
强化学习Agent 强化学习Agent包含以下模块: 策略(Policy):Agent的行为,状态到行动的映射 确定策略(Deterministic policy):a=T(s) ·随机策略(Stochastic policy):π(a|s)=P[A:=a|S:= ~值函数(Value function):状态(和行动)的评价 ·值函数是对当前状态(和行动)下未来效用的预测 vn(S)=E.R+1+yR+2+y2R+3+…|S:= ~模型(Model):Agent对环境的刻画 ·给定状态和行动预测环境下一步的反应(下一个状态和效用) P=PS+1=s|S:=5A=a司 g=E[R+1|5:=s,At=ad司 口卡4三4色进分QC
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 强化学习 Agent ▶ 强化学习 Agent 包含以下模块: ▶ 策略(Policy): Agent 的行为,状态到行动的映射 ▶ 确定策略(Deterministic policy):a = π(s) ▶ 随机策略(Stochastic policy):π(a | s) = P[At = a | St = s] ▶ 值函数(Value function): 状态(和行动)的评价 ▶ 值函数是对当前状态(和行动)下未来效用的预测 vπ(s) = Eπ[Rt+1 + γRt+2 + γ 2Rt+3 + · · · | St = s] ▶ 模型(Model):Agent 对环境的刻画 ▶ 给定状态和行动预测环境下一步的反应(下一个状态和效用) P a ss′ = P[St+1 = s ′ | St = s, At = a] R a s = E[Rt+1 | St = s, At = a]

迷宫(Maze)例子 Start Rewards:-1 per time-step ■Actions:N,E,S,W States:Agent's location Goal 4口卡404三·1怎生0C
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 迷宫(Maze)例子

迷宫(Maze)例子:策略 Start Goal Arrows represent policy (s)for each state s 口·三,4色,进分Q0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 迷宫(Maze)例子:策略
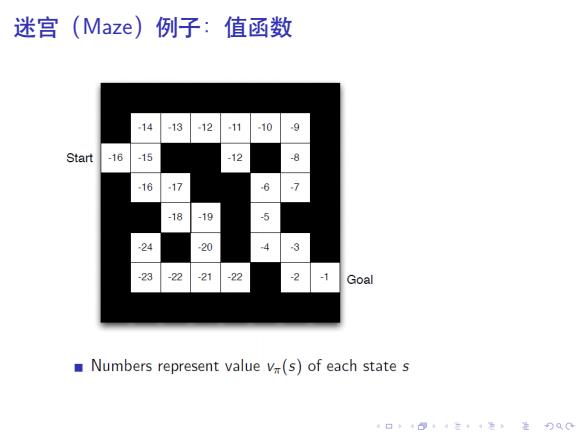
迷宫(Maze)例子:值函数 -14 -13 12 .11 -10 -9 Start -16 -15 -12 -8 -16 -17 6 > -18 -19 -5 24 20 -4 -3 -23 -22 -21 -22 -2 7 Goal Numbers represent value v(s)of each state s 4口◆4⊙t1三1=,¥9QC
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 迷宫(Maze)例子:值函数

迷宫(Maze)例子:模型 Agent may have an internal Start .1 model of the environment Dynamics:how actions change the state 1 Rewards:how much reward 1 from each state Goal The model may be imperfect Grid layout represents transition model p Numbers represent immediate reward Ra from each state s (same for all a) 口·三4,进分双0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 迷宫(Maze)例子:模型