
向量空间模型
向量空间模型

统计模型 基于关键词(一个文本由一个关键词列表组成) 根据关键词的出现频率计算相似度 。例如:文档的统计特性 。 用户规定一个词项(term)集合,可以给每个词项附加 权重 ■未加权的词项:Q=〈database;text;information) "加权的词项:Q=〈database0.5;text0.8;information0.2) ·查询式中没有布尔条件 ■根据相似度对输出结果进行排序 ■支持自动的相关反馈 ·有用的词项被添加到原始的查询式中 n例如:Q→(database;text;information;document〉
统计模型 基于关键词(一个文本由一个关键词列表组成) 根据关键词的出现频率计算相似度 例如:文档的统计特性 用户规定一个词项(term)集合,可以给每个词项附加 权重 未加权的词项: Q = 〈 database; text; information 〉 加权的词项: Q = 〈 database 0.5; text 0.8; information 0.2 〉 查询式中没有布尔条件 根据相似度对输出结果进行排序 支持自动的相关反馈 有用的词项被添加到原始的查询式中 例如:Q ⇒ 〈 database; text; information; document 〉

统计模型中的问题 ■怎样确定文档中哪些词是重要的词? ■怎样确定 一个词在某个文档中或在整个文档集 中的重要程度? ■怎样确定一个文档和一个查询式之间的相似 度? ■在WWW中,什么是文档集(collection),链 接、文档结构以及其它形式特征(如字体、颜 色等)对统计模型有何影响?
统计模型中的问题 怎样确定文档中哪些词是重要的词? 怎样确定一个词在某个文档中或在整个文档集 中的重要程度? 怎样确定一个文档和一个查询式之间的相似 度? 在WWW中,什么是文档集(collection),链 接、文档结构以及其它形式特征(如字体、颜 色等)对统计模型有何影响?
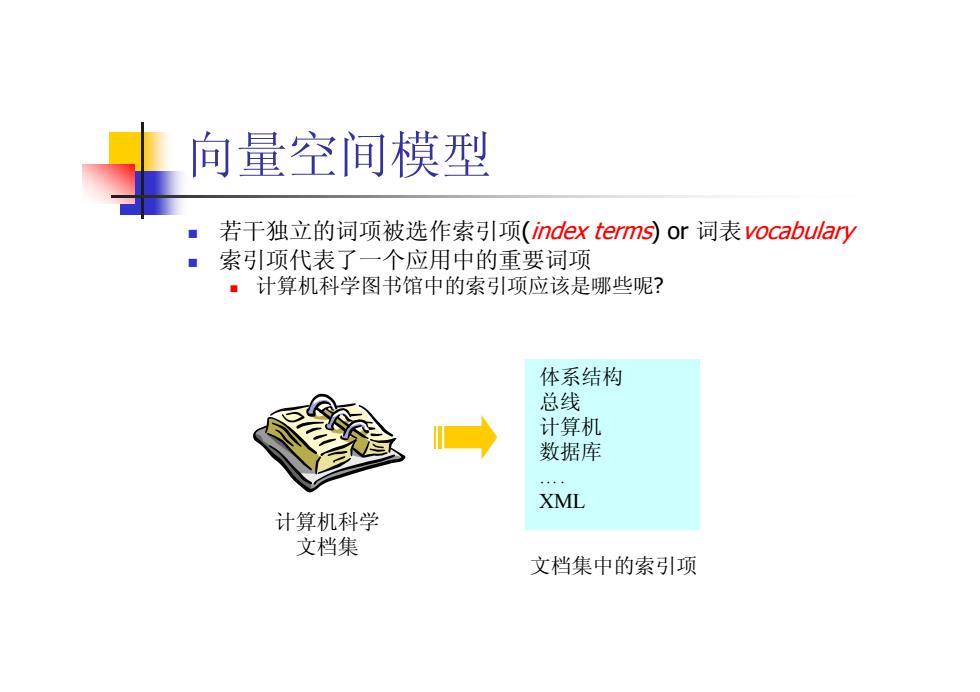
向量空间模型 若干独立的词项被选作索引项(index terms)or词表vocabulary 索引项代表了一个应用中的重要词项 ·计算机科学图书馆中的索引项应该是哪些呢? 体系结构 总线 计算机 数据库 XML 计算机科学 文档集 文档集中的索引项
向量空间模型 若干独立的词项被选作索引项 (index terms) or 词表vocabulary 索引项代表了一个应用中的重要词项 计算机科学图书馆中的索引项应该是哪些呢 ? 体系结构 总线 计算机 数据库 …. XML 计算机科学 文档集 文档集中的索引项

向量空间模型 这些索引项是不相关的un-correlated(或 若说是正交的orthogona),形成一个向 量空间vector space “计算机”“科学”“商务” 计算机科学文档集 该文档集中的全部重要词项
向量空间模型 这些索引项是不相关的un-correlated (或 者说是正交的orthogonal) ,形成一个向 量空间vector space “计算机” “科学” “商务 ” 计算机科学文档集 该文档集中的全部重要词项