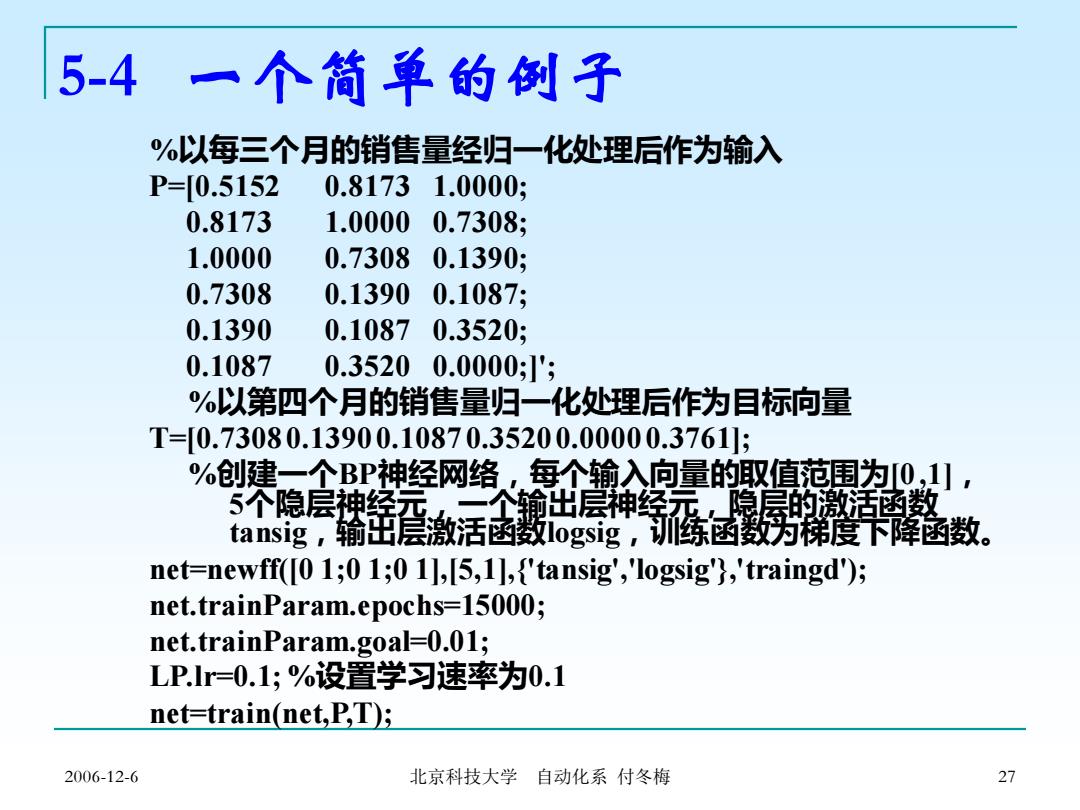
5-4一个简单的例子 %以每三个月的销售量经归一化处理后作为输入 P=0.5152 0.81731.0000; 0.8173 1.0000 0.7308; 1.0000 0.7308 0.1390; 0.7308 0.1390 0.1087; 0.1390 0.1087 0.3520; 0.1087 0.3520 0.0000;'; %以第四个月的销售量归一化处理后作为目标向量 T=0.73080.13900.10870.35200.00000.3761]; %创建,个BP神经网络,每个输入向量的取值范圃为0,1】, 5个隐层神经云一个输出层神终无,隐层的邀活函数 tansig,输茁层激活函数1 ogsig,,训练函数为稀度下降涵数。 net=newff([0 1;0 1;0 1],[5,1],{'tansig','logsig"),'traingd'); net.trainParam.epochs=15000; net.trainParam.goal=0.01; LP.lr=0.1;%设置学习速率为0.1 net=train(net,P,T); 2006-12-6 北京科技大学 自动化系付冬梅 27
2006-12-6 北京科技大学 自动化系 付冬梅 27 %以每三个月的销售量经归一化处理后作为输入 P=[0.5152 0.8173 1.0000; 0.8173 1.0000 0.7308; 1.0000 0.7308 0.1390; 0.7308 0.1390 0.1087; 0.1390 0.1087 0.3520; 0.1087 0.3520 0.0000;]'; %以第四个月的销售量归一化处理后作为目标向量 T=[0.7308 0.1390 0.1087 0.3520 0.0000 0.3761]; %创建一个BP神经网络,每个输入向量的取值范围为[0 ,1], 5个隐层神经元,一个输出层神经元,隐层的激活函数 tansig,输出层激活函数logsig,训练函数为梯度下降函数。 net=newff([0 1;0 1;0 1],[5,1],{'tansig','logsig'},'traingd'); net.trainParam.epochs=15000; net.trainParam.goal=0.01; LP.lr=0.1; %设置学习速率为0.1 net=train(net,P,T); 5-4 一个简单的例子

5-4一个简单的例子 BP网络应用于药品预测对比图 Figure 1 日▣☒ File Edit yiew Insert Iools Desktop Window Help 凸8日6⊙⑨秒回根公·凤口国■▣ 用前三个月销售量预侧第四个月药品销售结果图 0.8 ◆ 药品实际销售量 由对比图可以看出预 0.71 ·药品预测销售量 测效果与实际存在一 0.6 定误差,此误差可以 0.5 通过增加运行步数和 0.4 提高预设误差精度业 0.3 进一步缩小。 02 ◆ 0.1 2 3 5 6 2006-12-6 北京科技大学自动化系付冬梅 28
2006-12-6 北京科技大学 自动化系 付冬梅 28 由对比图可以看出预 测效果与实际存在一 定误差,此误差可以 通过增加运行步数和 提高预设误差精度业 进一步缩小。 ◼BP网络应用于药品预测对比图 5-4 一个简单的例子

5-5BP网络有关的几个问题 ·非线性映射能力 能学习和存贮大量输入-输出模式映射关系,无需事 先了解描述这种映射关系的数学方程。只要能提供足够 多的样本模式供网络进行学习训练,它便能完成由维 输入空间到维输出空间的非线性映射。 泛化能力 当向网络输入训练时未曾见过的非样本数据时,网络 也能完成由输入空间向输出空间的正确映射。这种能力 称为泛化能力。 容错能力 输入样本中带有较大的误差甚至个别错误对网络的输 入输出规律影响很小。 2006-12-6 北京科技大学自动化系付冬梅 29
2006-12-6 北京科技大学 自动化系 付冬梅 29 ◼ 非线性映射能力 能学习和存贮大量输入-输出模式映射关系,无需事 先了解描述这种映射关系的数学方程。只要能提供足够 多的样本模式供网络进行学习训练,它便能完成由n维 输入空间到m维输出空间的非线性映射。 ◼ 泛化能力 当向网络输入训练时未曾见过的非样本数据时,网络 也能完成由输入空间向输出空间的正确映射。这种能力 称为泛化能力。 ◼ 容错能力 输入样本中带有较大的误差甚至个别错误对网络的输 入输出规律影响很小。 5-5 BP网络有关的几个问题

5-5BP网络有关的几个问题 (1) 实现输入/输出非线性映射 若输入、输出节点为n、m个,实现的是n维至m维欧式空间 的映射: T:R"→Rm 可知网络的输出是样本输出在L,范数意义下的最佳逼近。 BP网络,通过若干简单非线性处理单元的复合映射,可获得复杂 的非线性处理能力。 (2)BP学习算法的数学分析 BP算法用了优化算法中的梯度下降法,把一组样本的I/O问 题,变为非线性优化问题,隐层使优化问题的可调参数增加,使解 更精确。 2006-12-6 北京科技大学自动化系付冬梅 30
2006-12-6 北京科技大学 自动化系 付冬梅 30 5-5 BP网络有关的几个问题 (1) 实现输入/输出非线性映射 若输入、输出节点为 n、m 个,实现的是 n 维至 m 维欧式空间 的映射: T R R n m : → 可知网络的输出是样本输出在L2范数意义下的最佳逼近。 BP 网络,通过若干简单非线性处理单元的复合映射,可获得复杂 的非线性处理能力。 (2)BP 学习算法的数学分析 BP 算法用了优化算法中的梯度下降法,把一组样本的 I/O 问 题,变为非线性优化问题,隐层使优化问题的可调参数增加,使解 更精确

5-5BP网络有关的几个问题 (3)全局逼近网络 由取的作用函数可知,BP网络是全局逼近网络,即 ∫(x)在x的相当大的域为非零值。 (4) 学习算予 门称梯度搜索算法的步长(收敛因子、学习算子), 0<7<1,7越大,权值调整的越快,在不导致振荡情况 下,7可大一些。 2006-12-6 北京科技大学自动化系付冬梅 31
2006-12-6 北京科技大学 自动化系 付冬梅 31 (3) 全局逼近网络 由取的作用函数可知,BP 网络是全局逼近网络,即 f (x) 在 x 的相当大的域为非零值。 (4) 学习算子 称梯度搜索算法的步长(收敛因子、学习算子), 0 1, 越大,权值调整的越快,在不导致振荡情况 下, 可大一些。 5-5 BP网络有关的几个问题