
非小细胞肺 癌和EGFR
非小细胞肺 癌和EGFR

疾病概述 ●●●● 肺癌是世界上最常见的恶性肿瘤之一,已成为我国城市人口恶性肿 瘤死亡原因的第1位。 非小细胞肺癌是起源于支气管黏膜、支气管腺体和肺泡上皮的一类 肺恶性肿瘤,显微镜下特点是核异形、细胞较大、胞浆丰富。 根据组织病理学分类可分为腺癌、鳞状细胞癌、腺鳞癌、大细胞癌 及肉瘤样癌等亚型。 在我国,非小细胞肺癌为最常见的肿瘤。 据2013年肺癌相关的调查报道,肺癌新发病及死亡数量为恶性肿瘤 首位,其中,非小细胞肺癌约占所有肺癌的85%,男性发病率与死 亡率均高于女性非小细胞型肺癌包括鳞状细胞癌(鳞癌)、腺癌、 大细胞癌,与小细胞癌相比其癌细胞生长分裂较慢,扩散转移相对 较晚。非小细胞肺癌约占所有肺癌的80%,约75%的患者发现时已处 于中晚期,5年生存率很低
1 疾病概述 肺癌是世界上最常见的恶性肿瘤之一,已成为我国城市人口恶性肿 瘤死亡原因的第1位。 非小细胞肺癌是起源于支气管黏膜、支气管腺体和肺泡上皮的一类 肺恶性肿瘤,显微镜下特点是核异形、细胞较大、胞浆丰富。 根据组织病理学分类可分为腺癌、鳞状细胞癌、腺鳞癌、大细胞癌 及肉瘤样癌等亚型。 在我国,非小细胞肺癌为最常见的肿瘤。 据2013年肺癌相关的调查报道,肺癌新发病及死亡数量为恶性肿瘤 首位,其中,非小细胞肺癌约占所有肺癌的85%,男性发病率与死 亡率均高于女性非小细胞型肺癌包括鳞状细胞癌(鳞癌)、腺癌、 大细胞癌,与小细胞癌相比其癌细胞生长分裂较慢,扩散转移相对 较晚。非小细胞肺癌约占所有肺癌的80%,约75%的患者发现时已处 于中晚期,5年生存率很低
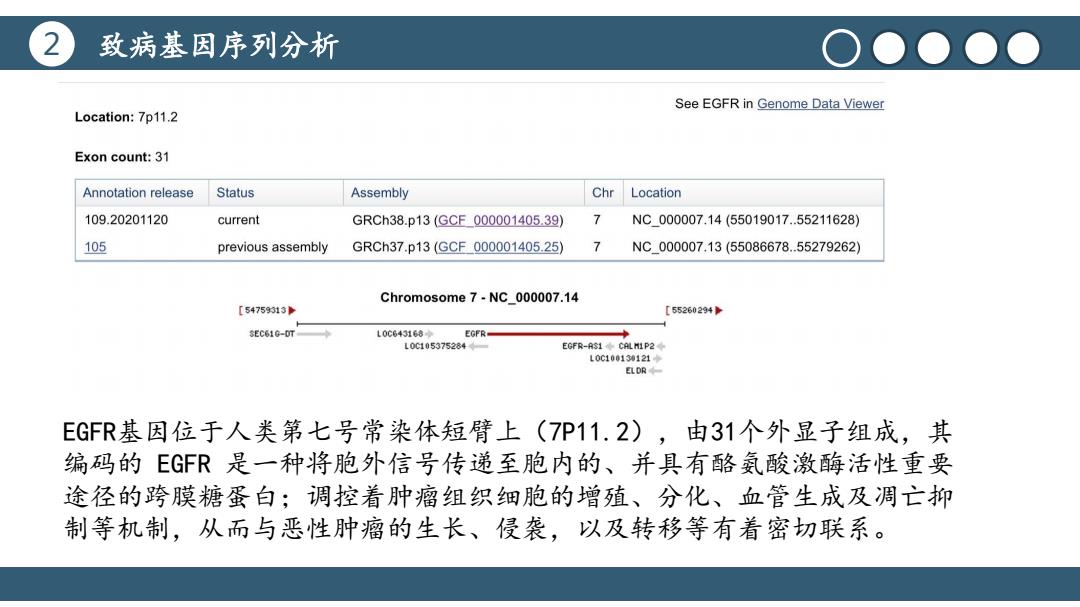
致病基因序列分析 O●●●● See EGFR in Genome Data Viewer Location:7p11.2 Exon count:31 Annotation release Status Assembly Chr Location 109.20201120 current GRCh38.p13(GCF000001405.39) NC_000007.14(55019017.55211628) 105 previous assembly GRCh37.p13(GCF000001405.25) NC000007,13(55086678.55279262) Chromosome 7-NC_000007.14 [54759313 [55260294 SEC610-DT L0c643168 EGFR L0C1053752844 EGFR-A31◆CALM1P2◆ L00100130121◆ ELDR EGFR基因位于人类第七号常染体短臂上(7P11.2),由31个外显子组成,其 编码的EG℉是一种将胞外信号传递至胞内的、并具有酪氨酸激酶活性重要 途径的跨膜糖蛋白;调控着肿瘤组织细胞的增殖、分化、血管生成及调亡抑 制等机制,从而与恶性肿瘤的生长、侵袭,以及转移等有着密切联系
2 致病基因序列分析 标题文本预设 点击此处更换文本点击此处更换文本点 击此处更换文本 标题文本预设 点击此处更换文本点击此处更换文本点 击此处更换文本 标题文本预设 点击此处更换文本点击此处更换文本点 击此处更换文本 EGFR基因位于人类第七号常染体短臂上(7P11.2),由31个外显子组成,其 编码的 EGFR 是一种将胞外信号传递至胞内的、并具有酪氨酸激酶活性重要 途径的跨膜糖蛋白;调控着肿瘤组织细胞的增殖、分化、血管生成及凋亡抑 制等机制,从而与恶性肿瘤的生长、侵袭,以及转移等有着密切联系

致病基因序列分析 O●●●● 104 120M 30M 90H 50M 70M 180M 90M 100M 1O M 120M 130M 140M 159,345973 白号Nc0o0007.14~|Fnd v→Q Q目 入Tools,◆Tracks~是Download,e?, 55H 155020K 55,040K 55,860K s5.880K s5100K 55120K 55140K 551680K $180K S5200K 55228K NCBI Homo sapiens Updated Annotation Release 109.20201120 on GRCh38... EGFR HH.005228.5H +HHP©052192 HH0013468992 HP001333828.1 HH0013469412 =P013338781 1H013468982 HHP.901333827.1 HH0013468972 HHNP0013338261 H2012842 十H十十十P9584411 H2012822 十HH十十一NP9584391 N2812832 1十P958441 00134690021 11P.0013338291 L0105375284 EGFR-ASI L0c10e1301 ■R0017452122 ■047551山 mR9272722 S6H8唱n9ate,NCBI Homo sap1 ens Updated Annotation- 上0× Genes,Ensembl release 102 0g 40× Es600000146648L- 计→州) Es60e000224e57 ■ ☐+BsT6000044241 456000602377 EHsT000042593
2 致病基因序列分析 标题文本预设 点击此处更换文本点击此处更换文本点 击此处更换文本 标题文本预设 点击此处更换文本点击此处更换文本点 击此处更换文本 标题文本预设 点击此处更换文本点击此处更换文本点 击此处更换文本

致病基因序列分析 ●●●● Assembly AGACGTCCGGGCAGCCCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCG GAGACTTTCTTTCTTGGATGTCTCTTTTTGCTGTTTGAAGAATTTGAGCCAACCAAAATATTAAACCTGT ACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCC CTTACACACACACACACACACACACACACACACACACCGGATTGCTGTCCCTGGTTCAAGTGTGCCAAGT ACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCGCACGGCCCCCTGAC GTGCAGACAGAACATGAGCGAGTCTGGCTTCGTGACTACCGACCATAAACCCACTTGACAGGGGAAACAT TCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGG GCCTTGGAAGGTTTAATTGCACAATTCCAACCTTGAGCTGCGCGGGTTCCAAGAGCCAGGCCCGTACTTG CCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGG CTGTTGATGTCATTGGCTTGGGGAGTTGGGGTTTGGTGCCCAGCGCGGTCGTTGGGGGAGGGGCAAGGCA TAAGGGCGTGTCTCGCCGGCTCCCGCGCCGCCCCCGGATCGCGCCCCGGACCCCGCAGCCCGCCCAACCG TAGAACAGTGGTTCCCAGACCTTGCTGCACATTGGAATTACCTGGGATTAAAAAAAAAAAAATCAAAACA CGCACCGGCGCACCGGCTCGGCGCCCGCGCCCCCGCCCGTCCTTTCCTGTTTCCTTGAGATCAGCTGCGC AAAACCAGTGTCTGGCTCCCGCCCCCAGACATTCTGATTTAATTGGCATGGGGCAAGACCTGGACTTGGG CGCCGACCGGGACCGCGGGAGGAACGGGACGTTTCGTTCTTCGGCCGGGAGAGTCTGGGGCGGGCGGAGG ATTTTTTTTAATGCTCTTCATGTGATCTGTTGGGCAGCCAGATTTGGGGATCACTAGACGGAAGAAGGAT AGGAGACGCGTGGGACACCGGGCTGCAGGCCAGGCGGGGAACGGCCGCCGGGACCTCCGGCGCCCCGAAC TGTTAAAGTCTCCGGAGATGTTACTTGCCAATGCTAAGAGCTCTTTGAGGACATCTGGAATTGTTACAAT CGCTCCCAACTTTCTTCCCTCACTTTCCCCGCCCAGCTGCGCAGGATCGGCGTCAGTGGGCGAAAGCCGG ATTGCCAAATATAGGAAAGAGGGAAAAGGTAGAGTGTGATTCCAATAATAAAGGATTCCGCTTTTCATTG GTGCTGGTGGGCGCCTGGGGCCGGGGTCCCGCACGTGCGCCCCGCGCTGTCTTCCCAGGGCGCGACGGGG AAGGAACTGGTGGAAAGGTTTCTTCTCTGCTGAGCCTGCAGGCCCGTCCTGCCTGCCTGGGGTGCCCGGG TCCTGGCGCGCACCCGAGGGGCGGGCGCTGCCCACCCGCCGAGACTGCACTGTTTAGGGAAGCTGAGGAA AGACGCGGGCCTGCTCCGGAGACTGCTGACTGCCGGTCCTGTTAGTCAGGTGTCAGCCCTGTCTCTGCCG GGAACCCAAAAATACAGCCTCCCCTCGGACCCCGCGGGACAGGCGGCTTTCTGAGAGGACCTCCCCGCCT AAGAGACTCTTCTCTTTATTTTAAATTAAACCCTCAGAGCACCACCAAAGCATCACTTTTCTCCCTCCAT CCGCCCTCCGCGCAGGTCTCAAACTGAAGCCGGCGCCCGCCAGCCTGGCCCCGGCCCCTCTCCAGGTCCC TGGTGTTCTCATTCTTTGATGTTACTTGTTTGAACACCACTATTAGTAGTTGGAGATTTGTTCCTGAGAA AAATATAAATACCACTTAATTTGCCTGTTTGTCCCGCATTCACTCAAAACAGAATGCTCCTGAAGACAAG CGCGATCCTCGTTCCCCAGTGTGGAGTCGCAGCCTCGACCTGGGAGCTGGGAGAACTCGTCTACCACCAC AGAGAGAGTAGGAGAACAGACGCTATTCCATTACAGTAACATAAAAGACTGGATTTTCAGGGGCAAATTA CTGCGGCTCCCGGGGAGGGGTGGTGCTGGCGGCGGTTAGTTTCCTCGTTGGCAAAAGGCAGGTGGGGTCC TTAAAATAGGAGATGAGCTCTTTTAACAGAAATTTGTTTAAGGCCTGTGTCTATCAAATTCAGTGGATTT GACCCGCCCCTTGGGCGCAGACCCCGGCCGCTCGCCTCGCCCGGTGCGCCCTCGTCTTGCCTATCCAAGA TATTCAAGATGCACTTTGTTTAGTGGGAGTTTTGTTTGGTTCTGGGACATGCTAACTTCTAGACTTGCTG GTGCCCCCCACCTCCCGGGGACCCCAGCTCCCTCCTGGGCGCCCGCGCCGAAAGCCCCAGGCTCTCCTTC CTCTTAGAGGTAATGACTGCCAGACACCATTTCATGAGTCCTAATCCCCACATTAAGCATAAGAGGTGCA GATGGCCGCCTCGCGGAGACGTCCGGGTCTGCTCCACCTGCAGCCCTTCGGTCGCGCCTGGGCTTCGCGG CACTCTCCTCCTATGGGGGAAACTGAGGTACGAAGAACTAAAGTGACTTTCCCACAGCTGGTGGGAGGCA TGGAGCGGGACGCGGCTGTCCGGCCACTGCAGGGGGGGATCGCGGGACTCTTGAGCGGAAGCCCCGGAAG GACGGGAAATTCACACCAGGGGCTTCCAACTCCAGATCCCTCTCTCAACTTCCAAACTCCACTGCCTTGT CAGAGCTCATCCTGGCCAACACCATGGTGTTTCAAAATGGGGCTCACAGCAAACTTCTCCTCAAAACCCG CCGAGTTCTGGTTTCAGGAGATCCAAATCAGGTGTGTGCAAATGTCTAATGTCAGAGCTGGCAAGGGGAA AGGGCCCAGGGAGCCGGCTCATGACGATGAGCCTGTCTGAAGCTTCAACGCGGGCTGTCCGGCAGTCTGC ATTCCTGCCGAGTTCCTCAGCCCTCTGTTGGGTCACCTTCCATAGAGGCAGCTTAGTCCTCAGTTCAGTG AGCATGGAGTGGAGACTGCTTGAGGGGTGCTGAGCAAAGCCCTGCCTCTTACAGGATGAAGGTGCTCTCC
2 致病基因序列分析