
第10卷第4期 智能系统学报 Vol.10 No.4 2015年8月 CAAI Transactions on Intelligent Systems Aug.2015 D0:10.3969/j.issn.1673-4785.201505009 网络出版地址:http://www.cnki.net/kcms/detail/23.1538.TP.20150630.1544.002.html 基于模糊关联规则和决策树的图像自动标注 李志欣12,李灵芝,张灿龙2 (1.广西师范大学广西多源信息挖据与安全重点实验室,广西桂林541004:2.广西信息科学实验中心,广西桂林541004) 摘要:传统的基于关联规则算法的图像自动标注存在“锐利边界”问题,使分类存在模糊性、不准确性。且随着多 媒体技术的飞速发展,图像信息数据迅速增长,海量的图像数据会形成大量冗余的关联规则,这将导致分类效率大 大降低。针对这2个问题,文中提出基于模糊关联规则和决策树的图像自动标注模型。该模型首先获得关联训练图 像低层特征和高层语义的模糊关联规则,再利用决策树方法删减冗余的模糊关联规则,基于决策树删减后的模糊关 联规则,大大减小了算法的计算复杂度。实验在Corl5k和IAPR-TC12两个基谁数据集上进行,并从精度、召回率、 F-measure以及产生的规则数量几个度量措施上进行比较。与其他几种前沿的图像自动标注方法的结果对比表明, 该方法在图像的标注精度和标注效率上有很大的提高。 关键词:锐利边界:模糊分类:图像自动标注:模糊关联规则:决策树 中图分类号:TP391文献标志码:A文章编号:1673-4785(2015)04-0636-08 中文引用格式:李志欣,李灵芝,张灿龙.基于模糊关联规则和决策树的图像自动标注[J】.智能系统学报,2015,10(4):636-644. 英文引用格式:LI Zhixin,LI Lingzhi,ZHANG Canlong.Automatic image annotation based on fuzzy association rules and decision trees[J].CAAI Transactions on Intelligent Systems,2015,10(4):636-644. Automatic image annotation based on fuzzy association rules and decision trees LI Zhixin'2,LI Lingzhi',ZHANG Canlong' (1.Guangxi Key Lab of Multi-source Information Mining Security,Guangxi Normal University,Guilin 541004,China;2.Guangxi Experiment Center of Information Science,Guilin 541004,China) Abstract:The traditional automatic image annotation based on association rules exists the problem of sharp boundary, which makes classification more fuzzy and inaccurate.Moreover,with the rapid development of multimedia technology, the size of image data increases quickly.Massive image data will produce a lot of redundant association rules,which greatly decreases the efficiency of image classification.In order to solve these two problems,this paper proposes an auto- matic image annotation approach based on fuzzy association rules and decision trees.The approach firstly obtains fuzzy association rules which represent the fuzzy correlations between low-level visual features and high-level semantic concepts of training images.Then,decision tree is adopted to reduce the redundant fuzzy association rules.As a result,computa- tional complexity of the algorithm is decreased to a large degree.Experiments were done on Corel5k and IAPR-TC12 datasets.The evaluation measures are compared from the aspects of precision,recall,F-measure and the number of rules.The experimental results show that the proposed method acquires higher accuracy and efficiency in comparison with several state-of-the-art automatic image annotation approaches. Keywords:sharp boundary;fuzzy classification;automatic image annotation;fuzzy association rules;decision tree 收稿日期:2015-05-06.网络出版日期:2015-06-30. 随着多媒体技术的飞速发展,图像信息数据迅 基金项目:国家自然科学基金资助项目(61165009,61262005.61363035. 61365009):国家973计划资助项目(2012CB326403):广西自然科 速增长,传统的人工图像标注2)已不能满足海量 学基金资助项目(2012 CXNSFAA053219,2013 GXNSFAA019345, 的图像数据库标注要求,如何实现有效标注和快速 2014 CXNSFAA118368). 通信作者:李志欣.E-mail:liax@gu.cdu.cm 存取,已经成为多媒体领域一项重大研究课题。基
第 10 卷第 4 期 智 能 系 统 学 报 Vol.10 №.4 2015 年 8 月 CAAI Transactions on Intelligent Systems Aug. 2015 DOI:10.3969 / j.issn.1673⁃4785.201505009 网络出版地址:http: / / www.cnki.net / kcms/ detail / 23.1538.TP.20150630.1544.002.html 基于模糊关联规则和决策树的图像自动标注 李志欣1,2 ,李灵芝1 ,张灿龙1,2 (1.广西师范大学 广西多源信息挖掘与安全重点实验室, 广西 桂林 541004; 2.广西信息科学实验中心, 广西 桂林 541004) 摘 要:传统的基于关联规则算法的图像自动标注存在“锐利边界”问题,使分类存在模糊性、不准确性。 且随着多 媒体技术的飞速发展,图像信息数据迅速增长,海量的图像数据会形成大量冗余的关联规则,这将导致分类效率大 大降低。 针对这 2 个问题,文中提出基于模糊关联规则和决策树的图像自动标注模型。 该模型首先获得关联训练图 像低层特征和高层语义的模糊关联规则,再利用决策树方法删减冗余的模糊关联规则,基于决策树删减后的模糊关 联规则,大大减小了算法的计算复杂度。 实验在 Corel 5k 和 IAPR⁃TC12 两个基准数据集上进行,并从精度、召回率、 F⁃measure 以及产生的规则数量几个度量措施上进行比较。 与其他几种前沿的图像自动标注方法的结果对比表明, 该方法在图像的标注精度和标注效率上有很大的提高。 关键词:锐利边界;模糊分类;图像自动标注;模糊关联规则;决策树 中图分类号: TP391 文献标志码:A 文章编号:1673⁃4785(2015)04⁃0636⁃08 中文引用格式:李志欣,李灵芝,张灿龙. 基于模糊关联规则和决策树的图像自动标注[J]. 智能系统学报, 2015, 10(4): 636⁃644. 英文引用格式:LI Zhixin,LI Lingzhi,ZHANG Canlong. Automatic image annotation based on fuzzy association rules and decision trees[J]. CAAI Transactions on Intelligent Systems, 2015, 10(4): 636⁃644. Automatic image annotation based on fuzzy association rules and decision trees LI Zhixin 1,2 ,LI Lingzhi 1 ,ZHANG Canlong 1,2 (1.Guangxi Key Lab of Multi⁃source Information Mining & Security, Guangxi Normal University, Guilin 541004, China; 2. Guangxi Experiment Center of Information Science, Guilin 541004, China) Abstract:The traditional automatic image annotation based on association rules exists the problem of sharp boundary, which makes classification more fuzzy and inaccurate. Moreover, with the rapid development of multimedia technology, the size of image data increases quickly. Massive image data will produce a lot of redundant association rules, which greatly decreases the efficiency of image classification. In order to solve these two problems, this paper proposes an auto⁃ matic image annotation approach based on fuzzy association rules and decision trees. The approach firstly obtains fuzzy association rules which represent the fuzzy correlations between low⁃level visual features and high⁃level semantic concepts of training images . Then, decision tree is adopted to reduce the redundant fuzzy association rules. As a result, computa⁃ tional complexity of the algorithm is decreased to a large degree. Experiments were done on Corel5k and IAPR⁃TC12 datasets. The evaluation measures are compared from the aspects of precision, recall, F⁃measure and the number of rules. The experimental results show that the proposed method acquires higher accuracy and efficiency in comparison with several state⁃of⁃the⁃art automatic image annotation approaches. Keywords:sharp boundary; fuzzy classification; automatic image annotation; fuzzy association rules; decision tree 收稿日期:2015⁃05⁃06. 网络出版日期:2015⁃06⁃30. 基金项目:国家自然科学基金资助项目(61165009, 61262005, 61363035, 61365009);国家 973 计划资助项目(2012CB326403);广西自然科 学基金资助项目(2012GXNSFAA053219, 2013GXNSFAA019345, 2014GXNSFAA118368). 通信作者:李志欣. E⁃mail:lizx@ gxnu.edu.cn. 随着多媒体技术的飞速发展,图像信息数据迅 速增长,传统的人工图像标注[1⁃2] 已不能满足海量 的图像数据库标注要求,如何实现有效标注和快速 存取,已经成为多媒体领域一项重大研究课题。 基

第4期 李志欣,等:基于模糊关联规则和决策树的图像自动标注 ·637. 于内容的图像检素(content based image retrieval, 但是,在以上标注模型中都没有考虑到图像处 CBR),用低维的视觉特征如颜色、形状、纹理以及 理中存在的模糊和不确定性的属性(锐利边界),如 空间位置等来检索图像信息,但是CBR系统存在 图像边缘、边界、区域等定义,对于临界的点,将其确 低维特征与高维语义间的“语义鸿沟”,针对该问 定为某一类都会影响标准的准确性,存在的这些模 题,图像自动标注研究如何更加有效地标注和快速 糊属性将干扰图像处理结果的精确性。故本文提出 存取图像。 一种基于隶属度的模糊分类方法,该方法结合模糊 在多数图像自动标注(automatic image annota- 关联规则(fuzzy association rules,FARs)和决策树方 tion,AA)系统中,采用全局特征、基于块的局部特 法来自动标注图像,方法的优点在于:一方面,在训 征或是基于区域的局部特征表示图像。Jeon等) 练阶段,根据提出的评价标准获得模糊关联规则,该 使用区域分割方法,假设图像语义用区域特征产生 关联规则决定图像特征和语义关联的程度,更加直 的词汇来描述,结合以上3种特征表述方法,提出全 观的获取了低维图像特征和高维图像语义间的联 局和局部的特征表示方法来标注图像。Wang等) 系,很好地解决了“语义鸿沟”问题:根据隶属度函 提出了一种结合全局、区域及上下文特征表示的改 数将低维图像特征映射到模糊特征向量,旨在处理 进模型,通过计算它们的联合概率并结合以上3种 “锐利的边界”的问题。另一方面,运用决策树算法 特征表示标注图像。Duygulu等[s)提出翻译模型标 来解决冗余的模糊关联规则,过滤掉不必要的和弱 注图像,该方法是一种生成式模型标注的代表性方 的关联规则,大大减小了算法的时间复杂度,提高了 法,它通过学习联合概率将关键词与图像的区域联 标注的准确性和效率。 系起来,将标注过程转化成一个将区域翻译为关键 1图像分割及特征提取 词的过程。Monay等[)提出基于概率潜在语义分析 (probabilistic latent semantic analysis,PLSA)模型的 在图像自动标注中,图像用全局特征或局部特 图像自动标注方法PLSA-WORDS。.李志欣等在此 征表示,把图像分割成不同子区域。图像分割是图 基础上先后提出融合语义主题的图像自动标注) 像处理的关键步骤,图像分割的好坏将影响到图像 及混合生成式和判别式模型的图像自动标注模型 标注的精度。分割方法包括边缘检测、边缘跟踪、区 hybrid generative/discriminative model,HGDM)[8] 域增长等。区域增长的图像分割通常能将具有相同 HGDM首先用连续PLSA模型处理图像视觉特征, 特征的联通区域分割出来。并且能提供很好的边界 然后构建用来学习图像语义类别的分类模型链,综 信息和分割结果。针对本文“锐利边界问题”,为了 合神经网络、多类SVM以及K近邻分类器模型,利 体现对图像的边缘信息点的处理,文中采用区域增 用EM算法计算一个权重参数,根据该参数来选择 长方法分割图像。区域生长一般分3个步骤:1)选 精确度更高的分类模型,最终得到目标的语义。茹 择合适的生长点:2)确定生长准则:3)确定生长停 立云等f9)提出一种基于boosting学习的图像自动标 止条件。表1给出了来自Corl5k数据集的部分图 注系统,假设一组具有同一语义的图像能够由一组 像分割前后对比。 视觉模型来表示,即颜色和纹理特殊组合的2维多 表1图像分割的几个实例 分辨率隐马尔可夫模型,然后使用boosting算法实 Table 1 Several examples of image segmentation 现关键词与模型的关联。Sumathi和Hemalatha提 原始图像 分割后图像 原始图像 分割后图像 出一种创新的混合分层图像标注模型],该方法运 用低维图像特征及其特征间距离找到图像的最近 邻,然后用SVM方法得到图像标注。张静等[山提 出一种新的模型提取图像前景和背景语义,运用视 觉特点分析多个判别方法获得前景语义概念,用区 域语义分析方法标注背景图像。Makadia等2]提出 用JEC(joint equal contribution)的方法进行图像标 图像表示和特征提取是标注算法中一个重要和 注,JEC利用全局低维图像特征和基本距离度量的 决定性的步骤,图像进行区域分割后,从分割区域中 简单结合寻找给定图像的最近邻,然后使用一种贪 提取低维视觉特征,特征向量呈现图像不同的属性 心的标签传递机制将关键词赋予对应的图像,取得 和特征。图像特征表示的相关文献有MPEG-7标 了很好的标注精度和检索性能。 准)、颜色聚合向量[14,Lowe在2004年提出的
于内容的图像检索( content based image retrieval, CBIR),用低维的视觉特征如颜色、形状、纹理以及 空间位置等来检索图像信息,但是 CBIR 系统存在 低维特征与高维语义间的“语义鸿沟”,针对该问 题,图像自动标注研究如何更加有效地标注和快速 存取图像。 在多数图像自动标注( automatic image annota⁃ tion, AIA)系统中,采用全局特征、基于块的局部特 征或是基于区域的局部特征表示图像。 Jeon 等[3] 使用区域分割方法,假设图像语义用区域特征产生 的词汇来描述,结合以上 3 种特征表述方法,提出全 局和局部的特征表示方法来标注图像。 Wang 等[4] 提出了一种结合全局、区域及上下文特征表示的改 进模型,通过计算它们的联合概率并结合以上 3 种 特征表示标注图像。 Duygulu 等[5] 提出翻译模型标 注图像,该方法是一种生成式模型标注的代表性方 法,它通过学习联合概率将关键词与图像的区域联 系起来,将标注过程转化成一个将区域翻译为关键 词的过程。 Monay 等[6]提出基于概率潜在语义分析 (probabilistic latent semantic analysis, PLSA)模型的 图像自动标注方法 PLSA⁃WORDS。 李志欣等在此 基础上先后提出融合语义主题的图像自动标注[7] 及混合生成式和判别式模型的图像自动标注模型 (hybrid generative / discriminative model, HGDM) [8] 。 HGDM 首先用连续 PLSA 模型处理图像视觉特征, 然后构建用来学习图像语义类别的分类模型链,综 合神经网络、多类 SVM 以及 K 近邻分类器模型,利 用 EM 算法计算一个权重参数,根据该参数来选择 精确度更高的分类模型,最终得到目标的语义。 茹 立云等[9]提出一种基于 boosting 学习的图像自动标 注系统,假设一组具有同一语义的图像能够由一组 视觉模型来表示,即颜色和纹理特殊组合的 2 维多 分辨率隐马尔可夫模型,然后使用 boosting 算法实 现关键词与模型的关联。 Sumathi 和 Hemalatha 提 出一种创新的混合分层图像标注模型[10] ,该方法运 用低维图像特征及其特征间距离找到图像的最近 邻,然后用 SVM 方法得到图像标注。 张静等[11] 提 出一种新的模型提取图像前景和背景语义,运用视 觉特点分析多个判别方法获得前景语义概念,用区 域语义分析方法标注背景图像。 Makadia 等[12]提出 用 JEC( joint equal contribution) 的方法进行图像标 注,JEC 利用全局低维图像特征和基本距离度量的 简单结合寻找给定图像的最近邻,然后使用一种贪 心的标签传递机制将关键词赋予对应的图像,取得 了很好的标注精度和检索性能。 但是,在以上标注模型中都没有考虑到图像处 理中存在的模糊和不确定性的属性(锐利边界),如 图像边缘、边界、区域等定义,对于临界的点,将其确 定为某一类都会影响标准的准确性,存在的这些模 糊属性将干扰图像处理结果的精确性。 故本文提出 一种基于隶属度的模糊分类方法,该方法结合模糊 关联规则(fuzzy association rules, FARs)和决策树方 法来自动标注图像,方法的优点在于:一方面,在训 练阶段,根据提出的评价标准获得模糊关联规则,该 关联规则决定图像特征和语义关联的程度,更加直 观的获取了低维图像特征和高维图像语义间的联 系,很好地解决了“语义鸿沟”问题;根据隶属度函 数将低维图像特征映射到模糊特征向量,旨在处理 “锐利的边界”的问题。 另一方面,运用决策树算法 来解决冗余的模糊关联规则,过滤掉不必要的和弱 的关联规则,大大减小了算法的时间复杂度,提高了 标注的准确性和效率。 1 图像分割及特征提取 在图像自动标注中,图像用全局特征或局部特 征表示,把图像分割成不同子区域。 图像分割是图 像处理的关键步骤,图像分割的好坏将影响到图像 标注的精度。 分割方法包括边缘检测、边缘跟踪、区 域增长等。 区域增长的图像分割通常能将具有相同 特征的联通区域分割出来。 并且能提供很好的边界 信息和分割结果。 针对本文“锐利边界问题”,为了 体现对图像的边缘信息点的处理,文中采用区域增 长方法分割图像。 区域生长一般分 3 个步骤:1) 选 择合适的生长点;2) 确定生长准则;3) 确定生长停 止条件。 表 1 给出了来自 Corel 5k 数据集的部分图 像分割前后对比。 表 1 图像分割的几个实例 Table 1 Several examples of image segmentation 原始图像 分割后图像 原始图像 分割后图像 图像表示和特征提取是标注算法中一个重要和 决定性的步骤,图像进行区域分割后,从分割区域中 提取低维视觉特征,特征向量呈现图像不同的属性 和特征。 图像特征表示的相关文献有 MPEG⁃7 标 准[13] 、颜色聚合向量[14] , Lowe 在 2004 年提出的 第 4 期 李志欣,等:基于模糊关联规则和决策树的图像自动标注 ·637·
·638. 智能系统学报 第10卷 SFT特征[等,文中采用图像的颜色、边缘和纹理 表示的边缘特征,从每幅图像提取一个22维特征向 特征来表示。 量。特征表示如图1所示。 2图像自动标注模型 关联规则算法广泛运用在数据挖掘和分 类[]中,研究证明关联规则方法比支持向量机(sup 边缘 颜色 纹理 port vector machine,SVM)、朴素贝叶斯、神经网络等 方法具有更高的分类准确率,但关联规则算法处理 “锐利边界”问题性能较弱。为了解决这个问题, 色度 饱和度 明度 Kuok等提出了模糊技术来挖掘关联规则1),研究了 图1图像的视觉特征表示 很多基于FARs的分类模型,并广泛运用于数据挖掘 Fig.1 Image representation of visual features 中,同时,模糊关联规则在图像处理领域也有相关研 颜色是图像的最重要的特征之一,RGB、LUV、 究。文献[19]提出了一种基于自适应区间划分的模 HSV、HMMD是使用频繁的色彩空间,图像特征描述 糊关联遥感图像分类方法。算法根据遥感图像分类 器包括颜色直方图、颜色矩、颜色聚合向量等。纹理 的特点,利用模糊C均值聚类算法自适应地建立连续 特征能粗糙的捕捉图像的特点,在图像处理和计算 型属性模糊区间,使用新的剪枝策略对项集进行筛选 机视觉中,纹理分析模型采用高斯分布、马尔可夫随 从而避免生成无用规则,采用一种新的规则重要性度 机场和Gabor滤波器获取图像数据。边缘特征对于 量方法对多模糊分类规则进行融合,从而有效地提高 提取一些灰暗的图像特别重要,在4个方向(0、45°、 分类效率和精确度。文献[20]提出运用一种分层的 90°和135)使用Canny边缘检测方法检测边缘线。 模糊关联规则用于图像分类。但以上方法都存在模 HSV模型跟人类视觉感知密切相关,本文使用HSV 糊关联规则库过于庞大的问题。 来定义颜色空间,通过包含9个容器的一维直方图 本文提出的标注方法首先对视觉特征模糊化, 来统计图像颜色的特征分布,它把颜色空间量化成 再提取特征与语义之间的关系,形成模糊关联规则。 不同的小容器并且计算属于每个区间颜色像素点的 最后用决策树方法处理冗余的规则,使标注性能更 频率。再综合9维的纹理特征向量和4维方向向量 高,标注结果更准确。系统框架如图2所示。 模糊分割 图像分割 特特提取 模糊特征 FARs 决策树 规则约简 图像分割 特征提取 自动标注 标注模型) 图2基于FARs和决策树的图像自动标注框架 Fig.2 Automatic image annotation framework based on FARs and decision tree 2.1模糊关联规则 2.1.1模糊分割 实验数据集分成训练和测试2个部分,训练数 在图像处理中,存在着模糊和不确定性的定义, 据集用来构建模型,测试数据集用来实现多标记图 如图像边缘、边界、区域和纹理等定义,模糊属性将 像的标注。在训练阶段,首先提取图像低维特征,根 干扰图像处理结果的精确性。 据模糊分割获得原始低维特征到模糊特征向量的映 将颜色、纹理、边缘特征映射到模糊特征向量 射,再计算模糊支持度和模糊置信度产生模糊关联 中,图3给出由三角隶属度函数转换数值型低维视 规则,最后,使用决策树对关联规则库进行后期处 觉特征到语义概念的模糊集,隶属度取值[0,1]。 理,删减冗余的关联规则
SIFT 特征[15] 等,文中采用图像的颜色、边缘和纹理 特征来表示。 图 1 图像的视觉特征表示 Fig.1 Image representation of visual features 颜色是图像的最重要的特征之一,RGB、LUV、 HSV、HMMD 是使用频繁的色彩空间,图像特征描述 器包括颜色直方图、颜色矩、颜色聚合向量等。 纹理 特征能粗糙的捕捉图像的特点,在图像处理和计算 机视觉中,纹理分析模型采用高斯分布、马尔可夫随 机场和 Gabor 滤波器获取图像数据。 边缘特征对于 提取一些灰暗的图像特别重要,在 4 个方向(0、45°、 90°和 135°)使用 Canny 边缘检测方法检测边缘线。 HSV 模型跟人类视觉感知密切相关,本文使用 HSV 来定义颜色空间,通过包含 9 个容器的一维直方图 来统计图像颜色的特征分布,它把颜色空间量化成 不同的小容器并且计算属于每个区间颜色像素点的 频率。 再综合 9 维的纹理特征向量和 4 维方向向量 表示的边缘特征,从每幅图像提取一个 22 维特征向 量。 特征表示如图 1 所示。 2 图像自动标注模型 关联规则算法广泛运用在数据挖掘[16] 和分 类[17]中,研究证明关联规则方法比支持向量机(sup⁃ port vector machine, SVM)、朴素贝叶斯、神经网络等 方法具有更高的分类准确率,但关联规则算法处理 “锐利边界” 问题性能较弱。 为了解决这个问题, Kuok 等提出了模糊技术来挖掘关联规则[18] ,研究了 很多基于 FARs 的分类模型,并广泛运用于数据挖掘 中,同时,模糊关联规则在图像处理领域也有相关研 究。 文献[19]提出了一种基于自适应区间划分的模 糊关联遥感图像分类方法。 算法根据遥感图像分类 的特点,利用模糊 C 均值聚类算法自适应地建立连续 型属性模糊区间,使用新的剪枝策略对项集进行筛选 从而避免生成无用规则,采用一种新的规则重要性度 量方法对多模糊分类规则进行融合,从而有效地提高 分类效率和精确度。 文献[20]提出运用一种分层的 模糊关联规则用于图像分类。 但以上方法都存在模 糊关联规则库过于庞大的问题。 本文提出的标注方法首先对视觉特征模糊化, 再提取特征与语义之间的关系,形成模糊关联规则。 最后用决策树方法处理冗余的规则,使标注性能更 高,标注结果更准确。 系统框架如图 2 所示。 图 2 基于 FARs 和决策树的图像自动标注框架 Fig.2 Automatic image annotation framework based on FARs and decision tree 2.1 模糊关联规则 实验数据集分成训练和测试 2 个部分,训练数 据集用来构建模型,测试数据集用来实现多标记图 像的标注。 在训练阶段,首先提取图像低维特征,根 据模糊分割获得原始低维特征到模糊特征向量的映 射,再计算模糊支持度和模糊置信度产生模糊关联 规则,最后,使用决策树对关联规则库进行后期处 理,删减冗余的关联规则。 2.1.1 模糊分割 在图像处理中,存在着模糊和不确定性的定义, 如图像边缘、边界、区域和纹理等定义,模糊属性将 干扰图像处理结果的精确性。 将颜色、纹理、边缘特征映射到模糊特征向量 中,图 3 给出由三角隶属度函数转换数值型低维视 觉特征到语义概念的模糊集,隶属度取值[0,1]。 ·638· 智 能 系 统 学 报 第 10 卷
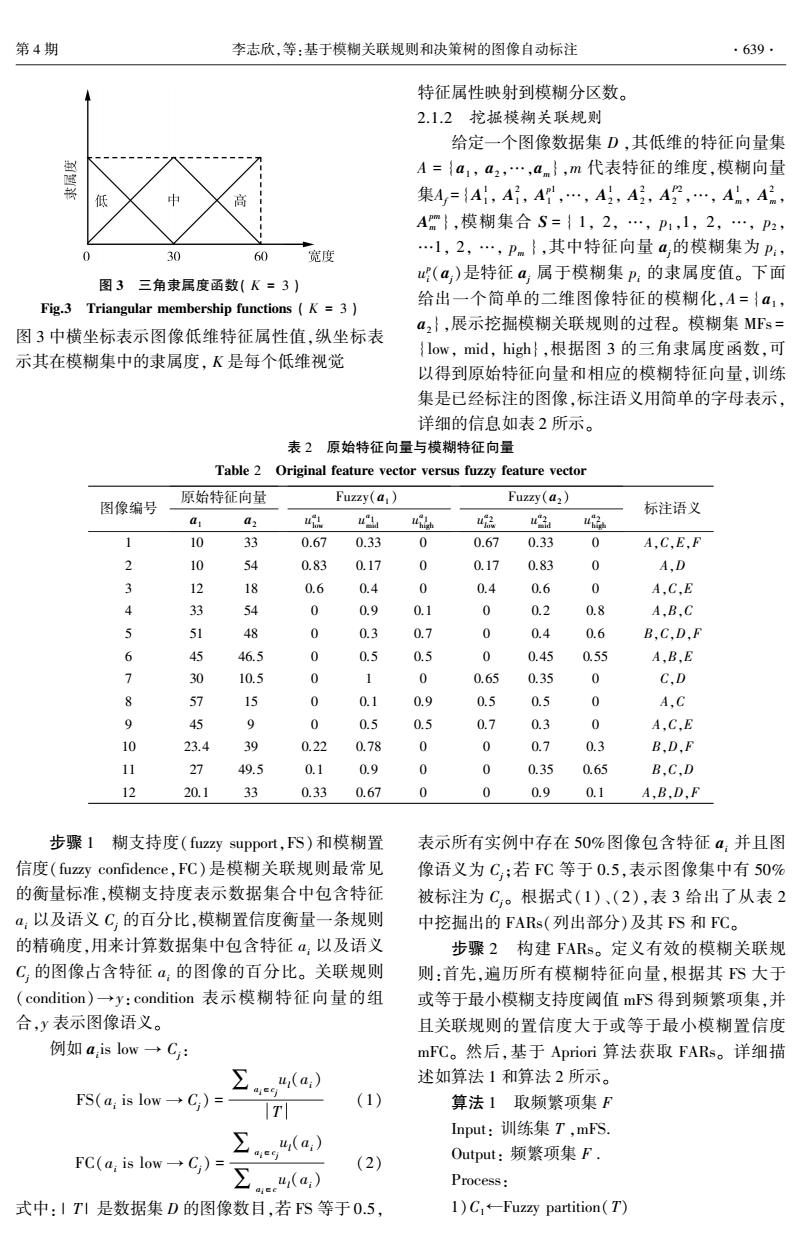
第4期 李志欣,等:基于模糊关联规则和决策树的图像自动标注 .639· 特征属性映射到模糊分区数。 2.1.2挖掘模糊关联规则 给定一个图像数据集D,其低维的特征向量集 赵 A={a,a2,…,an},m代表特征的维度,模糊向量 低 中 集A,={A1,A,A,…,A,A号,A,…,A,A2 Am},模糊集合S={1,2,…,P1,1,2,…,P2, 0 30 60 宽度 …l,2,…,pm},其中特征向量a的模糊集为p:, (a)是特征a属于模糊集P:的隶属度值。下面 图3三角隶属度函数(K=3) Fig.3 Triangular membership functions (K 3 给出一个简单的二维图像特征的模糊化,A={a1, a2},展示挖掘模糊关联规则的过程。模糊集MFs= 图3中横坐标表示图像低维特征属性值,纵坐标表 {low,mid,high},根据图3的三角隶属度函数,可 示其在模糊集中的隶属度,K是每个低维视觉 以得到原始特征向量和相应的模糊特征向量,训练 集是已经标注的图像,标注语义用简单的字母表示, 详细的信息如表2所示。 表2原始特征向量与模糊特征向量 Table 2 Original feature vector versus fuzzy feature vector 原始特征向量 图像编号 Fuzzy(a,) Fuzy(a2) 标注语义 a a2 t u 4品 ui u峰 1 10 33 0.67 0.33 0 0.67 0.33 0 A.C.E.F 2 10 54 0.83 0.17 0 0.17 0.83 0 A.D 3 12 18 0.6 0.4 0 0.4 0.6 0 A,C,E 4 3 54 0 0.9 0.1 0 0.2 0.8 A,B,C 5 51 48 0 0.3 0.7 0 0.4 0.6 B.C.D,F 6 45 46.5 0 0.5 0.5 0 0.45 0.55 A,B,E 7 30 10.5 1 0 0.65 0.35 0 C.D 8 57 15 0 0.1 0.9 0.5 0.5 0 A,C 9 45 9 0 0.5 0.5 0.7 0.3 0 A.C,E 10 23.4 西 0.22 0.78 0 0 0.7 0.3 B.D,F 11 27 49.5 0.1 0.9 0 0 0.35 0.65 B.C,D 12 20.1 33 0.33 0.67 0 0 0.9 0.1 A,B,D,F 步骤1糊支持度(fuzzy support,FS)和模糊置 表示所有实例中存在50%图像包含特征4,并且图 信度(fuzzy confidence,FC)是模糊关联规则最常见 像语义为C,:若FC等于0.5,表示图像集中有50% 的衡量标准,模糊支持度表示数据集合中包含特征 被标注为C。根据式(1)、(2),表3给出了从表2 a:以及语义C的百分比,模糊置信度衡量一条规则 中挖掘出的FARs(列出部分)及其FS和FC。 的精确度,用来计算数据集中包含特征a:以及语义 步骤2构建FARs。定义有效的模糊关联规 C:的图像占含特征α:的图像的百分比。关联规则 则:首先,遍历所有模糊特征向量,根据其FS大于 (condition)→y:condition表示模糊特征向量的组 或等于最小模糊支持度阈值mS得到频繁项集,并 合,y表示图像语义。 且关联规则的置信度大于或等于最小模糊置信度 例如a,is low→C: mFC。然后,基于Apriori算法获取FARs。详细描 u(a:)) 述如算法1和算法2所示。 FS(a:is low→C)= tl (1) 算法1取频繁项集F Input:训练集T,mFS. u(a:) FC(a:is low→C)= (2) Output:频繁项集F. Process: 式中:1T1是数据集D的图像数目,若FS等于0.5, 1)C+-Fuzzy partition(T)
图 3 三角隶属度函数( K = 3 ) Fig.3 Triangular membership functions ( K = 3 ) 图 3 中横坐标表示图像低维特征属性值,纵坐标表 示其在模糊集中的隶属度, K 是每个低维视觉 特征属性映射到模糊分区数。 2.1.2 挖掘模糊关联规则 给定一个图像数据集 D ,其低维的特征向量集 A = {a1 , a2 ,…,am },m 代表特征的维度,模糊向量 集Af = {A 1 1 , A 2 1 , A p1 1 ,…, A 1 2 , A 2 2 , A P2 2 ,…, A 1 m , A 2 m , A pm m },模糊集合 S = { 1, 2, …, p1 ,1, 2, …, p2 , …1, 2, …, pm },其中特征向量 aj的模糊集为 pi, u p i(aj)是特征 aj 属于模糊集 pi 的隶属度值。 下面 给出一个简单的二维图像特征的模糊化,A = { a1 , a2 },展示挖掘模糊关联规则的过程。 模糊集 MFs = {low, mid, high},根据图 3 的三角隶属度函数,可 以得到原始特征向量和相应的模糊特征向量,训练 集是已经标注的图像,标注语义用简单的字母表示, 详细的信息如表 2 所示。 表 2 原始特征向量与模糊特征向量 Table 2 Original feature vector versus fuzzy feature vector 图像编号 原始特征向量 a1 a2 Fuzzy(a1 ) u a 1 low u a 1 mid u a 1 high Fuzzy(a2 ) u a 2 low u a 2 mid u a 2 high 标注语义 1 10 33 0.67 0.33 0 0.67 0.33 0 A,C,E,F 2 10 54 0.83 0.17 0 0.17 0.83 0 A,D 3 12 18 0.6 0.4 0 0.4 0.6 0 A,C,E 4 33 54 0 0.9 0.1 0 0.2 0.8 A,B,C 5 51 48 0 0.3 0.7 0 0.4 0.6 B,C,D,F 6 45 46.5 0 0.5 0.5 0 0.45 0.55 A,B,E 7 30 10.5 0 1 0 0.65 0.35 0 C,D 8 57 15 0 0.1 0.9 0.5 0.5 0 A,C 9 45 9 0 0.5 0.5 0.7 0.3 0 A,C,E 10 23.4 39 0.22 0.78 0 0 0.7 0.3 B,D,F 11 27 49.5 0.1 0.9 0 0 0.35 0.65 B,C,D 12 20.1 33 0.33 0.67 0 0 0.9 0.1 A,B,D,F 步骤 1 糊支持度( fuzzy support,FS)和模糊置 信度(fuzzy confidence,FC)是模糊关联规则最常见 的衡量标准,模糊支持度表示数据集合中包含特征 ai 以及语义 Cj 的百分比,模糊置信度衡量一条规则 的精确度,用来计算数据集中包含特征 ai 以及语义 Cj 的图像占含特征 ai 的图像的百分比。 关联规则 (condition) →y:condition 表示模糊特征向量的组 合,y 表示图像语义。 例如 ai is low → Cj: FS(ai is low → Cj) = ∑ai∈cj ul(ai) T (1) FC(ai is low → Cj) = ∑ai∈cj ul(ai) ∑ai∈c ul(ai) (2) 式中: | T | 是数据集 D 的图像数目,若 FS 等于 0.5, 表示所有实例中存在 50%图像包含特征 ai 并且图 像语义为 Cj;若 FC 等于 0.5,表示图像集中有 50% 被标注为 Cj。 根据式(1)、(2),表 3 给出了从表 2 中挖掘出的 FARs(列出部分)及其 FS 和 FC。 步骤 2 构建 FARs。 定义有效的模糊关联规 则:首先,遍历所有模糊特征向量,根据其 FS 大于 或等于最小模糊支持度阈值 mFS 得到频繁项集,并 且关联规则的置信度大于或等于最小模糊置信度 mFC。 然后,基于 Apriori 算法获取 FARs。 详细描 述如算法 1 和算法 2 所示。 算法 1 取频繁项集 F Input: 训练集 T ,mFS. Output: 频繁项集 F . Process: 1)C1←Fuzzy partition(T) 第 4 期 李志欣,等:基于模糊关联规则和决策树的图像自动标注 ·639·
·640. 智能系统学报 第10卷 2)Ffuzzy frequent 1 item sets 著名的ID3算法、C4.5以及Breiman提出的CART 3)for(k=2;Fk-1≠;k++)do 算法。 4)Ca=Candidate(F-1); FARs的不足在于模糊关联规则数目随着图像 5)for each transaction tT do 数据集的扩大变得庞大,将产生大量冗余的关联规 6)for each candidate cC do 则,导致标注性能降低。约简模糊关联规则成了研 7)F=Checking(C,mFS) 究的热点,文献[21-22]提出用遗传算法解决这个 8)return F=UF 问题。 算法2获取FARs 本文提出运用决策树算法[]实现最佳模糊关 Input:频繁项集F,mFC. 联规则提取,在决策树的每个节点处根据一个或多 Output:FARs. 个属性值进行划分,这种方式直观且分类精度高、可 Process: 读性好、分类速度快。通过算法可以过滤掉冗余的 1)for every feature attribute cC,do 和弱的关联规则,实验证明该方法能取得很好的标 2)while F≠Φ,do 注效果。 3)for every frequent itemsets fF 通过获得的模糊关联规则,规则的前件用来 4)if(fuzconf(f→c)≥MFC)then 构建决策树的新的属性,若一条关联规则如下: 5)Output the rule f→c with conf=fuzconf(f→ R1:(a1 is low,a2 is mid)→A,a1∩a2即决策树 c); 的候选属性,这样的候选属性构建的决策树是否 表3模糊关联规则及其FS、FC 使标注效果更好,这是不确定的,这里提出了新 Table 3 Fuzzy support and fuzzy confidence of association rules 的评价标准。首先,选择候选属性AN作为决策 编号 规则 Fuzzy support Fuzzy confidence a,is low→A 树的根节点,根节点的信息量计算如式(3),T表 1 0.23 0.88 2 a is lowB 0.05 0.24 示数据库图像实例数目,k表示图像的类别数量, 3 a,is low→C 0.11 0.50 S代表类j的图像数量。 4 a is lowD 0.12 0.54 (3) 5 a2 is low→A 0.20 0.79 6名阁 6 a2 is low→B 0 0 用生成的候选属性进行数据分割时,使AN=1 7 a2 is low-C 0.24 0.95 的数据记录的数目用式(4)表示,在这些符合 8 a2 is low→+D 0.07 0.27 AN=1的数据记录中,类别属性C的值为c:的记 9 a,is mid→A 0.30 0.55 录数目如式(5),但是类别属性C的值为c:的记录 10 a,is mid→B 0.34 0.62 11 a1 is mid→C 数目是未知的,由于新的规则是利用近似精确规则 0.37 0.68 12 a,is mid→D 0.32 0.58 来生成的,即当规则前件出现时,规则的后件仅在少 13 a2 is mid→A 0.34 0.70 数例外的情况下不出现。从而这里忽略了这类数据 14 a2 is mid→B 0.25 0.51 包含的信息量。 15 a is midC 0.25 0.51 16 a2 is mid→D 0.29 0.60 T =T sup(R.) (4) conf(R:) 17 a1 is high→A 0.17 0.74 T2=T·sup(R:) (5) 18 a,is high一→B 0.11 0.48 这样符合AN,=1的数据记录所包含的信息量 19 a.is high→C 0.18 0.81 如式(6),而在这些不符合AN=1的数据记录数目 20 a1 is high→D 0.06 0.26 21 a2 is highA 0.12 0.48 为式(7): 22 a2 is high→B 0.16 1 (6) 23 a,is high→C 0.17 0.68 24a2 is high→D 0.14 0.55 (7) 2.2决策树 T3=T-T;=7conf(R:)-sup(R) conf(R) 决策树方法是一种基本的分类和回归方法,用 设在这些不符合AN,=1的数据记录中,类别属 于分类的决策树主要优点是具有可读性,分类速度 性值C(k=1,2,…,n)的记录数目为T4,则这些 快。决策树学习的思想主要来源于Quinlan提出的 记录所包含的信息量为
2)F1←{fuzzy frequent 1 item sets} 3)for ( k = 2; Fk-1≠;k++) do 4)Ck = Candidate(Fk-1 ); 5) for each transaction t ∈ T do 6) for each candidate c ∈ Ck do 7)Fk =Checking(Ck, mFS) 8) return F =∪kFk 算法 2 获取 FARs Input: 频繁项集 F ,mFC. Output: FARs. Process: 1) for every feature attribute c ∈ C , do 2)while Fk ≠ Φ , do 3)for every frequent itemsets f ∈ Fk 4)if (fuzconf( f → c ) ≥MFC) then 5)Output the rule f → c with conf = fuzconf( f → c ); 表 3 模糊关联规则及其 FS、FC Table 3 Fuzzy support and fuzzy confidence of association rules 编号 规则 Fuzzy support Fuzzy confidence 1 a1 is low → A 0.23 0.88 2 a1 is low → B 0.05 0.24 3 a1 is low → C 0.11 0.50 4 a1 is low → D 0.12 0.54 5 a2 is low → A 0.20 0.79 6 a2 is low → B 0 0 7 a2 is low → C 0.24 0.95 8 a2 is low → D 0.07 0.27 9 a1 is mid → A 0.30 0.55 10 a1 is mid → B 0.34 0.62 11 a1 is mid → C 0.37 0.68 12 a1 is mid → D 0.32 0.58 13 a2 is mid → A 0.34 0.70 14 a2 is mid → B 0.25 0.51 15 a2 is mid → C 0.25 0.51 16 a2 is mid → D 0.29 0.60 17 a1 is high → A 0.17 0.74 18 a1 is high → B 0.11 0.48 19 a1 is high → C 0.18 0.81 20 a1 is high → D 0.06 0.26 21 a2 is high → A 0.12 0.48 22 a2 is high → B 0.16 1 23 a2 is high → C 0.17 0.68 24 a2 is high → D 0.14 0.55 2.2 决策树 决策树方法是一种基本的分类和回归方法,用 于分类的决策树主要优点是具有可读性,分类速度 快。 决策树学习的思想主要来源于 Quinlan 提出的 著名的 ID3 算法、C4.5 以及 Breiman 提出的 CART 算法。 FARs 的不足在于模糊关联规则数目随着图像 数据集的扩大变得庞大,将产生大量冗余的关联规 则,导致标注性能降低。 约简模糊关联规则成了研 究的热点,文献[21⁃22] 提出用遗传算法解决这个 问题。 本文提出运用决策树算法[23] 实现最佳模糊关 联规则提取,在决策树的每个节点处根据一个或多 个属性值进行划分,这种方式直观且分类精度高、可 读性好、分类速度快。 通过算法可以过滤掉冗余的 和弱的关联规则,实验证明该方法能取得很好的标 注效果。 通过获得的模糊关联规则,规则的前件用来 构建决策树的新的属性,若一条关联规则如下: R1 : ( a1 is low, a2 is mid) → A,a1∩a2 即决策树 的候选属性,这样的候选属性构建的决策树是否 使标注效果更好,这是不确定的,这里提出了新 的评价标准。 首先,选择候选属性 ANj 作为决策 树的根节点,根节点的信息量计算如式( 3) ,T 表 示数据库图像实例数目,k 表示图像的类别数量, cj 代表类 j 的图像数量。 Groot = - ∑ k j = 1 cj T lb cj T (3) 用生成的候选属性进行数据分割时,使 ANj = 1 的数 据 记 录 的 数 目 用 式 ( 4) 表 示, 在 这 些 符 合 ANj = 1 的数据记录中,类别属性 C 的值为 ci 的记 录数目如式(5),但是类别属性 C 的值为 ci 的记录 数目是未知的,由于新的规则是利用近似精确规则 来生成的,即当规则前件出现时,规则的后件仅在少 数例外的情况下不出现。 从而这里忽略了这类数据 包含的信息量。 T1 = T sup(Ri) conf(Ri) (4) T2 = T·sup(Ri) (5) 这样符合 ANj = 1 的数据记录所包含的信息量 如式(6),而在这些不符合 ANj = 1 的数据记录数目 为式(7): G1 = T1 T - T2 T1 lb T2 T1 é ë ê ê ù û ú ú (6) T3 = T - T1 = T conf(Ri) - sup(Ri) conf(Ri) (7) 设在这些不符合 ANj = 1 的数据记录中,类别属 性值 Ck(k = 1,2,…,n) 的记录数目为 T3k ,则这些 记录所包含的信息量为 ·640· 智 能 系 统 学 报 第 10 卷