
2015-2016学年春季学期 实验经济学 学生作业摘选
2015-2016 学年春季学期 实验经济学 学生作业摘选

目录 实验经济学个人作业示例----------1 实验经济学数据分析个人作业示例1- .-3 实验经济学数据分析个人作业示例2-----------5 实验经济学数据分析个人作业示例3----------------11 实验经济学数据分析个人作业示例4 -16 实验经济学文献总结个人作业示例1--17 实验经济学文献总结个人作业示例2 -21 实验经济学小组作业示例1- -23 实验经济学小组作业示例2--------------29 实验经济学小组作业示例3 -32 实验经济学小组作业示例4-一 -35 实验经济学学生部分文献总结- -38 实验经济学总结-文献简单概述 45 实验经济学期未论文- -49 第一组实验设计---- ---58 第二组实验设计 -74
目录 实验经济学个人作业示例--------------------------------------------1 实验经济学数据分析个人作业示例 1----------------------------------3 实验经济学数据分析个人作业示例 2----------------------------------5 实验经济学数据分析个人作业示例 3----------------------------------11 实验经济学数据分析个人作业示例 4----------------------------------16 实验经济学文献总结个人作业示例 1----------------------------------17 实验经济学文献总结个人作业示例 2----------------------------------21 实验经济学小组作业示例 1------------------------------------------23 实验经济学小组作业示例 2------------------------------------------29 实验经济学小组作业示例 3------------------------------------------32 实验经济学小组作业示例 4------------------------------------------35 实验经济学学生部分文献总结----------------------------------------38 实验经济学总结-文献简单概述---------------------------------------45 实验经济学期末论文------------------------------------------------49 第一组实验设计----------------------------------------------------58 第二组实验设计----------------------------------------------------74
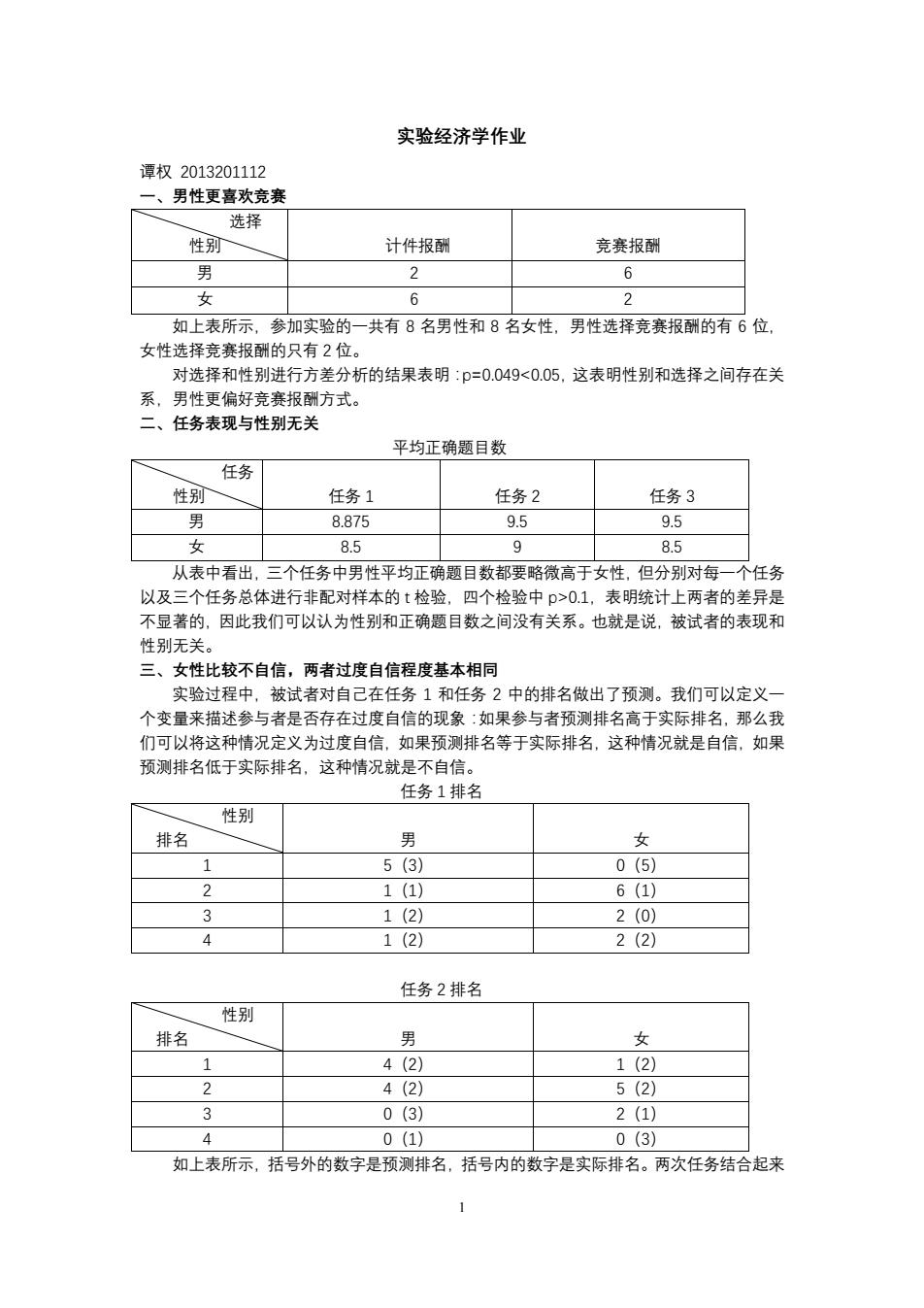
实验经济学作业 晋权2013201112 、男性更喜欢竞赛 性别 计件报酬 竞赛报酬 2 6 女 如上表所示,参加实验的一共有8名男性和8名女性,男性选择竞赛报酬的有6位, 女性选择竞赛报酬的只有2位 对选择和性别进行方差分析的结果表明:p=0.049<0.05,这表明性别和选择之间存在关 系,男性更偏好竞赛报酬方式。 二、任务表现与性别无关 平均正确题目数 任务 性别 任务1 任务2 任务3 8.875 95 9.5 女 85 g 85 从表中看出,三个任务中男性平均正确题目数都要略微高于女性, 但分别对每 个任务 以及三个任务总体进行非配对样本的t检验,四个检验中p>0.1,表明统计上两者的差异是 不显著的。因此我们可以认为性别和正确题目数之间没有关系。也就是说,被试者的表现和 性别无关。 三、女性比较不自信,两者过度自信程度基本相同 实验过程中,被试者对自己在任务1和任务2中的排名做出了预测。我们可以定义 个变量来描述参与者是否存在过度自信的现象:如果参与者预测排名高于实际排名,那么我 们可以将这种情况定义为过度自信,如果预测排名等于实际排名,这种情况就是自信,如果 预测排名低于实际排名,这种情况就是不自信。 任务1排名 性别 排名 男 女 1 5(3) 0(5) 1(1) 6(1) 3 1(2) 2(0 4 1(2) 2(2) 任务2排名 性别 排名 男 女 4(2) 1(2) 2 4(2 5(2) 0(3) 2(1) 4 0① 0③ 如上表所示,括号外的数字是预测排名,括号内的数字是实际排名。两次任务结合起来 1
1 实验经济学作业 谭权 2013201112 一、男性更喜欢竞赛 选择 性别 计件报酬 竞赛报酬 男 2 6 女 6 2 如上表所示,参加实验的一共有 8 名男性和 8 名女性,男性选择竞赛报酬的有 6 位, 女性选择竞赛报酬的只有 2 位。 对选择和性别进行方差分析的结果表明:p=0.049<0.05,这表明性别和选择之间存在关 系,男性更偏好竞赛报酬方式。 二、任务表现与性别无关 平均正确题目数 任务 性别 任务 1 任务 2 任务 3 男 8.875 9.5 9.5 女 8.5 9 8.5 从表中看出,三个任务中男性平均正确题目数都要略微高于女性,但分别对每一个任务 以及三个任务总体进行非配对样本的 t 检验,四个检验中 p>0.1,表明统计上两者的差异是 不显著的,因此我们可以认为性别和正确题目数之间没有关系。也就是说,被试者的表现和 性别无关。 三、女性比较不自信,两者过度自信程度基本相同 实验过程中,被试者对自己在任务 1 和任务 2 中的排名做出了预测。我们可以定义一 个变量来描述参与者是否存在过度自信的现象:如果参与者预测排名高于实际排名,那么我 们可以将这种情况定义为过度自信,如果预测排名等于实际排名,这种情况就是自信,如果 预测排名低于实际排名,这种情况就是不自信。 任务 1 排名 性别 排名 男 女 1 5(3) 0(5) 2 1(1) 6(1) 3 1(2) 2(0) 4 1(2) 2(2) 任务 2 排名 性别 排名 男 女 1 4(2) 1(2) 2 4(2) 5(2) 3 0(3) 2(1) 4 0(1) 0(3) 如上表所示,括号外的数字是预测排名,括号内的数字是实际排名。两次任务结合起来
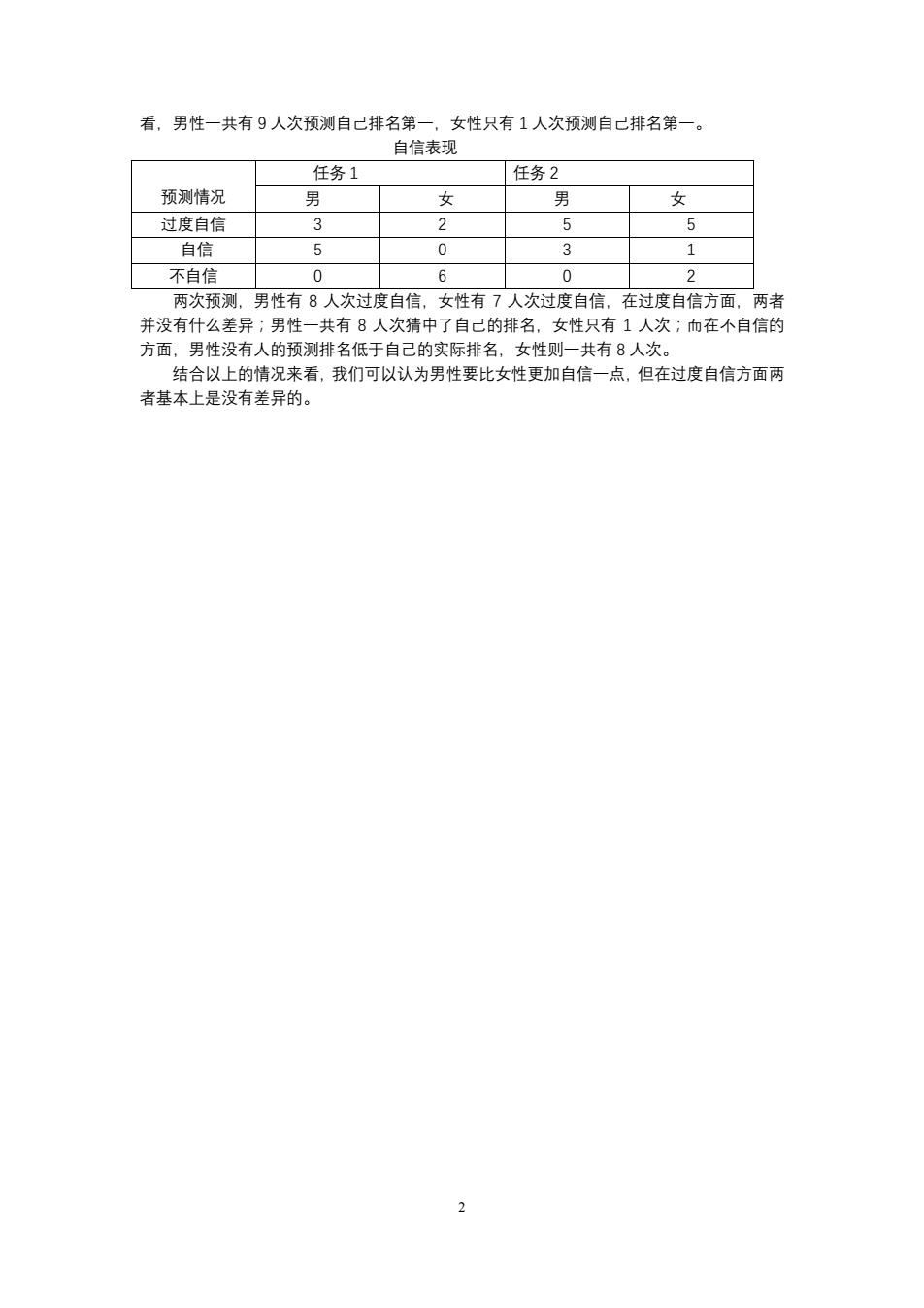
看,男性一共有9人次预测自己排名第一,女性只有1人次预测自己排名第一。 自信表现 任务1 任务2 预测情况 男 女 男 女 过度自信 2 5 5 自信 0 不自信 0 6 0 两次预测,男性有8人次过度自信,女性有7人次过度自信,在过度自信方面,两者 并没有什么差异;男性一共有8人次猜中了自己的排名,女性只有1人次:而在不自信的 方面 男性没有人的预测排名低于自己的实际 t有8人次。 结合以上的情况来看,我们可以认为男性要比女性更加自信一点,但在过度自信方面两 者基本上是没有差异的
2 看,男性一共有 9 人次预测自己排名第一,女性只有 1 人次预测自己排名第一。 自信表现 预测情况 任务 1 任务 2 男 女 男 女 过度自信 3 2 5 5 自信 5 0 3 1 不自信 0 6 0 2 两次预测,男性有 8 人次过度自信,女性有 7 人次过度自信,在过度自信方面,两者 并没有什么差异;男性一共有 8 人次猜中了自己的排名,女性只有 1 人次;而在不自信的 方面,男性没有人的预测排名低于自己的实际排名,女性则一共有 8 人次。 结合以上的情况来看,我们可以认为男性要比女性更加自信一点,但在过度自信方面两 者基本上是没有差异的

数据分析方法详述 谭权2013201112 Wilcoxon秩和检验 秩:设X为一总体,将一容量为的样本观察之按自小到大的次序编号排列成为 X(1)<X(2)<…<X(n) X(们的下标称为X()的秩。秩和就是一个样本中数据秩的总和。 该检验方法主要检验两个样本的总体的均值是否相同。原假设H0:比较两组的总体分 布均值相同 计算方法:首先建立假设,然后将两组数据混合排序,绵秩。将样本数最小的组的秩和 作为检验统计量T,接着以样本书含量叫小组的个体数nl,样本书之差n2-n1及T值查验 界值表 得出p值。做出统计结论。 文章中,作者运用实验1的数据得到了在standard和buy模式下人们对于独裁者行为 的社会合适度评价。由于是相同的被试者分别作出的评价,因此我们分配结果相同的情况下, 人们对于两种模式下行为评价数据的分布是相同的,仅仅是均值不同。运用计量软件得出结 当p值越小时,我们越能拒绝原假设,即认为两个样本的均值存在显著差异。这就是 说 人们对于不同模式下,造成相同分配结果的评价不同(口值小于0.05可以认为不同 Logistic regression Ordered logistic regression 当因变量是两分类变量,自变量是连续变量或者分类变量时,通过logistic回归可以分 析自变量对于因变量的影响程度。将因变量的两种分类分别设为Y=0和Y=1,logi1stic回归 是一种概率估 利 即自变量对于P(Y=1) 程度。 这和线性概率模型(PM)有 相似点,不同之处在于logistic回归采用的方程形式不同,P(Y=1)=e^ (1+enx), 表示影响因素或者影响因素的一个函数,logistic回归采用极大似然法估计相关系数。LPM 采用的是线性函数形式,采用最小二乘法估计相关系数。PM缺点在于进行估计后进行计 算时,概率值会不再0,1]区间内,且对于某些分析,比如患病概率和年龄的关系。两者之间 不是线性关系1。 sc回归可以使年龄越大,志病率的增加越快,更符合实际情况,同 时概率值一直位于0,1]内。 Ordered logistic regression和普通的logistic regression不同点就在于ordered logistic regression的因变量是多分类变量,而logistic regression的因变量是两分类变量。 在研究是否位于buy模式下对独裁者分配钱数的影响是,由于独裁者可以选择的行动 一共有11种,结果也有11种,是多分类变量,采用的是ordered logistic reg ression.而分 析是否位于buly模式下平均分配和独占时,结果只有两种,是或者不是,采用的就是logistic regression。 非参数卡方检验 卡方检验是指诵讨样本数据,推断样太来自的总体分布是否与期望分布或某一理论分布 存在显著性差异的吻合性检验。原假设为:样本来自的总体分布与期望分布或某一理论分布 无差异 作者发现捐款额度在1-4美元的人数比例在两种模式下存在差异,但并不了解这种差 异是否显著,那么以其中一种模式下的数据为期望分布,看另一种模式下的分布是否和期望 3
3 数据分析方法详述 谭权 2013201112 Wilcoxon 秩和检验 秩:设 X 为一总体,将一容量为 n 的样本观察之按自小到大的次序编号排列成为 X(1)<X(2)<…<X(n) X(i)的下标 i 称为 X(i)的秩。秩和就是一个样本中数据秩的总和。 该检验方法主要检验两个样本的总体的均值是否相同。原假设 H0:比较两组的总体分 布均值相同 计算方法:首先建立假设,然后将两组数据混合排序,编秩。将样本数最小的组的秩和 作为检验统计量 T,接着以样本书含量叫小组的个体数 n1,样本书之差 n2-n1 及 T 值查验 界值表,得出 p 值,做出统计结论。 文章中,作者运用实验 1 的数据得到了在 standard 和 bully 模式下人们对于独裁者行为 的社会合适度评价。由于是相同的被试者分别作出的评价,因此我们分配结果相同的情况下, 人们对于两种模式下行为评价数据的分布是相同的,仅仅是均值不同。运用计量软件得出结 果,当 p 值越小时,我们越能拒绝原假设,即认为两个样本的均值存在显著差异。这就是 说,人们对于不同模式下,造成相同分配结果的评价不同(p 值小于 0.05 可以认为不同) Logistic regression 和 Ordered logistic regression 当因变量是两分类变量,自变量是连续变量或者分类变量时,通过 logistic 回归可以分 析自变量对于因变量的影响程度。将因变量的两种分类分别设为 Y=0 和 Y=1,logistic 回归 是一种概率估计模型,即自变量对于 P(Y=1)的影响程度。这和线性概率模型(LPM)有 相似点,不同之处在于 logistic 回归采用的方程形式不同,P(Y=1)=e^x/(1+e^x),x 表示影响因素或者影响因素的一个函数,logistic 回归采用极大似然法估计相关系数。LPM 采用的是线性函数形式,采用最小二乘法估计相关系数。LPM 缺点在于进行估计后进行计 算时,概率值会不再[0,1]区间内,且对于某些分析,比如患病概率和年龄的关系,两者之间 并不是线性关系,logistic 回归可以使年龄越大,患病率的增加越快,更符合实际情况,同 时概率值一直位于[0,1]内。 Ordered logistic regression 和普通的 logistic regression 不同点就在于 ordered logistic regression 的因变量是多分类变量,而 logistic regression 的因变量是两分类变量。 在研究是否位于 bully 模式下对独裁者分配钱数的影响是,由于独裁者可以选择的行动 一共有 11 种,结果也有 11 种,是多分类变量,采用的是 ordered logistic regression,而分 析是否位于 bully 模式下平均分配和独占时,结果只有两种,是或者不是,采用的就是 logistic regression。 非参数卡方检验 卡方检验是指通过样本数据,推断样本来自的总体分布是否与期望分布或某一理论分布 存在显著性差异的吻合性检验。原假设为:样本来自的总体分布与期望分布或某一理论分布 无差异 作者发现捐款额度在 1-4 美元的人数比例在两种模式下存在差异,但并不了解这种差 异是否显著,那么以其中一种模式下的数据为期望分布,看另一种模式下的分布是否和期望