
第11卷第2期 智能系统学报 Vol.11 No.2 2016年4月 CAAI Transactions on Intelligent Systems Apr.2016 D0I:10.11992/is.201511008 网络出版地址:http://www.enki..net/kcms/detail/23.1538.TP.20160315.1248.018.html 一种语音特征提取中Ml倒谱系数的后处理算法 张毅,谢延义2,罗元3,席兵3 (1.重庆邮电大学先进制造工程学院,重庆400065:2.重庆邮电大学自动化学院,重庆400065:3.重庆邮电大学光 电工程学院,重庆400065) 摘要:为提高语音识别系统的鲁棒性,本文以Ml频率倒谱系数(MFCC)为基础,结合均值消减法、方差归一化、时 间序列滤波法和加权自回归移动平均滤波法,提出了一种后处理算法,本文将该算法命名为MVDA后处理法,所得 语音特征参数简称MVDA。本文首先从理论上推导了MVDA后处理法可以去除加性噪声和卷积噪声的干扰,接着 针对MVDA与MFCC做了对比试验,并分析了含噪语音与语音信号的欧氏距离变化,证明MVDA后处理法的每一步 均有效降低了噪声的干扰,且得出了MVDA在不同噪声环境中均更优的结论。这种简洁的语音特征不仅可以达到 许多复杂语音特征处理方法的效果,而且有效减少了自动语音识别系统的计算量。 关键词:后处理:语音特征:语音识别:噪声:鲁棒性 中图分类号:TP391.4文献标志码:A文章编号:1673-4785(2016)02-0208-07 中文引用格式:张毅,谢延义,罗元,等.一种语音特征提取中Ml倒谱系数的后处理算法[J].智能系统学报,2016,11(2): 208-215. 英文引用格式:ZHANG Yi,XIE Yanyi,LUO Yuan,etal.Postprocessing method of MFCC in speech feature extraction[J].CAAI transactions on intelligent systems,2016,11(2):208-215. Postprocessing method of MFCC in speech feature extraction ZHANG Yi',XIE Yanyi2,LUO Yuan',XI Bing' (1.Institute of Advanced Manufacturing Engineering,Chongqing University of Posts and Telecommunications,Chongqing 400065, China;2.College of Automation,Chongqing University of Posts and Telecommunications,Chongqing 400065,China;3.College of Opto Electronic Engineering,Chongqing University of Posts and Telecommunications,Chongqing 400065,China) Abstract:To improve the robustness of automatic speech recognition systems,a new speech feature postprocessing method based on the Mel-frequency Cepstral Coefficient MFCC)is proposed,which is named the MVDA postpro- cessing method.The postprocessed feature parameters are named MVDAs.This technique combines mean subtrac- tion,variance normalization,time sequence fltering,and autoregressive moving average flters.Experiments were conducted to compare MVDA and MFCC.Changes in the Euclidean distance of the speech with noise and the speech signal were analyzed,proving that every step of MVDA postprocessing could effectively reduce the noise in- terference.Thus,all MVDAs in different noise environments were superior.This simple feature does not only a- chieve the effect of many complex speech feature processing methods but also effectively reduces the computational complexity of automatic speech recognition systems. Keywords:postprocessing;phonetic feature;speech recognition;noise;robustness 为了提高语音识别系统的鲁棒性,谱减法、卡尔 收稿日期:2015-11-06.网络出版日期:2016-03-15. 曼滤波1]和麦克风阵列[]等语音增强技术得到应 基金项目:重庆市科委前沿技术专项重点项目(cstc2015 jeyjBX0066). 通信作者:谢延义.E-mail:811719530@qq.com. 用和推广。语音特征的失真造成声学空间的变形
第 11 卷第 2 期 智 能 系 统 学 报 Vol.11 №.2 2016 年 4 月 CAAI Transactions on Intelligent Systems Apr. 2016 DOI:10.11992 / tis.201511008 网络出版地址:http: / / www.cnki.net / kcms/ detail / 23.1538.TP.20160315.1248.018.html 一种语音特征提取中 Mel 倒谱系数的后处理算法 张毅1 ,谢延义2 ,罗元3 ,席兵3 (1.重庆邮电大学 先进制造工程学院,重庆 400065; 2. 重庆邮电大学 自动化学院,重庆 400065; 3. 重庆邮电大学 光 电工程学院,重庆 400065) 摘 要:为提高语音识别系统的鲁棒性,本文以 Mel 频率倒谱系数(MFCC)为基础,结合均值消减法、方差归一化、时 间序列滤波法和加权自回归移动平均滤波法,提出了一种后处理算法,本文将该算法命名为 MVDA 后处理法,所得 语音特征参数简称 MVDA。 本文首先从理论上推导了 MVDA 后处理法可以去除加性噪声和卷积噪声的干扰,接着 针对 MVDA 与 MFCC 做了对比试验,并分析了含噪语音与语音信号的欧氏距离变化,证明 MVDA 后处理法的每一步 均有效降低了噪声的干扰,且得出了 MVDA 在不同噪声环境中均更优的结论。 这种简洁的语音特征不仅可以达到 许多复杂语音特征处理方法的效果,而且有效减少了自动语音识别系统的计算量。 关键词:后处理;语音特征;语音识别;噪声;鲁棒性 中图分类号:TP391.4 文献标志码:A 文章编号:1673⁃4785(2016)02⁃0208⁃07 中文引用格式:张毅,谢延义,罗元,等. 一种语音特征提取中 Mel 倒谱系数的后处理算法[ J] . 智能系统学报, 2016, 11( 2) : 208⁃215. 英文引用格式:ZHANG Yi,XIE Yanyi,LUO Yuan, et al. Postprocessing method of MFCC in speech feature extraction[ J]. CAAI transactions on intelligent systems, 2016, 11(2): 208⁃215. Postprocessing method of MFCC in speech feature extraction ZHANG Yi 1 , XIE Yanyi 2 , LUO Yuan 3 , XI Bing 3 (1. Institute of Advanced Manufacturing Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China; 2. College of Automation, Chongqing University of Posts and Telecommunications, Chongqing 400065, China; 3. College of Opto Electronic Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China) Abstract:To improve the robustness of automatic speech recognition systems, a new speech feature postprocessing method based on the Mel⁃frequency Cepstral Coefficient (MFCC) is proposed, which is named the MVDA postpro⁃ cessing method. The postprocessed feature parameters are named MVDAs. This technique combines mean subtrac⁃ tion, variance normalization, time sequence fltering, and autoregressive moving average flters. Experiments were conducted to compare MVDA and MFCC. Changes in the Euclidean distance of the speech with noise and the speech signal were analyzed, proving that every step of MVDA postprocessing could effectively reduce the noise in⁃ terference. Thus, all MVDAs in different noise environments were superior. This simple feature does not only a⁃ chieve the effect of many complex speech feature processing methods but also effectively reduces the computational complexity of automatic speech recognition systems. Keywords: postprocessing; phonetic feature; speech recognition; noise; robustness 收稿日期:2015⁃11⁃06. 网络出版日期:2016⁃03⁃15. 基金项目:重庆市科委前沿技术专项重点项目(cstc2015jcyjBX0066). 通信作者:谢延义. E⁃mail:811719530@ qq.com. 为了提高语音识别系统的鲁棒性,谱减法、卡尔 曼滤波[1⁃2]和麦克风阵列[3] 等语音增强技术得到应 用和推广。 语音特征的失真造成声学空间的变形

第2期 张毅,等:一种语音特征提取中M倒谱系数的后处理算法 ·209· 对此声学模型可以相应地调整,以弥补训练和测试 声环境下的{s(t)}本身存在失真,这种失真可以看 语音之间的差异,这种调整通常被称为噪声模型补 做是式(4)的一个特例。 偿技术4。由于语音去噪的复杂性,甚至小词汇 1.2基础语音特征MFCC 的自动语音识别系统都采用了相对复杂的处理方 本文以Ml频率倒谱系数为基础,提出了新的 法[6)。这些复杂的处理方法往往会造成较大的计 语音特征提取法。MFCC的分析基于人的听觉机 算量和不必要的时延,降低自动语音识别系统的灵 理,即根据人的听觉实验结果来分析语音的频谱,期 活性。 望获得更好的语音特性。MFCC分析依据的听觉机 因此本文综合考虑自动语音识别系统的鲁棒性 理有两个:1)人的主观感知频域的划定并不是线性 和灵敏性,有针对性地提出了一种简洁的语音信号 的:2)人耳听觉的临界带原理。 后处理方法一MVDA后处理法。同时,也改善了 ~帧语音信号的MFCC参数可以表示为C△ 传统的MFCC特征提取方法中采用三角滤波器组带 (C[1]…C[D])',这里D表示倒谱系数的维数。 来的相邻频带之间的频谱能量相互泄露,且不利于 MFCC的定义如下: 反映共振特性的问题,为整个语音识别系统的优化 C=GInQ (5) 提供了基础。实验表明,MVDA后处理法在不同的 这里Q△(Q[1]…Q[J])'表示每帧的谱线能量经 噪声环境中的鲁棒性和灵敏性都要高于传统的MF- 过梅尔三角滤波器处理后的梅尔能量谱。G是代表 CC特征提取法。 离散余弦变换的1*J阶矩阵,表示为 1 噪声分类和MFCC G 2 -co 自动语音识别系统的鲁棒性取决于噪声、语音 i=1,2,…,1,j=1,2,…,J (6) 特征和语音信号处理方法。本节首先定义了日常声 MFCC特征提取方法采用三角滤波器组处理, 学环境中常见的噪声类型,对噪声的分类有利于本 同时也带来的相邻频带之间频谱能量的相互泄露。 文更加清晰地分析特征失真,并且有利于描述MV- 2 MVDA后处理法步骤 DA后处理法。 1.1噪声的分类 MVDA后处理法在MFCC特征提取法的基础 通常处理的噪声分为加性噪声和卷积噪声。加 上,融合了均值消减、方差归一化、时间序列滤波和 性噪声可以描述为 加权自回归移动平均滤波法,图1为MVDA后处理 x(t)=s(t)+n(t) (1) 法基本步骤。 式中:{s(t)}是语音信号,{n(t)}是加性噪声, 方 时 加权 {x(t)}是含噪语音。卷积噪声可以描述为 x(t) c 差归 自回 C 序 归 c 么 x(t)=s(t)*n(t) (2) 消 平 式中:*是卷积符号,h(t)是环境导致的卷积噪 化 滤 均滤 波法 声。此处假设环境是稳定的,在实际环境中,两种类 图1 MVDA后处理法 型的噪声同时存在。因此加噪语音可以描述为 Fig.1 Postprocessing of MVDA x(t)=s(t)*h(t)+n(t) (3) MVDA的提出是为了解决MFCC特征参数的 式(3)可以被看成是一般噪声情况下,表明语 加性和卷积噪声的问题,均值消减和方差归一化在 音成分与噪声成分的一种方法,可以简化为 语音处理中已经得到了相对广泛的应用[1)]。本文 x(t)=F(s(t)) (4) 提出了结合时间序列滤波和加权自回归移动平均滤 式中:F指非线性时变环境下语音信号的映射。由 波法在频域的应用,可以获得相较于单独使用均值 于语音信号具有短时连续性,经过分帧加窗之后,语 消减和方差归一化更好的效果。 音信号在短时内接近线性时不变。 本文用C)表示第r帧语音的特征,则均值消 另一种失真产生于噪声环境下样本采集过程中 减表示为 的Lombard效应[s】,如延长元音的持续时间和频谱 向高频率倾斜,从而改变了语音信号本身。因此,噪 Cr)=C(r)-u (7)
对此声学模型可以相应地调整,以弥补训练和测试 语音之间的差异,这种调整通常被称为噪声模型补 偿技术[4⁃5] 。 由于语音去噪的复杂性,甚至小词汇 的自动语音识别系统都采用了相对复杂的处理方 法[6] 。 这些复杂的处理方法往往会造成较大的计 算量和不必要的时延,降低自动语音识别系统的灵 活性[7] 。 因此本文综合考虑自动语音识别系统的鲁棒性 和灵敏性,有针对性地提出了一种简洁的语音信号 后处理方法———MVDA 后处理法。 同时,也改善了 传统的 MFCC 特征提取方法中采用三角滤波器组带 来的相邻频带之间的频谱能量相互泄露,且不利于 反映共振特性的问题,为整个语音识别系统的优化 提供了基础。 实验表明,MVDA 后处理法在不同的 噪声环境中的鲁棒性和灵敏性都要高于传统的 MF⁃ CC 特征提取法。 1 噪声分类和 MFCC 自动语音识别系统的鲁棒性取决于噪声、语音 特征和语音信号处理方法。 本节首先定义了日常声 学环境中常见的噪声类型,对噪声的分类有利于本 文更加清晰地分析特征失真,并且有利于描述 MV⁃ DA 后处理法。 1.1 噪声的分类 通常处理的噪声分为加性噪声和卷积噪声。 加 性噪声可以描述为 x(t) = s(t) + n(t) (1) 式中: {s(t)} 是语音信号, {n(t)} 是加性噪声, {x(t)} 是含噪语音。 卷积噪声可以描述为 x(t) = s(t)∗n(t) (2) 式中: ∗ 是卷积符号, h(t) 是环境导致的卷积噪 声。 此处假设环境是稳定的,在实际环境中,两种类 型的噪声同时存在。 因此加噪语音可以描述为 x(t) = s(t)∗h(t) + n(t) (3) 式(3)可以被看成是一般噪声情况下,表明语 音成分与噪声成分的一种方法,可以简化为 x(t) = F(s(t) ) (4) 式中: F 指非线性时变环境下语音信号的映射。 由 于语音信号具有短时连续性,经过分帧加窗之后,语 音信号在短时内接近线性时不变。 另一种失真产生于噪声环境下样本采集过程中 的 Lombard 效应[8] ,如延长元音的持续时间和频谱 向高频率倾斜,从而改变了语音信号本身。 因此,噪 声环境下的 {s(t)} 本身存在失真,这种失真可以看 做是式(4)的一个特例。 1.2 基础语音特征 MFCC 本文以 Mel 频率倒谱系数为基础,提出了新的 语音特征提取法。 MFCC 的分析基于人的听觉机 理,即根据人的听觉实验结果来分析语音的频谱,期 望获得更好的语音特性。 MFCC 分析依据的听觉机 理有两个:1)人的主观感知频域的划定并不是线性 的;2)人耳听觉的临界带原理。 一帧语音信号的 MFCC 参数可以表示为 C (C[1]…C[D]) T ,这里 D 表示倒谱系数的维数。 MFCC 的定义如下: C = G lnQ (5) 这里 Q (Q[1]…Q[J]) T 表示每帧的谱线能量经 过梅尔三角滤波器处理后的梅尔能量谱。 G 是代表 离散余弦变换的 I∗J 阶矩阵,表示为 Gij = 2 J cos πi J (j - 0.5) æ è ç ö ø ÷ i = 1,2,…,I, j = 1,2,…,J (6) MFCC 特征提取方法采用三角滤波器组处理, 同时也带来的相邻频带之间频谱能量的相互泄露。 2 MVDA 后处理法步骤 MVDA 后处理法在 MFCC 特征提取法的基础 上,融合了均值消减、方差归一化、时间序列滤波和 加权自回归移动平均滤波法,图 1 为 MVDA 后处理 法基本步骤。 图 1 MVDA 后处理法 Fig.1 Postprocessing of MVDA MVDA 的提出是为了解决 MFCC 特征参数的 加性和卷积噪声的问题,均值消减和方差归一化在 语音处理中已经得到了相对广泛的应用[9⁃12] 。 本文 提出了结合时间序列滤波和加权自回归移动平均滤 波法在频域的应用,可以获得相较于单独使用均值 消减和方差归一化更好的效果。 本文用 C (τ) 表示第 τ 帧语音的特征,则均值消 减表示为 C - (τ) = C (τ) - μ (7) 第 2 期 张毅,等:一种语音特征提取中 Mel 倒谱系数的后处理算法 ·209·

·210· 智能系统学报 第11卷 式中:山是根据样本数据估计的均值项。方差归一 平均滤波法的去噪效果,并分析在滤波前后噪声对 化法表示为 语音特征的影响。 c)[d]=(σ2[d])-2c[d] (8) 3.1均值消减 本文首先分析卷积噪声对语音特征造成的失 式中:C是均值消减和方差归一化之后的特征, 真,并且得出均值消减可以有效去除卷积噪声。分 σ2[d]是特征向量第d维的估计方差。本文的时间 析表明,频域均值消减导致参数在时不变卷积噪声 序列滤波法表示为 下是稳定的。 kc) (k-1)2C- 卷积噪声在频域内表现为乘法运算,因此 C)= k=1 k=1 (9) {x(t)}、{s(t)}和{h(t)}的功率谱可以表示为 P,[k]=P,[k]P,[k] 式中:C是均值消减、方差归一化和时间序列滤波之 式中:P[k]=|X[k]2|,X[k]为语音信号x[n] 后的特征,k代表时间序列的宽度,心为其最大宽 的离散傅里叶变换。根据式(5),x的第i维参数为 -1 度。本文的加权自回归移动平均滤波法表示为 C)=[C-m)+…+(m-1)C-)+mC]/m2+ 式中:F:表示第j个Mel特征滤波器的第k条谱线。 [(m-1)C+)+…+Cr+m)]/m2 般情况下,C,和C,并不是简单的通过h关 (10) 联,因为对数的参数求和不能被因式分解。如果假 设P。是相对平滑的,每一个Ml滤波器频带内卷积 式中:C是MVDA滤波之后的特征,m代表加权自 噪声的变化很小。 回归移动平均滤波法深度,特殊情况m=1表示没 有加权自回归移动平均滤波处理,综合考虑算法的 复杂度和准确度,一般取m=3。 艺- FP.[k]P.tk] 均值μ和方差σ2的估计可以采用多种方法。 N- 在方差估计法[3]中,均值和方差根据一整段对话语 P,[1名FP[ 音估计。如果环境是静态的,则这种估计是相对稳 式中:P[k]为{h(t)}在第j维滤波器中的能量谱。 定的。而根据在线估计法[4」,均值和方差可以不依 赖将来的特征观察值,根据当前样本估计,这种策略 c=2,h.[1点,P[)= 时延低,适用于灵敏度要求高的系统。介于这两种 策略之间的是语句估计法。本文中的所有结果都基 含c61+ieI2.PI) 于语句估计,其定义为 c9 C(]h.) u= B[i门+C,[i] (c[d]-[d]) 式中B,[]△∑C,lnP[]。 式中:T为给定语句中的帧数。注意在语句归一化 上述假设不排除在P,在Ml频域滤波器的不 法中,结果可能被语音前后的空白和噪声影响[5], 同频带内产生变化,而只要求其在每个频带内的变 本文的研究假设在计算均值和方差统计之前,已经 化足够小,该假设要求设计良好的传输设备通带。 对语音进行了合理的分割。 然而在多噪声环境中,从声源到接收者的多路径反 射可能导致峰谷的频率响应6,不满足上述假设。 3噪声影响与MVDA滤波法分析 因此第i维噪声和语音信号MFCC的差别与 关于频域加性和卷积噪声,本文均作了详细的 {h(t)},而与{s(t)}无关。也就是说,卷积噪声增 分析。本节从理论上推导MVDA滤波法,分析均值 加特征的偏置取决于瞬时的信道特性数值。如果进 消减、方差归一化、时间序列滤波和加权自回归移动 一步假设噪声是稳态的,对于MFCC,有
式中: μ 是根据样本数据估计的均值项。 方差归一 化法表示为 C ^ (τ) [d] = (σ 2 [d]) -1/ 2C - (τ) [d] (8) 式中: C ^ 是均值消减和方差归一化之后的特征, σ 2 [d] 是特征向量第 d 维的估计方差。 本文的时间 序列滤波法表示为 C ⌒ (τ) = ∑ w k = 1 k 2C ^ (τ+k) - ∑ w k = 1 (k - 1) 2C ^ (τ-k) (4k - 2)∑ w k = 1 k 2 (9) 式中: C ⌒ 是均值消减、方差归一化和时间序列滤波之 后的特征, k 代表时间序列的宽度, w 为其最大宽 度。 本文的加权自回归移动平均滤波法表示为 C ~ (τ) = C ~ (τ-m) + … + (m - 1)C ~ (τ-1) + mC ~ (τ) [ ] / m 2 + (m - 1)C ⌒ (τ+1) + … + C ⌒ (τ+m) [ ] / m 2 (10) 式中: C ⌒ 是 MVDA 滤波之后的特征, m 代表加权自 回归移动平均滤波法深度,特殊情况 m = 1 表示没 有加权自回归移动平均滤波处理, 综合考虑算法的 复杂度和准确度,一般取 m = 3。 均值 μ 和方差 σ 2 的估计可以采用多种方法。 在方差估计法[13 ]中,均值和方差根据一整段对话语 音估计。 如果环境是静态的,则这种估计是相对稳 定的。 而根据在线估计法[14 ] ,均值和方差可以不依 赖将来的特征观察值,根据当前样本估计,这种策略 时延低,适用于灵敏度要求高的系统。 介于这两种 策略之间的是语句估计法。 本文中的所有结果都基 于语句估计,其定义为 μ = 1 T ∑ T τ = 1 C (τ) σ 2 [d] = 1 T ∑ T τ = 1 (C (τ) [d] - μ[d]) 2 式中: T 为给定语句中的帧数。 注意在语句归一化 法中,结果可能被语音前后的空白和噪声影响[15 ] , 本文的研究假设在计算均值和方差统计之前,已经 对语音进行了合理的分割。 3 噪声影响与 MVDA 滤波法分析 关于频域加性和卷积噪声,本文均作了详细的 分析。 本节从理论上推导 MVDA 滤波法,分析均值 消减、方差归一化、时间序列滤波和加权自回归移动 平均滤波法的去噪效果,并分析在滤波前后噪声对 语音特征的影响。 3.1 均值消减 本文首先分析卷积噪声对语音特征造成的失 真,并且得出均值消减可以有效去除卷积噪声。 分 析表明,频域均值消减导致参数在时不变卷积噪声 下是稳定的。 卷积噪 声 在 频 域 内 表 现 为 乘 法 运 算, 因 此 {x(t)} 、 {s(t)} 和 {h(t)} 的功率谱可以表示为 Px[k] = Ps[k]Ph [k] 式中: Px[k] = X [k] 2 , X[k] 为语音信号 x[n] 的离散傅里叶变换。 根据式(5), x 的第 i 维参数为 Cx[i] = ∑ J j = 1 Gij ln ∑ N-1 k = 0 ( FjkPx[k] ) 式中: Fjk 表示第 j 个 Mel 特征滤波器的第 k 条谱线。 一般情况下, Cx 和 Cs 并不是简单的通过 h 关 联,因为对数的参数求和不能被因式分解。 如果假 设 Ph 是相对平滑的,每一个 Mel 滤波器频带内卷积 噪声的变化很小。 ∑ N-1 k = 0 FjkPx[k] = ∑ N-1 k = 0 FjkPs[k]Ph [k] ≈ Ph [kj]∑ N-1 k = 0 FjkPs[k] 式中: Ph [kj] 为 {h(t)} 在第 j 维滤波器中的能量谱。 Cx[i] = ∑ J j = 1 Gij ln Ph [kj]∑ N-1 k = 0 ( FjkPs[k] ) = ∑ J j = 1 Gij lnPh [kj] + log ∑ N-1 k = 0 ( [ FjkPs[k] ] ) = ∑ J j = 1 Gij lnPh [k ( j] + lnQs[j] ) = Bh [i] + Cs[i] 式中 Bh [i] ∑ J j = 1 Gij lnPh [kj] 。 上述假设不排除在 Ph 在 Mel 频域滤波器的不 同频带内产生变化,而只要求其在每个频带内的变 化足够小,该假设要求设计良好的传输设备通带。 然而在多噪声环境中,从声源到接收者的多路径反 射可能导致峰谷的频率响应[16] ,不满足上述假设。 因此 第 i 维 噪 声 和 语 音 信 号 MFCC 的 差 别 与 {h(t)} ,而与 {s(t)} 无关。 也就是说,卷积噪声增 加特征的偏置取决于瞬时的信道特性数值。 如果进 一步假设噪声是稳态的,对于 MFCC,有 ·210· 智 能 系 统 学 报 第 11 卷

第2期 张毅,等:一种语音特征提取中M倒谱系数的后处理算法 ·211· C,[i]=C.[i]-u,[i]= 三c,hno.j+20.ij+f0.i)- C,[i订+B[i订-(u,[i]+B[i])= C.[i]-4,[i]=C,[i],i=0,1,…,1 c,[+,+2y0 C,[i]+8C[i],i=1,2,…,1 因此在稳态噪声和相对平滑的卷积噪声环境 语音失真为 下,均值消减特征不会改变。从而在语句结构中,如 果环境噪声是卷积类型并且在语句内是稳态的、平 δC[i]△】 滑的,均值消减法是有效的。对均值消减的上述特 因此失真与语音信号s(t)和噪声n(t:y)相 性均建立在卷积噪声的基础上。对于加性噪声的分 关。一般强度的加性噪声影响与语音信号、噪声类 析将在后面三级滤波中进行分析。 型和噪声强度有着复杂的关系,因此加性噪声的滤 3.2方差归一化 波相对困难。当存在噪声语音数据样本时,可以考 加性噪声不同于卷积噪声,在经过频域变换之 虑设计潜在的非线性变换来减小语音信号的失真。 后语音与加性噪声更加难以区分,为了更加方便地 均值消减法的使用无法弥补(C2≠C,)造成 分析加性噪声环境下的语音信号,我们将含噪语音 的失真。处理含噪语音的方法有两种,一种是直接 定义为 使用含噪语音样本,另一种是非线性变换去噪,直接 x(t;y)=s(t)+n(t;y)=s(t)+yno(t) 使用含噪语音必须与测试语音噪声匹配。 式中:加性噪声n(ty)△yn.(t)中的y变量表示噪 加性噪声造成的语音信号失真不仅仅取决于噪 声的强度。本文首先分析加性噪声,然后分析语音信 声的加性增益,而与语音信号和噪声均相关,因此很 号。n(t;y)和n,(t)在Mel频域的对数特征表示为 难去除加性噪声。在低噪声环境下这种关联并不明 N- 显。高噪声环境下,在去除噪声增益项之后,本文应 In [j]=In ,F(y2P[k])) 用了方差归一化法以弥补语音信号特征的衰减。由 N-1 于存在y1的增益,在使用方差归一化法后,也无法 2nyl+ln(∑FP.[k])= 得到零加性噪声的语音信号,因此处理后的语音特 k=0 2In ly+In Q [j] 征很难满足要求。 3.3时间序列滤波和加权自回归移动平均滤波 式中:Q和Q分别是n(ty)和n.(t)的Mel频 本文首先分析了没有假设y的语音信号失真。 率谱表示,Mel倒谱系数可以表示为 以此为依据建立了方差归一化法,并基于该方法的 C [i]=G,(2In lyl+In Q.[jl)=C..[i] 不足,分析低噪声|yg1和高噪声|y之1,这两 种噪声情况都可以通过近似来简化。 式中:Ca)和Cn.分别是n(t;y)和n(t)的倒谱, 1)低加性噪声 MFCC并没有衰减。含噪语音的功率谱为 当|y≤1时,失真可以简化为 P[k]= Q] IS[k]2|+2y|S[k]N.[k]+y2|N.[k]2I= C.d=三c,n1+2y0 ≈2yCa[i] P.[k]+2y S[k]N,[k]+y'P [k] 式中:C[订△】 式中:P)、P和P.分别表示x(t:y)、s(t)和 c,(Q[]Q.]),并且 n.(t)的功率谱。由于Mel分级是线性运算,因此 ln(1+x)≈x。 2)高加性噪声 Q [j]=Q.[j]2yQ[]+yQ.,[j] 当y≥1时,失真可简化为 式中:Q,]△∑Fs[k]v[k]l,Q、Q. 和Q,分别代表x(t:y)、s(t)和n.(t)的功率谱。 0a-2cr(o.1+2o.j) Ml特征频谱的失真由两部分构成:一部分取决于 并且失真之后的MFCC特征近似为 噪声和语音信号,并且与y成正比。另一部分只取 决于噪声,并且与y2成正比。根据式(5): cti.)
C - x (τ) [i] = Cx (τ) [i] - μx[i] = Cx (τ) [i] + Bh [i] - (μs[i] + Bh [i]) = Cx (τ) [i] - μs[i] = C - s (τ) [i],i = 0,1,…,I 因此在稳态噪声和相对平滑的卷积噪声环境 下,均值消减特征不会改变。 从而在语句结构中,如 果环境噪声是卷积类型并且在语句内是稳态的、平 滑的,均值消减法是有效的。 对均值消减的上述特 性均建立在卷积噪声的基础上。 对于加性噪声的分 析将在后面三级滤波中进行分析。 3.2 方差归一化 加性噪声不同于卷积噪声,在经过频域变换之 后语音与加性噪声更加难以区分,为了更加方便地 分析加性噪声环境下的语音信号,我们将含噪语音 定义为 x(t;γ) = s(t) + n(t;γ) = s(t) + γn0(t) 式中:加性噪声 n(t;γ) γno(t) 中的 γ 变量表示噪 声的强度。 本文首先分析加性噪声,然后分析语音信 号。 n(t;γ) 和 no(t) 在 Mel 频域的对数特征表示为 ln Qn(γ) [j] = ln ∑ N-1 k = 0 Fjk γ 2Pno ( ( [k] ) ) = 2ln γ + ln ∑ N-1 k = 0 FjkPno ( [k] ) = 2ln γ + ln Qno [j] 式中: Qn(γ) 和 Qno 分别是 n(t;γ) 和 no(t) 的 Mel 频 率谱表示,Mel 倒谱系数可以表示为 Cn(γ) [i] = ∑ J j = 1 Gij 2ln γ + ln Qno ( [j] ) = Cno [i] 式中: Cn(γ) 和 Cno 分别是 n(t;γ) 和 no(t) 的倒谱, MFCC 并没有衰减。 含噪语音的功率谱为 Px(γ) [k] = S [k] 2 + 2γ S[k]No[k] + γ 2 No [k] 2 = Ps[k] + 2γ S[k]No[k] + γ 2Pno [k] 式中: Px(γ) 、 Ps 和 Pno 分别表示 x(t;γ) 、 s(t) 和 no(t) 的功率谱。 由于 Mel 分级是线性运算,因此 Qx(γ) [j] = Qs[j] + 2γQ1 [j] + γ 2Qno [j] 式中: Q1 [j] ∑ N-1 k = 0 Fjk S[k]No[k] , Qx(γ) 、 Qs 和 Qno 分别代表 x(t;γ) 、 s(t) 和 no(t) 的功率谱。 Mel 特征频谱的失真由两部分构成:一部分取决于 噪声和语音信号,并且与 γ 成正比。 另一部分只取 决于噪声,并且与 γ 2 成正比。 根据式(5): Cx(γ) [i] = ∑ J j = 1 Gij lnQx(γ) [j] = ∑ J j = 1 Gij ln Qs[j] + 2γQ1 [j] + γ 2Qno ( [j] ) = Cs[i] + ∑ J j = 1 Gij ln 1 + 2γ Q1 [j] Qs[j] + γ 2 Qno [j] Qs[j] æ è ç ö ø ÷ = Cs[i] + δCx(γ) [i], i = 1,2,…,I 语音失真为 δCx(γ) [i] ∑ J j = 1 Gij ln 1 + 2γ Q1 [j] Qs[j] + æ è ç ö ø ÷ γ 2 Qno [j] Qs[j] 因此失真与语音信号 s(t) 和噪声 n(t;γ) 相 关。 一般强度的加性噪声影响与语音信号、噪声类 型和噪声强度有着复杂的关系,因此加性噪声的滤 波相对困难。 当存在噪声语音数据样本时,可以考 虑设计潜在的非线性变换来减小语音信号的失真。 均值消减法的使用无法弥补 Ce2 ≠ Cs ( ) 造成 的失真。 处理含噪语音的方法有两种,一种是直接 使用含噪语音样本,另一种是非线性变换去噪,直接 使用含噪语音必须与测试语音噪声匹配。 加性噪声造成的语音信号失真不仅仅取决于噪 声的加性增益,而与语音信号和噪声均相关,因此很 难去除加性噪声。 在低噪声环境下这种关联并不明 显。 高噪声环境下,在去除噪声增益项之后,本文应 用了方差归一化法以弥补语音信号特征的衰减。 由 于存在 γ -1 的增益,在使用方差归一化法后,也无法 得到零加性噪声的语音信号,因此处理后的语音特 征很难满足要求。 3.3 时间序列滤波和加权自回归移动平均滤波 本文首先分析了没有假设 γ 的语音信号失真。 以此为依据建立了方差归一化法,并基于该方法的 不足,分析低噪声 γ ≪ 1 和高噪声 γ ≫ 1,这两 种噪声情况都可以通过近似来简化。 1)低加性噪声 当 γ ≪ 1 时,失真可以简化为 δCx(γ) [i] ≈ ∑ J j = 1 Gij ln 1 + 2γ Q1 [j] Qs [j] æ è ç ö ø ÷ ≈ 2γCe1 [i] 式 中: Ce1 [i] ∑ J j = 1 Gij(Q1 [j] / Qs[j]) , 并 且 ln (1 + x) ≈ x 。 2)高加性噪声 当 γ ≫ 1 时,失真可简化为 Qx(γ) [i] ≈ ∑ J j = 1 Gij ln γ 2 Qno [j] + 2 γ Q1 [j] æ è ç ö ø ÷ æ è ç ö ø ÷ 并且失真之后的 MFCC 特征近似为 Cx(γ) [i] ≈ ∑ J j = 1 Gij γ 2 Qno [j] + 2 γ Q1 [j] æ è ç ö ø ÷ æ è ç ö ø ÷ ≈ ∑ J j = 1 Gij ln γ 2Qno 1 + 2 γ Q1 [j] Qno [j] æ è ç ö ø ÷ æ è ç ö ø ÷ ≈ 第 2 期 张毅,等:一种语音特征提取中 Mel 倒谱系数的后处理算法 ·211·
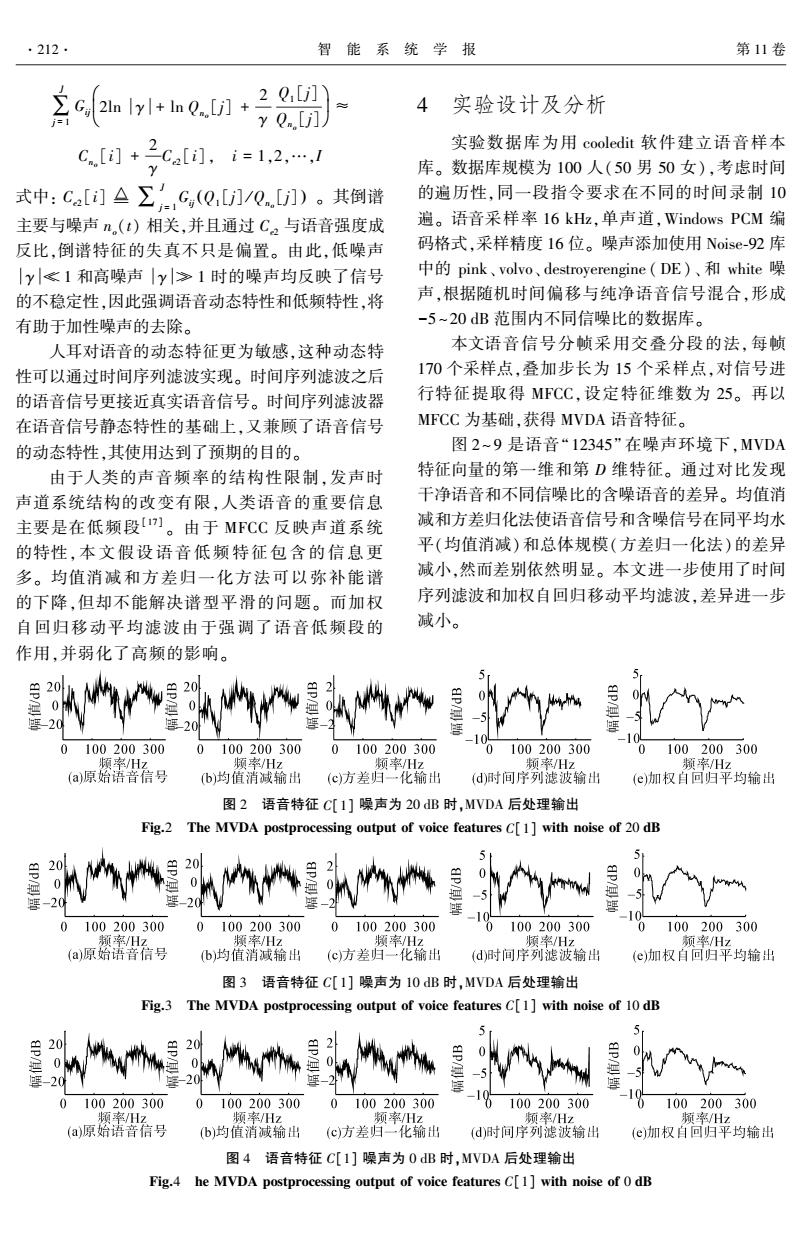
.212. 智能系统学报 第11卷 含c1+h.in+8 4 *y Q..[j]) 实验设计及分析 6.+2ca.ie1,21 实验数据库为用cooledit软件建立语音样本 库。数据库规模为100人(50男50女),考虑时间 式中:Ca[i]△∑c,(Q,j]/J)。其倒谱 的遍历性,同一段指令要求在不同的时间录制10 主要与噪声n.(t)相关,并且通过C2与语音强度成 遍。语音采样率16kHz,单声道,Windows PCM编 反比,倒谱特征的失真不只是偏置。由此,低噪声 码格式,采样精度16位。噪声添加使用Noise-92库 |y≤1和高噪声|y≥1时的噪声均反映了信号 中的pink、volvo、destroyerengine(DE)、和white噪 的不稳定性,因此强调语音动态特性和低频特性,将 声,根据随机时间偏移与纯净语音信号混合,形成 有助于加性噪声的去除。 -5~20dB范围内不同信噪比的数据库。 人耳对语音的动态特征更为敏感,这种动态特 本文语音信号分帧采用交叠分段的法,每帧 性可以通过时间序列滤波实现。时间序列滤波之后 170个采样点,叠加步长为15个采样点,对信号进 的语音信号更接近真实语音信号。时间序列滤波器 行特征提取得MFCC,设定特征维数为25。再以 在语音信号静态特性的基础上,又兼顾了语音信号 MFCC为基础,获得MVDA语音特征。 的动态特性,其使用达到了预期的目的。 图2~9是语音“12345”在噪声环境下,MVDA 由于人类的声音频率的结构性限制,发声时 特征向量的第一维和第D维特征。通过对比发现 声道系统结构的改变有限,人类语音的重要信息 干净语音和不同信噪比的含噪语音的差异。均值消 主要是在低频段1。由于MFCC反映声道系统 减和方差归化法使语音信号和含噪信号在同平均水 的特性,本文假设语音低频特征包含的信息更 平(均值消减)和总体规模(方差归一化法)的差异 多。均值消减和方差归一化方法可以弥补能谱 减小,然而差别依然明显。本文进一步使用了时间 的下降,但却不能解决谱型平滑的问题。而加权 序列滤波和加权自回归移动平均滤波,差异进一步 自回归移动平均滤波由于强调了语音低频段的 减小。 作用,并弱化了高频的影响。 20 20 0 100200300 0 100200300 0 100200300 100200300 100200300 頫率/Hz 频率Hz 频率Hz 频率Hz 频率/Hz (a)原始语音信号 (b)均值消减输出 (c方差归一化输出 (d)时间序列滤波输出 (e)加权自回归平均输出 图2语音特征C[1]噪声为20dB时,MVDA后处理输出 Fig.2 The MVDA postprocessing output of voice features C[1]with noise of 20 dB 20 920 0100200300 0100200300 0100200300 100200300 0100200300 、频率/Hz 顺率Hz 频率Hz 頫案Hz 频率/Hz (a)原始语音信号 b)均值消减输出 (c方差归一·化输出 (d)时间序列滤波输出 (e)加权自回归平均输出 图3语音特征C[1]噪声为10dB时,MVDA后处理输出 Fig.3 The MVDA postprocessing output of voice features C[1]with noise of 10 dB 5 ap/ m20 0 蟹-20 -20 0 100200300 0 100200300 100200300 100200300 100200300 频率Hz 频率Hz 频率/Hz 频率/Hz 频率/Hz (a)原始语音信号 (b)均值消减输出 (c)方差归一化输出 (d)时间序列滤波输出 (e)加权自回归平均输出 图4语音特征C[1]噪声为0dB时,MVDA后处理输出 Fig.4 he MVDA postprocessing output of voice features C[1]with noise of 0 dB
∑ J j = 1 Gij 2ln γ + ln Qno [j] + 2 γ Q1 [j] Qno [j] æ è ç ö ø ÷ ≈ Cno [i] + 2 γ Ce2 [i], i = 1,2,…,I 式中: Ce2 [i] ∑ J j = 1 Gij Q1 [j] / Qno ( [j] ) 。 其倒谱 主要与噪声 no(t) 相关,并且通过 Ce2 与语音强度成 反比,倒谱特征的失真不只是偏置。 由此,低噪声 γ ≪ 1 和高噪声 γ ≫ 1 时的噪声均反映了信号 的不稳定性,因此强调语音动态特性和低频特性,将 有助于加性噪声的去除。 人耳对语音的动态特征更为敏感,这种动态特 性可以通过时间序列滤波实现。 时间序列滤波之后 的语音信号更接近真实语音信号。 时间序列滤波器 在语音信号静态特性的基础上,又兼顾了语音信号 的动态特性,其使用达到了预期的目的。 由于人类的声音频率的结构性限制,发声时 声道系统结构的改变有限,人类语音的重要信息 主要是在低频段[ 17] 。 由于 MFCC 反映声道系统 的特性,本文假设语音低频特征包 含 的 信 息 更 多。 均值消减和方差归一化方法可以弥补能谱 的下降,但却不能解决谱型平滑的问题。 而加权 自回归移动平均滤波由于强调了语音低频段的 作用,并弱化了高频的影响。 4 实验设计及分析 实验数据库为用 cooledit 软件建立语音样本 库。 数据库规模为 100 人(50 男 50 女),考虑时间 的遍历性,同一段指令要求在不同的时间录制 10 遍。 语音采样率 16 kHz,单声道,Windows PCM 编 码格式,采样精度 16 位。 噪声添加使用 Noise⁃92 库 中的 pink、 volvo、 destroyerengine ( DE)、 和 white 噪 声,根据随机时间偏移与纯净语音信号混合,形成 -5~20 dB 范围内不同信噪比的数据库。 本文语音信号分帧采用交叠分段的法,每帧 170 个采样点,叠加步长为 15 个采样点,对信号进 行特征提取得 MFCC,设定特征维数为 25。 再以 MFCC 为基础,获得 MVDA 语音特征。 图 2~ 9 是语音“12345” 在噪声环境下,MVDA 特征向量的第一维和第 D 维特征。 通过对比发现 干净语音和不同信噪比的含噪语音的差异。 均值消 减和方差归化法使语音信号和含噪信号在同平均水 平(均值消减)和总体规模(方差归一化法)的差异 减小,然而差别依然明显。 本文进一步使用了时间 序列滤波和加权自回归移动平均滤波,差异进一步 减小。 图 2 语音特征 C[1] 噪声为 20 dB 时,MVDA 后处理输出 Fig.2 The MVDA postprocessing output of voice features C[1] with noise of 20 dB 图 3 语音特征 C[1] 噪声为 10 dB 时,MVDA 后处理输出 Fig.3 The MVDA postprocessing output of voice features C[1] with noise of 10 dB 图 4 语音特征 C[1] 噪声为 0 dB 时,MVDA 后处理输出 Fig.4 he MVDA postprocessing output of voice features C[1] with noise of 0 dB ·212· 智 能 系 统 学 报 第 11 卷