
2.3性能度量 3 必然都被选上了,但这样查准率就会较低:若希望选出的瓜中好瓜比例尽可能 高,则可只挑选最有把握的瓜,但这样就难免会漏掉不少好瓜,使得查全率较 低.通常只有在一些简单任务中,才可能使查全率和查准率都很高。 在很多情形下,我们可根据学习器的预测结果对样例进行排序,排在前面 的是学习器认为“最可能”是正例的样本,排在最后的则是学习器认为“最 不可能”是正例的样本,按此顺序逐个把样本作为正例进行预测,则每次可以 兴地的信急,即可计算出计算出当前的查全率、查准率.以查准率为纵轴、查全率为横轴作图,就得到 查全率、查淮率 了查准率查全率曲线,简称“PR曲线”,显示该曲线的图称为“PR图”,图 点格R物黄·或23给出了一个示意图 1 0. 04 常盖非单调。不平滑的 0.2 在很多局部有上下波动 0.4 08 春会套 图2.3P-R曲线与平衡点示意图 PR图直观地显示出学习器在样本总体上的查全率、查准率,在进行比较 时,若一个学习器的PR曲线被另一个学习器的曲线完全“包住”,则可断言 后者的性能优于前者,例如图2.3中学习器A的性能优于学习器C;如果两个 学习器的P-R曲线发生了交叉,例如图2.3中的A与B,则难以一般性地断言 两者孰优孰劣,只能在具体的查准率或查全率条件下进行比较.然而,在很多情 形下,人们往往仍希望把学习器A与B比出个高低.这时一个比较合理的判据 是比较P曲线下面积的大小,它在一定程度上表征了学习器在查准率和查全 率上取得相对“双高”的比例.但这个值不太容易估算,因此,人们设计了一些 综合考虑查准率、查全率的性能度量, “平衡点”(Break-Event Point,简称BEP)就是这样一个度量,它是“查 准率=查全率”时的取值,例如图2.3中学习器C的BEP是0.64,而基于BEP 的比较,可认为学习器A优于B

第2章模型评估与选择 但BEP还是过于简化了些,更常用的是F1度量: FI-2xPxR 2×TP P+R =祥例总数+TP-TN (2.10) 在一些应用中,对查准率和查全率的重视程度有所不同.例如在商品推荐 F们是蒸于查准率与查 全率的调和平均(harmonic 系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时查准 mean)定义的: 率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更 高-(合+) 重要.F1度量的一般形式一F,能让我们表达出对查准率/查全率的不同偏 好,它定义为 Fa则是加权调和平均: FB=L+的)xP×R (2.11) 房(信+) (2×P)+R 其中B>0度量了查全率对查准率的相对重要性Van Rijsbergen,1979).B=1 与算术平均(B)和几 时退化为标准的F1;B>1时查全率有更大影响:B<1时查准率有更大影响 何平均(√P×)相比,词 和平均更重视城小值 很多时候我们有多个二分类混淆矩阵,例如进行多次训练/测试,每次得到 一个混淆矩阵;或是在多个数据集上进行训练/测试,希望估计算法的“全局” 性能;甚或是执行多分类任务,每两两类别的组合都对应一个混淆矩阵;… 总之,我们希望在n个二分类混淆矩阵上综合考察查准率和查全率。 一种直接的做法是先在各混淆矩阵上分别计算出查准率和查全率, 记为(B,R1),(B,2),,(P,n),再计算平均值,这样就得到“宏查准 率”(macro-P)、“宏查全率”(macro-R),以及相应的“宏F1”(macro-F1: macro-P n (2.12) macro RR. n (2.13) macro-F1=2×macro-P×macro-R (2.14) macro-P+macro-R 还可先将各混淆矩阵的对应元素进行平均,得到TP、FP、TN、FN的 平均值,分别记为T严、F严、T下、FV,再基于这些平均值计算出“微查准 率”(micro-P)、“微查全率”(micro-)和“微F1”(micro-F1): T micro-P=Tp+F币 (2.15)

2.3性能度量 33 TP micro-R=P+F示' (2.16) micro-F1=2x micro-Px micro-R micro-P+micro-R (2.17) 2.3.3R0C与AUC 很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与 一个分类阑值(threshold)进行比较,若大于阑值则分为正类,否则为反类.例 如,神经网络在一般情形下是对每个测试样本预测出一个0.0,1.0之间的实值, 神经网络参见第5幸」 然后将这个值与0.5进行比较,大于0.5则判为正例,否则为反例.这个实值或 概率预测结果的好坏,直接决定了学习器的泛化能力.实际上,根据这个实值或 概率预测结果,我们可将测试样本进行排序,“最可能”是正例的排在最前面 “最不可能”是正例的排在最后面.这样,分类过程就相当于在这个排序中以 某个“截断点”(cut point)将样本分为两部分,前一部分判作正例,后一部分则 判作反例. 在不同的应用任务中,我们可根据任务需求来采用不同的截断点,例如若 我们更重视“查准率”,则可选择排序中靠前的位置进行截断:若更重视“查 全率”,则可选择靠后的位置进行截断.因此,排序本身的质量好坏,体现了综 合考虑学习器在不同任务下的“期望泛化性能”的好坏,或者说,“一般情况 下”泛化性能的好坏.ROC曲线则是从这个角度出发来研究学习器泛化性能 的有力工具 ROC全称是“受试者工作特征”(Receiver Operating Characteristic)曲 线,它源于“二战”中用于敌机检测的雷达信号分析技术,二十世纪六七十 年代开始被用于一些心理学、医学检测应用中,此后被引入机器学习领域 [Spackman,.1989.与2.3.2节中介绍的P-R曲线相似,我们根据学习器的预 测结果对样例进行排序,按此顺序逐个把样本作为正例进行顶测,每次计算 出两个重要量的值,分别以它们为横、纵坐标作图,就得到了“ROC曲线” 与PR曲线使用查准率、查全率为纵、横轴不同,ROC曲线的纵轴是“真正 例率”(True Positive Rate,,简称TPR),横轴是“假正例率”(False Positive Rate,简称FPR),基于表2.1中的符号,两者分别定义为 TP TPR-TP+FN' (2.18) FP FPR-TN+FP (2.19)
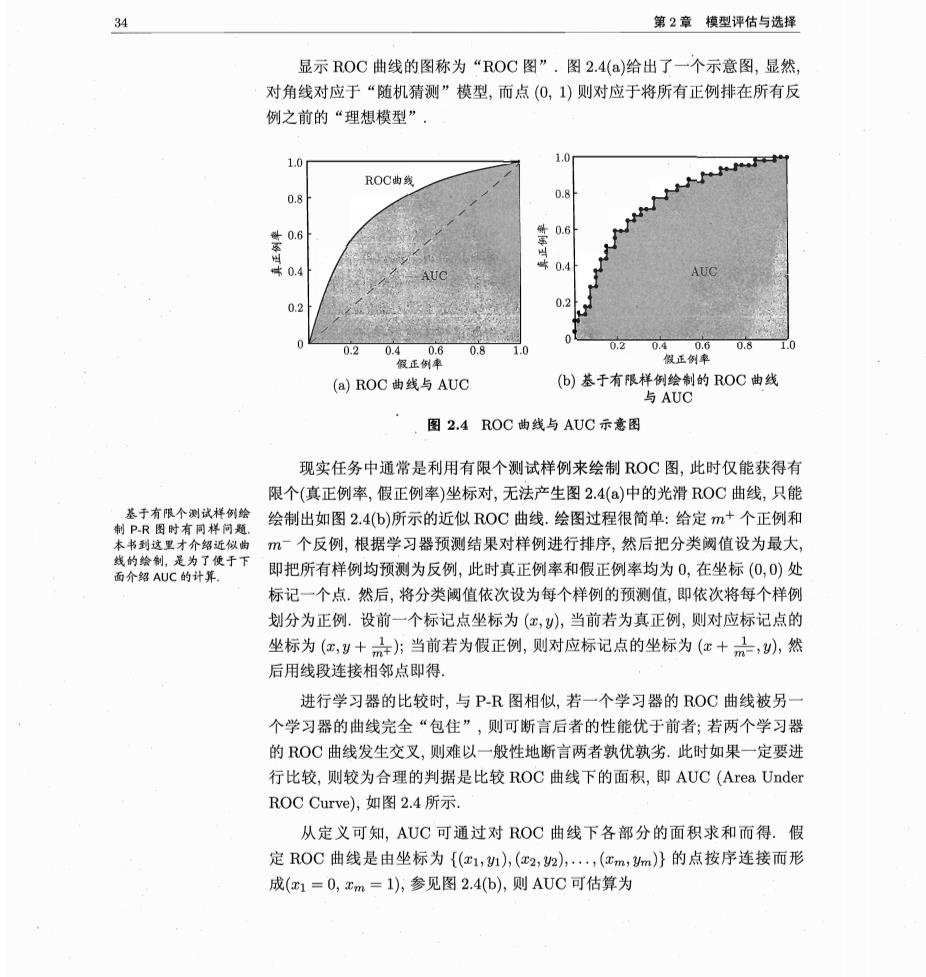
34 第2章模型评估与选择 显示ROC曲线的图称为“ROC图”.图2.4()给出了一个示意图,显然, 对角线对应于“随机猜测”模型,而点(0,)则对应于将所有正例排在所有反 例之前的“理想模型”. 1.0 1.0 ROC曲线 0.8 0.8 ±0.6 0.6 0.4 0.2 02 0 0.2 0.8 1.0 0204 0.8 假正例率 (a)ROC曲线与AUC (b)基于有限样例绘制的ROC曲线 与AUC 图2.4ROC曲线与AUC示意图 现实任务中通常是利用有限个测试样例来绘制ROC图,此时仅能获得有 限个(真正例率,假正例率)坐标对,无法产生图2.4()中的光滑ROC曲线,只能 绘制出如图2.4(b)所示的近似ROC曲线.绘图过程很简单:给定m+个正例和 时有样 m个反例,根据学习器预测结果对样例进行排序,然后把分类阙值设为最大, 是为了便于 面介绍AUC的计算, 即把所有样例均预测为反例,此时真正例率和假正例率均为0,在坐标(0,0)处 标记一个点。然后,将分类阙值依次设为每个样例的预测值,即依次将每个样例 划分为正例.设前一个标记点坐标为(红,),当前若为真正例,则对应标记点的 坐标为(,y十六方当前若为假正例,则对应标记点的坐标为(c十品,),然 后用线段连接相邻点即得。 进行学习器的比较时,与PR图相似,若一个学习器的ROC曲线被另 个学习器的曲线完全“包住”,则可断言后者的性能优于前者;若两个学习器 的OC曲线发生交叉,则难以一般性地断言两者孰优孰劣.此时如果一定要进 行比较,则较为合理的判据是比较ROC曲线下的面积,即AUC(Area Under ROC Curve),如图2.4所示, 从定义可知,AUC可通过对ROC曲线下各部分的面积求和而得.假 定ROC曲线是由坐标为{e1,n,(c2,h),,(cm,m}的点按序连接而形 成(x1=0,xm=1),参见图2.4(b),则AUC可估算为

2.3性能度量 35 AUC=2∑+1-)(+h+) (2.20) 形式化地看,AUC考虑的是样本预测的排序质量,因此它与排序误差有紧 密联系.给定m+个正例和m个反例,令D+和D分别表示正、反例集合, 则排序“损失”(Qoss)定义为 1 (e)<fe》+e*)=fe. gtED+-ED- (2.21) 即考虑每一对正、反例,若正例的预测值小于反例,则记一个“罚分”,若相 等,则记0.5个“罚分”,容易看出,(ramk对应的是R0C曲线之上的面积:若 一个正例在ROC曲线上对应标记点的坐标为(红,),则x恰是排序在其之前的 反例所占的比例,即假正例率.因此有 AUC=1-rank (2.22) 2.3.4代价敏感错误率与代价曲线 在现实任务中常会遇到这样的情况:不同类型的错误所造成的后果不同 例如在医疗诊断中,错误地把患者诊断为健康人与错误地把健康人诊断为患者, 看起来都是犯了“一次错误”,但后者的影响是增加了进一步检查的麻烦,前 者的后果却可能是丧失了拯救生命的最佳时机:再如,门禁系统错误地把可通 行人员拦在门外,将使得用户体验不佳,但错误地把陌生人放进门内,则会造成 严重的安全事故.为权衡不同类型错误所造成的不同损失,可为错误赋予“非 均等代价”(unequal cost). 以二分类任务为例,我们可根据任务的领域知识设定一个“代价矩 阵”(cost matrix),如表2.2所示,其中cost,表示将第i类样本预测为第j类 样本的代价.一般来说,cost=0:若将第0类判别为第1类所造成的损失更 大,则costo1>cost10;损失程度相差越大,costo1与cost10值的差别越大 与50:10所起戴果相当。 表2.2 二分类代价矩阵 真实类别 预测类别 第0类第1类 第0类 0 costo1 第1类cost100