
数据科学引论-Python之道 第7课数据科学方法学 一、 数据科学方法学 我们来看看数据科学方法学的内涵。下面这张图描述了数据分析的整个过程。 1.Business 2.Analytic 3.Data 4.Data 5.Data Understanding Approach Requirements Collection Understanding Prediction Interpretation Justification DEPLOY! 鑫 歌 Testing 10.Feedback 9 8.Evaluation 7.Modelling 6.Data Deployment Preparation 让我们结合一个实例来看看在这个过程当中10个步骤的每一个步骤都在做 些什么,要解决什么样的问题。假设Peter在7月22号星期五下午3点要在纽 约参加一个会议,但是他人目前在旧金山,当天他要乘坐航班飞到纽约去参加这 个会议,那么他乘坐的航班会不会延误导致他无法参加这个会议呢?我们要解决 的就是这样一个问题。 首先,第一步是业务理解。所有的项目都始于业务理解,业务理解就是要去 理解我们当前这个项目在做什么,我们的目标是什么。也就是说要明确我们要解 决的问题,定义相关的一些问题和对解决方案的一些需求。在这个例子中,我们 要解决的问题就是要去预测某一天的某个航班是否会延误。 如何去进行这样的预测呢?我们来到了第二个步骤,就是要确定分析方法
数据科学引论-Pyth瀂瀁 之道 第 7 课 数据科学方法学 一、 数据科学方法学 我们来看看数据科学方法学的内涵。下面这张图描述了数据分析的整个过程。 让我们结合一个实例来看看在这个过程当中 10 个步骤的每一个步骤都在做 些什么,要解决什么样的问题。假设 Peter 在 7 月 22 号星期五下午 3 点要在纽 约参加一个会议,但是他人目前在旧金山,当天他要乘坐航班飞到纽约去参加这 个会议,那么他乘坐的航班会不会延误导致他无法参加这个会议呢?我们要解决 的就是这样一个问题。 首先,第一步是业务理解。所有的项目都始于业务理解,业务理解就是要去 理解我们当前这个项目在做什么,我们的目标是什么。也就是说要明确我们要解 决的问题,定义相关的一些问题和对解决方案的一些需求。在这个例子中,我们 要解决的问题就是要去预测某一天的某个航班是否会延误。 如何去进行这样的预测呢?我们来到了第二个步骤,就是要确定分析方法

我们可以通过历史的航班信息来进行预测,于是我们确定,我们要根据历史数据, 通过某种数理统计或者是机器学习的方法来进行预测。数理统计和机器学习的方 法有很多种,我们可以选择其中的一种,比如可以选择逻辑回归。紧接着,我们 要去考虑要做这种预测到底需要哪些航班数据?这些数据是什么格式的?我们 可以想象一下,我们需要某一年的所有航班的起降数据,这些数据最好都是纯文 本的,以方便我们去处理。确定了数据的需求之后,我们要去收集这些数据,这 些数据有可能是开放数据,可以在网络上下载,也有可能是一些私有数据,需要 购买。无论怎样,得到数据之后,要对这些数据做一些理解,比如说这些数据看 起来怎么样,是不是很完整?我们对这些数据会产生一些什么样的初步见解?这 些数据能不能可视化?除了这些数据,我们是不是还遗漏了一些东西? 在当前这个例子中,我们可以看到,一旦拿到航班的历史数据,我们就可以 判断出哪些机场最繁忙,哪些航班最容易延误,而哪些机场延误的情况是最糟糕 的。我们来观察一下我们得到的航班数据,这里我们只取了2007年的有关700 万个航班的数据,其中我们最关注的一列是Departure Delay,也就是飞机实际 起飞时间和预计起飞之间之间的一个延误分钟数。要注意的是,这个数据里面并 没有直接去定义某一个航班是否延误了,它只给出了这个延误的分钟数,这一点 很重要。 ArrTime|CRSArrTime CRSDepTime DayofWeek DayofMonth DepDelay DepTimeDest Distance MonthOrigin| 1341 1340 1225 1232 ONT 389 NN|2007 2043 2035 1905 13 191日 PDX 479 SMP |2007 2334 2300 2130 6 2206 PDX 479 SMF N|2007 1356 1330 1200 1 1230 PDX 479 SMP N|2007 957 1000 B30 1 1 B31 PDX 479 11 SMP N2007 通过可视化,我们可以知道哪些机场最繁忙。我们把所有的机场起降的飞机 的航班的数量通过热图呈现出来,就可以看到面积越大的圆圈,颜色越深的圆圈, 表示机场越繁忙
我们可以通过历史的航班信息来进行预测,于是我们确定,我们要根据历史数据, 通过某种数理统计或者是机器学习的方法来进行预测。数理统计和机器学习的方 法有很多种,我们可以选择其中的一种,比如可以选择逻辑回归。紧接着,我们 要去考虑要做这种预测到底需要哪些航班数据?这些数据是什么格式的?我们 可以想象一下,我们需要某一年的所有航班的起降数据,这些数据最好都是纯文 本的,以方便我们去处理。确定了数据的需求之后,我们要去收集这些数据,这 些数据有可能是开放数据,可以在网络上下载,也有可能是一些私有数据,需要 购买。无论怎样,得到数据之后,要对这些数据做一些理解,比如说这些数据看 起来怎么样,是不是很完整?我们对这些数据会产生一些什么样的初步见解?这 些数据能不能可视化?除了这些数据,我们是不是还遗漏了一些东西? 在当前这个例子中,我们可以看到,一旦拿到航班的历史数据,我们就可以 判断出哪些机场最繁忙,哪些航班最容易延误,而哪些机场延误的情况是最糟糕 的。我们来观察一下我们得到的航班数据,这里我们只取了 2007 年的有关 700 万个航班的数据,其中我们最关注的一列是 De瀃arture De濿ay,也就是飞机实际 起飞时间和预计起飞之间之间的一个延误分钟数。要注意的是,这个数据里面并 没有直接去定义某一个航班是否延误了,它只给出了这个延误的分钟数,这一点 很重要。 通过可视化,我们可以知道哪些机场最繁忙。我们把所有的机场起降的飞机 的航班的数量通过热图呈现出来,就可以看到面积越大的圆圈,颜色越深的圆圈, 表示机场越繁忙
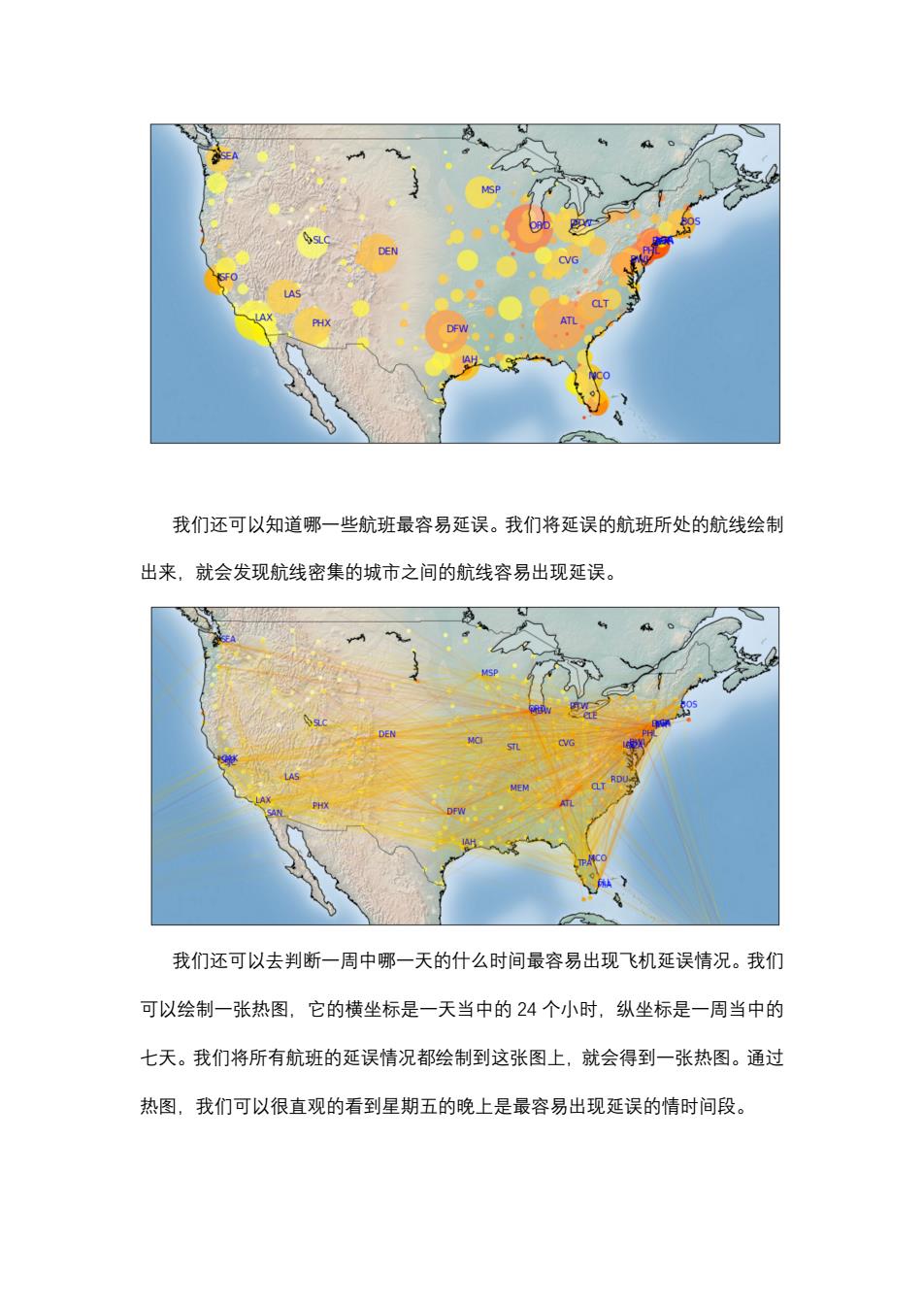
PHX DFW A 我们还可以知道哪一些航班最容易延误。我们将延误的航班所处的航线绘制 出来,就会发现航线密集的城市之间的航线容易出现延误。 CT RDU 我们还可以去判断一周中哪一天的什么时间最容易出现飞机延误情况。我们 可以绘制一张热图,它的横坐标是一天当中的24个小时,纵坐标是一周当中的 七天。我们将所有航班的延误情况都绘制到这张图上,就会得到一张热图。通过 热图,我们可以很直观的看到星期五的晚上是最容易出现延误的情时间段
我们还可以知道哪一些航班最容易延误。我们将延误的航班所处的航线绘制 出来,就会发现航线密集的城市之间的航线容易出现延误。 我们还可以去判断一周中哪一天的什么时间最容易出现飞机延误情况。我们 可以绘制一张热图,它的横坐标是一天当中的 24 个小时,纵坐标是一周当中的 七天。我们将所有航班的延误情况都绘制到这张图上,就会得到一张热图。通过 热图,我们可以很直观的看到星期五的晚上是最容易出现延误的情时间段
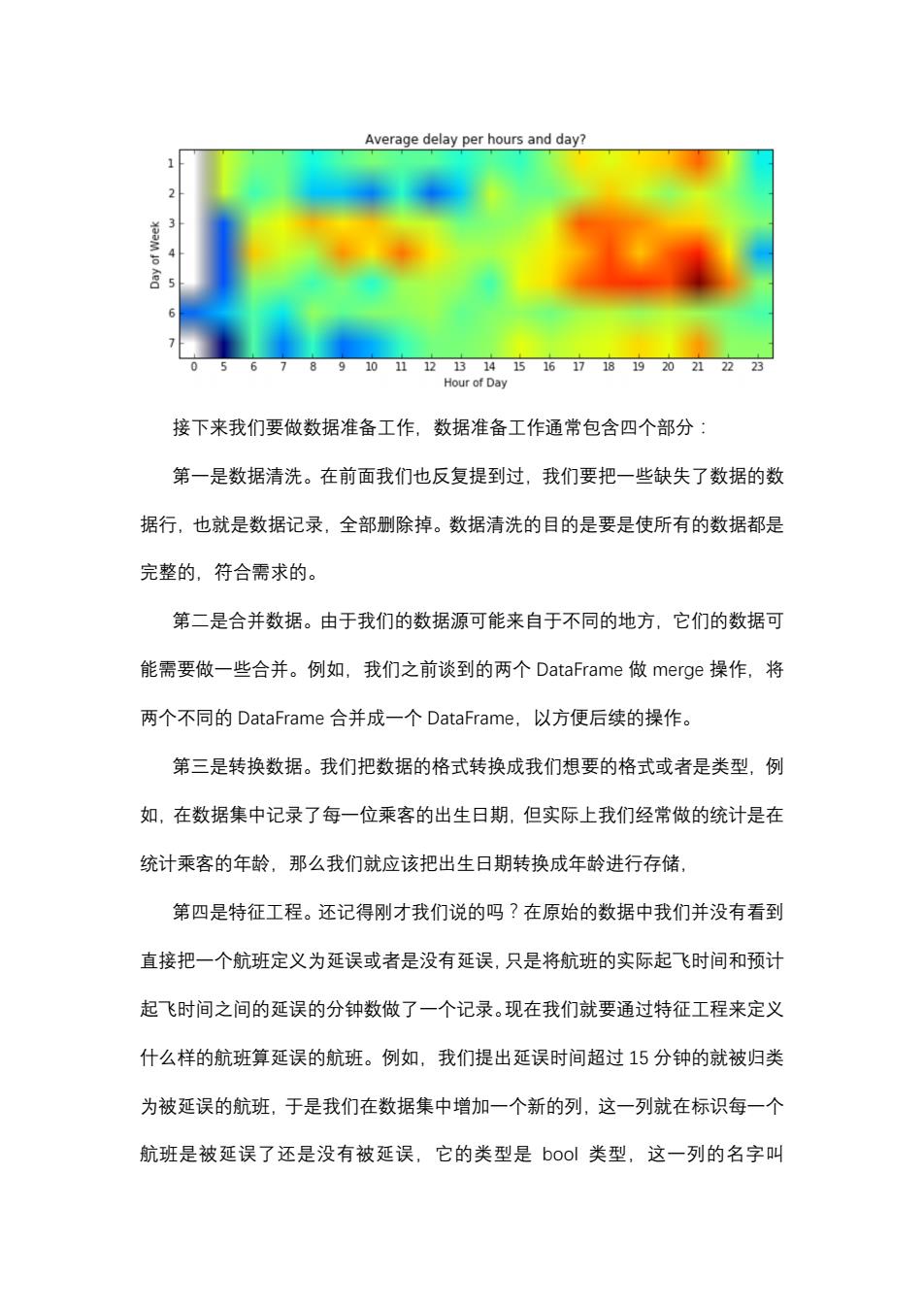
Average delay per hours and day? 2 3 4 67891011121314151617181920212223 Hour of Day 接下来我们要做数据准备工作,数据准备工作通常包含四个部分: 第一是数据清洗。在前面我们也反复提到过,我们要把一些缺失了数据的数 据行,也就是数据记录,全部删除掉。数据清洗的目的是要是使所有的数据都是 完整的,符合需求的。 第二是合并数据。由于我们的数据源可能来自于不同的地方,它们的数据可 能需要做一些合并。例如,我们之前谈到的两个DataFrame做merge操作,将 两个不同的DataFrame合并成一个DataFrame,以方便后续的操作。 第三是转换数据。我们把数据的格式转换成我们想要的格式或者是类型,例 如,在数据集中记录了每一位乘客的出生日期,但实际上我们经常做的统计是在 统计乘客的年龄,那么我们就应该把出生日期转换成年龄进行存储 第四是特征工程。还记得刚才我们说的吗?在原始的数据中我们并没有看到 直接把一个航班定义为延误或者是没有延误,只是将航班的实际起飞时间和预计 起飞时间之间的延误的分钟数做了一个记录。现在我们就要通过特征工程来定义 什么样的航班算延误的航班。例如,我们提出延误时间超过15分钟的就被归类 为被延误的航班,于是我们在数据集中增加一个新的列,这一列就在标识每一个 航班是被延误了还是没有被延误,它的类型是bool类型,这一列的名字叫
接下来我们要做数据准备工作,数据准备工作通常包含四个部分: 第一是数据清洗。在前面我们也反复提到过,我们要把一些缺失了数据的数 据行,也就是数据记录,全部删除掉。数据清洗的目的是要是使所有的数据都是 完整的,符合需求的。 第二是合并数据。由于我们的数据源可能来自于不同的地方,它们的数据可 能需要做一些合并。例如,我们之前谈到的两个 DataFra瀀e 做 瀀erge 操作,将 两个不同的 DataFra瀀e 合并成一个 DataFra瀀e,以方便后续的操作。 第三是转换数据。我们把数据的格式转换成我们想要的格式或者是类型,例 如,在数据集中记录了每一位乘客的出生日期,但实际上我们经常做的统计是在 统计乘客的年龄,那么我们就应该把出生日期转换成年龄进行存储, 第四是特征工程。还记得刚才我们说的吗?在原始的数据中我们并没有看到 直接把一个航班定义为延误或者是没有延误,只是将航班的实际起飞时间和预计 起飞时间之间的延误的分钟数做了一个记录。现在我们就要通过特征工程来定义 什么样的航班算延误的航班。例如,我们提出延误时间超过 15 分钟的就被归类 为被延误的航班,于是我们在数据集中增加一个新的列,这一列就在标识每一个 航班是被延误了还是没有被延误,它的类型是 b瀂瀂濿 类型,这一列的名字叫

Delayed,True就表示是延误的航班,False是没有延误的航班。所以我们看到特 征工程是从数据集中抽取出一些特征,并标记在数据集中。 到这里为止,数据就准备好了,下面就可以去做数据的分析了。在前面的这 几个步骤中,我们是可以不断地进行迭代的。不断地迭代就可以不断地提高数据 的质量,就可以有助于最后数据分析质量的提高。 紧接着,我们来建模。建模就是要确定在数据分析过程中的输入是什么?输 出是什么?中间使用的是什么样的算法或技术。在建模时,我们确定输入是航班 的起飞时间,包括年月日和出发时间以及目标机场,输出期望是预测这个航班是 否会延误,就是一个bool值,即True或False。中间我们希望使用逻辑回归的 方式来进行处理。 建模实际上是一个高度迭代化的过程。也就是说,我们会拿航班的历史数据 中的一部分,不断地作为输入去产生输出,拿输出和实际的值进行比较,然后不 断地校正中间逻辑回归模型中的参数。所以我们可以看到建模过程是一个高度迭 代化的过程,在这个过程中,模型是在不断地被修正的。 当我们确定好一个模型之后,就要去对这个模型进行评估。例如,我们拿出 历史数据集中没有去训练这个模型的那一部分数据进行校验,来判断这个模型是 否准确。我们不断地拿这种测试用例输入到建立的模型中,根据模型的输出值和 实际值之间的差异来评估模型的准确性。如果用户对数据分析的性能也很在意, 那么在评估过程中还要去评估模型的性能。毕竟,对于模型的准确性而言,高性 能虽然是用户所希望的,但是如果模型过于费时,它的计算复杂度过高,性能很 差,也并不是用户希望的。所以在模型评估的阶段,我们可能会涉及到多个目标 或者是多个约束条件的测试和评估
De濿ayed,True 就表示是延误的航班,Fa濿se 是没有延误的航班。所以我们看到特 征工程是从数据集中抽取出一些特征,并标记在数据集中。 到这里为止,数据就准备好了,下面就可以去做数据的分析了。在前面的这 几个步骤中,我们是可以不断地进行迭代的。不断地迭代就可以不断地提高数据 的质量,就可以有助于最后数据分析质量的提高。 紧接着,我们来建模。建模就是要确定在数据分析过程中的输入是什么?输 出是什么?中间使用的是什么样的算法或技术。在建模时,我们确定输入是航班 的起飞时间,包括年月日和出发时间以及目标机场,输出期望是预测这个航班是 否会延误,就是一个 b瀂瀂濿 值,即 True 或 Fa濿se。中间我们希望使用逻辑回归的 方式来进行处理。 建模实际上是一个高度迭代化的过程。也就是说,我们会拿航班的历史数据 中的一部分,不断地作为输入去产生输出,拿输出和实际的值进行比较,然后不 断地校正中间逻辑回归模型中的参数。所以我们可以看到建模过程是一个高度迭 代化的过程,在这个过程中,模型是在不断地被修正的。 当我们确定好一个模型之后,就要去对这个模型进行评估。例如,我们拿出 历史数据集中没有去训练这个模型的那一部分数据进行校验,来判断这个模型是 否准确。我们不断地拿这种测试用例输入到建立的模型中,根据模型的输出值和 实际值之间的差异来评估模型的准确性。如果用户对数据分析的性能也很在意, 那么在评估过程中还要去评估模型的性能。毕竟,对于模型的准确性而言,高性 能虽然是用户所希望的,但是如果模型过于费时,它的计算复杂度过高,性能很 差,也并不是用户希望的。所以在模型评估的阶段,我们可能会涉及到多个目标 或者是多个约束条件的测试和评估