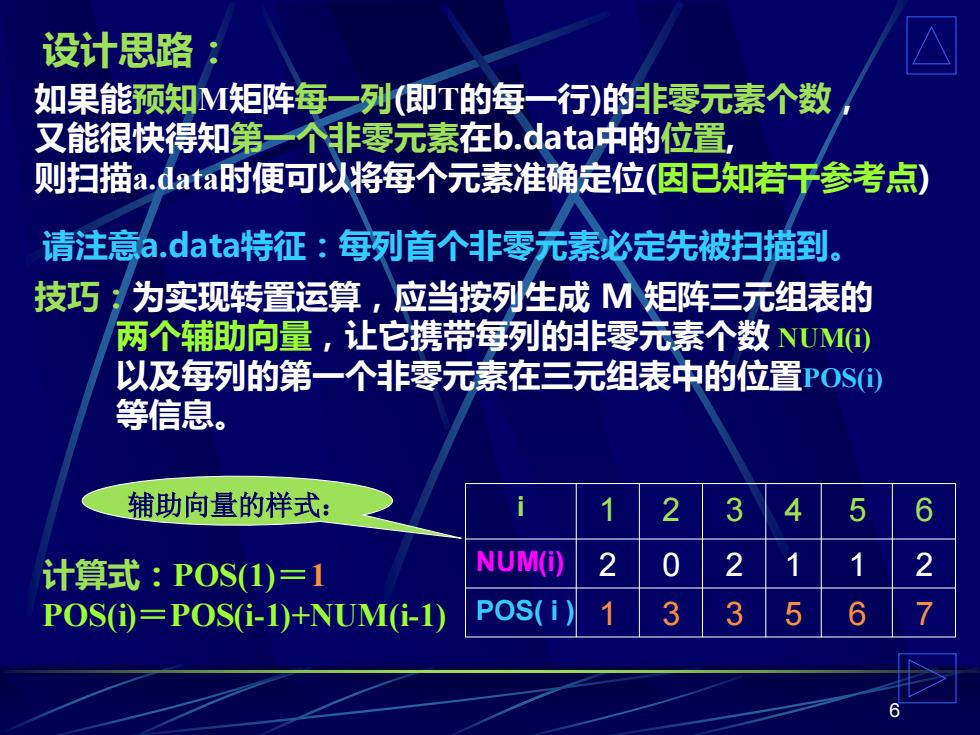
设计思路 如果能预知M矩阵每一列(即T的每一行)的非零元素个数 又能很快得知第一个非零元素在b.data中的位置, 则扫描a.data时便可以将每个元素准确定位(因已知若干参考点) 请注意a.data特征:每列首个非零元素必定先被扫描到。 技巧:为实现转置运算,应当按列生成M矩阵三元组表的 两个辅助向量,让它携带每列的非零元素个数NUM⑥ 以及每列的第一个非零元素在三元组表中的位置P0S) 等信息。 辅助向量的样式: 3 计算式:POS1)=1 POS(i)=POS(i-1)+NUM(i-1) POS( 6
6 如果能预知M矩阵每一列(即T的每一行)的非零元素个数, 又能很快得知第一个非零元素在b.data中的位置, 则扫描a.data时便可以将每个元素准确定位(因已知若干参考点) 技巧:为实现转置运算,应当按列生成 M 矩阵三元组表的 两个辅助向量,让它携带每列的非零元素个数 NUM(i) 以及每列的第一个非零元素在三元组表中的位置POS(i) 等信息。 设计思路: i 1 2 3 4 5 6 NUM(i) 2 0 2 1 1 2 POS( i ) 1 3 3 5 6 7 计算式:POS(1)=1 POS(i)=POS(i-1)+NUM(i-1) 辅助向量的样式: 请注意a.data特征:每列首个非零元素必定先被扫描到
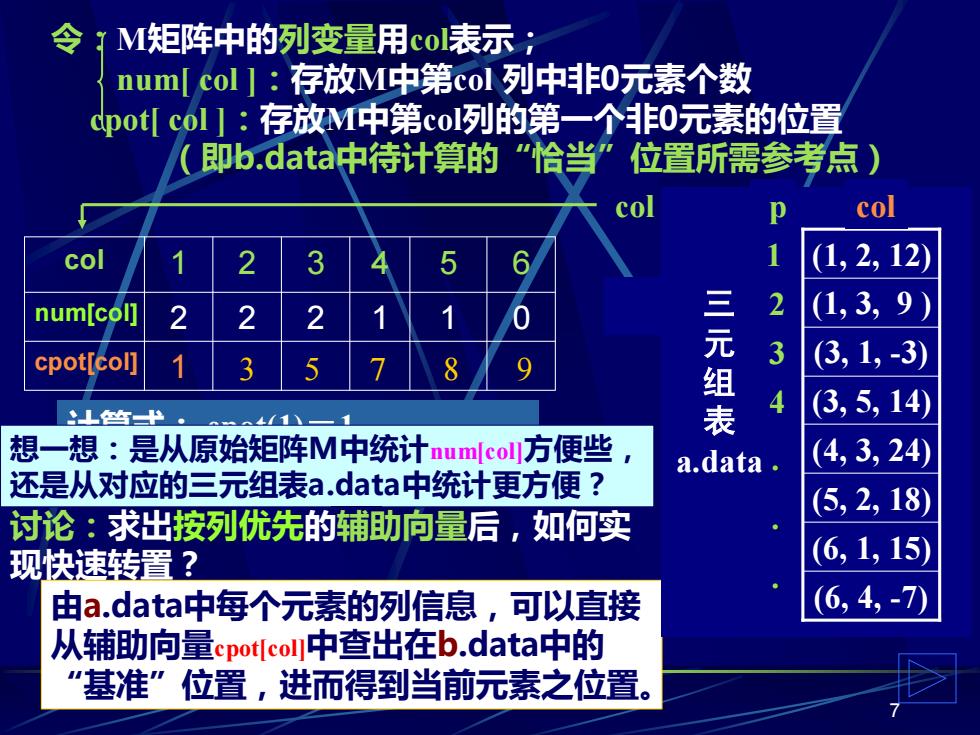
令 ?M矩阵中的列变量用col表示: num[col]:存放M中第col列中非0元素个数 pot[col]:存放M中第col列的第一个非0元素的位置 即b.data中待计算的”恰当”位置所需参考点) col col 5 6 1 (1,2,12 num[col] 2 三元 2 (1,3,9 3 Q 3 (3,1,-3) L竺H 表 (3,5,14) 41N 想一想:是从原始矩阵M中统计numfcoll方便些 a.data (4,3,24 还是从对应的三元组表a.data中统计更方便? (5,2,18) 讨论:求出按列优先的铺助向量后,如何实 现快速转置? (6,1,15) 由a.data中每个元素的列信息,可以直接 (6,4,-7 从辅助向量epotcoll中查出在b.data中的 “基准”位置,进而得到当前元素之位置
7 令:M矩阵中的列变量用col表示; num[ col ]:存放M中第col 列中非0元素个数 cpot[ col ]:存放M中第col列的第一个非0元素的位置 (即b.data中待计算的“恰当”位置所需参考点) 讨论:求出按列优先的辅助向量后,如何实 现快速转置? col 1 2 3 4 5 6 num[col] 2 2 2 1 1 0 cpot[col] 1 计算式: cpot(1)=1 cpot[col]= cpot[col-1] + num[col-1] 3 5 7 8 9 0 12 9 0 0 0 0 0 0 0 0 0 -3 0 0 0 14 0 0 0 24 0 0 0 0 18 0 0 0 0 15 0 0 -7 0 0 M col 1 2 3 4 5 6 由a.data中每个元素的列信息,可以直接 从辅助向量cpot[col]中查出在b.data中的 “基准”位置,进而得到当前元素之位置。 三 元 组 表 a.data (6, 4, -7) (6, 1, 15) (5, 2, 18) (4, 3, 24) (3, 5, 14) (3, 1, -3) (1, 3, 9 ) (1, 2, 12) p col 1 2 3 4 . . . 想一想:是从原始矩阵M中统计num[col]方便些, 还是从对应的三元组表a.data中统计更方便?