
分布存在显著差异,拒绝了原假设,说明人数比例存在显著差异。 条件logistic回归和ordered logistic回归的差别在于自变量,条件logistic回归的自变 量是个体选择的分布情况,而ordered logistic回归的自变量是个体的选择情况,两者所采 用的函数模型是相同的。 作者运用了独裁者行为的分布,估计出了在buly和standard模式下金钱效用和社会 合适度评价的系数,得出了两者之间的取舍关系
4 分布存在显著差异,拒绝了原假设,说明人数比例存在显著差异。 Conditional logistic regression 条件 logistic 回归和 ordered logistic 回归的差别在于自变量,条件 logistic 回归的自变 量是个体选择的分布情况,而 ordered logistic 回归的自变量是个体的选择情况,两者所采 用的函数模型是相同的。 作者运用了独裁者行为的分布,估计出了在 bully 和 standard 模式下金钱效用和社会 合适度评价的系数,得出了两者之间的取舍关系
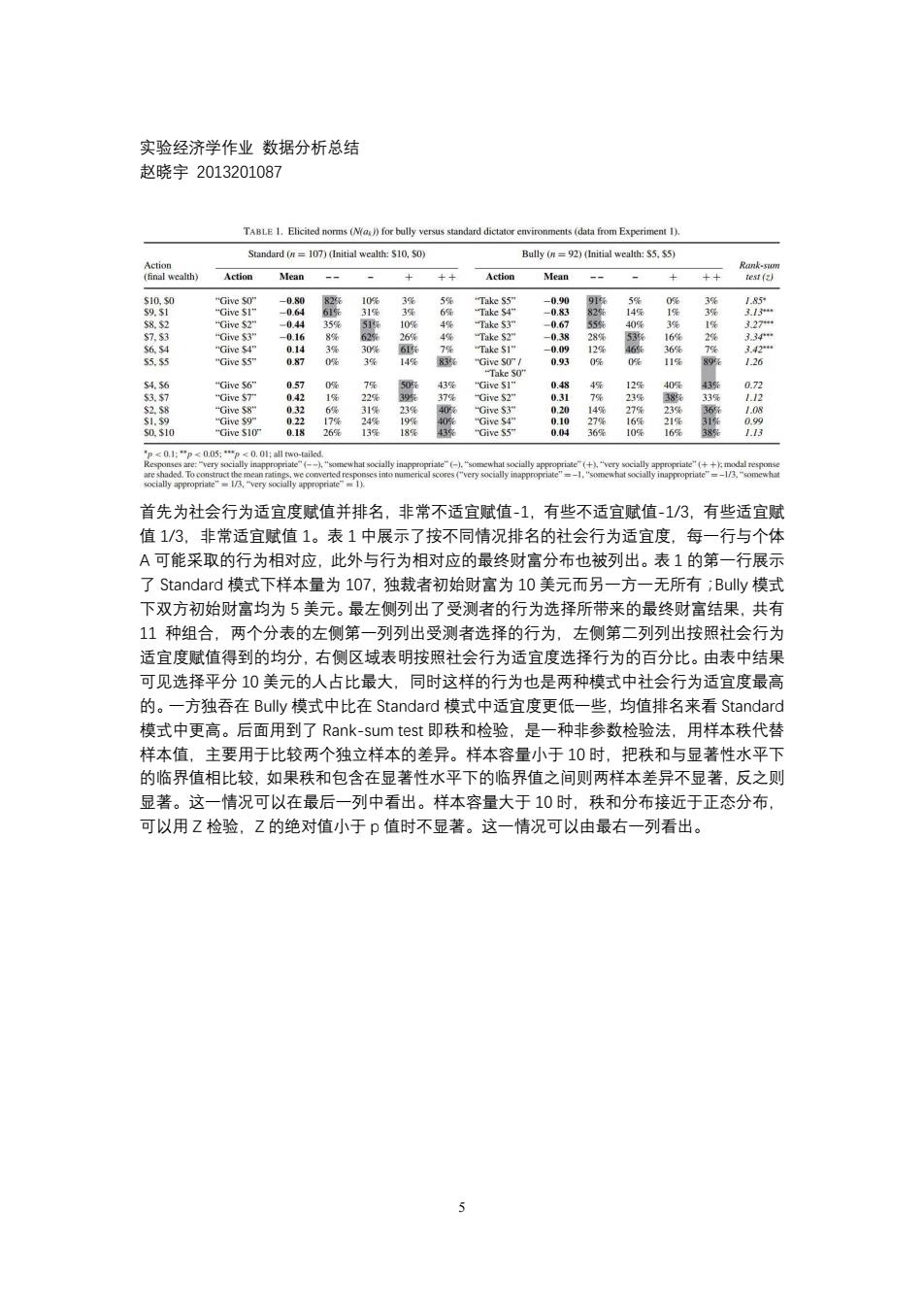
实验经济学作业数据分析总结 赵晓宇2013201087 sYa升6ye om E 107)(Initial wealth:$10.50 1weah35,35 () Action Mean Action Mea ++ ·21酒 26 首先为社会行为适宜度赋值并排名,非常不适宜赋值-1,有些不适宜赋值-1/3,有些适宜赋 值13,非常适宜赋值1。表1中展示了按不同情况排名的社会行为适宜度.每一行与个体 一A可能果取的行为相对应,比外与行为相对应的墨丝财富分布也被列出。表1的第一布腿示 模式下样本量为107 独裁者初始财富为10美元而另 -方一无所有;Buly模式 下双方初始财富均为5美元。最左侧列出了受测者的行为选择所带来的最终财富结果,共有 11种组合,两个分表的左侧第一列列出受测者选择的行为,左侧第二列列出按照社会行为 适宜度赋值得到的均分,右侧区域表明按照社会行为适宜度选择行为的百分比。由表中结果 可见选择平分10美元的人占比最大,同时这样的行为也是两种模式中社会行为适宜度最高 -方独吞在Buly模式中比在Standar 模 中适宜度更低一些,均值排名来看Standard 模式中更高。后面用到了Rank-sum test即秩和检验,是一种非参数检验法,用样本秩代替 样本值,主要用于比较两个独立样本的差异。样本容量小于10时,把秩和与显著性水平下 的临界值相比较,如果秩和包含在显著性水平下的临界值之间则两样本差异不显著,反之则 显著。这一情况可以在最后一列中看出。样本容量大于10时,秩和分布接近于正态分布, 可以用Z检验,Z的绝对值小于P值时不显著。这一情况可以由最右一列看出
5 实验经济学作业 数据分析总结 赵晓宇 2013201087 首先为社会行为适宜度赋值并排名,非常不适宜赋值-1,有些不适宜赋值-1/3,有些适宜赋 值 1/3,非常适宜赋值 1。表 1 中展示了按不同情况排名的社会行为适宜度,每一行与个体 A 可能采取的行为相对应,此外与行为相对应的最终财富分布也被列出。表 1 的第一行展示 了 Standard 模式下样本量为 107,独裁者初始财富为 10 美元而另一方一无所有;Bully 模式 下双方初始财富均为 5 美元。最左侧列出了受测者的行为选择所带来的最终财富结果,共有 11 种组合,两个分表的左侧第一列列出受测者选择的行为,左侧第二列列出按照社会行为 适宜度赋值得到的均分,右侧区域表明按照社会行为适宜度选择行为的百分比。由表中结果 可见选择平分 10 美元的人占比最大,同时这样的行为也是两种模式中社会行为适宜度最高 的。一方独吞在 Bully 模式中比在 Standard 模式中适宜度更低一些,均值排名来看 Standard 模式中更高。后面用到了 Rank-sum test 即秩和检验,是一种非参数检验法,用样本秩代替 样本值,主要用于比较两个独立样本的差异。样本容量小于 10 时,把秩和与显著性水平下 的临界值相比较,如果秩和包含在显著性水平下的临界值之间则两样本差异不显著,反之则 显著。这一情况可以在最后一列中看出。样本容量大于 10 时,秩和分布接近于正态分布, 可以用 Z 检验,Z 的绝对值小于 p 值时不显著。这一情况可以由最右一列看出
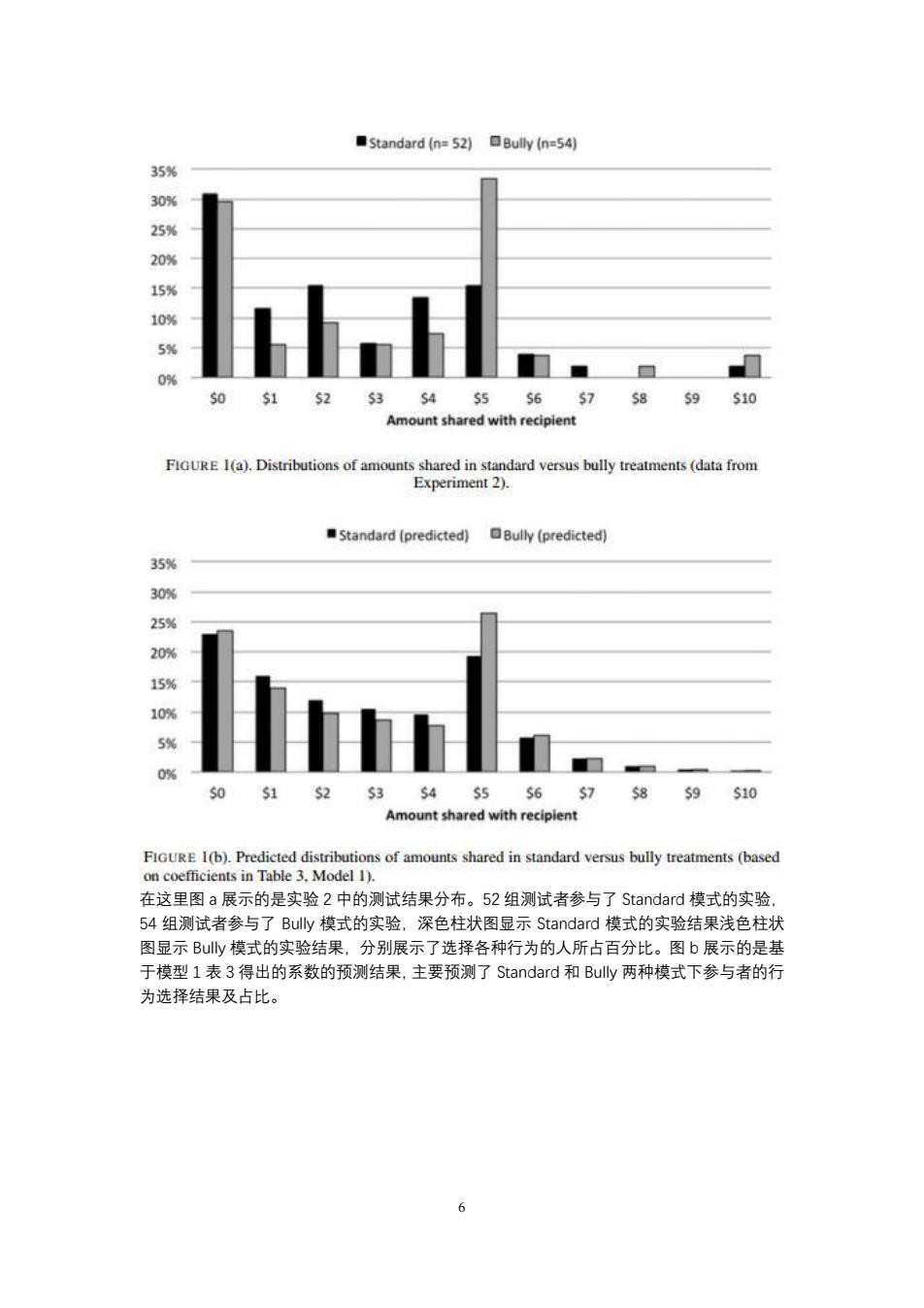
■Standard(n=52日Bully (n=54) 35% 30 5% 2 5% 51525354555657 5859510 Amount shared with recipient Fa)Dbofmvbllyre (ataom Standard (predicted)Bully (predicted) 35% 30 25% 20% 15 0 51 5253 54 56 58 59510 t shared with FGUE I(b).Predicted distributions of amounts shared in standard versus bully treatments (based on coefficients in Table 3.Model 1). 在这里图a展示的是实验2中的测试结果分布。52组测试者参与了Standard模式的实验, 54组测试者参与了Buy模式的实验.深色柱状图显示Standard模式的实验结果浅色柱状 图显示Buy模式的实验结果,分别展示了选择各种行为的人所占百分比。图b展示的是基 于模型1表3得出的系数的预测结果,主要预测了Standard和Buy两种模式下参与者的行 为选择结果及占比
6 在这里图 a 展示的是实验 2 中的测试结果分布。52 组测试者参与了 Standard 模式的实验, 54 组测试者参与了 Bully 模式的实验,深色柱状图显示 Standard 模式的实验结果浅色柱状 图显示 Bully 模式的实验结果,分别展示了选择各种行为的人所占百分比。图 b 展示的是基 于模型 1 表 3 得出的系数的预测结果,主要预测了 Standard 和 Bully 两种模式下参与者的行 为选择结果及占比

.Statisticaltests of bebavior acrss bl versus standard treatments (dataom Experiment B to recipient (Share $5) (Share $0) Bully 0.678 1.570 0.532 Class size (0.006 Constant 106 Suawcle oatedlagiaiagesiom less than S6 to recipient less than S5 to recipient 表2展示的是实验2的数据结果,显示出两种不同待遇下行为的变化。在这里控制了招募 学生的样本容量,从87到184.汶是潜在的社会距离的测度值。正如猜测的一样样太容 量与分享的金额大小呈反向相关。第一个模型中,与Standard模式相比,Buy模式的分享 金新更多。这一先怀进行了对一分类弯量的ic回归分析多用干经济预测预概速 并可以得到自变量的权重,进而根据权重得到预测事件发生的概率。其 对所有数据即参加 者分配金额状况进行了有序Logistic回归,而后面两栏则是把全部情况分为分给参与者的少 于5美元和少于6美元进行二分类变量的Logistic回归分析。因变量有Buy模式,样本容 量大小,参与者人数,模型类型及分析对象等等。初始预期为在Buy模式中选择均分的人 会比Standard模式中多。 c Behva d 以在Buy模式中选择均分的人会比Standard模式中多为初始预期,表3中p值小于0.001 可见结果显著,初始预期得到了证实。第二个预期关于如果他们不选择均分那么他们会怎么 做,预期认为接受者如果接受少于5美元则在Buy模式下独裁者不会分给对方财富。在 Standard模式下,这么做的人有40%.而在Buly模式下则有52%的人这么做。在表3中p 值为0.03,仍旧显著。以非参数卡方分布得到的结果显著.其中2(1)=3.85.p=0.05
7 表 2 展示的是实验 2 的数据结果,显示出两种不同待遇下行为的变化。在这里控制了招募 学生的样本容量,从 87 到 184,这是潜在的社会距离的测度值。正如猜测的一样,样本容 量与分享的金额大小呈反向相关。第一个模型中,与 Standard 模式相比,Bully 模式的分享 金额更多。这一步还进行了对二分类变量的 Logistic 回归分析,多用于经济预测,预测概率, 并可以得到自变量的权重,进而根据权重得到预测事件发生的概率。其中对所有数据即参加 者分配金额状况进行了有序 Logistic 回归,而后面两栏则是把全部情况分为分给参与者的少 于 5 美元和少于 6 美元进行二分类变量的 Logistic 回归分析。因变量有 Bully 模式,样本容 量大小,参与者人数,模型类型及分析对象等等。初始预期为在 Bully 模式中选择均分的人 会比 Standard 模式中多。 以在 Bully 模式中选择均分的人会比 Standard 模式中多为初始预期,表 3 中 p 值小于 0.001, 可见结果显著,初始预期得到了证实。第二个预期关于如果他们不选择均分那么他们会怎么 做,预期认为接受者如果接受少于 5 美元则在 Bully 模式下独裁者不会分给对方财富。在 Standard 模式下,这么做的人有 40%,而在 Bully 模式下则有 52%的人这么做。在表 3 中 p 值为 0.03,仍旧显著。以非参数卡方分布得到的结果显著,其中 χ2(1) = 3.85, p = 0.05
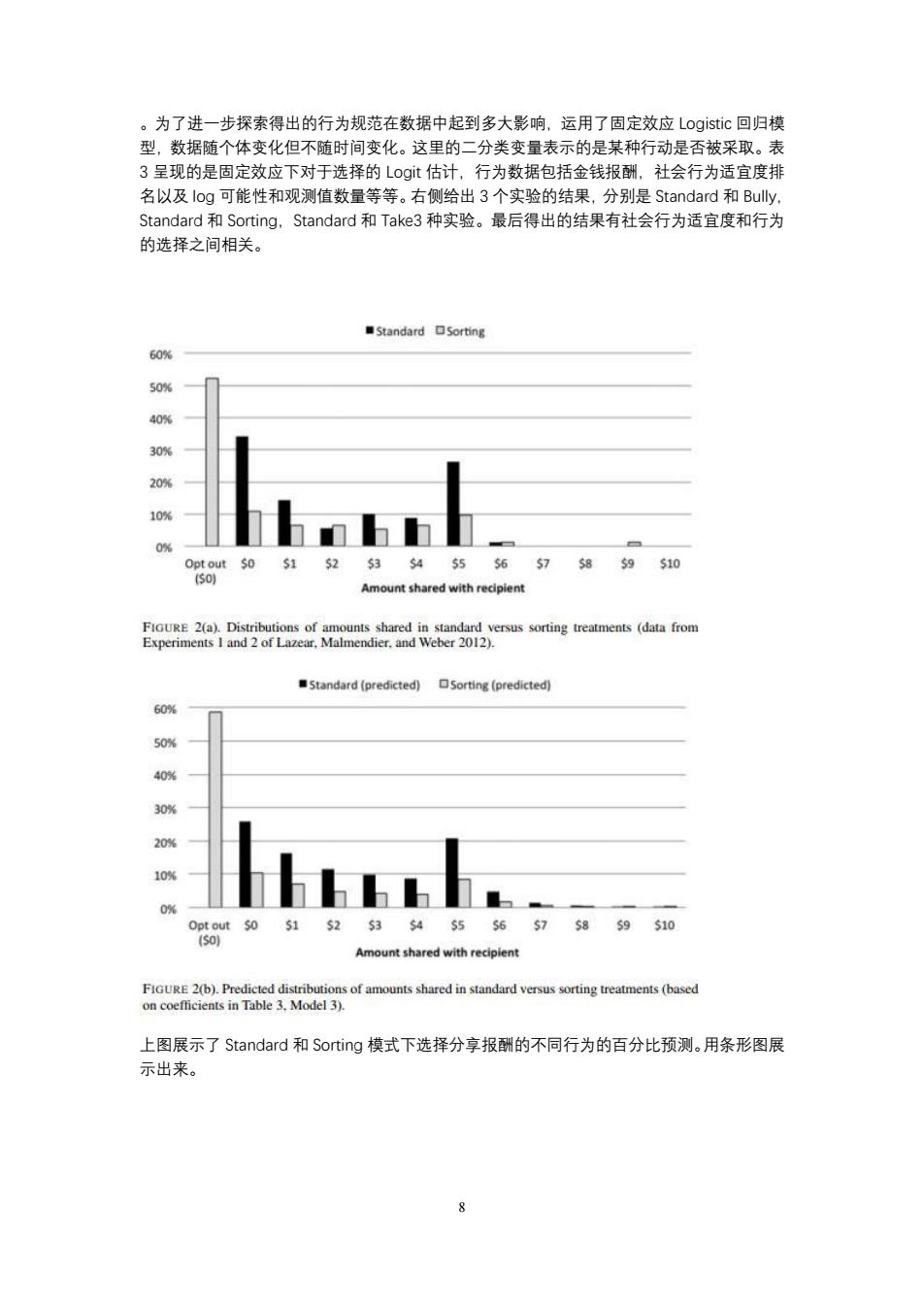
。为了进一步探素得出的行为规范在数据中起到多大影响,运用了固定效应L0gsic回归模 型,数据随个体变化但不随时间变化。这里的二分类变量表示的是某种行动是否被采取。表 3呈现的是固定效应下对于选择的Logt估计,行为数据包括金钱报酬 ,社会行为适宜度排 名以及g可能性和观测值数量等等。右侧给出3个实验的结果 分别是Standard和Buly Standard和Sorting,Standard和Take3种实验。最后得出的结果有社会行为适宜度和行为 的选择之间相关。 ■Standard口Sorting 60% 05 Amount shared with recipient Standard (predicted)(predicted) 60% 30% 20% 10% hhhhh Amount shared with recipient 上图展示了Standard和Sorting模式下选择分享报酬的不同行为的百分比预测。用条形图展 示出来
8 。为了进一步探索得出的行为规范在数据中起到多大影响,运用了固定效应 Logistic 回归模 型,数据随个体变化但不随时间变化。这里的二分类变量表示的是某种行动是否被采取。表 3 呈现的是固定效应下对于选择的 Logit 估计,行为数据包括金钱报酬,社会行为适宜度排 名以及 log 可能性和观测值数量等等。右侧给出 3 个实验的结果,分别是 Standard 和 Bully, Standard 和 Sorting,Standard 和 Take3 种实验。最后得出的结果有社会行为适宜度和行为 的选择之间相关。 上图展示了 Standard 和 Sorting 模式下选择分享报酬的不同行为的百分比预测。用条形图展 示出来