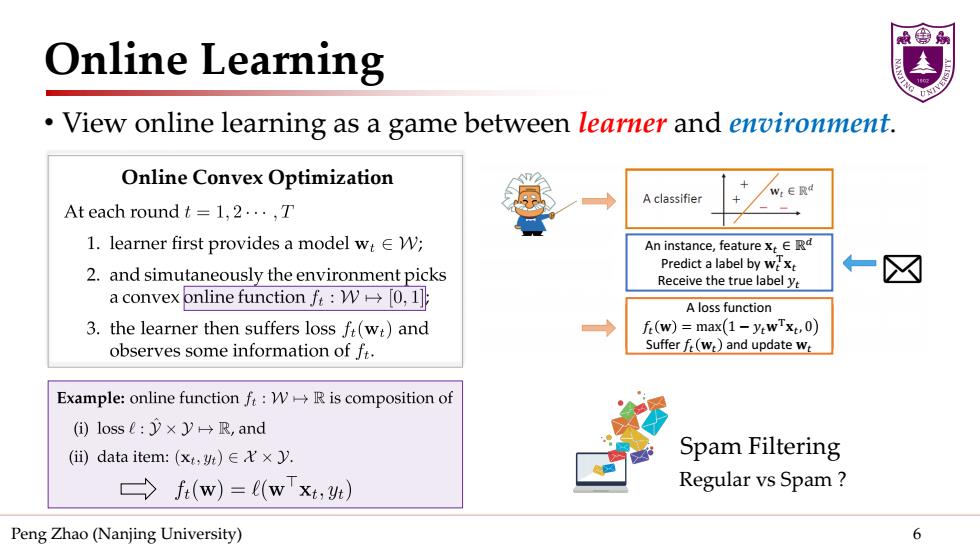
Online Learning View online learning as a game between learner and environment. Online Convex Optimization A classifier W:ER At each round t=l,2·,T 1.learner first provides a model wtEW; An instance,feature xt ERd 2.and simutaneously the environment picks Predict a label by wext Receive the true label yt a convex online functionf:W[0,1] A loss function 3.the learner then suffers loss ft(w:)and f(w)=max(1-y:wTxt,0) observes some information of f. Suffer f(wr)and update wr Example:online function f:W>R is composition of ()losse:)×y→R,and (i)data item:(xt,t)∈X×Jy. Spam Filtering →f(w)=(wxt,) Regular vs Spam Peng Zhao (Nanjing University) 6
Peng Zhao (Nanjing University) 6 Online Learning • View online learning as a game between learner and environment. An instance, feature 𝐱𝐱𝑡𝑡 ∈ ℝ𝑑𝑑 Predict a label by 𝐰𝐰𝑡𝑡 T𝐱𝐱𝑡𝑡 Receive the true label 𝑦𝑦𝑡𝑡 Regular vs Spam ? Spam Filtering A loss function 𝑓𝑓𝑡𝑡 𝐰𝐰 = max 1 − 𝑦𝑦𝑡𝑡𝐰𝐰T𝐱𝐱𝑡𝑡, 0 Suffer 𝑓𝑓𝑡𝑡 𝐰𝐰𝑡𝑡 and update 𝐰𝐰𝑡𝑡 Online Convex Optimization
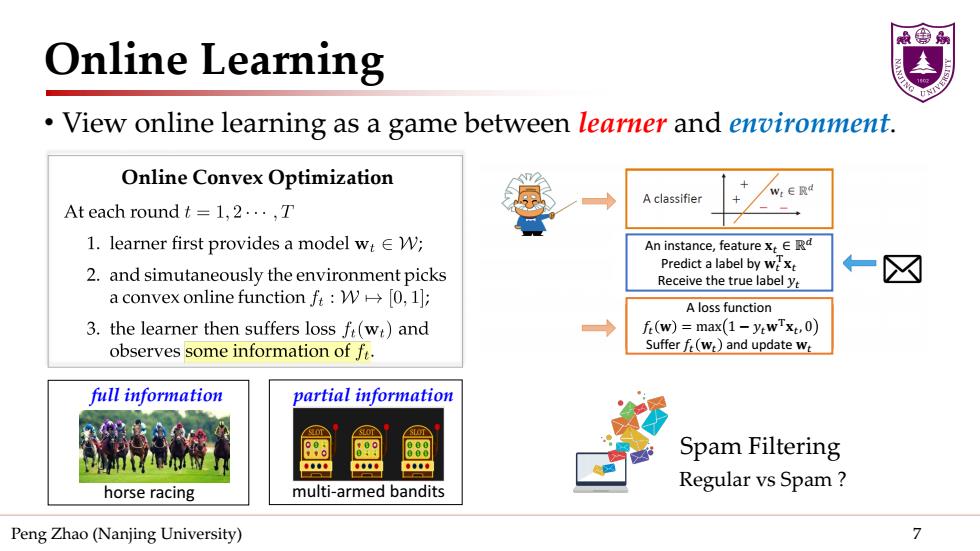
Online Learning View online learning as a game between learner and environment. Online Convex Optimization A classifier w:e段d At each round t=1,2...,T 1.learner first provides a model w:EW; An instance,feature x ERd Predict a label by we xt 2.and simutaneously the environment picks Receive the true label yt 仁区☒ a convex online function f:W→[0,l: A loss function 3.the learner then suffers loss f(wt)and fr(w)=max(1-y:wTxt,0) observes some information of f. Sufferf(wr)and update w full information partial information Spam Filtering 金海的单 800专 单意金也 horse racing multi-armed bandits Regular vs Spam Peng Zhao(Nanjing University) 7
Peng Zhao (Nanjing University) 7 Online Learning • View online learning as a game between learner and environment. An instance, feature 𝐱𝐱𝑡𝑡 ∈ ℝ𝑑𝑑 Predict a label by 𝐰𝐰𝑡𝑡 T𝐱𝐱𝑡𝑡 Receive the true label 𝑦𝑦𝑡𝑡 Regular vs Spam ? Spam Filtering A loss function 𝑓𝑓𝑡𝑡 𝐰𝐰 = max 1 − 𝑦𝑦𝑡𝑡𝐰𝐰T𝐱𝐱𝑡𝑡, 0 Suffer 𝑓𝑓𝑡𝑡 𝐰𝐰𝑡𝑡 and update 𝐰𝐰𝑡𝑡 Online Convex Optimization full information horse racing partial information multi-armed bandits

效鲁 Outline 。Problem Setup Non-stationary Online Learning Universal Online Learning 。Conclusion Peng Zhao (Nanjing University) 8
Peng Zhao (Nanjing University) 8 Outline • Problem Setup • Non-stationary Online Learning • Universal Online Learning • Conclusion

殿细 Non-stationary Online Learning Distribution shift:data are usually collected in open environments species monitoring urban computing route planning winter For the online learning scenario,the distributions will evolve over time. M continuous M沙 distribution provably robust methods for non-stationary online learning Peng Zhao(Nanjing University) 9
Peng Zhao (Nanjing University) 9 Non-stationary Online Learning • Distribution shift: data are usually collected in open environments species monitoring summer winter urban computing route planning • For the online learning scenario, the distributions will evolve over time. continuous distribution shift provably robust methods for non-stationary online learning

Community Discussions turing lecture What needs to be improved.From the early days,theoreticians of ma- chine learning have focused on the iid “Deep Learning for AI assumption,which states that the test can neu al metwok learn the rieh cases are expected to come from the same distribution as the training ex- Communication of ACM amples.Unfortunately,this is not a re- alistic assumption in the real world: just consider the non-stationarities July,2021.Vol 64.No 7. Deep due to actions of various agents chang- ing the world,or the gradually expand- Learning ing mental horizon of a learning agent which always has more to learn and discover.As a practical consequence, for Al the performance of today's best Al sys- tems tends to take a hit when they go TURING LECTURE from the lab to the field. Our desire to achieve greater robust- ness when confronted with changes in distribution(called out-of-distribution generalization)is a special case of the mothated by the more general objective of reducing sample complexity (the number of ex- amples needed to generalize well)when Yoshua Benglo Geoffrey Hinton Yann LeCun faced with a new task-as in transfer learning and lifelong learning-or 2018 Turing Award Recipients simply with a change in distribution or Peng Zhao (Nanjing University) 10
Peng Zhao (Nanjing University) 10 Community Discussions “Deep Learning for AI” Communication of ACM July, 2021. Vol 64. No 7. 2018 Turing Award Recipients