
第11卷第3期 智能系统学报 Vol.11 No.3 2016年6月 CAAI Transactions on Intelligent Systems Jun.2016 D0I:10.11992/is.201603048 网络出版地址:http://www.enki..net/kcms/detail/23.1538.TP.20160513.0958.036.html 一种结合词向量和图模型的特定领域实体消歧方法 汪沛,线岩团2,郭剑毅2,文永华12,陈玮2,王红斌2 (1.昆明理工大学信息工程与自动化学院,云南昆明650500:2.昆明理工大学智能信息处理重点实验室,云南昆明 650500) 摘要:针对特定领域提出了一种结合词向量和图模型的方法来实现实体消歧。以旅游领域为例,首先选取维基百 科离线数据库中的旅游分类下的页面内容构建领域知识库,然后用知识库中的文本和从各大旅游网站爬取到的旅 游文本,通过词向量计算工具Wod2Vc构建词向量模型,结合人工标注的实体关系图谱,采用一种基于图的随机游 走算法辅助计算相似度,使其能够较准确地计算旅游领域词与词之间的相似度。最后,提取待消歧实体的背景文本 的若干关键词和知识库中候选实体文本的若干关键词,利用训练好的词向量模型结合图模型分别进行交叉相似度 计算,把相似度均值最高的候选实体作为最终的目标实体。实验结果表明,这种新的相似度计算方法能够有效获取 实体指称项与目标实体之间的相似度,从而能够较为准确地实现特定领域的实体消歧。 关键词:实体消歧;实体链接:Word2Vec;图模型:随机游走:维基百科 中图分类号:TP393文献标志码:A文章编号:1673-4785(2016)03-0366-09 中文引用格式:汪沛,线岩团,郭剑毅,等.一种结合词向量和图模型的特定领域实体消歧方法[J].智能系统学报,2016,11(3): 366-375. 英文引用格式:WANG Pei,XIAN Yantuan,GUO Jianyi,etal.A novel method using word vector and graphical models for entity disambiguation in specific topic domains[J].CAAI transactions on intelligent systems,2016,11(3):366-375. A novel method using word vector and graphical models for entity disambiguation in specific topic domains WANG Pei',XIAN Yantuan'2,GUO Jianyi2,WEN Yonghua2,CHEN Wei'2,WANG Hongbin'2 (1.School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China; 2.Key Laboratory of Intelligent Information Processing,Kunming University of Science and Technology,Kunming 650500,China) Abstract:In this paper,a novel method based on word vector and graph models is proposed to deal with entity dis- ambiguation in specific topic domains.Take the tourism topic domain as an example.The method firstly chooses the web-pages of the tourism category in a Wikipedia offline database to build a knowledge base;then,the tool Word2Vec is used to build a word vector model with the texts in the knowledge base and texts taken from several tourism websites.Combined with a manual annotation graph,a random walk algorithm based on the graph is used to compute similarity to accurately calculate the similarity between words within the tourism domain.Next,the method extracts several keywords from the background text of the entity to be disambiguated and compares them with the keyword text in the knowledge base that describes the candidate entities.Finally,the method uses the trained Word2Vec model and graphical model to calculate the similarity between the keywords of name mention and the keywords of candidate entities.The method then chooses the candidate entities which have the maximum average similarity to the target entity.Experimental results show that this new method can effectively capture the similarity between name mention and a target entity;thus,it can accurately achieve entity disambiguation of a topic-specific domain. Keywords:entity disambiguation;entity linking;Word2Vec;Wikipedia;graphical model;random walking 收稿日期:2016-03-19.网络出版日期:2016-05-13. 实体链接是知识库构建的关键技术之一,其目 基金项目:国家自然科学基金项目(61262041,61472168,61462054, 61562052):云南省自然科学基金重点项目(2013FA0B0). 的是将文本中已经获取到的命名实体链接到已有的 通信作者:郭剑毅.E-mail:adc86@hotmail.com
第 11 卷第 3 期 智 能 系 统 学 报 Vol.11 №.3 2016 年 6 月 CAAI Transactions on Intelligent Systems Jun. 2016 DOI:10.11992 / tis.201603048 网络出版地址:http: / / www.cnki.net / kcms/ detail / 23.1538.TP.20160513.0958.036.html 一种结合词向量和图模型的特定领域实体消歧方法 汪沛1 ,线岩团1,2 ,郭剑毅1,2 ,文永华1,2 ,陈玮1,2 ,王红斌1,2 (1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500; 2.昆明理工大学 智能信息处理重点实验室,云南 昆明 650500) 摘 要:针对特定领域提出了一种结合词向量和图模型的方法来实现实体消歧。 以旅游领域为例,首先选取维基百 科离线数据库中的旅游分类下的页面内容构建领域知识库,然后用知识库中的文本和从各大旅游网站爬取到的旅 游文本,通过词向量计算工具 Word2Vec 构建词向量模型,结合人工标注的实体关系图谱,采用一种基于图的随机游 走算法辅助计算相似度,使其能够较准确地计算旅游领域词与词之间的相似度。 最后,提取待消歧实体的背景文本 的若干关键词和知识库中候选实体文本的若干关键词,利用训练好的词向量模型结合图模型分别进行交叉相似度 计算,把相似度均值最高的候选实体作为最终的目标实体。 实验结果表明,这种新的相似度计算方法能够有效获取 实体指称项与目标实体之间的相似度,从而能够较为准确地实现特定领域的实体消歧。 关键词:实体消歧;实体链接;Word2Vec;图模型;随机游走;维基百科 中图分类号:TP393 文献标志码:A 文章编号:1673⁃4785(2016)03⁃0366⁃09 中文引用格式:汪沛,线岩团,郭剑毅,等.一种结合词向量和图模型的特定领域实体消歧方法[ J]. 智能系统学报, 2016, 11( 3): 366⁃375. 英文引用格式:WANG Pei, XIAN Yantuan, GUO Jianyi, et al. A novel method using word vector and graphical models for entity disambiguation in specific topic domains[J]. CAAI transactions on intelligent systems, 2016, 11(3): 366⁃375. A novel method using word vector and graphical models for entity disambiguation in specific topic domains WANG Pei 1 , XIAN Yantuan 1,2 , GUO Jianyi 1,2 , WEN Yonghua 1,2 , CHEN Wei 1,2 , WANG Hongbin 1,2 (1.School of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China; 2. Key Laboratory of Intelligent Information Processing, Kunming University of Science and Technology, Kunming 650500, China) Abstract:In this paper, a novel method based on word vector and graph models is proposed to deal with entity dis⁃ ambiguation in specific topic domains. Take the tourism topic domain as an example. The method firstly chooses the web - pages of the tourism category in a Wikipedia offline database to build a knowledge base; then, the tool Word2Vec is used to build a word vector model with the texts in the knowledge base and texts taken from several tourism websites. Combined with a manual annotation graph, a random walk algorithm based on the graph is used to compute similarity to accurately calculate the similarity between words within the tourism domain. Next, the method extracts several keywords from the background text of the entity to be disambiguated and compares them with the keyword text in the knowledge base that describes the candidate entities. Finally, the method uses the trained Word2Vec model and graphical model to calculate the similarity between the keywords of name mention and the keywords of candidate entities. The method then chooses the candidate entities which have the maximum average similarity to the target entity. Experimental results show that this new method can effectively capture the similarity between name mention and a target entity; thus, it can accurately achieve entity disambiguation of a topic-specific domain. Keywords:entity disambiguation; entity linking; Word2Vec; Wikipedia; graphical model; random walking 收稿日期:2016⁃03⁃19. 网络出版日期:2016⁃05⁃13. 基金项 目: 国 家 自 然 科 学 基 金 项 目 ( 61262041, 61472168, 61462054, 61562052);云南省自然科学基金重点项目(2013FA030). 通信作者:郭剑毅.E⁃mail:gjade86@ hotmail.com. 实体链接是知识库构建的关键技术之一,其目 的是将文本中已经获取到的命名实体链接到已有的

第3期 汪沛,等:一种结合词向量和图模型的特定领域实体消歧方法 ·367· 知识库中,实体消岐是实体链接的关键任务。由于 在上面的例子中,很明显第一句中的“香格里 海量数据中存在的实体指称通常可以对应到多个命 拉”指的是某旅游胜地,第二句指的是某著名酒店 名实体概念,这无疑对实体消歧造成了很大的障碍。 品牌,但是如何让计算机也能将实体指称项准确链 实体消歧的任务就是将这些存在歧义的实体指称在 接到知识库中具有特定概念的实体仍然是自然语言 众多的候选实体中匹配出对应的目标实体。目前实 处理领域研究的热点和难点。 体消歧任务分为两种类型:实体聚类消歧和实体链 传统的消歧模型难以有效利用能反映领域特有 接消歧山,实体聚类消歧就是利用聚类算法来对实 属性的实体词特征。因此,本文针对旅游领域实体 体进行消歧,而实体链接消歧则是借助外部知识库, 间的关系较为复杂的特征,提出了一种结合词向量 将待消歧命名实体指称链接到外部知识库中对应实 和图模型的消歧方法,通过提取实体指称项背景文 体来进行消歧。本文选择用后者来实现特定领域的 本的若干关键词和候选实体文本的若干关键词,利 实体消歧。 用训练好的模型对这些关键词分别进行交叉相似度 实体消歧的本质是计算实体指称项和候选实体 计算,把相似度均值最高的候选实体作为最终的目 的相似度,选择相似度最大的候选实体作为链接的 标实体。 目标实体2】。针对英文实体消岐,Bunescu和Pas- 1 ca[)提出了一种基于余弦相似度排序的方法来实现 相关理论 实体消歧。Bagga和Gideon4s]等将实体指称项的 1.1词向量 上下文与候选实体的上下文分别表示成BOW(Bag 在自然语言处理中,要将自然语言理解的问题 of words)向量形式,利用向量空间模型实现了人名 转化为机器学习的问题,就需将自然语言的符号数 的消歧。韩先培等)提出一种基于图的实体消歧 学化,其中最直观和常用的方法是One-hot表示法。 方法,将指称项与实体通过带权的无向图连接起来, 这种方法将每个词表示为一个很长的向量,其维数 从而将指称项与实体、实体与实体间的语义关联通 是词汇表大小,其中绝大多数元素为0,只有一个维 过图的形式表征出来。上述工作主要是对英文的实 度的值为1,这个维度就代表当前的词。 体消歧,相比较而言,针对中文的实体消歧工作远远 在自然语言处理中,常将One-hot表示采用稀 落后于英文。在中文的实体消歧领域,王建勇等] 疏的方式进行存储,即为每个词分配一个数字D。 利用一种基于图的GHOST算法,结合AP聚类算法 该方法因其简单易用,广泛应用于各种自然语言处 进行相似度计算,在人名消歧方面取得了较好的实 理任务中,如N-gram模型中就采用这种词向量表示 验结果。怀宝兴等)提出了一种基于概率主题模 法。但这种表述方法也存在一定问题:其表示的任 型的命名实体链接方法,在通用领域,通过构建歧义 意两个词之间是孤立的,无法表示这两个词之间的 词表,用LDA基于语义层面对文档建模和实体消 依赖关系,从词向量上看不出两个词是否相关:采用 岐:宁博等9]针对中文命名实体消歧问题提出了一 稀疏表示法,在处理某些任务,如构建N-gram模型 种基于异构知识库的层次聚类方法,将维基百科和 时,会引起维数灾难问题。 百度百科结合起来作为多源知识库,并利用Hadoop 而在机器学习领域,一般采用分布式表示(ds 平台进行层次聚类,从而实现实体消歧。另外,朱敏 tributed representation)的方法表示词向量,这种表 等[1]提出了一种实体聚类消歧与百度百科词频的 示法最早由Hinton!)提出,通常称为Word Repre-- 同类实体消歧相结合的消歧方法,通过构建同义词 sentation。这种方法将词用一种低维实数向量表示, 表、优化知识库、改进拼音距离编辑算法等方式实现 优点在于相似的词在距离上更接近,能体现出不同 对中文微博的实体消歧。 词之间的相关性,从而反映词之间的依赖关系。同 同样在旅游领域也存在着大量的实体同名现 时,较低的维度也使特征向量在应用时有一个可接 象,在维基百科中“金花”一词有11个同名实体, 受的复杂度。因此,新近提出的许多语言模型,如潜 “香格里拉”一词有12个同名实体,这无疑对消歧 在语义分析(latent semantic analysis,LSA)模型、潜 工作产生很大影响,例如,给定两个句子: 在狄利克雷分布(latent dirichlet allocation,LDA)模 1)2014年,香格里拉县共接待国内外游客 型以及目前流行的神经网络模型等,都采用这种方 1080.22万人次。 法表示词向量213) 2)在结束了一天的旅程后我们选择了在香格 本文利用旅游领域的丰富语料对词向量模型进 里拉酒店入住。 行训练,从而将抽取的关键词进行向量化表示,用这
知识库中,实体消岐是实体链接的关键任务。 由于 海量数据中存在的实体指称通常可以对应到多个命 名实体概念,这无疑对实体消歧造成了很大的障碍。 实体消歧的任务就是将这些存在歧义的实体指称在 众多的候选实体中匹配出对应的目标实体。 目前实 体消歧任务分为两种类型:实体聚类消歧和实体链 接消歧[1] ,实体聚类消歧就是利用聚类算法来对实 体进行消歧,而实体链接消歧则是借助外部知识库, 将待消歧命名实体指称链接到外部知识库中对应实 体来进行消歧。 本文选择用后者来实现特定领域的 实体消歧。 实体消歧的本质是计算实体指称项和候选实体 的相似度,选择相似度最大的候选实体作为链接的 目标实体[2] 。 针对英文实体消岐,Bunescu 和 Pas⁃ ca [3]提出了一种基于余弦相似度排序的方法来实现 实体消歧。 Bagga 和 Gideon [4⁃5] 等将实体指称项的 上下文与候选实体的上下文分别表示成 BOW(Bag of words)向量形式,利用向量空间模型实现了人名 的消歧。 韩先培等[6] 提出一种基于图的实体消歧 方法,将指称项与实体通过带权的无向图连接起来, 从而将指称项与实体、实体与实体间的语义关联通 过图的形式表征出来。 上述工作主要是对英文的实 体消歧,相比较而言,针对中文的实体消歧工作远远 落后于英文。 在中文的实体消歧领域,王建勇等[7] 利用一种基于图的 GHOST 算法,结合 AP 聚类算法 进行相似度计算,在人名消歧方面取得了较好的实 验结果。 怀宝兴等[8] 提出了一种基于概率主题模 型的命名实体链接方法,在通用领域,通过构建歧义 词表,用 LDA 基于语义层面对文档建模和实体消 岐;宁博等[9]针对中文命名实体消歧问题提出了一 种基于异构知识库的层次聚类方法,将维基百科和 百度百科结合起来作为多源知识库,并利用 Hadoop 平台进行层次聚类,从而实现实体消歧。 另外,朱敏 等[ 10 ]提出了一种实体聚类消歧与百度百科词频的 同类实体消歧相结合的消歧方法,通过构建同义词 表、优化知识库、改进拼音距离编辑算法等方式实现 对中文微博的实体消歧。 同样在旅游领域也存在着大量的实体同名现 象,在维基百科中“金花” 一词有 11 个同名实体, “香格里拉”一词有 12 个同名实体,这无疑对消歧 工作产生很大影响,例如,给定两个句子: 1) 2014 年, 香 格 里 拉 县 共 接 待 国 内 外 游 客 1 080.22万人次。 2)在结束了一天的旅程后我们选择了在香格 里拉酒店入住。 在上面的例子中,很明显第一句中的“香格里 拉”指的是某旅游胜地,第二句指的是某著名酒店 品牌,但是如何让计算机也能将实体指称项准确链 接到知识库中具有特定概念的实体仍然是自然语言 处理领域研究的热点和难点。 传统的消歧模型难以有效利用能反映领域特有 属性的实体词特征。 因此,本文针对旅游领域实体 间的关系较为复杂的特征,提出了一种结合词向量 和图模型的消歧方法,通过提取实体指称项背景文 本的若干关键词和候选实体文本的若干关键词,利 用训练好的模型对这些关键词分别进行交叉相似度 计算,把相似度均值最高的候选实体作为最终的目 标实体。 1 相关理论 1.1 词向量 在自然语言处理中,要将自然语言理解的问题 转化为机器学习的问题,就需将自然语言的符号数 学化,其中最直观和常用的方法是 One⁃hot 表示法。 这种方法将每个词表示为一个很长的向量,其维数 是词汇表大小,其中绝大多数元素为 0,只有一个维 度的值为 1,这个维度就代表当前的词。 在自然语言处理中,常将 One⁃hot 表示采用稀 疏的方式进行存储,即为每个词分配一个数字 ID。 该方法因其简单易用,广泛应用于各种自然语言处 理任务中,如 N⁃gram 模型中就采用这种词向量表示 法。 但这种表述方法也存在一定问题:其表示的任 意两个词之间是孤立的,无法表示这两个词之间的 依赖关系,从词向量上看不出两个词是否相关;采用 稀疏表示法,在处理某些任务,如构建 N⁃gram 模型 时,会引起维数灾难问题。 而在机器学习领域,一般采用分布式表示( dis⁃ tributed representation) 的方法表示词向量,这种表 示法最早由 Hinton [11] 提出,通常称为 Word Repre⁃ sentation。 这种方法将词用一种低维实数向量表示, 优点在于相似的词在距离上更接近,能体现出不同 词之间的相关性,从而反映词之间的依赖关系。 同 时,较低的维度也使特征向量在应用时有一个可接 受的复杂度。 因此,新近提出的许多语言模型,如潜 在语义分析(latent semantic analysis, LSA)模型、潜 在狄利克雷分布 ( latent dirichlet allocation,LDA)模 型以及目前流行的神经网络模型等,都采用这种方 法表示词向量[12⁃13] 。 本文利用旅游领域的丰富语料对词向量模型进 行训练,从而将抽取的关键词进行向量化表示,用这 第 3 期 汪沛,等:一种结合词向量和图模型的特定领域实体消歧方法 ·367·

·368 智能系统学报 第11卷 若干个关键词向量来表征一篇文档,通过计算关键 则的变动形式,如同一个人酒后乱步,所形成的随机 词向量间的余弦相似度得出它们之间的关联程度, 过程记录6。它的基本思想是,从一个或一系列顶 进而得出文档之间的相似度。 点开始遍历一张图,在任意一个顶点,遍历者将以概 l.2 TextRank算法 率1-α游走到这个顶点的邻居顶点,以概率α随机 同一文档中的大多数词语都是为表达同一主题 跳跃到图中的任何一个顶点,称α跳转发生概率, 服务的,它们之间具有一定的语义关系。和词语W 每次游走后得出一个概率分布,该概率分布刻画了 有语义关系的词语越多,词语W越可能是表达文档 图中每一个顶点被访问到的概率,用这个概率分布 主题的重要词语,同时和词语W有语义关系的词语 作为下一次游走的输人并反复迭代这一过程,当满 的重要性也会影响词语W的重要性。根据这两个 足一定前提条件时,这个概率分布会趋于收敛,收敛 特性,本节引入基于图的排序算法用于抽取多文档 后,即可以得到一个稳定的概率分布。近年来,随机 关键词。基于图的排序算法是决定图中点重要性的 游走算法逐渐开始吸引机器学习研究者的目光,并 一种方法,它根据全局信息(图的结构)而不是局部 开始被应用于半监督学习.1】、聚类分析192】、图 信息来对节点排序。其基本理论是“投票”,当图中 像分割[]和图的匹配[]等问题上。与随机游走相 一个点A和另一个点B之间有连线时,那么点A就 关的扩散核也被应用于242)基于核的学习等方面。 给点B投票,点B获得的投票越多,点B就越重要; 由于实体间的关系错综复杂,可以将这种关系 更进一步,投票点A的重要性决定了其投票的重要 抽象为一种图模型,本文在这种图模型上运用随机 性,因此,点B的分数由其获得的投票和给B投票的 游走算法可以将实体间的关联程度准确地表征 点的分数共同决定。 出来。 Mihalcea14]将在自然语言处理领域中应用的 2领域实体消歧 基于图的排序算法称为TextRank,一般TextRank模 型可以表示为一个加权的有向图。TextRank的思想 2.1系统流程 来源于Google的PageRank算法,通过把文本分割 本文提出的方法由4个模块构成分别为关键词 成若干组成单元并建立图模型,利用投票机制对文 提取模块、词向量模块、图模型模块和空实体判断 本中的重要成分进行排序,仅利用单篇文档本身的 模块。 信息即可实现关键词抽取。本文采用该算法将文档 在关键词提取模块中,分别利用TextRank算法 表示为无向图G(V,E),由点集合V和边集合E组 提取出待消歧的实体指称所在的背景文本的若干关 成,E是V×V的子集,图中两点i,j之间边的权重为 键词和候选实体对应的知识库描述文本的若干关键 W。对于一个给定的点V:,n(V)为指向该点的点 词,这里提取的两组关键词用于后面的相似度计算。 集合,Out(V:)为点V指向的点集合,点V,的分数 在词向量模块中,抽取维基百科离线数据中旅 定义为式(2): 游分类下的页面信息构建领域知识库,由于维基百 Ws(V)=(1-d)+d×∑ 10 科中包含大量的结构化信息,取该知识库的摘要信 —WS(V) a(∑ 0声 息作为语料对词向量模型进行训练,这时,领域实体 VeOu(V) 都能通过该模型表征为一个向量,从而实现关键词 (2) 之间的相似度计算。 式中:d为阻尼因数,取值范围为0~1,代表从图中 在图模型模块中,人工构建一个领域实体关系 某一特定点指向其他任意点的概率。通过这种算法 图谱,通过在该图谱上的随机游走算法实现关键词 我们可以获得每个词语在文档中的分数,从而可以 之间相似度的计算。 根据分数大小来进行关键词的排序。 在空实体判断模块中,从待消歧实体指称所在 本文利用该算法抽取文档中的关键词,分别用 的文本中抽取若干关键词和从候选实体所在文本中 抽取的关键词来表征待消歧实体指称项所在文本和 抽取的关键词分别用本文提出的图模型与词向量方 目标实体所在文本。 法相结合进行交叉相似度计算取平均值,选择其中 1.3随机游走算法 最大的相似度平均值,因为计算结果所对应的目标 随机游走模型是在1905年Karl Pearsonti]首 实体未必在我们的知识库中存在,这时通过比对该 次提出的一种数学统计模型,它是一连串的轨迹组 平均值与通过大量实验确定的空实体阈值入的大 成的,其中每一次都是随机的。它能用来表示不规 小,如果大于该阈值入,则该实体为目标实体,如果
若干个关键词向量来表征一篇文档,通过计算关键 词向量间的余弦相似度得出它们之间的关联程度, 进而得出文档之间的相似度。 1.2 TextRank 算法 同一文档中的大多数词语都是为表达同一主题 服务的,它们之间具有一定的语义关系。 和词语 W 有语义关系的词语越多,词语 W 越可能是表达文档 主题的重要词语,同时和词语 W 有语义关系的词语 的重要性也会影响词语 W 的重要性。 根据这两个 特性,本节引入基于图的排序算法用于抽取多文档 关键词。 基于图的排序算法是决定图中点重要性的 一种方法,它根据全局信息(图的结构) 而不是局部 信息来对节点排序。 其基本理论是“投票”,当图中 一个点 A 和另一个点 B 之间有连线时,那么点 A 就 给点 B 投票,点 B 获得的投票越多,点 B 就越重要; 更进一步,投票点 A 的重要性决定了其投票的重要 性,因此,点 B 的分数由其获得的投票和给 B 投票的 点的分数共同决定。 Mihalcea [1 4 ]将在自然语言处理领域中应用的 基于图的排序算法称为 TextRank,一般 TextRank 模 型可以表示为一个加权的有向图。 TextRank 的思想 来源于 Google 的 PageRank 算法,通过把文本分割 成若干组成单元并建立图模型,利用投票机制对文 本中的重要成分进行排序,仅利用单篇文档本身的 信息即可实现关键词抽取。 本文采用该算法将文档 表示为无向图 G(V,E),由点集合 V 和边集合 E 组 成,E 是 V×V 的子集,图中两点 i,j 之间边的权重为 Wj。 对于一个给定的点 Vi,In(Vi)为指向该点的点 集合,Out(Vi ) 为点 Vi 指向的点集合,点 Vi 的分数 定义为式(2): WS(Vi) = (1 - d) + d × V ∑ j∈In(Vi ) wji V ∑k∈Out(Vi ) wjk WS(Vj) (2) 式中:d 为阻尼因数,取值范围为 0 ~ 1,代表从图中 某一特定点指向其他任意点的概率。 通过这种算法 我们可以获得每个词语在文档中的分数,从而可以 根据分数大小来进行关键词的排序。 本文利用该算法抽取文档中的关键词,分别用 抽取的关键词来表征待消歧实体指称项所在文本和 目标实体所在文本。 1.3 随机游走算法 随机游走模型是在 1905 年 Karl Pearson [15] 首 次提出的一种数学统计模型,它是一连串的轨迹组 成的,其中每一次都是随机的。 它能用来表示不规 则的变动形式,如同一个人酒后乱步,所形成的随机 过程记录[16] 。 它的基本思想是,从一个或一系列顶 点开始遍历一张图,在任意一个顶点,遍历者将以概 率 1-α 游走到这个顶点的邻居顶点,以概率 α 随机 跳跃到图中的任何一个顶点,称 α 跳转发生概率, 每次游走后得出一个概率分布,该概率分布刻画了 图中每一个顶点被访问到的概率,用这个概率分布 作为下一次游走的输入并反复迭代这一过程,当满 足一定前提条件时,这个概率分布会趋于收敛,收敛 后,即可以得到一个稳定的概率分布。 近年来,随机 游走算法逐渐开始吸引机器学习研究者的目光,并 开始被应用于半监督学习[17⁃18] 、聚类分析[19⁃21] 、图 像分割[22]和图的匹配[23] 等问题上。 与随机游走相 关的扩散核也被应用于[24⁃28]基于核的学习等方面。 由于实体间的关系错综复杂,可以将这种关系 抽象为一种图模型,本文在这种图模型上运用随机 游走算法可以将实体间的关联程度准确地表征 出来。 2 领域实体消歧 2.1 系统流程 本文提出的方法由 4 个模块构成分别为关键词 提取模块、词向量模块、图模型模块和空实体判断 模块。 在关键词提取模块中,分别利用 TextRank 算法 提取出待消歧的实体指称所在的背景文本的若干关 键词和候选实体对应的知识库描述文本的若干关键 词,这里提取的两组关键词用于后面的相似度计算。 在词向量模块中,抽取维基百科离线数据中旅 游分类下的页面信息构建领域知识库,由于维基百 科中包含大量的结构化信息,取该知识库的摘要信 息作为语料对词向量模型进行训练,这时,领域实体 都能通过该模型表征为一个向量,从而实现关键词 之间的相似度计算。 在图模型模块中,人工构建一个领域实体关系 图谱,通过在该图谱上的随机游走算法实现关键词 之间相似度的计算。 在空实体判断模块中,从待消歧实体指称所在 的文本中抽取若干关键词和从候选实体所在文本中 抽取的关键词分别用本文提出的图模型与词向量方 法相结合进行交叉相似度计算取平均值,选择其中 最大的相似度平均值,因为计算结果所对应的目标 实体未必在我们的知识库中存在,这时通过比对该 平均值与通过大量实验确定的空实体阈值 λ 的大 小,如果大于该阈值 λ,则该实体为目标实体,如果 ·368· 智 能 系 统 学 报 第 11 卷
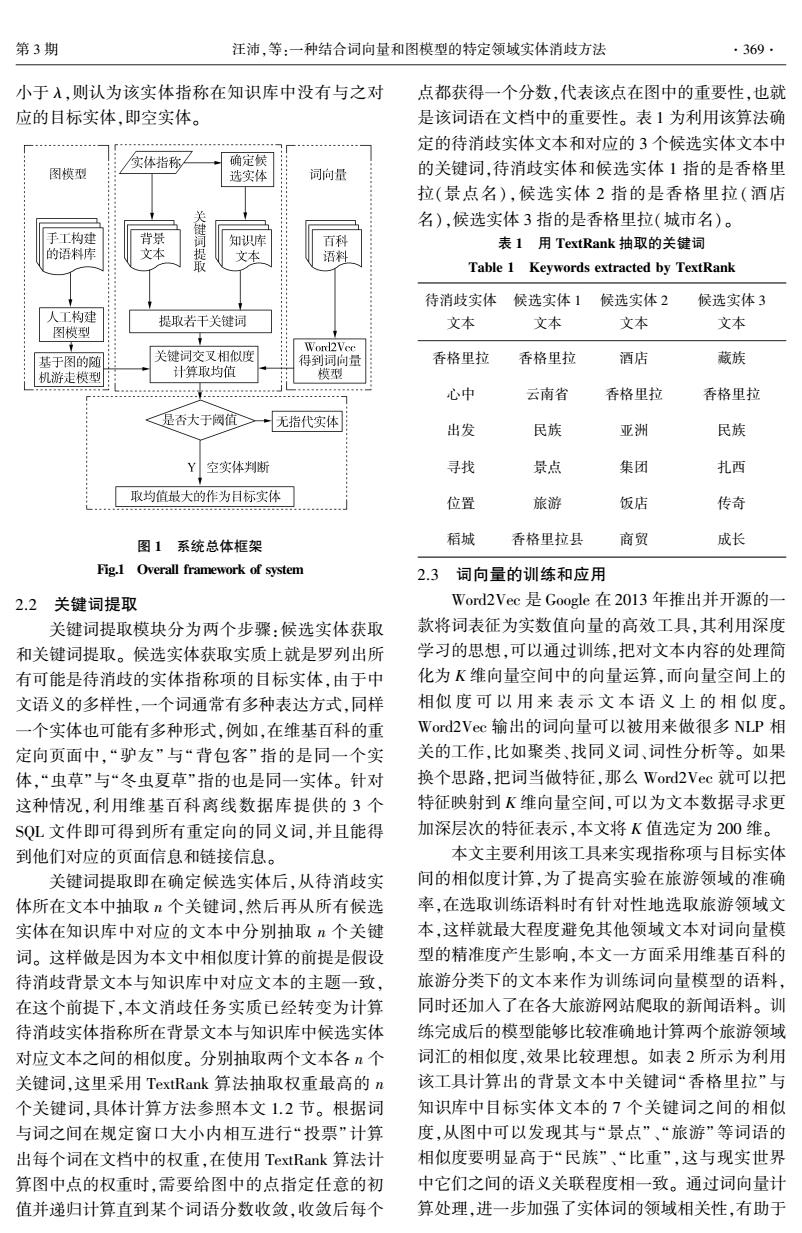
第3期 汪沛,等:一种结合词向量和图模型的特定领域实体消歧方法 ·369- 小于入,则认为该实体指称在知识库中没有与之对 点都获得一个分数,代表该点在图中的重要性,也就 应的目标实体,即空实体。 是该词语在文档中的重要性。表1为利用该算法确 定的待消歧实体文本和对应的3个候选实体文本中 /实体指称 确定候 图模型 选实体 词向量 的关键词,待消歧实体和候选实体1指的是香格里 拉(景点名),候选实体2指的是香格里拉(酒店 毽 名),候选实体3指的是香格里拉(城市名)。 手工构建 背景 知识库 百科 表I用TextRank抽取的关键词 的语料库 文本 最 文本 语料 Table 1 Keywords extracted by TextRank 待消歧实体 候选实体1 候选实体2 候选实体3 人工构建 提取若干关键词 文本 文本 文本 文本 图模型 基于图的随 关键词交叉相似度 Word2Vee 得到词问量 香格里拉 香格里拉 酒店 藏族 机游走模型 计算取均值 模型 心中 云南省 香格里拉 香格里拉 <是否大于岗值 无指代实体 出发 民族 亚洲 民族 Y空实体判断 寻找 景点 集团 扎西 取均值最大的作为目标实体 位置 旅游 饭店 传奇 图1系统总体框架 稻城 香格里拉县 商贸 成长 Fig.1 Overall framework of system 2.3词向量的训练和应用 2.2关键词提取 Word2Vec是Google在2013年推出并开源的一 关键词提取模块分为两个步骤:候选实体获取 款将词表征为实数值向量的高效工具,其利用深度 和关键词提取。候选实体获取实质上就是罗列出所 学习的思想,可以通过训练把对文本内容的处理简 有可能是待消歧的实体指称项的目标实体,由于中 化为K维向量空间中的向量运算,而向量空间上的 文语义的多样性,一个词通常有多种表达方式,同样 相似度可以用来表示文本语义上的相似度。 一个实体也可能有多种形式,例如,在维基百科的重 Word2Vec输出的词向量可以被用来做很多NLP相 定向页面中,“驴友”与“背包客”指的是同一个实 关的工作,比如聚类、找同义词、词性分析等。如果 体,“虫草”与“冬虫夏草”指的也是同一实体。针对 换个思路,把词当做特征,那么Word2Vec就可以把 这种情况,利用维基百科离线数据库提供的3个 特征映射到K维向量空间,可以为文本数据寻求更 SQL文件即可得到所有重定向的同义词,并且能得 加深层次的特征表示,本文将K值选定为200维。 到他们对应的页面信息和链接信息。 本文主要利用该工具来实现指称项与目标实体 关键词提取即在确定候选实体后,从待消歧实 间的相似度计算,为了提高实验在旅游领域的准确 体所在文本中抽取n个关键词,然后再从所有候选 率,在选取训练语料时有针对性地选取旅游领域文 实体在知识库中对应的文本中分别抽取n个关键 本,这样就最大程度避免其他领域文本对词向量模 词。这样做是因为本文中相似度计算的前提是假设 型的精准度产生影响,本文一方面采用维基百科的 待消歧背景文本与知识库中对应文本的主题一致, 旅游分类下的文本来作为训练词向量模型的语料, 在这个前提下,本文消歧任务实质已经转变为计算 同时还加入了在各大旅游网站爬取的新闻语料。训 待消歧实体指称所在背景文本与知识库中候选实体 练完成后的模型能够比较准确地计算两个旅游领域 对应文本之间的相似度。分别抽取两个文本各个 词汇的相似度,效果比较理想。如表2所示为利用 关键词,这里采用TextRank算法抽取权重最高的n 该工具计算出的背景文本中关键词“香格里拉”与 个关键词,具体计算方法参照本文1.2节。根据词 知识库中目标实体文本的7个关键词之间的相似 与词之间在规定窗口大小内相互进行“投票”计算 度,从图中可以发现其与“景点”、“旅游”等词语的 出每个词在文档中的权重,在使用TextRank算法计 相似度要明显高于“民族”、“比重”,这与现实世界 算图中点的权重时,需要给图中的点指定任意的初 中它们之间的语义关联程度相一致。通过词向量计 值并递归计算直到某个词语分数收敛,收敛后每个 算处理,进一步加强了实体词的领域相关性,有助于
小于 λ,则认为该实体指称在知识库中没有与之对 应的目标实体,即空实体。 图 1 系统总体框架 Fig.1 Overall framework of system 2.2 关键词提取 关键词提取模块分为两个步骤:候选实体获取 和关键词提取。 候选实体获取实质上就是罗列出所 有可能是待消歧的实体指称项的目标实体,由于中 文语义的多样性,一个词通常有多种表达方式,同样 一个实体也可能有多种形式,例如,在维基百科的重 定向页面中,“驴友” 与“背包客” 指的是同一个实 体,“虫草”与“冬虫夏草”指的也是同一实体。 针对 这种情况,利用维基百科离线数据库提供的 3 个 SQL 文件即可得到所有重定向的同义词,并且能得 到他们对应的页面信息和链接信息。 关键词提取即在确定候选实体后,从待消歧实 体所在文本中抽取 n 个关键词,然后再从所有候选 实体在知识库中对应的文本中分别抽取 n 个关键 词。 这样做是因为本文中相似度计算的前提是假设 待消歧背景文本与知识库中对应文本的主题一致, 在这个前提下,本文消歧任务实质已经转变为计算 待消歧实体指称所在背景文本与知识库中候选实体 对应文本之间的相似度。 分别抽取两个文本各 n 个 关键词,这里采用 TextRank 算法抽取权重最高的 n 个关键词,具体计算方法参照本文 1.2 节。 根据词 与词之间在规定窗口大小内相互进行“投票” 计算 出每个词在文档中的权重,在使用 TextRank 算法计 算图中点的权重时,需要给图中的点指定任意的初 值并递归计算直到某个词语分数收敛,收敛后每个 点都获得一个分数,代表该点在图中的重要性,也就 是该词语在文档中的重要性。 表 1 为利用该算法确 定的待消歧实体文本和对应的 3 个候选实体文本中 的关键词,待消歧实体和候选实体 1 指的是香格里 拉(景点名),候选实体 2 指的是香格里拉( 酒店 名),候选实体 3 指的是香格里拉(城市名)。 表 1 用 TextRank 抽取的关键词 Table 1 Keywords extracted by TextRank 待消歧实体 文本 候选实体 1 文本 候选实体 2 文本 候选实体 3 文本 香格里拉 香格里拉 酒店 藏族 心中 云南省 香格里拉 香格里拉 出发 民族 亚洲 民族 寻找 景点 集团 扎西 位置 旅游 饭店 传奇 稻城 香格里拉县 商贸 成长 2.3 词向量的训练和应用 Word2Vec 是 Google 在 2013 年推出并开源的一 款将词表征为实数值向量的高效工具,其利用深度 学习的思想,可以通过训练,把对文本内容的处理简 化为 K 维向量空间中的向量运算,而向量空间上的 相似 度 可 以 用 来 表 示 文 本 语 义 上 的 相 似 度。 Word2Vec 输出的词向量可以被用来做很多 NLP 相 关的工作,比如聚类、找同义词、词性分析等。 如果 换个思路,把词当做特征,那么 Word2Vec 就可以把 特征映射到 K 维向量空间,可以为文本数据寻求更 加深层次的特征表示,本文将 K 值选定为 200 维。 本文主要利用该工具来实现指称项与目标实体 间的相似度计算,为了提高实验在旅游领域的准确 率,在选取训练语料时有针对性地选取旅游领域文 本,这样就最大程度避免其他领域文本对词向量模 型的精准度产生影响,本文一方面采用维基百科的 旅游分类下的文本来作为训练词向量模型的语料, 同时还加入了在各大旅游网站爬取的新闻语料。 训 练完成后的模型能够比较准确地计算两个旅游领域 词汇的相似度,效果比较理想。 如表 2 所示为利用 该工具计算出的背景文本中关键词“香格里拉” 与 知识库中目标实体文本的 7 个关键词之间的相似 度,从图中可以发现其与“景点”、“旅游”等词语的 相似度要明显高于“民族”、“比重”,这与现实世界 中它们之间的语义关联程度相一致。 通过词向量计 算处理,进一步加强了实体词的领域相关性,有助于 第 3 期 汪沛,等:一种结合词向量和图模型的特定领域实体消歧方法 ·369·
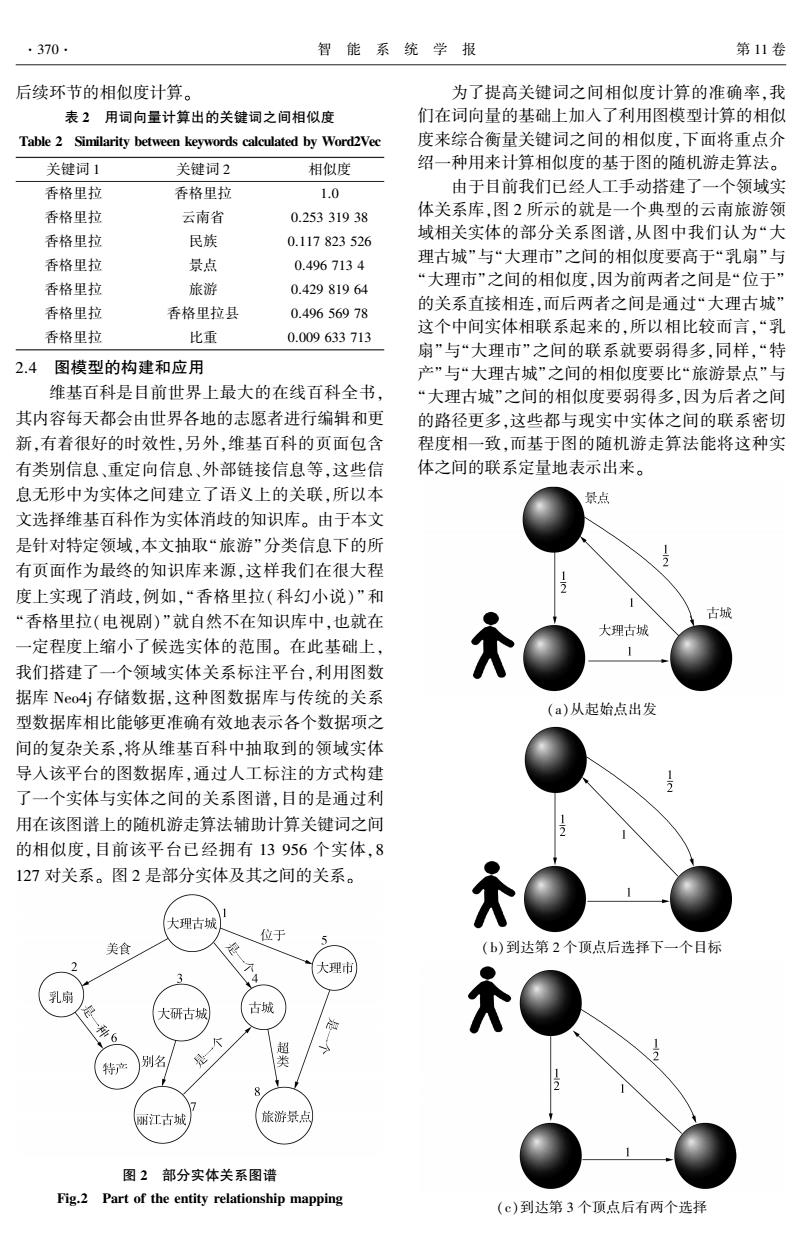
.370 智能系统学报 第11卷 后续环节的相似度计算。 为了提高关键词之间相似度计算的准确率,我 表2用词向量计算出的关键词之间相似度 们在词向量的基础上加入了利用图模型计算的相似 Table 2 Similarity between keywords calculated by Word2Vec 度来综合衡量关键词之间的相似度,下面将重点介 关键词1 关键词2 相似度 绍一种用来计算相似度的基于图的随机游走算法。 香格里拉 香格里拉 1.0 由于目前我们已经人工手动搭建了一个领域实 香格里拉 云南省 0.25331938 体关系库,图2所示的就是一个典型的云南旅游领 香格里拉 民族 0.117823526 域相关实体的部分关系图谱,从图中我们认为“大 香格里拉 景点 0.4967134 理古城”与“大理市”之间的相似度要高于“乳扇”与 香格里拉 旅游 0.42981964 “大理市”之间的相似度,因为前两者之间是“位于” 香格里拉 香格里拉县 的关系直接相连,而后两者之间是通过“大理古城” 0.49656978 香格里拉 比重 这个中间实体相联系起来的,所以相比较而言,“乳 0.009633713 扇”与“大理市”之间的联系就要弱得多,同样,“特 2.4图模型的构建和应用 产”与“大理古城”之间的相似度要比“旅游景点”与 维基百科是目前世界上最大的在线百科全书, “大理古城”之间的相似度要弱得多,因为后者之间 其内容每天都会由世界各地的志愿者进行编辑和更 的路径更多,这些都与现实中实体之间的联系密切 新,有着很好的时效性,另外,维基百科的页面包含 程度相一致,而基于图的随机游走算法能将这种实 有类别信息、重定向信息、外部链接信息等,这些信 体之间的联系定量地表示出来。 息无形中为实体之间建立了语义上的关联,所以本 景点 文选择维基百科作为实体消歧的知识库。由于本文 是针对特定领域,本文抽取“旅游”分类信息下的所 有页面作为最终的知识库来源,这样我们在很大程 度上实现了消歧,例如,“香格里拉(科幻小说)”和 “香格里拉(电视剧)”就自然不在知识库中,也就在 古城 大理古城 一定程度上缩小了候选实体的范围。在此基础上, 1 我们搭建了一个领域实体关系标注平台,利用图数 据库No4j存储数据,这种图数据库与传统的关系 (a)从起始点出发 型数据库相比能够更准确有效地表示各个数据项之 间的复杂关系,将从维基百科中抽取到的领域实体 导入该平台的图数据库,通过人工标注的方式构建 了一个实体与实体之间的关系图谱,目的是通过利 用在该图谱上的随机游走算法辅助计算关键词之间 的相似度,目前该平台已经拥有13956个实体,8 127对关系。图2是部分实体及其之间的关系。 大理古城 位于 美食 (b)到达第2个顶点后选择下一个目标 2 个 大理市 乳扇 大研古城 古城 特产 别名 是 类 丽江古城 旅游景点 图2部分实体关系图谱 Fig.2 Part of the entity relationship mapping (c)到达第3个顶点后有两个选择
后续环节的相似度计算。 表 2 用词向量计算出的关键词之间相似度 Table 2 Similarity between keywords calculated by Word2Vec 关键词 1 关键词 2 相似度 香格里拉 香格里拉 1.0 香格里拉 云南省 0.253 319 38 香格里拉 民族 0.117 823 526 香格里拉 景点 0.496 713 4 香格里拉 旅游 0.429 819 64 香格里拉 香格里拉县 0.496 569 78 香格里拉 比重 0.009 633 713 2.4 图模型的构建和应用 维基百科是目前世界上最大的在线百科全书, 其内容每天都会由世界各地的志愿者进行编辑和更 新,有着很好的时效性,另外,维基百科的页面包含 有类别信息、重定向信息、外部链接信息等,这些信 息无形中为实体之间建立了语义上的关联,所以本 文选择维基百科作为实体消歧的知识库。 由于本文 是针对特定领域,本文抽取“旅游”分类信息下的所 有页面作为最终的知识库来源,这样我们在很大程 度上实现了消歧,例如,“香格里拉(科幻小说)”和 “香格里拉(电视剧)”就自然不在知识库中,也就在 一定程度上缩小了候选实体的范围。 在此基础上, 我们搭建了一个领域实体关系标注平台,利用图数 据库 Neo4j 存储数据,这种图数据库与传统的关系 型数据库相比能够更准确有效地表示各个数据项之 间的复杂关系,将从维基百科中抽取到的领域实体 导入该平台的图数据库,通过人工标注的方式构建 了一个实体与实体之间的关系图谱,目的是通过利 用在该图谱上的随机游走算法辅助计算关键词之间 的相似度,目前该平台已经拥有 13 956 个实体,8 127 对关系。 图 2 是部分实体及其之间的关系。 图 2 部分实体关系图谱 Fig.2 Part of the entity relationship mapping 为了提高关键词之间相似度计算的准确率,我 们在词向量的基础上加入了利用图模型计算的相似 度来综合衡量关键词之间的相似度,下面将重点介 绍一种用来计算相似度的基于图的随机游走算法。 由于目前我们已经人工手动搭建了一个领域实 体关系库,图 2 所示的就是一个典型的云南旅游领 域相关实体的部分关系图谱,从图中我们认为“大 理古城”与“大理市”之间的相似度要高于“乳扇”与 “大理市”之间的相似度,因为前两者之间是“位于” 的关系直接相连,而后两者之间是通过“大理古城” 这个中间实体相联系起来的,所以相比较而言,“乳 扇”与“大理市”之间的联系就要弱得多,同样,“特 产”与“大理古城”之间的相似度要比“旅游景点”与 “大理古城”之间的相似度要弱得多,因为后者之间 的路径更多,这些都与现实中实体之间的联系密切 程度相一致,而基于图的随机游走算法能将这种实 体之间的联系定量地表示出来。 (a)从起始点出发 (b)到达第 2 个顶点后选择下一个目标 (c)到达第 3 个顶点后有两个选择 ·370· 智 能 系 统 学 报 第 11 卷