
数据科学引论-Python之道 第5课数据收集 一、Python网络爬虫实践样例一 我们将通过使用Python编写一个爬虫脚本,从网页上爬取数据集,这需要 综合地使用Python所涉及的基本语法,然后同时也掌握一些爬虫的技巧。 首先,我们需要了解爬虫是什么,包括理解URL、爬虫机制、网页HTML的 基本概念。我们在浏览网页的时候,肯定会希望得到网页中的一些关键内容和一 些有趣的图片,你想把它们直接批量下载下来,这就是需要爬虫来支持。爬虫 crawler,即网络爬虫Spider,是一个能够自动化地访问互联网并将网站内容下载 下来的的程序或脚本。 在爬取之前,我们需要定位网址,也就是URL,我们要通过URL选择要爬取 的网页。URL可以理解为网址,它是一个路径,一个指向网页的路径。我们将通 过指定很多个网页路径的方式来对网页进行批量爬取。爬虫任务会使用到一些 Python的类、列表、字典、循环等基础语法。 我们的任务是从名人名言的网站爬取其前两页。我们可以点击进去看一下这 个网页的内容。该网页分为了好几部分,有好几条名言,每一条名言都会显示其 内容,作者和标签。我们的任务就是爬取每一条名言当中的文字内容、作者以及 标签,并且以SON格式保存到文件中,那么我们需要关注什么呢?
数据科学引论-P瀌瀇濻瀂瀁 之道 第 5 课 数据收集 一、P瀌瀇濻瀂瀁 网络爬虫实践 样例一 我们将通过使用 P瀌瀇濻瀂瀁 编写一个爬虫脚本,从网页上爬取数据集,这需要 综合地使用 P瀌瀇濻瀂瀁 所涉及的基本语法,然后同时也掌握一些爬虫的技巧。 首先,我们需要了解爬虫是什么,包括理解 URL、爬虫机制、网页 HTML 的 基本概念。我们在浏览网页的时候,肯定会希望得到网页中的一些关键内容和一 些有趣的图片,你想把它们直接批量下载下来,这就是需要爬虫来支持。爬虫 濶瀅濴瀊濿濸瀅,即网络爬虫 S瀃濼濷濸瀅,是一个能够自动化地访问互联网并将网站内容下载 下来的的程序或脚本。 在爬取之前,我们需要定位网址,也就是 URL,我们要通过 URL 选择要爬取 的网页。URL 可以理解为网址,它是一个路径,一个指向网页的路径。我们将通 过指定很多个网页路径的方式来对网页进行批量爬取。爬虫任务会使用到一些 P瀌瀇濻瀂瀁 的类、列表、字典、循环等基础语法。 我们的任务是从名人名言的网站爬取其前两页。我们可以点击进去看一下这 个网页的内容。该网页分为了好几部分,有好几条名言,每一条名言都会显示其 内容,作者和标签。我们的任务就是爬取每一条名言当中的文字内容、作者以及 标签,并且以 JSON 格式保存到文件中,那么我们需要关注什么呢?

→C⊙quotes.toscrape,com/page.2l Quotes to Scrape "This life is what you make it.No matter what,you're going to sometimes,it's a universal truth.But the good part is you get t how you're going to mess it up.Girls will be your friends-they anyway.But just remember,some come,some go.The ones t 我们使用的是Scrapy爬虫,它使用Python编写的爬虫,其中最主要的是 scrapy..spider类,它有两个方法需要我们关注,一个是init初始化方法,一个是 parse解析方法,分别代表了爬取过程中的两个步骤。在init方法中,我们需要 设置网站列表和保存文件的路径,前者决定了需要爬取哪些网站,后者确定了爬 取内容的保存方式。parse则指明了在每一个网页上需要爬取哪些内容,以及如 何进行爬取。下图显示了爬虫工作的过程: 机构 投资总数最新投资事件 Secur htps://www.itjuzi.com/ Scrapy 25 IDG资本 725 品生医学 3经纬中国 602 皇包车 URL HTML TOOL FORMAT 地址 网页原内容 工具 格式 统一资源定位 网页内容编码 爬虫工具 统化格式 符网址) 根据urd指定 我们要从中 访问网页并 得到信息将 需要爬取的 提取我们需 从html解析 数据整理成 网页 要的关键信 信息的具体 统一格式导 息 工具,如 出 Scrapy 在init的方法中,我们需要关注两个变量,一个是self.urls,表示待爬取网站 的列表;另一个是sef.fle,表示的是用于输出的文件对象。 parse方法针对每一个URL,决定了在网页内容爬取下来之后,如何解析它 们,即如何从中提取到一些关键的内容。这里需要使用一些Scrapy的选择器, 选择器的语法其实很多。在这里,我们这个样例中只用到了很小的一部分,如果 你想去深入地了解,那么我们可以点击notebook上的链接,它是一个很全面的
我们使用的是 S濶瀅濴瀃瀌 爬虫,它使用 P瀌瀇濻瀂瀁 编写的爬虫,其中最主要的是 瀆濶瀅濴瀃瀌.瀆瀃濼濷濸瀅 类,它有两个方法需要我们关注,一个是 濼瀁濼瀇 初始化方法,一个是 瀃濴瀅瀆濸 解析方法,分别代表了爬取过程中的两个步骤。在 濼瀁濼瀇 方法中,我们需要 设置网站列表和保存文件的路径,前者决定了需要爬取哪些网站,后者确定了爬 取内容的保存方式。瀃濴瀅瀆濸 则指明了在每一个网页上需要爬取哪些内容,以及如 何进行爬取。下图显示了爬虫工作的过程: 在 濼瀁濼瀇 的方法中,我们需要关注两个变量,一个是 瀆濸濿濹.瀈瀅濿瀆,表示待爬取网站 的列表;另一个是 瀆濸濿濹.濹濼濿濸,表示的是用于输出的文件对象。 瀃濴瀅瀆濸 方法针对每一个 URL,决定了在网页内容爬取下来之后,如何解析它 们,即如何从中提取到一些关键的内容。这里需要使用一些 S濶瀅濴瀃瀌 的选择器, 选择器的语法其实很多。在这里,我们这个样例中只用到了很小的一部分,如果 你想去深入地了解,那么我们可以点击 瀁瀂瀇濸濵瀂瀂濾 上的链接,它是一个很全面的
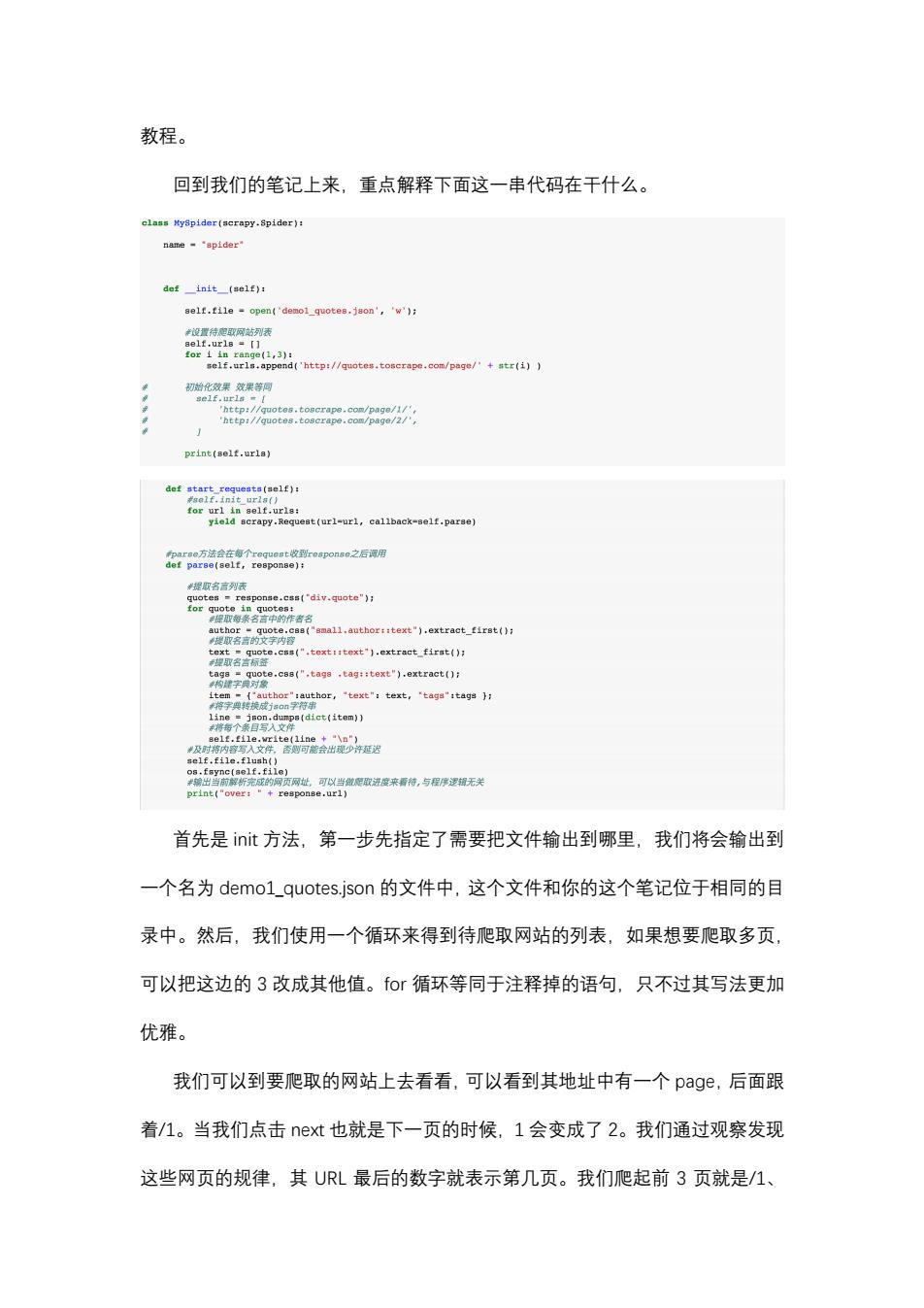
教程。 回到我们的笔记上来,重点解释下面这一串代码在干什么。 class NySpider(serapy.Spider): name -"spider" def_init_〔elf)r aelf.file open('demol_quotes.json','w'); 来设置特爬取网站列表 ae1f,ur1s=【1 for i in range(1,3): self.urls.append('http://quotes.toscrape.com/page/'+str(i) 初始化效果效果等同 self.urls=[ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/', print(self.urla) e(urlul,callbaek-aeif-paree) 米提飘名言列表 quotes response.css("div.quote"); coCegoeteat1etocttnti ote.c88(".tags .tag::text").extract(); oF,text,) ·c网址可以当做爬取进度来特,与程序逻无关 (self.file) print("over:"+response.url) 首先是iit方法,第一步先指定了需要把文件输出到哪里,我们将会输出到 一个名为demo1_quotes.json的文件中,这个文件和你的这个笔记位于相同的目 录中。然后,我们使用一个循环来得到待爬取网站的列表,如果想要爬取多页, 可以把这边的3改成其他值。for循环等同于注释掉的语句,只不过其写法更加 优雅。 我们可以到要爬取的网站上去看看,可以看到其地址中有一个page,后面跟 着/1。当我们点击next也就是下一页的时候,1会变成了2。我们通过观察发现 这些网页的规律,其URL最后的数字就表示第几页。我们爬起前3页就是/1
教程。 回到我们的笔记上来,重点解释下面这一串代码在干什么。 首先是 濼瀁濼瀇 方法,第一步先指定了需要把文件输出到哪里,我们将会输出到 一个名为 濷濸瀀瀂1_瀄瀈瀂瀇濸瀆.濽瀆瀂瀁 的文件中,这个文件和你的这个笔记位于相同的目 录中。然后,我们使用一个循环来得到待爬取网站的列表,如果想要爬取多页, 可以把这边的 3 改成其他值。濹瀂瀅 循环等同于注释掉的语句,只不过其写法更加 优雅。 我们可以到要爬取的网站上去看看,可以看到其地址中有一个 瀃濴濺濸,后面跟 着/1。当我们点击 瀁濸瀋瀇 也就是下一页的时候,1 会变成了 2。我们通过观察发现 这些网页的规律,其 URL 最后的数字就表示第几页。我们爬起前 3 页就是/1

/2、3,爬取两页就是/1、/2。 start_request函数我们不用去深究,这是涉及到Scrapy语法的问题。如果你 有兴趣去修改,可以去参考其教程。 我们回到爬虫当中最复杂也就是最关键的一部分,就是专门负责如何去解析 的parser函数,它有一个参数叫做response,其中包含的就是从网页上爬取下 来的所有HTML代码,然后我们将分条目从里面获取到我们想要的信息。 首先,我们看到的是quotes=response.css(div.quote"),这条语句的意思是 提取出名言列表。什么是名言列表?网页爬虫的工作过程是跟网页密切相关的。 我们回到第一页,可以看到其中包含好几条名言,爬虫实际解析的是HTML代 码,我们可以看右边HTML代码中有好几个div,每一个class为quotes的div 就是一条名言。 t年50.451,2 arm The world as we have created it is a process of our thinking.It cannot be changed without changing our thinking." by Albert Einstein (about) Tags:chanpe deep-thoughts thinking world "It is our choices,Harry,that show what we truly are,far more than our abilities." by J.K.Rowling (about) dlv ctass-"tags"/div </div> Tags:abities choices e ty=htp/ sdmagentyoe-http/ "There are only two ways to live your life.One is as though nothing is a miracle.The other is as though everything is a miracle. 我们通过选择器把名言一条一条地区分开来,然后再从中展开得到里面的名 言信息。第一条语句的含义就是将HTML代码中的所有div的class等于quote 的名言以列表形式一条一条全部提取出来。一旦这条语句执行完,我们就会提取 到每条已经分隔开的名言了。然后,我们要对每一条名言提取关键内容,即名言 内容,作者以及标签的提取,代码中的for循环就是对每一条名言进行这样的操
/2、/3,爬取两页就是/1、/2。 瀆瀇濴瀅瀇_瀅濸瀄瀈濸瀆瀇 函数我们不用去深究,这是涉及到 S濶瀅濴瀃瀌 语法的问题。如果你 有兴趣去修改,可以去参考其教程。 我们回到爬虫当中最复杂也就是最关键的一部分,就是专门负责如何去解析 的 瀃濴瀅瀆濸瀅 函数,它有一个参数叫做 瀅濸瀆瀃瀂瀁瀆濸,其中包含的就是从网页上爬取下 来的所有 HTML 代码,然后我们将分条目从里面获取到我们想要的信息。 首先,我们看到的是 瀄瀈瀂瀇濸瀆 = 瀅濸瀆瀃瀂瀁瀆濸.濶瀆瀆("濷濼瀉.瀄瀈瀂瀇濸"), 这条语句的意思是 提取出名言列表。什么是名言列表?网页爬虫的工作过程是跟网页密切相关的。 我们回到第一页,可以看到其中包含好几条名言,爬虫实际解析的是 HTML 代 码,我们可以看右边 HTML 代码中有好几个 濷濼瀉,每一个 濶濿濴瀆瀆 为 瀄瀈瀂瀇濸瀆 的 濷濼瀉 就是一条名言。 我们通过选择器把名言一条一条地区分开来,然后再从中展开得到里面的名 言信息。第一条语句的含义就是将 HTML 代码中的所有 濷濼瀉 的 濶濿濴瀆瀆 等于 瀄瀈瀂瀇濸 的名言以列表形式一条一条全部提取出来。一旦这条语句执行完,我们就会提取 到每条已经分隔开的名言了。然后,我们要对每一条名言提取关键内容,即名言 内容,作者以及标签的提取,代码中的 濹瀂瀅 循环就是对每一条名言进行这样的操

作。在循环中,我们先提取每条名言中的作者名,在每个quote对象上调用css 函数,找到HTML中的smal.author,提取其中的文本内容。由于一条名言可能 包含多条smal.author,所以我们使用extract_first()提取第一条。接下来,我们再 提取名言的文字内容,就是class=text中的文本内容,并且提取第一条信息。最 后,我们要提取tags,tags有一点特殊,因为每条名言都有好几个tag,我们希 望都能提取出来,所以提取它时不是调用extract_first(),而是调用extract0,这 时会返回一个列表。 最终,当我们得到三项关键信息之后,我们需要做一个整合,并输出整合的 内容。因为我们目标是JSON格式,并且Python提供将字典直接转换成JSON的 功能,所以我们先要把这三个变量转换成字典,然后将字典转换成JSON,最后 写入到文件。最后两条语句是为了及时SON字符串写入文件,如果不写它们, 写入就会在缓满了或其他适当条件满足时才触发。我们暂时不用去深究这两条语 句的含义。 每一个parser只针对一个网页,因为我们之前指定了两个网页,所以它会分 别对两个网页都执行一遍,把所有的数据都爬取下来,并且输出到一个文件中。 之后,我们就要执行一下这个爬虫来看看效果。 前面的代码只是在定义爬虫任务,然后我们要如何真正执行任务呢?就需要 让Scrapy去执行process..start)(,我们可以看到它输出的一些调试信息, 执行爬虫任务 启动后,将执行My9pde,这御分的代码块,如果确实非常了解scrapy的运行机制,那么可以做定制,否测不建议自行修改。 In [2]:from scrapy.cravler import CrawlerProcess process.crawl(MySpider) process..start()这句代码就是开始了整个泥虫过程,会输出一大维信息,可以无规 我们可以从目录中找到写出的SON文件,使用文本编辑器打开,就可以发
作。在循环中,我们先提取每条名言中的作者名,在每个 瀄瀈瀂瀇濸 对象上调用 濶瀆瀆 函数,找到 HTML 中的 瀆瀀濴濿濿.濴瀈瀇濻瀂瀅,提取其中的文本内容。由于一条名言可能 包含多条 瀆瀀濴濿濿.濴瀈瀇濻瀂瀅,所以我们使用 濸瀋瀇瀅濴濶瀇_濹濼瀅瀆瀇()提取第一条。接下来,我们再 提取名言的文字内容,就是 濶濿濴瀆瀆=瀇濸瀋瀇 中的文本内容,并且提取第一条信息。最 后,我们要提取 瀇濴濺瀆,瀇濴濺瀆 有一点特殊,因为每条名言都有好几个 瀇濴濺,我们希 望都能提取出来,所以提取它时不是调用 濸瀋瀇瀅濴濶瀇_濹濼瀅瀆瀇(),而是调用 濸瀋瀇瀅濴濶瀇(),这 时会返回一个列表。 最终,当我们得到三项关键信息之后,我们需要做一个整合,并输出整合的 内容。因为我们目标是 JSON 格式,并且 P瀌瀇濻瀂瀁 提供将字典直接转换成 JSON 的 功能,所以我们先要把这三个变量转换成字典,然后将字典转换成 JSON,最后 写入到文件。最后两条语句是为了及时 JSON 字符串写入文件,如果不写它们, 写入就会在缓满了或其他适当条件满足时才触发。我们暂时不用去深究这两条语 句的含义。 每一个 瀃濴瀅瀆濸瀅 只针对一个网页,因为我们之前指定了两个网页,所以它会分 别对两个网页都执行一遍,把所有的数据都爬取下来,并且输出到一个文件中。 之后,我们就要执行一下这个爬虫来看看效果。 前面的代码只是在定义爬虫任务,然后我们要如何真正执行任务呢?就需要 让 S濶瀅濴瀃瀌 去执行 瀃瀅瀂濶濸瀆瀆.瀆瀇濴瀅瀇(),我们可以看到它输出的一些调试信息, 我们可以从目录中找到写出的 JSON 文件,使用文本编辑器打开,就可以发