
数据科学引论-Python之道 第4课数据分析入门 一、numpy和pandas 我们主要学习两个库:numpy和pandas的使用方式。numpy是第一个库, 什么是numpy,就是python中用于科学计算的一个基础包,它的特点是运行速 度很快,支持多维数组,并且支持向量化的计算。它的使用方式像下面这样,先 要导入numpy,这个包导入以后可以起个别名np,然后就可以使用np这个别 名来调用numpy中的功能。例如,我们通过np来创建一个array,也就是一个 数组,这个数组是一个3×2的二维数组。 import numpy as np data=np.array([1.9526,-0.246,-0.8856], [0.5639,0.2379,0.9104]) data array([[1.9526,-0.246,-0.8856], [0.5639,0.2379,0.9104]]) 接下来,我们来看一看pandas这个包。我们主要讨论其中的两类对象,一 类是series,另外一类是DataFrame。pandas是什么?pandas是python中专门 用于数据分析的包,它主要的成分就是刚才讲的series和data frames。我们可 以通过这两类对象可以来下载数据可视化和分析数据。 Series是由数字构成的列表,在前面我们讲python入门时提到过列表这样 的数据类型。列表里每个元素都有自己的数据以及索引,所以在缺省情况下, series里面的索引是整数类型的,并且和列表一样从0开始的。所以我们定义一 个数据集data,它包含三个元素,再用data这个数据集来创建一个series,我 们就得到了一个pandas里面的series对象。这个对象里面的数据是连续存储的, 并且它的索引是0、1、2这样排列的。通过索引的值我们就可以访问到一个具体
数据科学引论-P瀌瀇h瀂瀁 之道 第 4 课 数据分析入门 一、瀁瀈瀀瀃瀌 和 瀃a瀁da瀆 我们主要学习两个库:瀁瀈瀀瀃瀌 和 瀃a瀁da瀆 的使用方式。瀁瀈瀀瀃瀌 是第一个库, 什么是 瀁瀈瀀瀃瀌,就是 瀃瀌瀇h瀂瀁 中用于科学计算的一个基础包,它的特点是运行速 度很快,支持多维数组,并且支持向量化的计算。它的使用方式像下面这样,先 要导入 瀁瀈瀀瀃瀌,这个包导入以后可以起个别名 瀁瀃,然后就可以使用 瀁瀃 这个别 名来调用 瀁瀈瀀瀃瀌 中的功能。例如,我们通过 瀁瀃 来创建一个 a瀅瀅a瀌,也就是一个 数组,这个数组是一个 3×2 的二维数组。 接下来,我们来看一看 瀃a瀁da瀆 这个包。我们主要讨论其中的两类对象,一 类是 瀆e瀅ie瀆,另外一类是 Da瀇aF瀅a瀀e。瀃a瀁da瀆 是什么?瀃a瀁da瀆 是 瀃瀌瀇h瀂瀁 中专门 用于数据分析的包,它主要的成分就是刚才讲的 瀆e瀅ie瀆 和 da瀇a f瀅a瀀e瀆。我们可 以通过这两类对象可以来下载数据可视化和分析数据。 Se瀅ie瀆 是由数字构成的列表,在前面我们讲 瀃瀌瀇h瀂瀁 入门时提到过列表这样 的数据类型。列表里每个元素都有自己的数据以及索引,所以在缺省情况下, 瀆e瀅ie瀆 里面的索引是整数类型的,并且和列表一样从 0 开始的。所以我们定义一 个数据集 da瀇a,它包含三个元素,再用 da瀇a 这个数据集来创建一个 瀆e瀅ie瀆,我 们就得到了一个瀃a瀁da瀆里面的瀆e瀅ie瀆对象。这个对象里面的数据是连续存储的, 并且它的索引是 0、1、2 这样排列的。通过索引的值我们就可以访问到一个具体

的对象,比如S1],就指向的是第一个23这个数据。 data=[11,23,23] s pd.Series(data) data 11 23 23 Index 0 11 23 2 23 dtype:int64 s[1]=23 s1] 23 如果我们不想使用缺省情况下从0开始的不断递增的整数类型的索引,我们 可以自己来设置series里面元素的索引。例如,在下面这段脚本中,我们仍然是 定义了三个元素构成的一个数据集,另外又定义一个由三个字符串构成的索引集。 用这个数据集以及索引集来创建一个series。.注意,这里的第一个index是关键 字,表示索引;第二个是表示的是第二行的这个index变量,表示在创建这个 series对象所使用的索引,就是我们这里定义的series这个对象。这样创建好的 series仍然包含三个元素,但是它们的索引值现在就变成了a、b、c。同样地, 通过索引值可以访问到具体的对象,例如S"a"门等于11。 data=[11,23,23] index=["a","b","c"] s pd.Series(data,index=index) data 11 23 23 Index a a 11 b 23 23 dtype:int64 s["a"]=11 s["a"] 11 除了访问一个对象之外,我们还可以访问一组对象。例如,在下面这段脚本中, 我们希望访问索引为a和b的两个对象,一次性读取出来。所以,可以在S中传 入一组索引值的方法来获取多个对象,所以S["a"门的11和S"b门的12被一次性 地获取了出来
的对象,比如 S[1],就指向的是第一个 23 这个数据。 如果我们不想使用缺省情况下从 0 开始的不断递增的整数类型的索引,我们 可以自己来设置 瀆e瀅ie瀆 里面元素的索引。例如,在下面这段脚本中,我们仍然是 定义了三个元素构成的一个数据集,另外又定义一个由三个字符串构成的索引集。 用这个数据集以及索引集来创建一个 瀆e瀅ie瀆。注意,这里的第一个 i瀁de瀋 是关键 字,表示索引;第二个是表示的是第二行的这个 i瀁de瀋 变量,表示在创建这个 瀆e瀅ie瀆 对象所使用的索引,就是我们这里定义的 瀆e瀅ie瀆 这个对象。这样创建好的 瀆e瀅ie瀆 仍然包含三个元素,但是它们的索引值现在就变成了 a、b、c。同样地, 通过索引值可以访问到具体的对象,例如 S["a"]等于 11。 除了访问一个对象之外,我们还可以访问一组对象。例如,在下面这段脚本中, 我们希望访问索引为 a 和 b 的两个对象,一次性读取出来。所以,可以在 S 中传 入一组索引值的方法来获取多个对象,所以 S["a"]的 11 和 S["b"]的 12 被一次性 地获取了出来

s["b"]=12 import pandas as pd data=11,12,131 ind■【"a","b","c"J data 11 12 13 Index a b s=pd.Series(data,index=ind) s【"a","b"1】 12 s["a"]=11 dtype:int64 DataFrame是什么呢?DataFrame是一个类似电子表格的对象,它是一个有 序的列集合,并且同时具有行和列的索引,也就是说在DataFrame的构成中,每 一列都是我们之前定义的一个series,这些列凑到一起之后,对应的行上面都还 会有一个行的索引。 列 Dictionary A 行 Index Series 1 Series 2 Series 2 具体来说,我们在这里举一个例子。首先,我们导入pandas的包,我们定 义了一个data字典,这个字典里面包含了若干个键值。这些键值对每一个都表 示的是一列。所以我们看到的电子表格里面包含了三列points、name、year。同 时,我们在创建DataFrame时,要指定行索引是什么。由于我们在前面的data 里面包含了五行,所以要指定它的五个行索引是什么,这里我们指定的是Dy1 一直到Day5。使用data和这个index构建出来的Dateframe就像下面这样, 它有列索引,又有行索引,看起来就像一个电子表格
Da瀇aF瀅a瀀e 是什么呢?Da瀇aF瀅a瀀e 是一个类似电子表格的对象,它是一个有 序的列集合,并且同时具有行和列的索引,也就是说在 Da瀇aF瀅a瀀e 的构成中,每 一列都是我们之前定义的一个 瀆e瀅ie瀆,这些列凑到一起之后,对应的行上面都还 会有一个行的索引。 具体来说,我们在这里举一个例子。首先,我们导入 瀃a瀁da瀆 的包,我们定 义了一个 da瀇a 字典,这个字典里面包含了若干个键值。这些键值对每一个都表 示的是一列。所以我们看到的电子表格里面包含了三列 瀃瀂i瀁瀇瀆、瀁a瀀e、瀌ea瀅。同 时,我们在创建 Da瀇aF瀅a瀀e 时,要指定行索引是什么。由于我们在前面的 da瀇a 里面包含了五行,所以要指定它的五个行索引是什么,这里我们指定的是 Da瀌1 一直到 Da瀌5。 使用 da瀇a 和这个 i瀁de瀋 构建出来的 Da瀇ef瀅a瀀e 就像下面这样, 它有列索引,又有行索引,看起来就像一个电子表格
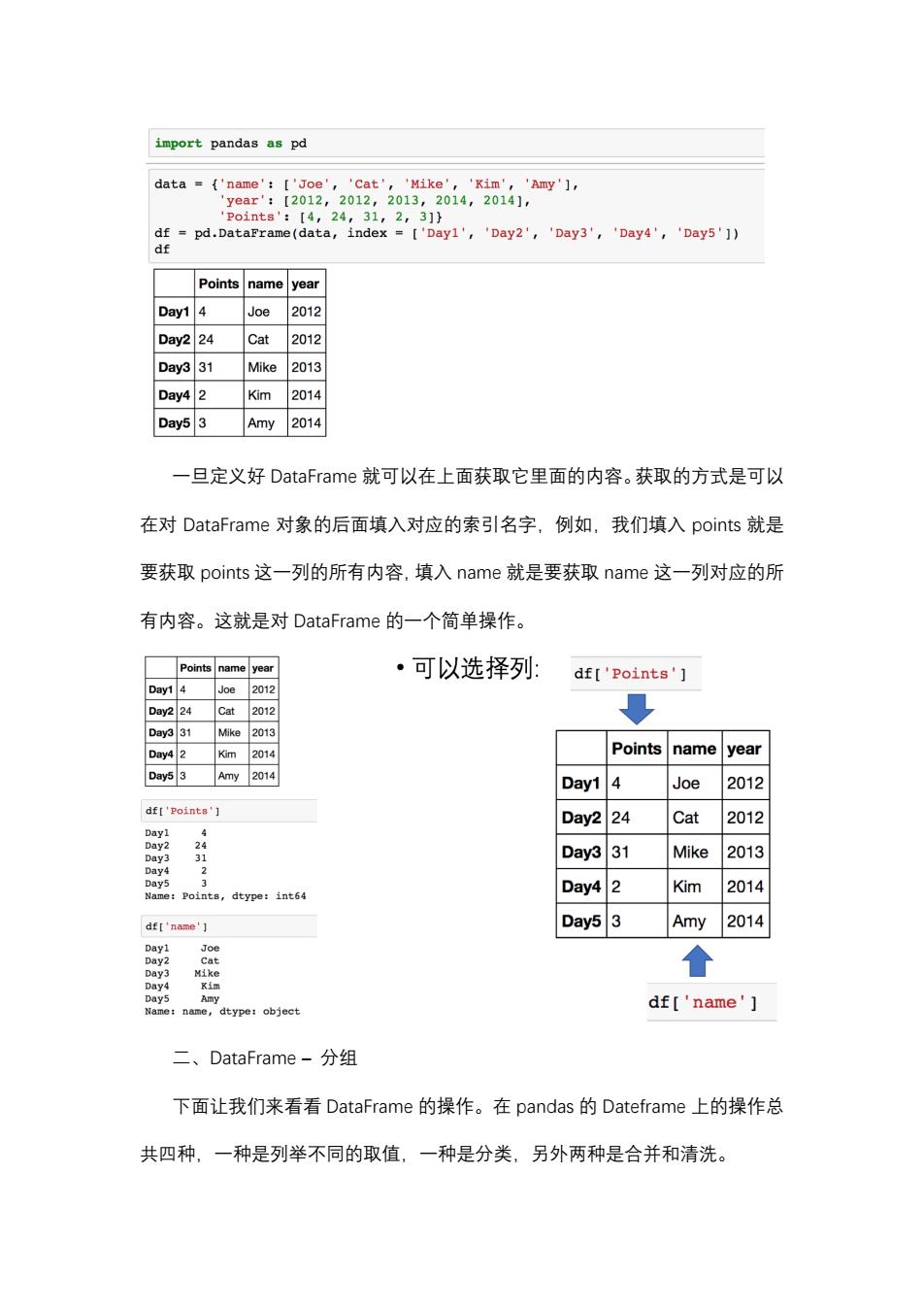
import pandas as pd data =('name':['Joe','Cat','Mike','Kim','Amy'], 'year':[2012,2012,2013,2014,20141, 'Points':【4,24,31,2,3]} df pd.DataFrame(data,index =['Day1','Day2','Day3','Day4','Day5']) df Points name year Day1 4 Joe 2012 Day2 24 Cat 2012 Day3 31 Mike 2013 Day4 2 Kim 2014 Day5 3 Amy 2014 一旦定义好DataFrame就可以在上面获取它里面的内容。获取的方式是可以 在对DataFrame对象的后面填入对应的索引名字,例如,我们填入points就是 要获取points这一列的所有内容,填入name就是要获取name这一列对应的所 有内容。这就是对DataFrame的一个简单操作。 Points nameyear ·可以选择列: df['Points'] Day1 4 Joe 2012 Day2 24 Cat 2012 Day3 31 Mike 2013 Day4 2 Kim 2014 Points name year Day5 3 Amy 2014 Day1 4 Joe 2012 df['Points'] Day2 24 Cat 2012 Dayl Day2 24 Day3 3 Day3 31 Mike 2013 Day4 Day5 3 Day4 2 Kim 2014 Name:Points,dtype:int64 df['name'】 Day5 3 Amy 2014 Day1 Joe Day2 Cat Day3 Mike Day4 Kim Day5 Amy Name:name, dtype:object df['name' 二、DataFrame-分组 下面让我们来看看DataFrame的操作。在pandas的Dateframe上的操作总 共四种,一种是列举不同的取值,一种是分类,另外两种是合并和清洗
一旦定义好 Da瀇aF瀅a瀀e 就可以在上面获取它里面的内容。获取的方式是可以 在对 Da瀇aF瀅a瀀e 对象的后面填入对应的索引名字,例如,我们填入 瀃瀂i瀁瀇瀆 就是 要获取 瀃瀂i瀁瀇瀆 这一列的所有内容,填入 瀁a瀀e 就是要获取 瀁a瀀e 这一列对应的所 有内容。这就是对 Da瀇aF瀅a瀀e 的一个简单操作。 二、Da瀇aF瀅a瀀e – 分组 下面让我们来看看 Da瀇aF瀅a瀀e 的操作。在 瀃a瀁da瀆 的 Da瀇ef瀅a瀀e 上的操作总 共四种,一种是列举不同的取值,一种是分类,另外两种是合并和清洗

首先,我们来看最简单的列举不同取值。列举不同取值是通过unique函数 来实现的。所谓不同的取值,它的概念是这样的:在下面的图中,我们看到这个 是列数据有很多行,但是这一列数据当中不同的取值只有红绿蓝三种。我们想知 道在这一列上不同的取值到底有多少种,这就是unique函数的作用。 举一个例子,下面是一个DataFrame,在它的Stat_Date这一列中,我们可 以看到,尽管有七行数据,但是不同的取值实际上只有四个,我们想要取得这些 不同的数据,该怎么做呢?首先,我们通过对DataFrame传入索引列的索引的 方式获取这一列,于是我们得到了Start_Date这一列。接着,我们在这一列上调 用unique方法,就会得到不同的取值,于是,我们看到这四个不同的取值被取 回。 Start_Date name Start_Date d2002 Jason 2002 2002 df['Start Date'] 12012 Molly 2012 2012 22012 Tina 2012 2014 32014 2014 1999 Jake 42014 Amy 2014 51999 1999 John 1999 61999 Bob 接下来我们看看分组,分组是什么概念?在电子表格中,也就是在DataFrame
首先,我们来看最简单的列举不同取值。列举不同取值是通过 瀈瀁i瀄瀈e 函数 来实现的。所谓不同的取值,它的概念是这样的:在下面的图中,我们看到这个 是列数据有很多行,但是这一列数据当中不同的取值只有红绿蓝三种。我们想知 道在这一列上不同的取值到底有多少种,这就是 瀈瀁i瀄瀈e 函数的作用。 举一个例子,下面是一个 Da瀇aF瀅a瀀e,在它的 S瀇a瀅瀇_Da瀇e 这一列中,我们可 以看到,尽管有七行数据,但是不同的取值实际上只有四个,我们想要取得这些 不同的数据,该怎么做呢?首先,我们通过对 Da瀇aF瀅a瀀e 传入索引列的索引的 方式获取这一列,于是我们得到了 S瀇a瀅瀇_Da瀇e 这一列。接着,我们在这一列上调 用 瀈瀁i瀄瀈e 方法,就会得到不同的取值,于是,我们看到这四个不同的取值被取 回。 接下来我们看看分组,分组是什么概念?在电子表格中,也就是在Da瀇aF瀅a瀀e