
特征提取(Feature Selection) 特征提取 ·在文本分类问题中遇到的一个主要困难就是高 维的特征空间。 ·通常一份普通的文本在经过文本表示后,如果 以词为特征,它的特征空间维数将达到几千, 甚至几万。 ·大多数学习算法都无法处理如此大的维数。 ·为了能够在保证分类性能的前提下,自动降低 特征空间的维数,在许多文本分类系统的实现 中都引入了特征提取方法
特征提取(Feature Selection) 特征提取 在文本分类问题中遇到的一个主要困难就是高 维的特征空间。 通常一份普通的文本在经过文本表示后,如果 以词为特征,它的特征空间维数将达到几千, 甚至几万。 大多数学习算法都无法处理如此大的维数。 为了能够在保证分类性能的前提下,自动降低 特征空间的维数,在许多文本分类系统的实现 中都引入了特征提取方法

学习 训练样本实例:<XC()> ·一个文本实例X∈X ■带有正确的类别标记(x) ■学习的过程是在给定训练样本集合D的 前提下,寻找一个分类函数八),使得: V<x,c(x)>ED:h(x)=c(x)
学习 训练样本实例:<x, c(x)> 一个文本实例 x∈X 带有正确的类别标记 c(x) 学习的过程是在给定训练样本集合D 的 前提下,寻找一个分类函数h(x), 使得: ∀ < x,c(x) >∈ D : h(x) = c(x)

分类的评测 偶然事件表(Contingency Table) 属于此类 不属于此类 判定属于此类 A B 判定不属于此类 C D ■对一个分类器的度量 。准确率(precision)=a/(a+b) ·召▣率(recall)=a/(a+c) 。fallout=b/(b+d)
分类的评测 偶然事件表(Contingency Table ) 对一个分类器的度量 准确率(precision) = a / (a + b) 召回率(recall) = a / (a + c) fallout = b / (b + d) 属于此类 不属于此类 判定属于此类 A B 判定不属于此类 C D

D B
D A B C
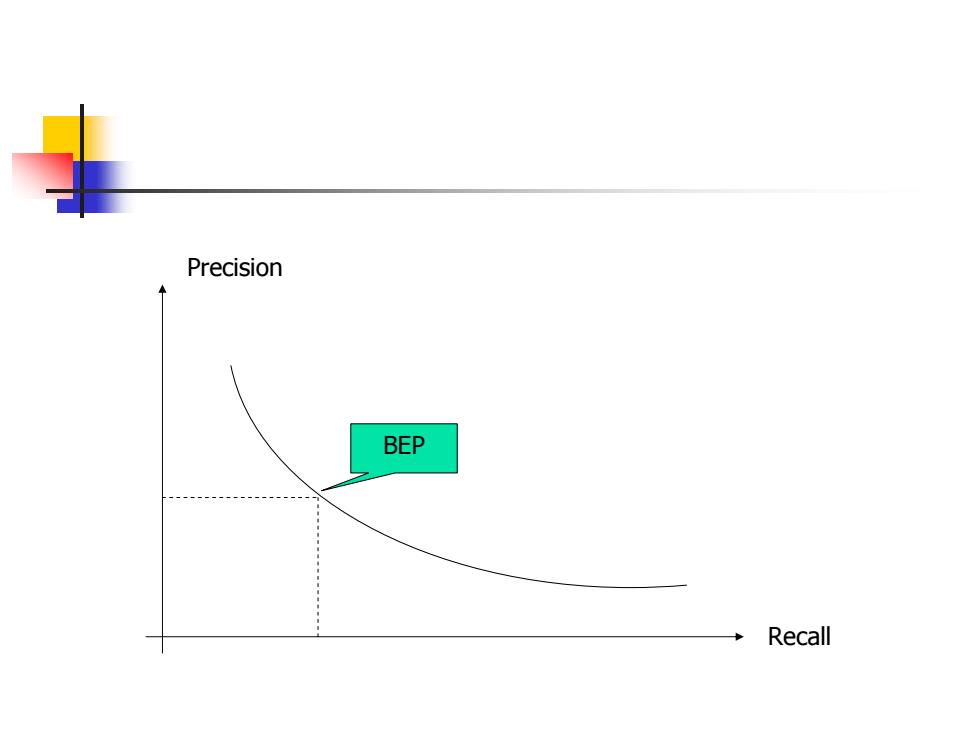
Precision BEP Recall
Precision BEP Recall