Kmeans与谱 K值下的KNN分类结果并取平均值mean。采用不 聚类算法均是给定聚类数目的聚类算法,时间复杂 的相似性度量方法作为文本之间近似性度量方法, 度低,聚类准确度高:在聚类数目未知的情况下,上 结合KNN方法进行数值实验,其实验结果如表4 述两种方法聚类结果会产生较大的偏差。AP聚类 所示。 没有事先给定聚类数目,根据数据自身的特性进行 表4基于分类检验方法的数据实验结果 聚类,聚类结果与聚类对象特征更加吻合。将相似 Table 4 Experiment results based on classified method 性度量方法实验结果做聚类分析,数值实验结果如 分类 表3。 方法 -mean 12345678910 表3基于聚类检验方法的数据实验结果 CL_Sim0.600.580.640.640.720.680.700.620.700.780.67 Table 3 Experiment results based on clustering method ZW Sim0.220.240.240.260.240.260.260.240.260.28025 Spectral Kmeans AP聚类 CD Sim0.800.840.840.900.900.840.880.900.860.840.86 方法 聚类 聚类 LSA Sim0.820.840.840.840.840.840.860.760.780.800.82 NUM 嫡值纯净度熵值纯净度嫡值纯净度 数值实验结果表明,4种相似性度量方法中」 CL Sim 14 0.960.741.76 0.47 1.84 0.41 CD_Sim方法分类实验结果最好,分类准确率最高, ZW Sim 9 2.130.28 1.84 0.41 2.22 0.24 LSA Sim方法实验结果次之,优于其他方法分类实 CD Sim 18 0.330.900.900.821.26 0.66 验结果。3种基于语义知识规则的相似性度量方法 LSA Sim180.600.851.600.501.680.51 分类检验结果进行比较,CD_Sim方法分类实验结 数值实验中,聚类结果通过熵值和纯净度来度 果优于CL_Sim方法和ZW_Sim方法,分类准确度 量。聚类结果嫡值越低、纯净度越高,则聚类结果 最高。 越好。NUM记录了将各相似性度量方法结果进行 3.4时间复杂度分析 AP聚类所得聚类类别数。基于LSA的相似性度量 实验中方法的时间复杂度是除准确性外方法
3.1 实验数据与实验设计 实验语料数据选自搜狗实验室提供的搜狗分 类语料库,该语料库包含了环境、计算机、交通、教 育、经济、军事、体育、医药、艺术和政治 10 个类别文 本文档。 数值实验选取了环境、交通、政治、教育、体育 5 个类别,每个类别随机选取 20 个文本文档共 100 个 文本文档进行实验。 实验中通过 TF_IDF 特征选择 方法在 100 个文本中分别选择 15 个关键词进行相 似性度量,其中,由于基于统计方法的特殊性,该类 方法采用整个词语 - 文档权重矩阵进行相似度 计算。 实验选择基于 LSA 的文本相似性度量方法、基 于词林的文本相似性度量方法和基于知网的语义 相似性度量方法作为对比方法,分别采用 AP 聚类、 Kmeans 聚类、谱聚类以及 KNN 分类对相似性度量 结果进行检验。 3.2 聚类分析 相似性度量结果的好坏直接影响文本聚类算 法的精度,在已知文档类别的样本中,聚类精度可 以反过来检验文本相似性度量结果的好坏。 比较 经典的基于距离矩阵的聚类算法有 Kmeans,AP 聚 类及后来发展起来的谱聚类算法等。 Kmeans 与谱 聚类算法均是给定聚类数目的聚类算法,时间复杂 度低,聚类准确度高;在聚类数目未知的情况下,上 述两种方法聚类结果会产生较大的偏差。 AP 聚类 没有事先给定聚类数目,根据数据自身的特性进行 聚类,聚类结果与聚类对象特征更加吻合。 将相似 性度量方法实验结果做聚类分析,数值实验结果如 表 3。 表 3 基于聚类检验方法的数据实验结果 Table 3 Experiment results based on clustering method 方法 AP 聚类 Spectral 聚类 Kmeans 聚类 NUM 熵值 纯净度 熵值 纯净度 熵值 纯净度 CL_Sim 14 0.96 0.74 1.76 0.47 1.84 0.41 ZW_Sim 9 2.13 0.28 1.84 0.41 2.22 0.24 CD_Sim 18 0.33 0.90 0.90 0.82 1.26 0.66 LSA_Sim 18 0.60 0.85 1.60 0.50 1.68 0.51 数值实验中,聚类结果通过熵值和纯净度来度 量。 聚类结果熵值越低、纯净度越高,则聚类结果 越好。 NUM 记录了将各相似性度量方法结果进行 AP 聚类所得聚类类别数。 基于 LSA 的相似性度量 算法,K 值取[10,20,…,100]这 10 组数据值进行实 验,每种聚类检验方法中均取熵值最小且纯净度最 高的实验结果作为基于 LSA 的相似性度量算法的 实验结果。 根据聚类实验结果分析,对 4 种相似性度量方 法进行比较。 AP 聚类中,CD_Sim 方法聚类结果最 好,但数值实验样本仅包含 5 类文档,CD_Sim 方法 聚类数目达 18 种,存在一定的不合理性。 在谱聚类 算法中,CD_Sim 方法聚类检验结果明显优于其他 相似性度量方法,在 4 种相似性度量方法中,熵值最 小,纯净度最高。 Kmeans 聚类算法中,CD_Sim 方法 实验结果纯净度较低、熵值较大,但结果仍优于其 他相似性度量方法。 根据实验结果,对 3 种基于语义知识规则的相 似性度量方法聚类实验结果进行比较分析,CD_Sim 方法实验结果优于 CL_Sim 方法和 ZW_Sim 方法,聚 类熵值最小、纯净度最高。 3.3 分类实验 分类检验采用 KNN 算法进行分析,算法从每个 类别样本中均选取一半作为已知类别样本,剩下一 半作为实验集,检验结果以分类准确率进行度量, 分类算法 K 值分别取[1,2,…,10],得出 10 组不同 K 值下的 KNN 分类结果并取平均值 mean。 采用不 的相似性度量方法作为文本之间近似性度量方法, 结合 KNN 方法进行数值实验, 其实验结果如表 4 所示。 表 4 基于分类检验方法的数据实验结果 Table 4 Experiment results based on classified method 方法 分类 1 2 3 4 5 6 7 8 9 10 mean CL_Sim 0.60 0.58 0.64 0.64 0.72 0.68 0.70 0.62 0.70 0.78 0.67 ZW_Sim 0.22 0.24 0.24 0.26 0.24 0.26 0.26 0.24 0.26 0.28 0.25 CD_Sim 0.80 0.84 0.84 0.90 0.90 0.84 0.88 0.90 0.86 0.84 0.86 LSA_Sim 0.82 0.84 0.84 0.84 0.84 0.84 0.86 0.76 0.78 0.80 0.82 数值实验结果表明,4 种相似性度量方法中, CD_Sim 方法分类实验结果最好,分类准确率最高, LSA_Sim 方法实验结果次之,优于其他方法分类实 验结果。 3 种基于语义知识规则的相似性度量方法 分类检验结果进行比较,CD_Sim 方法分类实验结 果优于 CL_Sim 方法和 ZW_Sim 方法,分类准确度 最高。 3.4 时间复杂度分析 实验中方法的时间复杂度是除准确性外方法 ·560· 智 能 系 统 学 报 第 12 卷