
第12卷第5期 智能系统学报 Vol.12 No.5 2017年10月 CAAI Transactions on Intelligent Systems 0ct.2017 D0I:10.11992/is.201706033 网络出版地址:htp:/kns.cmki.net/kcms/detail/23.1538.TP.20170831.1058.018.html 基于Spark的多标签超网络集成学习 李航,王进2,赵蕊2 (1.重庆邮电大学软件工程学院,重庆400065:2.重庆邮电大学计算智能重庆市重点实验室,重庆400065) 摘要:近年来,多标签学习在图像识别和文本分类等多个领域得到了广泛关注,具有越来越重要的潜在应用价值。 尽管多标签学习的发展日新月异,但仍然存在两个主要挑战,即如何利用标签间的相关性以及如何处理大规模的多 标签数据。针对上述问题,基于MLHN算法,提出一种能有效利用标签相关性且能处理大数据集的基于Sak的多 标签超网络集成算法SE-MLHN。该算法首先引人代价敏感,使其适应不平衡数据集。其次,改良了超网络演化学 习过程,并优化了损失函数,降低了算法时间复杂度。最后,进行了选择性集成,使其适应大规模数据集。在11个不 同规模的数据集上进行实验,结果表明,该算法具有较好的分类性能,较低的时间复杂度且具备良好的处理大规模 数据集的能力。 关键词:多标签学习;超网络:标签相关性;Apache Spark;选择性集成学习 中图分类号:TP181文献标志码:A文章编号:1673-4785(2017)05-0624-16 中文引用格式:李航,王进,赵蕊.基于Spark的多标签超网络集成学习[J].智能系统学报,2017,12(5):624-639. 英文引用格式:LI Hang,WANG Jin,ZHAO Rui.Multi-label hypernetwork ensemble learning based on Spark[J].CAAI transactions on intelligent systems,2017,12(5):624-639. Multi-label hypernetwork ensemble learning based on Spark LI Hang',WANG Jin2,ZHAO Rui2 (1.College of Software Engineering,Chongqing University of Posts and Telecommunications,Chongqing 400065,China;2.Chongqing Key Laboratory of Computational Intelligence,Chongging University of Posts and Telecommunications,Chongging 400065,China) Abstract:Multi-label learning has attracted a great deal of attention in recent years and has a wide range of potential real-world applications,including image identification and text categorization.Although great effort has been expended in the development of multi-label learning,two main challenges remain,i.e.,how to utilize the correlation between labels and how to tackle large-scale multi-label data.To solve these challenges,based on the multi-label hypernetwork (MLHN)algorithm,in this paper,we propose a Spark-based multi-label hypernetwork ensemble algorithm(SEI-MLHN)that effectively utilizes label correlation and can deal with large-scale multi-label datasets.First,the algorithm introduces cost sensitivity to enable it to adapt to unbalanced datasets.Secondly,it improves the hypernetwork evolution learning process,optimizes the loss function,and reduces the inherent time complexity.Lastly,it uses selective ensemble learning to enable it to adapt to large-scale datasets.We conducted experiments on 11 datasets wit different scales.The results show that the proposed algorithm demonstrates excellent categorization performance,low time complexity,and the capability to handle large-scale datasets. Keywords:multi-label learning;hypernetwork;label correlations;Apache Spark;selective ensemble learning 多标签学习在文本分类】、图像注释[3]和生有越来越重要的应用价值。在多标签学习中,训练 物信息学)等多个应用领域得到了广泛关注,也具 集的一个样本均对应一组标签集合。假设X表示 样本空间,Y={1,2,…,9}表示所有可能的标签集 收稿日期:2017-06-09.网络出版日期:2017-08-31. 合,其中标签的总数为q,T={(x1,Y),(x2,Y2),, 基金项目:重庆市基础与前沿研究计划项目(cstc2014 jeyiA40001, cstc2014 jcyjA40022):重庆教委科学技术研究项目(自然科 (xm,Ym)}为具有m个样本的训练集,其中x:∈X且 学类)(K1400436). Y二Y。则多标签分类的目标是输出一个多标签分 通信作者:李航.E-mail:1326202954@q4.com
第 12 卷第 5 期 智 能 系 统 学 报 Vol.12 №.5 2017 年 10 月 CAAI Transactions on Intelligent Systems Oct. 2017 DOI:10.11992 / tis.201706033 网络出版地址:http: / / kns.cnki.net / kcms/ detail / 23.1538.TP.20170831.1058.018.html 基于 Spark 的多标签超网络集成学习 李航1 ,王进2 ,赵蕊2 (1.重庆邮电大学 软件工程学院,重庆 400065; 2. 重庆邮电大学 计算智能重庆市重点实验室,重庆 400065) 摘 要:近年来,多标签学习在图像识别和文本分类等多个领域得到了广泛关注,具有越来越重要的潜在应用价值。 尽管多标签学习的发展日新月异,但仍然存在两个主要挑战,即如何利用标签间的相关性以及如何处理大规模的多 标签数据。 针对上述问题,基于 MLHN 算法,提出一种能有效利用标签相关性且能处理大数据集的基于 Spark 的多 标签超网络集成算法 SEI-MLHN。 该算法首先引入代价敏感,使其适应不平衡数据集。 其次,改良了超网络演化学 习过程,并优化了损失函数,降低了算法时间复杂度。 最后,进行了选择性集成,使其适应大规模数据集。 在 11 个不 同规模的数据集上进行实验,结果表明,该算法具有较好的分类性能,较低的时间复杂度且具备良好的处理大规模 数据集的能力。 关键词:多标签学习;超网络;标签相关性;Apache Spark;选择性集成学习 中图分类号:TP181 文献标志码:A 文章编号:1673-4785(2017)05-0624-16 中文引用格式:李航,王进,赵蕊.基于 Spark 的多标签超网络集成学习[J]. 智能系统学报, 2017, 12(5): 624-639. 英文引用 格 式: LI Hang, WANG Jin, ZHAO Rui. Multi⁃label hypernetwork ensemble learning based on Spark [ J ]. CAAI transactions on intelligent systems, 2017, 12(5): 624-639. Multi⁃label hypernetwork ensemble learning based on Spark LI Hang 1 , WANG Jin 2 , ZHAO Rui 2 (1.College of Software Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China; 2. Chongqing Key Laboratory of Computational Intelligence, Chongqing University of Posts and Telecommunications, Chongqing 400065, China) Abstract:Multi⁃label learning has attracted a great deal of attention in recent years and has a wide range of potential real⁃world applications, including image identification and text categorization. Although great effort has been expended in the development of multi⁃label learning, two main challenges remain, i. e., how to utilize the correlation between labels and how to tackle large⁃scale multi⁃label data. To solve these challenges, based on the multi⁃label hypernetwork (MLHN) algorithm, in this paper, we propose a Spark⁃based multi⁃label hypernetwork ensemble algorithm (SEI⁃MLHN) that effectively utilizes label correlation and can deal with large⁃scale multi⁃label datasets. First, the algorithm introduces cost sensitivity to enable it to adapt to unbalanced datasets. Secondly, it improves the hypernetwork evolution learning process, optimizes the loss function, and reduces the inherent time complexity. Lastly, it uses selective ensemble learning to enable it to adapt to large⁃scale datasets. We conducted experiments on 11 datasets wit different scales. The results show that the proposed algorithm demonstrates excellent categorization performance, low time complexity, and the capability to handle large⁃scale datasets. Keywords:multi⁃label learning; hypernetwork; label correlations; Apache Spark; selective ensemble learning 收稿日期:2017-06-09. 网络出版日期:2017-08-31. 基金项 目: 重 庆 市 基 础 与 前 沿 研 究 计 划 项 目 ( cstc2014jcyjA40001, cstc2014jcyjA40022);重庆教委科学技术研究项目(自然科 学类)(KJ1400436). 通信作者:李航.E⁃mail:1326202954@ qq.com. 多标签学习在文本分类[1-2] 、图像注释[3-4]和生 物信息学[5]等多个应用领域得到了广泛关注,也具 有越来越重要的应用价值。 在多标签学习中,训练 集的一个样本均对应一组标签集合。 假设 X 表示 样本空间,Y = {1,2,…,q} 表示所有可能的标签集 合,其中标签的总数为 q,T = {(x1 ,Y1 ),(x2 ,Y2 ),…, (xm ,Ym )}为具有 m 个样本的训练集,其中 xi∈X 且 Yi⊆Y。 则多标签分类的目标是输出一个多标签分

第5期 李航,等:基于Spark的多标签超网络集成学习 ·625· 类器h:x→2',使得对每一个给定的实例x∈X,都能 据集,同时算法也未考虑到标签不平衡对性能的 预测出合适的标签集合Y·二Y。 影响。 多标签学习的关键挑战在于分类器预测的标 针对目前多标签超网络存在的问题,本文基于 签空间数量为指数级(2)。为了解决这个问题,有 MLHN的思想,提出了Spark平台下的改进多标签 效地利用不同标签之间的相关性以促进学习过程 超网络集成算法SEI-MLHN,有效且高效地解决了 已成为多标签学习的关键6-刃。在过去几年,许多 多标签学习问题。首先对多标签数据集进行划分: 利用标签相关性的算法被提出,如校准标签排序 然后对划分后的数据分别用基于Spark平台的改进 (CLR)[)⑧,随机k标签集(RAkEL)[)和广义k标签 超网络算法SI-MLHN进行训练,形成多个局部超网 集成(GLE)[均考虑了标签之间的相关性,然而这 络:最后对多个局部超网络进行选择性集成完成对 些算法的计算复杂度随标签数量的增加而显著 测试样本的预测。其中,SI-MLHN利用MLHN的思 增加。 想并在Spark平台下进行改进,首先计算每个样本 同时,大部分现有的多标签学习方法没有充分 的k近邻,然后利用k近邻对超网络进行演化学习, 考虑多标签数据的固有属性,即标签类别不平衡。 得到演化超网络。 对每一个标签y∈Y,令D={(x,+1)y∈Y:,1≤ 为了评估本文算法的性能以及对大规模数据 i≤N}以及D={(x:,-1)lyY:,1≤i≤N}作为正 集的适应性,选用不同规模数据集来进行对比实 样本和负样本。一般来说,每个类别的正训练样本 验,验证了本文算法具有良好性能以及具备处理大 数远远低于其负训练样本数,这可能导致大多数多 规模数据集的能力。本文的主要贡献如下: 标签学习算法的性能降低。文献[12-14]指出, 1)引入了代价敏感,使其能良好地适应多标签 不平衡问题普遍存在于多标签应用中,会损害分类 不平衡数据,提升算法性能; 性能。算法交叉耦合聚合学习方法(cross-coupling 2)改良了超网络演化学习过程,大幅度降低 aggregation,COCOA)[同时考虑了标签相关性和 MLHN算法的计算复杂度: 不平衡问题,同样其算法复杂度很高,因此如何有 3)利用选择性集成,降低了时间复杂度,并提 效和高效地利用标签间的相关性并削弱不平衡问 高分类性能; 题的影响仍然是一个悬而未决的问题。 4)基于Spark计算框架实现算法,使算法实现 另一方面,目前现实应用中的多标签数据集的 并行,提高算法运行效率。 样本、特征和标签的数量远远超过常规大小,例如, 1 相关工作 视频共享网站Youtube中有数百万个视频,而每个 视频可以被数百万个候选类别标记。然而,大多数 虽然多标签学习已经成功应用于生物信息学 多标签学习算法不能很好地适应数据集规模很大 音频分类[2]以及wb挖掘2]等多个领域,但是由 的应用。对近3年出现的多标签学习方法[5-]使 于多标签分类器的输出空间为指数级,以及现在大 用的训练集的规模进行统计,可以看出训练样本数 部分应用的数据集规模日益增加,对多标签学习造 在50000~100000之间的数据集仅有5个,样本数 成了很大的挑战。 大于100000的数据集仅有1个,大多数现有的多标 为了应对分类器输出空间数量巨大这个问题, 签学习算法仅适用于处理中小规模数据集。其次, 现有的方法是利用标签相关性来促进学习过程。 文献[19]虽然利用大规模数据集进行了实验,但是 基于标签关联性,张敏灵和周志华[7-]将现有的学 它的计算复杂度高。 习算法分为3类,分别为一阶策略、二阶策略以及高 多标签超网络LHN与协同演化多标签超网 阶策略。一阶策略是简单地将多标签学习转为多 络Co-MLHN[24]可以挖掘标签间的高阶关系,它将 个独立的二分类问题来解决多标签学习问题,例如 传统的超网络转为多标签超网络,用超边和超边的 L-KNN2]、BR[30]等:二阶策略通过利用标签之间 权重来表示特征子集与标签之间的高阶关系,利用 的成对关系解决多标签学习问题,例如CLR31] 了任意标签间的相关性,且计算复杂度随标签数量 BP-ML[)]等:高阶策略通过探索标签之间的高阶 的增加呈线性增长,但是其算法时间复杂度与样本 关系来解决多标签学习问题,例如CC[3)、CNMF[34] 数量呈平方级关系,不能很好地处理规模较大的数 等。对这3种策略进行比较分析,一阶策略的效率
类器 h:x→2 y ,使得对每一个给定的实例 x∈X,都能 预测出合适的标签集合 Y ∗⊆Y。 多标签学习的关键挑战在于分类器预测的标 签空间数量为指数级(2 q )。 为了解决这个问题,有 效地利用不同标签之间的相关性以促进学习过程 已成为多标签学习的关键[6-7] 。 在过去几年,许多 利用标签相关性的算法被提出,如校准标签排序 (CLR) [8] ,随机 k 标签集(RAkEL) [9] 和广义 k 标签 集成(GLE) [10]均考虑了标签之间的相关性,然而这 些算法的计算复杂度随标签数量的增加而显著 增加。 同时,大部分现有的多标签学习方法没有充分 考虑多标签数据的固有属性,即标签类别不平衡。 对每一个标签 yj∈Y,令 D + j = {(xi,+1) yj∈Yi,1≤ i≤N}以及 D - j = {(xi,-1) yj∉Yi,1≤i≤N}作为正 样本和负样本。 一般来说,每个类别的正训练样本 数远远低于其负训练样本数,这可能导致大多数多 标签学习算法的性能降低[11] 。 文献[12-14]指出, 不平衡问题普遍存在于多标签应用中,会损害分类 性能。 算法交叉耦合聚合学习方法( cross⁃coupling aggregation, COCOA) [14] 同时考虑了标签相关性和 不平衡问题,同样其算法复杂度很高,因此如何有 效和高效地利用标签间的相关性并削弱不平衡问 题的影响仍然是一个悬而未决的问题。 另一方面,目前现实应用中的多标签数据集的 样本、特征和标签的数量远远超过常规大小,例如, 视频共享网站 Youtube 中有数百万个视频,而每个 视频可以被数百万个候选类别标记。 然而,大多数 多标签学习算法不能很好地适应数据集规模很大 的应用。 对近 3 年出现的多标签学习方法[15-23] 使 用的训练集的规模进行统计,可以看出训练样本数 在50 000~100 000之间的数据集仅有 5 个,样本数 大于100 000的数据集仅有 1 个,大多数现有的多标 签学习算法仅适用于处理中小规模数据集。 其次, 文献[19]虽然利用大规模数据集进行了实验,但是 它的计算复杂度高。 多标签超网络 MLHN 与协同演化多标签超网 络 Co⁃MLHN [24]可以挖掘标签间的高阶关系,它将 传统的超网络转为多标签超网络,用超边和超边的 权重来表示特征子集与标签之间的高阶关系,利用 了任意标签间的相关性,且计算复杂度随标签数量 的增加呈线性增长,但是其算法时间复杂度与样本 数量呈平方级关系,不能很好地处理规模较大的数 据集,同时算法也未考虑到标签不平衡对性能的 影响。 针对目前多标签超网络存在的问题,本文基于 MLHN 的思想,提出了 Spark 平台下的改进多标签 超网络集成算法 SEI⁃MLHN,有效且高效地解决了 多标签学习问题。 首先对多标签数据集进行划分; 然后对划分后的数据分别用基于 Spark 平台的改进 超网络算法 SI⁃MLHN 进行训练,形成多个局部超网 络;最后对多个局部超网络进行选择性集成完成对 测试样本的预测。 其中,SI⁃MLHN 利用 MLHN 的思 想并在 Spark 平台下进行改进,首先计算每个样本 的 k 近邻,然后利用 k 近邻对超网络进行演化学习, 得到演化超网络。 为了评估本文算法的性能以及对大规模数据 集的适应性,选用不同规模数据集来进行对比实 验,验证了本文算法具有良好性能以及具备处理大 规模数据集的能力。 本文的主要贡献如下: 1)引入了代价敏感,使其能良好地适应多标签 不平衡数据,提升算法性能; 2)改良了超网络演化学习过程,大幅度降低 MLHN 算法的计算复杂度; 3)利用选择性集成,降低了时间复杂度,并提 高分类性能; 4)基于 Spark 计算框架实现算法,使算法实现 并行,提高算法运行效率。 1 相关工作 虽然多标签学习已经成功应用于生物信息学、 音频分类[25] 以及 web 挖掘[26] 等多个领域,但是由 于多标签分类器的输出空间为指数级,以及现在大 部分应用的数据集规模日益增加,对多标签学习造 成了很大的挑战。 为了应对分类器输出空间数量巨大这个问题, 现有的方法是利用标签相关性来促进学习过程。 基于标签关联性,张敏灵和周志华[27-28] 将现有的学 习算法分为 3 类,分别为一阶策略、二阶策略以及高 阶策略。 一阶策略是简单地将多标签学习转为多 个独立的二分类问题来解决多标签学习问题,例如 ML⁃KNN [29] 、BR [30] 等;二阶策略通过利用标签之间 的成对关系解决多标签学习问题,例如 CLR [31 ] 、 BP⁃MLL [32]等;高阶策略通过探索标签之间的高阶 关系来解决多标签学习问题,例如 CC [33] 、CNMF [34] 等。 对这 3 种策略进行比较分析,一阶策略的效率 第 5 期 李航,等:基于 Spark 的多标签超网络集成学习 ·625·

·626 智能系统学报 第12卷 高且概念易理解,但忽略了标签相关性。二阶策略 首先,对多标签数据集进行划分,然后对划分后的 在一定程度上解决了标签相关性,但忽略了现实世 数据分别用SI-MLHN算法进行训练,形成多个局部 界中相关性超过二阶的情况。高阶策略具有比一 超网络,最后对多个局部超网络进行选择性集成完 阶和二阶更强的建模能力,但是其计算复杂度更 成对测试样本的预测。其中,算法SI-MLHN利用 高,可扩展性更低。 MLHN的思想,在Spark平台下进行改进,首先计算 为了应对多标签数据的不平衡性造成算法 每个样本的k近邻,然后利用k近邻对超网络进行 性能下降这个问题,常规解决方案是为每一个标 演化学习,得到超网络。本节中,将对算法MLHN, 签训练一个二分类器,并通过随机或合成欠采 MLHN的改进算法SI-MLHN,以及以SI-MLHN为基 样/过采样来处理这个二分类器[35-6],但这些方 学习器进行选择性集成的算法SEI-MLHN依次进行 法没有很好地利用标签间的关联性。也有其他 介绍。 的解决方案,如张敏灵等[1)提出交叉耦合聚合 2.1 多标签演化超网络(MLHN)】 算法C0COA,但是这种算法时间复杂度高,不适 多标签演化超网络利用超边集合以及超边权 合处理大规模数据集。 重来表示样本特征子集与多标签类别之间的高阶 为了应对数据集规模大这个问题,现有的解决 关联。通过演化学习,可以近似地表示训练样本X 方案是利用分布式存储系统,提供一个基础架构, 和其标签Y之间的概率分布P(X,Y),在MLHN中 从而实现高效和可扩展的大数据挖掘与分析。目 可以按式(1)进行表示: 前,为大数据分析开发了大量的计算框架7),其 P(x,y:=1) 中,最经典的是MapReduce[。MapReduce简单 P(y:=1x) P(x) 通用且成熟,被广泛使用,但是它只能进行M即和 0x%=19 Reduce计算,不适合描述复杂数据处理过程,数据 需要写到磁盘,不能有效地执行迭代算法。为了克 ,0=19)+y,10x=09 服MapReduce的缺点,大量的计算框架被设计出 (1) 来,如Haloop【wy、Apache Mahout[),i2 MapReduce 式中:y:为样本x的第i个标签;0:为超边集合 [o]和Apache Spark[a】等。Haloop是Hadoop |E|中e,的第i个权重向量的值;I(x,y:;e)为超边 MapReduce框架的修改版本,它继承了Hadoop的基 与样本匹配函数,若匹配则取值为1,反之则为0,如 本分布式计算模型和架构。Apache Mahout是一个 式(2)所示: 开源项目,主要用于创建可扩展的机器学习算法。 (1,dis(xn;e)≤8且y元=ym I(x。,ym;e;)= i2 MapReduce是MapReduce的一个增量处理扩展, 0,其他 并广泛用于大数据挖掘。Apache Spark是一个开源 (2) 的集群计算框架,用于大规模的交互计算。在上述 式中:ya是超边e的第i个标签,dis(xn;e)为超边 框架中,Apache Spark利用内存计算,并保留 e,与样本x的欧氏距离,δ为匹配阈值。δ的计算方 MapReduce的可扩展性和容错能力,对迭代算法非 法如式(3): 常有效。Spark执行速度比Hadoop MapReduce快 dim(e) G.lx dim(l 6= (3) 100倍[),并且显著快于其他计算框架。 综上所述,为了解决上述问题,本文使用Spark 式中:其中G,为x的近邻样本集合,dim(x)为样本 计算框架作为平台来实现多标签算法。 x的特征维度。 为了对未知样本进行预测,MLHN通常把标签 2 Spark下改进多标签超网络集成 预测误差和相关标签不一致性最小化作为演化学 算法 习目标。通过超边初始化、超边替代和梯度下降演 MLHN可以高效地挖掘标签间的关联性且学习 化学习来对训练集进行学习,使超边权重心:进行更 复杂度与标签维度呈线性关系,因此本文基于 新,流程如图1所示。图1中,超边ea=(",y4, MLHN算法提出了Spark平台下的改进多标签超网 w6),'a是超边的顶点,为x的部分特征;y。为x的 络集成算法SEI-MLHN,高效地解决了多标签问题。 标签;w是x.对应y.的权重向量
高且概念易理解,但忽略了标签相关性。 二阶策略 在一定程度上解决了标签相关性,但忽略了现实世 界中相关性超过二阶的情况。 高阶策略具有比一 阶和二阶更强的建模能力,但是其计算复杂度更 高,可扩展性更低。 为了应对多标签数据的不平衡性造成算法 性能下降这个问题,常规解决方案是为每一个标 签训练一个二分类器,并通过随机 或 合 成 欠 采 样 / 过采样来处理这个二分类器[ 35-36] ,但这些方 法没有很好地利用标签间的关联性。 也有其他 的解决方案,如张敏灵等[ 14] 提出交叉耦合聚合 算法 COCOA,但是这种算法时间复杂度高,不适 合处理大规模数据集。 为了应对数据集规模大这个问题,现有的解决 方案是利用分布式存储系统,提供一个基础架构, 从而实现高效和可扩展的大数据挖掘与分析。 目 前,为大数据分析开发了大量的计算框架[37-41] ,其 中,最经典的是 MapReduce [37] 。 MapReduce 简单、 通用且成熟,被广泛使用,但是它只能进行 Map 和 Reduce 计算,不适合描述复杂数据处理过程,数据 需要写到磁盘,不能有效地执行迭代算法。 为了克 服 MapReduce 的缺点,大量的计算框架被设计出 来,如 Haloop [38] 、Apache Mahout [39] 、i2MapReduce [40]和 Apache Spark [41] 等。 Haloop 是 Hadoop MapReduce 框架的修改版本,它继承了 Hadoop 的基 本分布式计算模型和架构。 Apache Mahout 是一个 开源项目,主要用于创建可扩展的机器学习算法。 i2MapReduce 是 MapReduce 的一个增量处理扩展, 并广泛用于大数据挖掘。 Apache Spark 是一个开源 的集群计算框架,用于大规模的交互计算。 在上述 框架 中, Apache Spark 利 用 内 存 计 算, 并 保 留 MapReduce 的可扩展性和容错能力,对迭代算法非 常有效。 Spark 执行速度比 Hadoop MapReduce 快 100 倍 [41] ,并且显著快于其他计算框架。 综上所述,为了解决上述问题,本文使用 Spark 计算框架作为平台来实现多标签算法。 2 Spark 下改进多标签超网络集成 算法 MLHN 可以高效地挖掘标签间的关联性且学习 复杂度 与 标 签 维 度 呈 线 性 关 系, 因 此 本 文 基 于 MLHN 算法提出了 Spark 平台下的改进多标签超网 络集成算法 SEI⁃MLHN,高效地解决了多标签问题。 首先,对多标签数据集进行划分,然后对划分后的 数据分别用 SI⁃MLHN 算法进行训练,形成多个局部 超网络,最后对多个局部超网络进行选择性集成完 成对测试样本的预测。 其中,算法 SI⁃MLHN 利用 MLHN 的思想,在 Spark 平台下进行改进,首先计算 每个样本的 k 近邻,然后利用 k 近邻对超网络进行 演化学习,得到超网络。 本节中,将对算法 MLHN, MLHN 的改进算法 SI⁃MLHN,以及以 SI⁃MLHN 为基 学习器进行选择性集成的算法 SEI⁃MLHN 依次进行 介绍。 2.1 多标签演化超网络(MLHN) 多标签演化超网络利用超边集合以及超边权 重来表示样本特征子集与多标签类别之间的高阶 关联。 通过演化学习,可以近似地表示训练样本 X 和其标签 Y 之间的概率分布 P(X,Y),在 MLHN 中 可以按式(1)进行表示: P(yi = 1 x) = P(x,yi = 1) P(x) = ∑ E j = 1 wji I(x,yi = 1;ej) ∑ E j = 1 wji I(x,yi = 1;ej) + ∑ E j = 1 wji I(x,yi = 0;ej) (1) 式中: yi 为样本 x 的第 i 个标签;wji 为超边集合 E 中 ej 的第 i 个权重向量的值;I(x,yi;ej)为超边 与样本匹配函数,若匹配则取值为 1,反之则为 0,如 式(2)所示: I(xn ,yni;ej) = 1, dis(xn ;ej) ≤ δ 且 yji = yni {0, 其他 (2) 式中:yji是超边 ej 的第 i 个标签, dis(xn ;ej) 为超边 ej 与样本 x 的欧氏距离,δ 为匹配阈值。 δ 的计算方 法如式(3): δ = dim(ej) Gx × dim(x)∑x′∈Gx ‖x - x′‖ (3) 式中:其中 Gx 为 x 的近邻样本集合,dim(x)为样本 x 的特征维度。 为了对未知样本进行预测,MLHN 通常把标签 预测误差和相关标签不一致性最小化作为演化学 习目标。 通过超边初始化、超边替代和梯度下降演 化学习来对训练集进行学习,使超边权重 wji进行更 新,流程如图 1 所示。 图 1 中,超边 eh = ( vh , yh , wh ),vh 是超边的顶点,为 x 的部分特征;yh 为 x 的 标签;wh 是 xh 对应 yh 的权重向量。 ·626· 智 能 系 统 学 报 第 12 卷
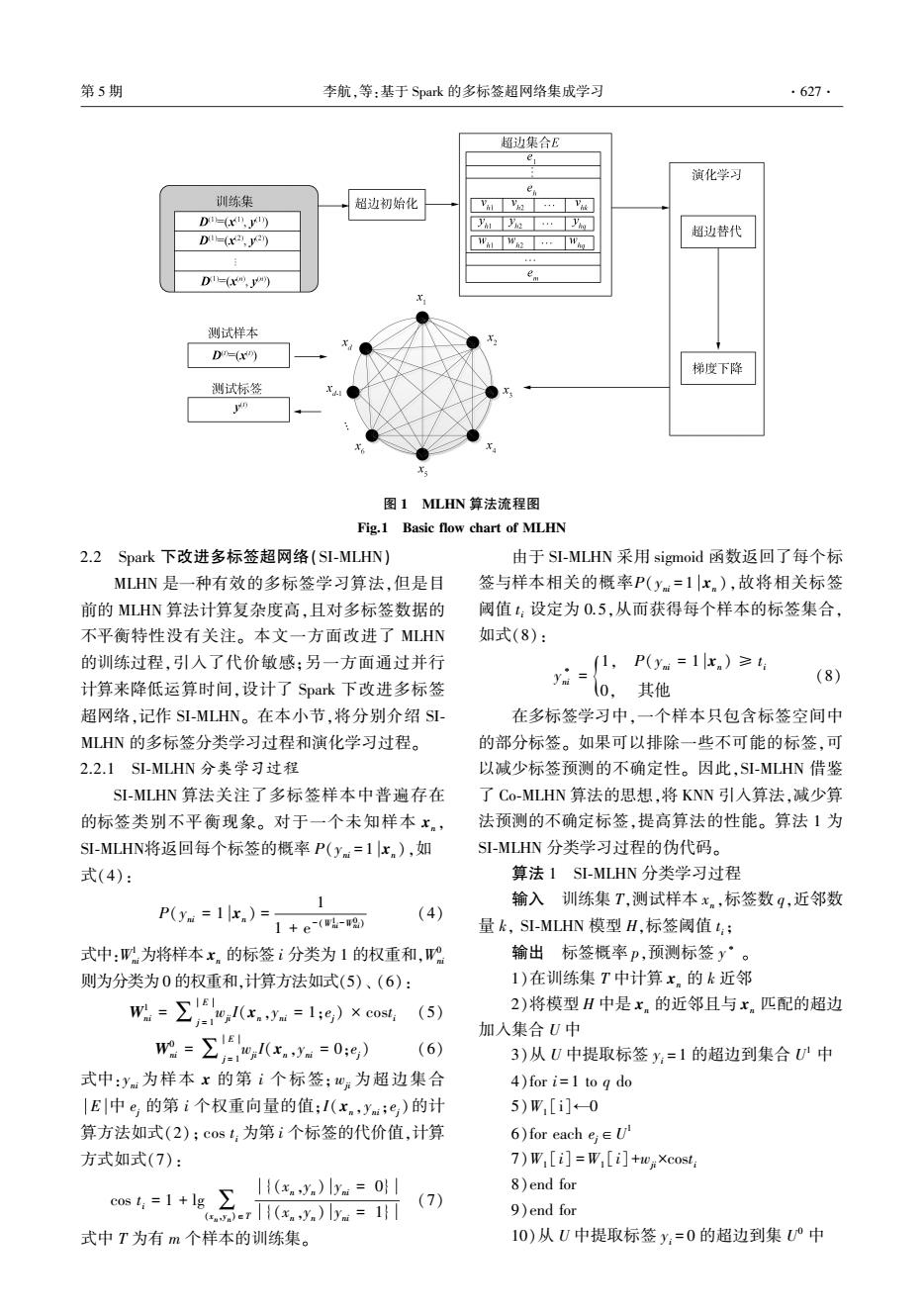
第5期 李航,等:基于Spark的多标签超网络集成学习 ·627. 超边集合E e 演化学习 e 训练集 超边初始化 VilVh2.Vis D(x) Y12·y 超边替代 D=(2,y2 W1w2…w D1=(xm,) 测试样本 D=(x) 梯度下降 测试标签 J” 图1MLHN算法流程图 Fig.1 Basic flow chart of MLHN 2.2 Spark下改进多标签超网络(Sl-MLHN) 由于SL-MLHN采用sigmoid函数返回了每个标 MLHN是一种有效的多标签学习算法,但是目 签与样本相关的概率P(ym=1x.),故将相关标签 前的MLHN算法计算复杂度高,且对多标签数据的 阈值:设定为0.5,从而获得每个样本的标签集合, 不平衡特性没有关注。本文一方面改进了MLHN 如式(8): 的训练过程,引入了代价敏感:另一方面通过并行 1,P(ym=1xn)≥ y= (8) 计算来降低运算时间,设计了Spark下改进多标签 0,其他 超网络,记作SI-MLHN。在本小节,将分别介绍SL 在多标签学习中,一个样本只包含标签空间中 MLHN的多标签分类学习过程和演化学习过程。 的部分标签。如果可以排除一些不可能的标签,可 2.2.1SI-MLHN分类学习过程 以减少标签预测的不确定性。因此,SI-MLHN借鉴 S-MLHN算法关注了多标签样本中普遍存在 了Co-MLHN算法的思想,将KNN引入算法,减少算 的标签类别不平衡现象。对于一个未知样本x。, 法预测的不确定标签,提高算法的性能。算法1为 SI-MLHN将返回每个标签的概率P(ym=1x),如 SI-MLHN分类学习过程的伪代码。 式(4): 算法1SI-MLHN分类学习过程 P(m=1x)=1 输入训练集T,测试样本x。,标签数q,近邻数 1+e(h-8) (4) 量k,SI-MLHN模型H,标签阈值t: 式中:W为将样本x。的标签i分类为1的权重和,W 输出标签概率p,预测标签y·。 则为分类为0的权重和,计算方法如式(5)、(6): 1)在训练集T中计算x。的k近邻 w=∑,10xa=1g)×c(5) 2)将模型H中是x.的近邻且与x匹配的超边 加入集合U中 明=,0x=05) (6) 3)从U中提取标签y:=1的超边到集合U中 式中:y为样本x的第i个标签;w:为超边集合 4)for i=1 to q do |E中e,的第i个权重向量的值;I(x.,ym;e)的计 5)W[i]←0 算方法如式(2);cost:为第i个标签的代价值,计算 6)for each e∈U 方式如式(7): 7)W,[i]=W,[i]+w元×cost (x)y=o 8)end for w4=1+器2 (7) 9)end for 式中T为有m个样本的训练集。 10)从中提取标签y,=0的超边到集°中
图 1 MLHN 算法流程图 Fig.1 Basic flow chart of MLHN 2.2 Spark 下改进多标签超网络(SI⁃MLHN) MLHN 是一种有效的多标签学习算法,但是目 前的 MLHN 算法计算复杂度高,且对多标签数据的 不平衡特性没有关注。 本文一方面改进了 MLHN 的训练过程,引入了代价敏感;另一方面通过并行 计算来降低运算时间,设计了 Spark 下改进多标签 超网络,记作 SI⁃MLHN。 在本小节,将分别介绍 SI⁃ MLHN 的多标签分类学习过程和演化学习过程。 2.2.1 SI⁃MLHN 分类学习过程 SI⁃MLHN 算法关注了多标签样本中普遍存在 的标签类别不平衡现象。 对于一个未知样本 xn , SI⁃MLHN将返回每个标签的概率 P(yni = 1 xn ),如 式(4): P(yni = 1 xn ) = 1 1 + e -(W1 ni -W0 ni ) (4) 式中:W 1 ni为将样本 xn 的标签 i 分类为 1 的权重和,W 0 ni 则为分类为 0 的权重和,计算方法如式(5)、 (6): W 1 ni = ∑ E j = 1 wji I(xn ,yni = 1;ej) × cost i (5) W 0 ni = ∑ E j = 1 wji I(xn ,yni = 0;ej) (6) 式中:yni 为样本 x 的第 i 个标签; wji 为超边集合 E 中 ej 的第 i 个权重向量的值;I( xn ,yni;ej)的计 算方法如式(2); cos t i 为第 i 个标签的代价值,计算 方式如式(7): cos t i = 1 + lg ∑ (xn ,yn )∈T {(xn ,yn ) yni = 0} {(xn ,yn ) yni = 1} (7) 式中 T 为有 m 个样本的训练集。 由于 SI⁃MLHN 采用 sigmoid 函数返回了每个标 签与样本相关的概率P(yni = 1 xn ),故将相关标签 阈值 t i 设定为 0.5,从而获得每个样本的标签集合, 如式(8): y ∗ ni = 1, P(yni = 1 xn ) ≥ t i 0, 其他 { (8) 在多标签学习中,一个样本只包含标签空间中 的部分标签。 如果可以排除一些不可能的标签,可 以减少标签预测的不确定性。 因此,SI⁃MLHN 借鉴 了 Co⁃MLHN 算法的思想,将 KNN 引入算法,减少算 法预测的不确定标签,提高算法的性能。 算法 1 为 SI⁃MLHN 分类学习过程的伪代码。 算法 1 SI⁃MLHN 分类学习过程 输入 训练集 T,测试样本 xn ,标签数 q,近邻数 量 k, SI⁃MLHN 模型 H,标签阈值 t i; 输出 标签概率 p,预测标签 y ∗ 。 1)在训练集 T 中计算 xn 的 k 近邻 2)将模型 H 中是 xn 的近邻且与 xn 匹配的超边 加入集合 U 中 3)从 U 中提取标签 yi = 1 的超边到集合 U 1 中 4)for i = 1 to q do 5)W1 [i]←0 6)for each ej∈U 1 7)W1 [i] =W1 [i]+wji ×cost i 8)end for 9)end for 10)从 U 中提取标签 yi = 0 的超边到集 U 0 中 第 5 期 李航,等:基于 Spark 的多标签超网络集成学习 ·627·

·628 智能系统学报 第12卷 11)for i=1 to q do 度越高,则适应值越高。同时,式(4)也展示出,样 12)W[i]←0 本与匹配超边的标签相似度越高,被正确分类的概 l3)for each e∈ 率越大。 14)W[i门=W[]+0月 本文将预测误差作为学习目标。损失函数如 15)end for 式(10)所示,P·(ym=1x.)为SI-MLHN分类器对 16)end for 样本(xmyn)的第i个标签的预测值,利用梯度下降 17)for i=1 to g do 调整超边的权重,降低损失值。超边权重更新为式 1 (11),并通过式(12)~(14),计算△0,其中心为 18)P(y:=1x.)=1+em-a可 第k条超边第i个标签的权重,)为学习速率。 19)p[i]=P(y:=1lxn) (网=2[P6.=小)-P.=1k 20)ifP(ym=1x.)≥t (10) 21)y·[i]=1 0后=10:+△10 (11) 22)else y·[i]=0 aErr,(W) 23)end if △10a=-7 (12) oWki 24)end for Err,(W) 25)return p,y' aw =(P(y=1x)- 2.2.2SI-MLHN演化学习过程 SI-MLHN利用超边的顶点和权重向量来代表 P*(y=1x)) ap'(y:=1x) (13) 8wki 多标签数据标签间的高阶关联,其权重向量由超边 1 从训练集中演化学习而来,首先进行了超边初始 ap'(yni=1x)1+e-(w-w&) 化,然后进行了超边替代与梯度下降演化学习,并 8w 利用Spark进行分布式并行计算,通过多个操作技 1 巧,如cache、broadst,.将变量缓存于内存中,大量减 1- 1+e-(w-w9 少了网络交换数据量和磁盘/0操作,使算法更 1+e-(-9) (14) 高效。 算法2为SI-MLHN的演化学习流程伪代码。 在超边初始化的过程中,利用样本(x,y)生成 由于本文采用欧氏距离作为距离度量,故需要先进 超边e=(v,,w),超边的顶点向量v随机地从样本 行归一化处理。 x特征中产生,标签向量)为样本的标签y,权重向 算法2SI-MLHN演化学习算法 量初始化为1,表示为w=[w102…0,],其中:= 输入训练集T={(xn,yn)}(1≤n≤N),标签 1.0(1≤i≤q)。 数q,每个样本生成的超边数e,超边替代迭代次数 由于超边顶点向量为随机的,为了更好地拟 t,随机梯度下降迭代次数ta,样本的近邻数量k: 合训练样本,需要通过超边替代来选择适应度高的 输出SI-MLHN:H。 超边。如果新生成的超边适应值高于现有超边,则 1)To=T.map 替换该超边。适应值的计算方法如式(9)所示: 2)每条样本进行归一化 fites(eg)=a2,q白 Σ1立1.=1(9) 3)end map.cache 4)T Bro broadcast(Tor) 式中:超边e的近邻样本个数为k,G为与超边e匹 5)Tky=Thor .map 配的抽样训练集TS样本集合,则将TS中样本的数 6)每条样本计算与TBo中样本的欧式距离 量设置为10倍的k,其中k个是超边e,的近邻样 7)end map.map 本,其余的样本则为训练集样本的随机抽样;9为标 8)获取距离最近的k个样本 签数量;ym为样本(xn,yn)的第i个标签;y:'为超边 9)end map e,的第i个标签。由式(9)可以看出适应值代表了 10)Ti,Bro broadcast(Tv) 超边标签与匹配样本标签的相似度的平均值,相似 ll)Hm=T,.flatmap
11)for i = 1 to q do 12) W0 [i]←0 13) for each ej∈U 0 14) W0 [i] =W0 [i]+wji 15) end for 16)end for 17)for i = 1 to q do 18) P(yi = 1 xn )= 1 1+e -(W1 [i]-W0 [i]) 19)p[i] =P(yi = 1 xn ) 20) if P(yni = 1 xn )≥t i 21)y ∗ [i] = 1 22)else y ∗ [i] = 0 23)end if 24)end for 25)return p,y ∗ 2.2.2 SI⁃MLHN 演化学习过程 SI⁃MLHN 利用超边的顶点和权重向量来代表 多标签数据标签间的高阶关联,其权重向量由超边 从训练集中演化学习而来,首先进行了超边初始 化,然后进行了超边替代与梯度下降演化学习,并 利用 Spark 进行分布式并行计算,通过多个操作技 巧,如 cache、broadst,将变量缓存于内存中,大量减 少了网络交换数据量和磁盘 I/ O 操作,使算法更 高效。 在超边初始化的过程中,利用样本( x,y) 生成 超边 e = (v,y ^ ,w),超边的顶点向量 v 随机地从样本 x 特征中产生,标签向量 y ^ 为样本的标签 y,权重向 量初始化为 1,表示为 w = [w1 w2… wq],其中wi = 1.0(1≤i≤q)。 由于超边顶点向量 v 为随机的,为了更好地拟 合训练样本,需要通过超边替代来选择适应度高的 超边。 如果新生成的超边适应值高于现有超边,则 替换该超边。 适应值的计算方法如式(9)所示: fitness(ej) = 1 G ∑ (xn ,yn ) 1 q ∑ q i = 1 i yni = yi { ′} (9) 式中:超边 ej 的近邻样本个数为 k,G 为与超边 ej 匹 配的抽样训练集 TS 样本集合,则将 TS 中样本的数 量设置为 10 倍的 k,其中 k 个是超边 ej 的近邻样 本,其余的样本则为训练集样本的随机抽样;q 为标 签数量;yni为样本(xn ,yn )的第 i 个标签;yi ′为超边 ej 的第 i 个标签。 由式(9)可以看出适应值代表了 超边标签与匹配样本标签的相似度的平均值,相似 度越高,则适应值越高。 同时,式(4) 也展示出,样 本与匹配超边的标签相似度越高,被正确分类的概 率越大。 本文将预测误差作为学习目标。 损失函数如 式(10)所示,P ∗ ( yni = 1 xn ) 为 SI⁃MLHN 分类器对 样本(xn ,yn )的第 i 个标签的预测值,利用梯度下降 调整超边的权重,降低损失值。 超边权重更新为式 (11),并通过式(12) ~ (14),计算 Δwki,其中 wki为 第 k 条超边第 i 个标签的权重,η 为学习速率。 Errn(W) = 1 2∑ q i = 1 [P ∗ (yni = 1 xn) - P(yni = 1 xn)] 2 (10) wki = wki + Δwki (11) Δwki = - η ∂Errn(W) ∂wki (12) ∂Errn(W) ∂wki = (P(yni = 1 xn ) - P ∗ (yni = 1 xn )) ∂P ∗ (yni = 1 xn ) ∂wki (13) ∂P ∗ (yni = 1 xn ) ∂wki = ∂ 1 1 + e -(W1 ni -W0 ni ) ∂wki = 1 - 1 1 + e -(W1 ni -W0 ni ) 1 + e -(W1 ni -W0 ni ) (14) 算法 2 为 SI⁃MLHN 的演化学习流程伪代码。 由于本文采用欧氏距离作为距离度量,故需要先进 行归一化处理。 算法 2 SI⁃MLHN 演化学习算法 输入 训练集 T = {(xn ,yn )} (1≤n≤N),标签 数 q,每个样本生成的超边数 e, 超边替代迭代次数 t r,随机梯度下降迭代次数 t d ,样本的近邻数量 k; 输出 SI⁃MLHN:H。 1) Tnor = T .map 2)每条样本进行归一化 3) end map.cache 4) TnorBro = broadcast( Tnor ) 5) Tkv = Tnor .map 6)每条样本计算与 TnorBro 中样本的欧式距离 7)end map.map 8)获取距离最近的 k 个样本 9)end map 10) TkvBro = broadcast( Tkv ) 11) Hini = Tkv .flatmap ·628· 智 能 系 统 学 报 第 12 卷