
Detecting Oriented Text in Natural Images by Linking Segments ---0 汇报人:盛驰云 ---
Detecting Oriented Text in Natural Images by Linking Segments 汇报人:盛驰云

l 背景介绍 Dreifalfigkeilsplalz 文本检测: 即用单词或文本行的边界框定位文本,可以看作 是应用于文本的目标检测。 文本特点: (1)文本的高度宽度比值特别大或者小, (2)自然场景中的文本通常存在一定的旋转角度
背景介绍 文本检测: 即用单词或文本行的边界框定位文本,可以看作 是应用于文本的目标检测。 文本特点:(1)文本的高度宽度比值特别大或者小, (2)自然场景中的文本通常存在一定的旋转角度

li 背景介绍 本文提出:引入旋转角度0学习参数,回归参数(x,y,w,h)→(xy,w,h,0) Segment(段):文本行的一部分(可以是字符或者文本行中任意某部分) Linkng(连接):用以连接每个Segment CfCS + CS crocs crocs Segments Links Combined (yellow boxes) (green edges) detection boxes
背景介绍 本文提出:引入旋转角度θ学习参数,回归参数(x,y,w,h) (x,y,w,h,θ) Segment(段):文本行的一部分(可以是字符或者文本行中任意某部分) Linkng(连接):用以连接每个Segment
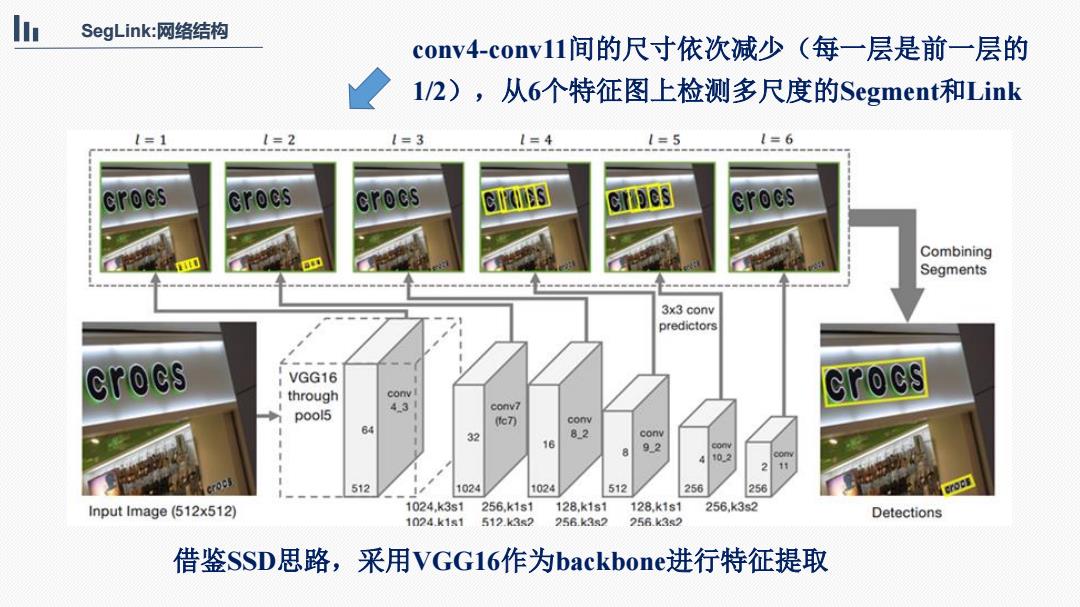
li SegLink:网络结构 conv4-conv11间的尺寸依次减少(每一层是前一层的 1/2),从6个特征图上检测多尺度的Segm㎡ent和Link 1=1 1=2 1=3 1=4 1=5 1=6 crocs crocs crocs s Clipes crocs Combining Segments 3x3 conv predictors crocs VGG16 i through convl crocs 4.3 conv7 pool5 te刀 conv 64 32 82 conv 16 92 conv 10.2 com 11 512 1024 1024 512 256 256 Input Image (512x512) 1024.k3s1 256,k1s1 128.k1s1 128.k1s1 256,k3s2 Detections 1024.k1s1 512k32 256.k32 256.k32 借鉴SSD思路,采用VGG16作为backbone进行特征提取
SegLink:网络结构 借鉴SSD思路,采用VGG16作为backbone进行特征提取 conv4-conv11间的尺寸依次减少(每一层是前一层的 1/2),从6个特征图上检测多尺度的Segment和Link

l Segment检测 Segment类似于SSD中的回归box,表达形式如下: s=(s,Vs,Ws,hs:0s) default box个数,本文每个feature map的每个位置只采用了一个 aspect ratio=l的default box,scale size设置结合当前层感受野: a where =1.5. Segment计算公式:xs=au△xs+xa ys=au△ys+ya ws=ar exp(△ws) hs=ar exp(△hs 0s=△0s
Segment检测 Segment类似于SSD中的回归box,表达形式如下: default box个数,本文每个feature map的每个位置只采用了一个 aspect ratio=1的default box,scale size设置结合当前层感受野: Segment计算公式: